编码:把看得懂的 转换为 看不懂的
解码:把看不懂的 转换为 看得懂的
# 什么是字符集?什么是编码?
本节所有文字来源于:编码字符集和字符集编码傻傻分不清楚!看完这篇文章你就懂了?
字符集编码
字符(Character):是文字与符号的总称,包括文字、图形符号、数学符号等。
字符集(Charset):一组抽象字符的集合。
之所以说“抽象”二字,是因为这里所提及的字符是不具任何具体形式的字符。
例如“汉”这个字符,在文章中看到这个“汉”字,这其实是这个字符的一种具体表现形式,是它的图像表现形式;当人们嘴上读“汉”这个字的时候,他们使用的是另一个具体表现形式——声音。但是无论如何,这两个表现形式都是指这个“汉”字,同一个字符的表现形式可能有无数种(点阵法、矢量法、音频等),把每一种的表现形式下的同一个字符都纳入到字符集中,会使得集合过于庞大。
因此抽象字符集中的字符,都是指唯一存在的抽象字符,而忽略了它的具体表现形式。在给定一个抽象字符集合中的每个字符都分配了一个整数编号之后,这个字符集就有了顺序,就成为了编码字符集。同时,这个编号,可以唯一确定到底指的是哪一个字符。
对于同一个字符,不同的字符集编码系统所指定的整数编号也不尽相同。例如“儿”这个字,在 Unicode 中,它的编号是 0x513F,意思是它是 Unicode 这个编码字符集中的第 0X513F 个字符。而在另一种编码字符集中,这个字是 0xA449。
编码字符集
编码字符集,指的是这种被分配了整数编号的字符集合,但是编码字符集中字符被分配的整数编号,不一定就是该字符在计算机中存储时所使用的值,计算机中存储的字符到底使用什么二进制整数值来表示,由字符集编码决定。
字符集编码决定了如何将一个字符的整数编号对应到一个二进制的整数值。英文字符几乎所有的字符集编码中,英文字母的整数编号与其在计算机内部存储的二进制形式都一致。但是有的编码方式中,例如适用于 Unicode 字符集的 UTF-8 编码形式,就将很大一部分字符的整数编号作了变换后存储到计算机中。例如“汉”的 Unicode 值为 0x6C49, 但其编码格式为 UTF-8 格式后的值为 0xE6B189 (3个字节)。
一般只有在Unicode字符集中才有编码字符集的概念。
区分字符集与编码(实现)
在早期,字符集与编码是一对一的。有很多的字符编码方案,一个字符集只有唯一一个编码实现,两者是一一对应的。比如 GB2312,这种情况,无论你怎么去称呼它们,比如“GB2312编码”,“GB2312字符集”,说来说去其实都是一个东西,可能它本身就没有特意去做什么区分,所以无论怎么说都不会错。
到了 Unicode,变得不一样了,唯一的 Unicode 字符集对应了三种编码实现:UTF-8,UTF-16,UTF-32。字符集和编码等概念被彻底分离且模块化,其实是 Unicode 时代才得到广泛认同的。
charset是character set的简写,即字符集。encoding是charset encoding的简写,即字符集编码,简称编码。
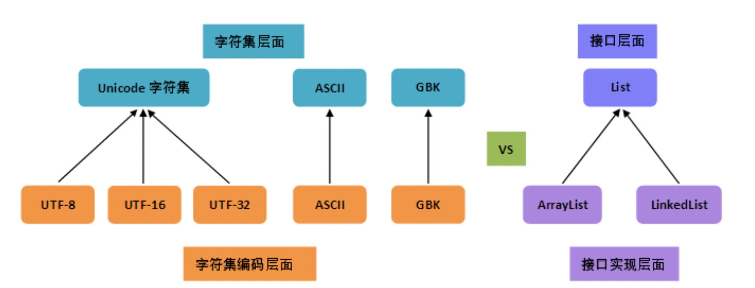
从上图可以很清楚地看到,
- 编码是依赖于字符集的,就像代码中的接口实现依赖于接口一样;
- 一个字符集可以有多个编码实现,就像一个接口可以有多个实现类一样。
为什么 Unicode 这么特殊?
搞出新的字符集标准,无外乎是旧的字符集里的字符不够用了。
Unicode 的目标是统一所有的字符集,囊括所有的字符,因此再去整什么新的字符集就没必要了。
但如果觉得它现有的编码方案不太好呢?在不能弄出新的字符集情况下,只能在编码方面做文章了,于是就有了多个实现,这样一来传统的一一对应关系就打破了。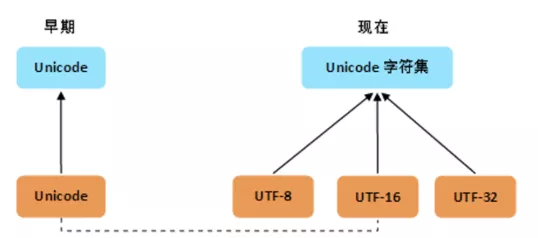
从上图可以看出,由于历史方面的原因,你还会在不少地方看到把 Unicode 和 UTF-8 混在一块的情况,这种情况下的 Unicode 通常就是 UTF-16 或者是更早的 UCS-2 编码。
我们现在说了不少 Unicode,由于各种原因,必须承认,在不同的语境下,“Unicode”这个词有着不同的含义。它可能指:
- Unicode 标准
- Unicode 字符集
- Unicode 的抽象编码(编号),也即码点( code point )
- Unicode 的一个具体编码实现,通常即为变长的 UTF-16,又或者是更早期的定长 16 位的 UCS-2。
这里重点介绍下 UTF-16 编码,UTF-16 把 Unicode 字符集的码点映射为 16 位长的整数(即码元, 长度为 2 Byte)的序列,用于数据存储或传递。Unicode 字符的码点,需要 1 个或者 2 个 16 位长的码元来表示,因此这是一个变长表示。
UTF-16 可看成是 UCS-2 的父集。在没有辅助平面字符(基本思想是用 2 个 16 位的编码表示一个字符,只对超过 65535 的字符这么做)前,UTF-16 与 UCS-2 指的是同一的意思。引入辅助平面字符后,就称为 UTF-16 了。
现在若有软件声称自己支持 UCS-2 编码,那其实是暗指它不能支持在 UTF-16 中超过 2 bytes 的字集。对于小于 0x10000 的 UCS 码,UTF-16 编码就等于 UCS 码。
为什么要重点介绍 UTF-16 编码,因为 Java 的内码使用的是 UTF-16 编码,也就是我们常说的 Unicode 编码。
没想到写了那么长,只是介绍了字符集以及编码的区别,看来是要分成两篇文章才能回答前文留下的问题,本文总结其实就是两句话:
编码字符集里的每一个字符规定的顺序,叫码点( code point ),而这个字符在编码字符集里的序号,在给定的编码方式下的二进制序列叫码元( code unit )。
在 Java 的世界里,我们更多接触的外码,即程序与外部交互时外部使用的字符编码,而你不知道的还有更多,期待下期我们正式进入 Java 的编码世界,最终去回答前文的那个问题。
# 编码表的由来
计算机只能识别二进制数据,早期由来是电信号。为了方便应用计算机,让它可以识别各个国家的文字。就将各个国家的文字用数字来表示,并一一对应,形成一张表。这就是编码表。
常见的编码表
| ASCIl | 美国标准信息交换码 | 用一个字节的7位可以表示 |
| ISO8859-1 | 拉丁码表 / 欧洲码表 | 用一个字节的8位表示 |
| GB2312 | 中国的中文编码表 | 最多两个字节编码所有字符 |
| GBK | 中国的中文编码表升级 | 融合了更多的中文文字符号,最多两个字节编码。(字节的首位表示字符耗用字节的长度) |
| Unicode | 国际标准码 | 融合了目前人类使用的所有字符,为每个字符分配唯一的字符码。所有的文字都用两个字节来表示,但是是基于字节的首位不表示字符耗用字节的长度(如下所示)。 |
一个问题,计算机读取到两个字节的时候,它是把这两个字节作为一个字符来识别还是单独的两个字符来识别?
如何解决这个问题:它看字节的首位,因为字节有8位嘛,如果首位是0,则该字节表示1个字符。如果是1,则表示要拿两个字节来作为1个字符。
# java的码点和码元
码元,又叫做代码单元。
版本1:Java 编码很难吗?看完这篇文章你就懂了
编码字符集里的每一个字符规定的顺序,叫码点( code point ),而这个字符在编码字符集里的序号,在给定的编码方式下的二进制序列叫码元( code unit )。
编码字符集里的每一个字符,都对应到唯一的一个代码值,这些代码值叫做码点(code point),可以看做是这个字符在编码字符集里的序号。
字符在给定的编码方式下的二进制比特序列称为码元(code unit)。
版本2:https://blog.csdn.net/diehuang3426/article/details/83422309
码点是指一个编码表中的某个字符对应的代码值。Unicode的码点分为17个代码级别,第一个级别是基本的多语言级别,码点从U+0000——U+FFFF,其余的16个级别从U+10000——U+10FFFF,其中包括一些辅助字符。
基本的多语言级别,每个字符用16位表示代码单元,而辅助字符采用连续的一对连续代码单元进行编码。
版本3:https://www.cnblogs.com/benbenalin/p/6921553.html
# 字符集编码 / 编码字符集
Unicode
Unicode并不完美,这里就有三个问题:
- 我们已经知道,英文字母只用一个字节表示就够了,
- 如何才能区别Unicode和ASCII?计算机怎么知道两个字节表示一个符号,而不是分别表示两个符号呢?
- 如果和GBK等双字节编码方式一样,用最高位是1或0表示两个字节和一个字节,就少了很多值无法用于表示字符,不够表示所有字符。Unicode在很长一段时间内无法推广,直到互联网的出现。
弹幕: Unicode字符集就像一个字典,你能找到所有的字符对应的编码,具体的Unicode编码类型则是如何将这些编码按照指定的格式存起来 Unicode字符集类似字典,它定义了所有字符对应的编码,而具体的Unicode编码,则是这些字符的编码就提要怎样存储到硬盘里
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。Unicode用数字0-0x10FFFF(十六进制:10FFFF = 1114111)来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位。码位就是可以分配给字符的数字。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
在计算机显示`\u5C1A`,表示这是以十六进制表示的Unicode字符编码,其中,`\u`表示这是一个Unicode值。所以`\u5C1A`就叫做Unicode值
编码范围
Unicode用数字0-0x10FFFF(十六进制:10FFFF = 1114111)来映射这些字符,最多可以容纳1114112个字符。
编码范围:
0000-007F:C0控制符及基本拉丁文(C0 Control and Basic Latin)
0080-00FF:C1控制符及拉丁文补充-1(C1 Control and Latin 1 Supplement)
0100-017F:拉丁文扩展-A(Latin Extended-A)
0180-024F:拉丁文扩展-B(Latin Extended-B)
0250-02AF:国际音标扩展(IPA Extensions)
….
4DC0-4DFF:易经六十四卦符号(Yijing Hexagrams Symbols)
4E00-9FFF:CJK统一表意符号(CJK Unified Ideographs)意思是“中日韩统一表意文字”,把分别来自中文、日文、韩文、越文中,本质、意义相同、形状一样或稍异的表意文字赋予相同编码,其中主要为汉字,但也有仿汉字如日本国字、韩国独有汉字、越南的喃字等。
A000-A48F:彝文音节(Yi Syllables)
…
30000–3FFFF:第3辅助平面,表意文字第三平面(Tertiary Ideographic Plane, TIP)
40000–DFFFF:第4-13辅助平面,尚未使用
E0000–EFFFF:第14辅助平面,特别用途补充平面(Supplementary Special-purpose Plane, SSP)
F0000–FFFFF:第15辅助平面,保留作为私人使用区(Private Use Area, PUA)
100000–10FFFF:第16辅助平面,保留作为私人使用区(Private Use Area, PUA) [2]
编码实现
UTFunicode只规定哪些数字对应哪些字符,比如规定0就对应空格,如0000就表示空格,所以`\u0000`表示为空格。那虽然我知道这些数字表示这些字符,那我存储或传输的时候怎么以什么格式来存储或传输呢?此时UTF就出现了
为解决Unicode的问题,面向传输的众多UTF (UCS Transfer Format)标准出现了。
UTF,是Unicode Transformation Format的缩写,意为Unicode转换格式。
即:将一个Unicode字符保存为字节序列的格式规范,用于文件存储、数据传输等。Unicode标准支持3种编码格式,如下:
- UTF-32: 使用4字节表示一个Unicode字符。
- UTF-16: 变长的编码格式,码位大于
\xFFFF的字符,使用4字节存储,小于等于\xFFFF的字符,使用2字节存储。 - UTF-8: 变长的编码格式,码位大于
\xFFFF的字符,使用4字节存储,小于等于\xFFFF大于\x07FF的使用3字节,小于等于\x07FF大于\x007F的使用2字节,小于等于\x007F使用1字节。
UTF-8
UTF-8是UTF中最常用的转换格式,是UNICODE的一种变长字符编码,由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码UNICODE字符。
UTF-8以字节为单位对Unicode进行编码

比如“尚”这个字,Unicode编码值是23578,该编码值的十六进制为5C1A,二进制为0101 1100 0001 1010。
现在要把这个字存到磁盘中,怎么存?中文在UTF-8中是3个字节作为1个字符, (把“0101 1100 0001 1010”截成几部分塞进模板里)
(把“0101 1100 0001 1010”截成几部分塞进模板里)
在标准UTF-8编码中,超出基本多语言范围(BMP-Basic Multlingual Plane )的字符被编码为4字节格式,但是在修正的UT-8编码中,他们由代理编码对 (surogatepairs)斯际,然后这些代理编码对在序列中分别重新编码。结果标准UTF-8编码中需要4个字节的字符,在修正后的UTF-8编码中将需要6个字节。
ANSI
ANSI:American National Standards Institute(美国国家标准学会)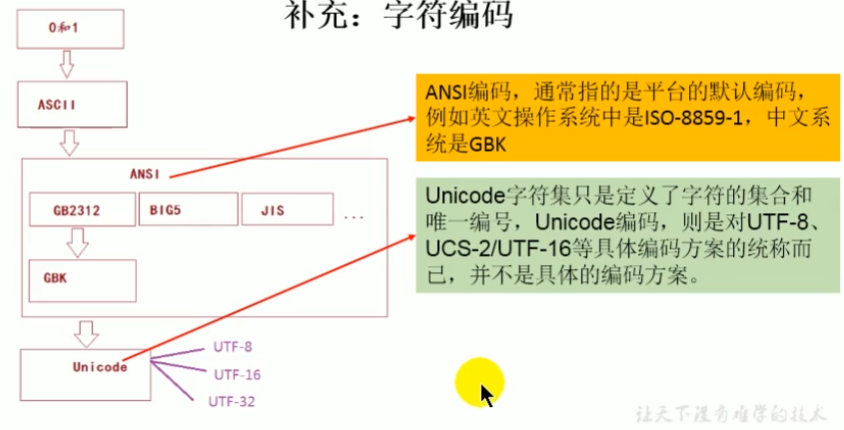

若有收获,就点个赞吧
0 人点赞
