查询
函数
长度
背景
- 爬虫收集知乎提问数据时,收集到300万左右的数据发现mysql占用到了将近1G的内存,但其实300W的数据也没有达到1G大小
解决
- 背景
- count极慢,where极慢,而且count还是使用的主键,仍然需要花将近十秒
- count慢
- 参考:https://blog.csdn.net/csdnhsh/article/details/116329858
- count用来统计结果集中不为null的数值,所以需要进行全表扫描
- 查询速度大小比较:
- count(字段)<count(主键id)<count(1)≈count(*)
- count(1) 无需对数据行进行解析
- 最终
- 使用:SHOW TABLE STATUS;查询到内部统计数据代替表的行数查询
- SELECT (table_rows) FROM information_schema.TABLEs WHERE table_name=’question’;
- 可见关键的表信息都在系统的 information_schema.TABLEs 表中
- 但是此方法查询到的数据很不准确很不准确,而且没有实时性,时大时小
- 参考:https://blog.csdn.net/csdnhsh/article/details/116329858
- where慢
- 主要是对于非主键字段而言查询过慢,所以最好的办法就是直接加索引
- ALTER TABLE tb_stu_info3 ADD index(id) ;
- 主要是对于非主键字段而言查询过慢,所以最好的办法就是直接加索引
缓存问题
- 前提
- 如果表频繁改动不建议使用
- 会增加服务器开销,先对比缓存数据
- 使用查询缓存方式(query_cache_type)
- 查看是否开启: select @@query_cache_type;
- 打开缓存:set session query_cache_type=off;
- 禁用缓存:set session query_cache_type=on;
- 系统查询缓存可用性(have_query_cache)
- 查询是否可用:show variables like ‘have_query_cache’;
- 查询缓存大小(query_cache_size)
- 查询大小:select @@global.query_cache_size;
- 设置大小:set @@global.query_cache_size=100000;(1M)
- 查询结果最大数量(query_cache_limit)
- 前提
千万级数据
where和on的区别在于效率

- 更严重的效率问题是inner join和select from where,后者先算出笛卡尔积后再进行筛选,前者一步一步筛选(多表的情况下)

-
2. 临时表
创建临时表
本质的区别就是where筛选的是数据库表里面本来就有的字段,而having筛选的字段是从前筛选的字段筛选的
- where和having都可以使用的场景:
- select goods_price,goods_name from sw_goods where goods_price>100
- select goods_price,goods_name from sw_goods having goods_price>100
- 原因:goods_price作为条件也出现在了查询字段中。
- 只可以使用where,不可以使用having的情况:
- select goods_name,goods_number from sw_goods where goods_price>100
- select goods_name,goods_number from sw_goods having goods_price>100(X)
- 原因:goods_price作为筛选条件没有出现在查询字段中,所以就会报错。
- having的原理是先select 然后从select出来的进行筛选。而where是先筛选在select。
- 只可以使用having,不可以使用where的情况:
- select goods_category_id,avg(good_price) as ag from sw_goods group by goods_category having ag>1000
- select goods_category_id,avg(goods_price) as ag from sw_goods where ag>1000 group by goods_category(X)报错,这个表里没有这个ag这个字段。
- where子句中一般不使用聚合函数那种情况。
- where和having都可以使用的场景:
引用:https://www.cnblogs.com/ljf-Sky/p/9024683.html
4. exist
注意
- EXISTS(包括 NOT EXISTS )子句的返回值是一个BOOL值。
- EXISTS内部有一个子查询语句(SELECT … FROM…), 我将其称为EXIST的内查询语句。
- 其内查询语句返回一个结果集。
- EXISTS子句根据其内查询语句的结果集空或者非空,返回一个布尔值。
- 一种通俗的可以理解为:将外查询表的每一行,代入内查询作为检验,如果内查询返回的结果取非空值,则EXISTS子句返回TRUE,这一行行可作为外查询的结果行,否则不能作为结果。
- 引用:https://www.cnblogs.com/qlqwjy/p/8598091.html
个人理解
https://blog.csdn.net/u014717572/article/details/80687042
骚操作
SQLyog破解方法
- 先WIN+R打开命令行窗口wo- 然后输入regedit打开注册表- 找到相应注册表<br />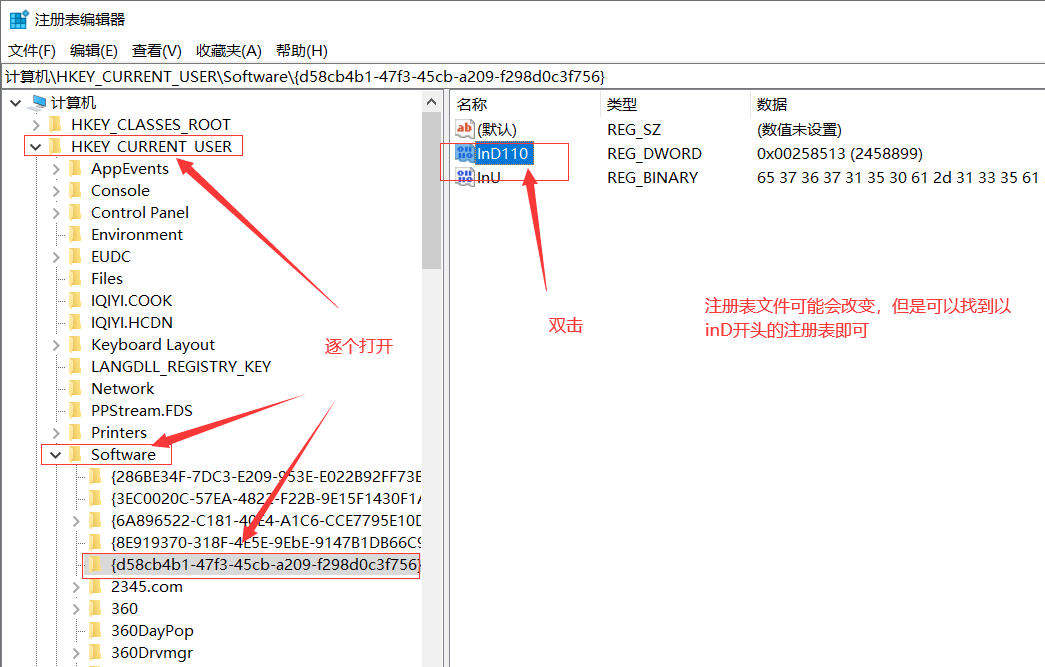- 修改数值<br />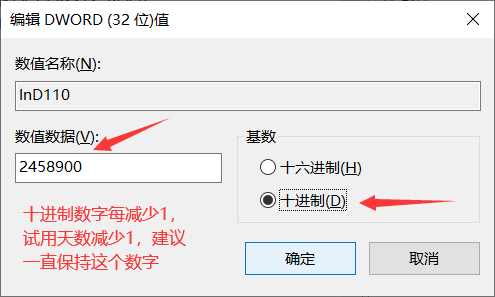- 保持使用(每过一天将数字增加1,表示在这个天时注册)<br />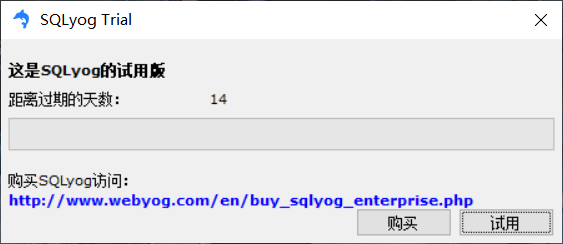
电源电池充电最大设置
- 
数据库中文乱码
- [完整解决方案](https://blog.csdn.net/qq_39240270/article/details/86603715)- [文件位置](https://blog.csdn.net/nihang1234/article/details/81872584)- 重启mysql服务器可以直接在任务管理器进行



若有收获,就点个赞吧
0 人点赞
