PHP 中的 HTML 解析是使用的 DOM模块
$dom = new DOMDocument;$dom->loadHTML($html);$images = $dom->getElementsByTagName('img');foreach ($images as $image) {$image->setAttribute('src', 'http://example.com/' . $image->getAttribute('src'));}$html = $dom->saveHTML();
这里列举所有包含 nofollow 属性的 <a> 标签:
$doc = new DOMDocument();libxml_use_internal_errors(true);$doc->loadHTML($html); // loads your HTML$xpath = new DOMXPath($doc);// returns a list of all links with rel=nofollow$nlist = $xpath->query("//a[@rel='nofollow']");
提取谷歌结果的 dom 程序.
<?php# Use the Curl extension to query Google and get back a page of results$url = "http://www.google.com";$ch = curl_init();$timeout = 5;curl_setopt($ch, CURLOPT_URL, $url);curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);$html = curl_exec($ch);curl_close($ch);# Create a DOM parser object$dom = new DOMDocument();# Parse the HTML from Google.# The @ before the method call suppresses any warnings that# loadHTML might throw because of invalid HTML in the page.@$dom->loadHTML($html);# Iterate over all the <a> tagsforeach($dom->getElementsByTagName('a') as $link) {# Show the <a href>echo $link->getAttribute('href');echo "<br />";}?>
FAQ
DOMDocument::loadHTML(): Unexpected end tag : p in Entity
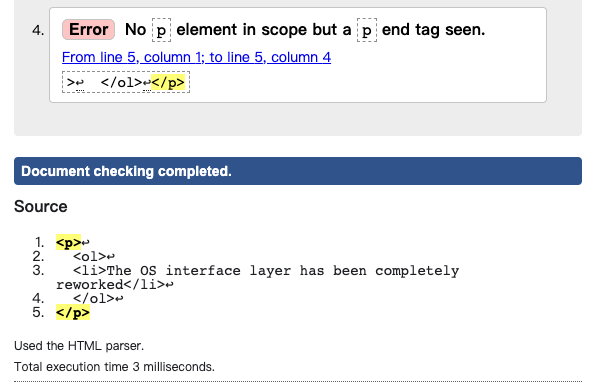
当分析 html 代码的时候如果嵌套类型不正确, 则会报这个错误, 因为 <ol> 是一个块级元素, p之内是不能存放任何块级元素的
$html = '<p><ol><li>The OS interface layer has been completely reworked</li></ol></p>';$Dom = new DOMDocument();$Dom->loadHTML($html);$Xpath = new DOMXPath($Dom);$Xpath->query('//p');
这个 $html在 https://validator.w3.org/ 中进行验证会有如下错误
No
pelement in scope but apend tag seen.

若有收获,就点个赞吧
0 人点赞
