概述
当我们的逻辑计划引擎把SQL生成了逻辑计划后,后端的物理计算引擎接收到逻辑计划生成物理执行计划,便可以开始去真正执行计算作业了。在关系数据库发展的早期,受制于计算机IO能力的约束,数据库通常的物理执行引擎采用的是火山模型的设计方式。因为火山模型每次只处理一行数据,大大的节约了内存的使用量。
数据库物理计算引擎通常分为二类,一类是以火山模型(Volcano Model)为代表的拉取模型。另一类是以Pipeline为代表的推模型。本文主要讲述的是第一种火山模型(Volcano Model)。了解火山模型前,我们了解一下数据库的一些基本算子。
算子介绍
先简单介绍数据库中基本的算子。
Scan算子,作用是读取数据源的具体数据。例如: select * from t 就是读取t表中的数据。<br /> Selection算子,作用是处理Sql中的谓词条件。例如: select xxx from t where xx = 5 里面的 where 过滤条件就是Selection算子处理的。<br /> Projection算子,作用是物理执行器计算出的数据传递给外部。例如: select c from t 中 Projection算子是输出C列中的数据。<br /> Join算子,作用是计算两个表的连接后的数据。例如: select xx from t1, t2 where t1.c = t2.c 就是把 t1 t2 两个表做 Join。

火山模型
火山模型又叫迭代器模型, 最早于1990年Goetz Graefe在Volcano, an Extensible and Parallel Query Evaluation System这篇论文中提出(参考资料中有论文链接),在90年代早期,计算机的内存资源十分昂贵,相对于CPU的执行效率,IO效率要差得多,因此运算符和存储之间的IO交换是影响查询效率的主要因素(IO墙效应),火山模型将更多的内存资源用于IO的缓存设计而没有优化CPU的执行效率是在当时的硬件基础上很自然的权衡。
火山模型其基本思路十分简单:将关系代数当中的每一个算子抽象成一个迭代器。每个迭代器都带有一个 next 方法。每次调用这个方法将会返回这个算子的产生的一行数据(或者说一个 Tuple)。程序通过在 SQL 的计算树的根节点不断地调用 next方法来获得整个查询的全部结果。比如 SELECT col1 FROM table1 WHERE col2 > 0;这条 SQL 就可以被翻译成由三个算子组成的计算树。如下图所示,我们也可以使用伪代码将这三个算子的执行逻辑表示出来。
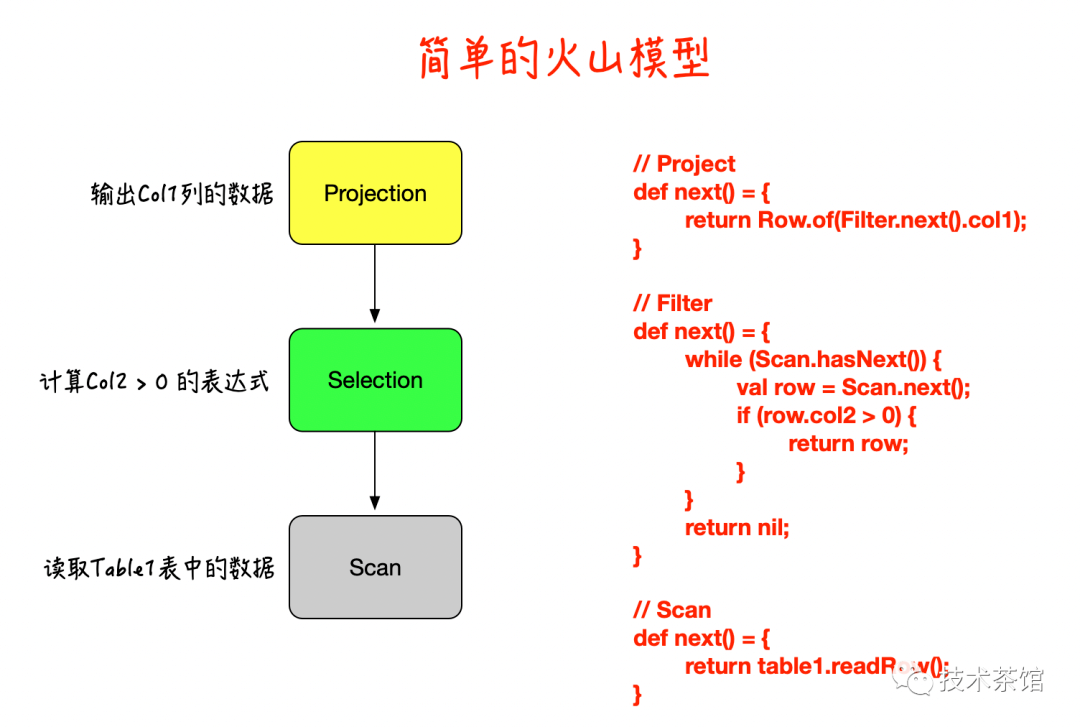
通过上图可以看到,Volcano 模型是十分简单的,而且他对每个算子的接口都进行了一致性的封装。也就是说,从父节点来看,子节点具体是什么类型的算子并不重要,只需要能源源不断地从子节点的算子中 Fetch 到数据行就可以。
上面的例子简单的说明了下火山模型的工作原理,下面我们举一个稍微复杂点的例子了解一下物化的这个概念,有一个 JOIN 算子,因此在生成的执行方案树当中会有一个分叉。我们假定 RIGHT_TABLE 表的行数远小于 LEFT_TABLE 表,这样一个合理的执行方案可能是先将 RIGHT_TABLE 表的所有数据读出来构造一个 Hash 表,再将 LEFT_TABLE 表当中的每一行读出并通过 Hash 表查询获得结果。此时的 Volcano 模型的执行要更复杂些。JOIN 算子为了向上封装这些细节,需要在内部不断调用 RIGHT_TABLE 表的 next 方法直到将其内容全部读取出来。
SQL如下:

因此,对于这样一条 SQL,他的执行树表示成下图的样子。
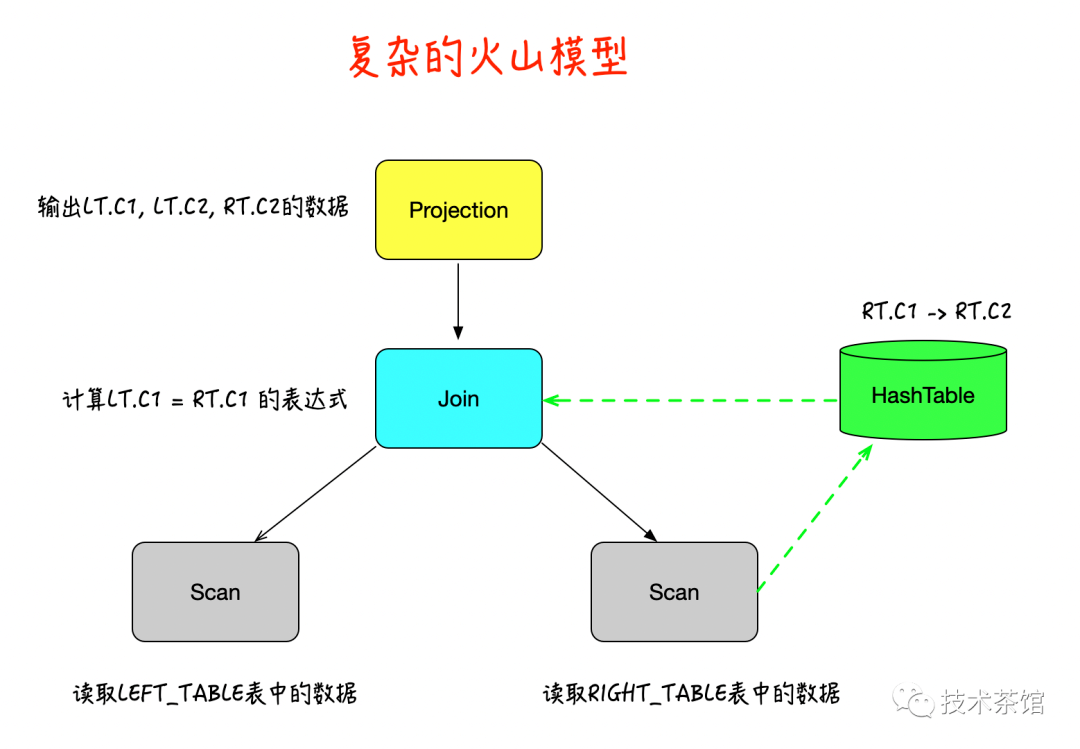
如上图所示,我们将 RIGHT_TABLE 的内容读入 Hash 表,构建 RIGHT_TABLE.C1 -> RIGHT_TABLE.C2 的映射。之后再逐一读入 LEFT_TABLE 表的内容,对于 LEFT_TABLE 表的每一行,我们使用它的 C1 列在 Hash 表中进行查询,从而得到 JOIN 之后的结果。
JOIN 算子的执行分为两个部分。第一个部分它会在内部不断调用 RIGHT_TABLE.next() 函数构建 Hash 表,之后调用 LEFT_TABLE 的 SCAN 算子一次以便返回第一行结果。之后对 JOIN 的调用就只会读取 LEFT_TABLE 的内容进行并在 Hash 表里探查(Probe)。这一方式实现的 Hash 表是一个带有内部状态的算子,与其他的算子大不相同。而它构建内部 Hash 表的过程可以被认为是一种物化(Materialization)。
火山模型痛点
火山模型简单明了,也非常灵活。但是在当代CPU的硬件环境与大数据场景下,性能表现却差强人意。究其原因。主要有如下几点:
一、虚函数的开销
next函数通常是一次虚函数调用。在Java中,为了支持多态,所有的非静态方法与非final方法本质上都是动态绑定的虚函数,在JVM层依赖于invokevirtual和invokeinterface这两个方法指令。虚函数调用与普通函数的调用的区别在于后者是一次直接调用,直接调用的跳转地址在编译时是确定的。而虚函数调用是一次间接调用,需要在运行时才能从虚表获取地址再跳转。所以,虚函数首先会多一次寻址的时间开销;其次,虚函数是无法在编译期做内联优化的,所以运行时会实实在在多一次函数调用开销。对于Java来说,方法调用会在运行时会多一次栈桢入栈出栈操作;最后,也是最重要的一点,虚函数的间接调用本身会导致分支预测。据统计,间接分支预测的失败率在25%左右。一旦分支预测失败,将会导致流水线被冲刷,进而需要重新获取指令、译码,对性能造成严重的影响。
二、Cpu Cache的利用率
这种风格对代码和数据的局部性并不友好。它不能很好的利用CPU的缓存机制。由于CPU的各级Cache都是从下一级存储按特定长度单位对齐取数的,且取到的数据也是连续的,所以每次取到的连续的数据如果能被集中充分处理,将会得到最大的收益。但next调用每次只处理一条记录,而且火山模型是个拉取的模型,即下游什么时候拉取并不随当前算子控制,所以当前算子刚刚cache的数据在只取用了一部分就很有可能马上被其他算子的next调用获取的数据给冲掉(evict)了。而当前算子再次调用next时又会冲掉别人的cache,重新将之前被人冲掉的未处理的数据从较慢的存储中读取来给CPU处理。这样的周而复始,造成了不必要的开销。而且拉取模型也要求严格以算子为界进行物化,其实很多物化点是可以避免的。
大数据时代的体量放大了1和2的问题。如果数据量不多,那么1和2的问题并不明显。但是在大数据时代,我们需要处理的数据量从百万到数十亿是家常便饭。每条记录都会经历next的调用,所以性能问题将被放大百万倍、数十亿倍以至更甚。从而警醒我们不容忽视。
那么有没有一种解决方案处理虚函数的问题呢?火山模型影响的是执行流程的代码布局,但只要是解释执行,就无法避免运算符之间的虚函数调用。随着计算机硬件的发展,内存变得越来越大,这意味着越来越多的数据可以直接cache在内存中,而访问磁盘的频率被大幅度的降低,这个时候“IO墙”的效应被削弱,而由于解释执行无法感知CPU寄存器,高频的内存访问,使CPU和内存之间形成了“内存墙”效应,为了解决这个问题,越来越多的内存数据库开始使用Llvm编译执行的技术来优化自己的查询效率,例如HyPer、MemSQL、Hekaton、Impala、Spark Tungsten等,参考资料中给出了impala中的使用编译执行的论文。
那么有没有一种解决方案处理CPU Cache的问题呢?答案是显而易见的,我们可以通过批量处理的方式来优化处理。之前提到,在火山模型中,next方法是一次处理一条记录,而我们知道next的调用开销是挺高的,而一次处理一条记录对于代码和数据的局部性都不是很友好。所以,如果能next方法改善为例如nextBatch方法,让每次能在算子里一次性处理的数据与CPU的Cache Line对齐,那将在局部性这块上得到最大化的收益。当然,batch不宜过大,正好能放入Cache Line为佳。批处理计算还为进一步的优化(如 SIMD 指令执行)提供了有利条件。
结论
本文介绍了物理计算引擎的Pull模型是实现之一的火山模型。火山模型是一种简单的计算模型,把各个的物理算子抽象成一个个迭代器。每一个算子只关心自己内部的逻辑即可,让各个算子之间的耦合性降低。但是同样火山模型也带来的虚函数开销和CPU Cache不友好的问题。下一节中带来物理计算引擎Push模型的Pipeline设计方式。敬请期待。

若有收获,就点个赞吧
0 人点赞
