与计算机视觉中使用图像进行数据增强不同,NLP中文本数据增强是非常罕见的。这是因为图像的一些简单操作,如将图像旋转或将其转换为灰度,并不会改变其语义。语义不变变换的存在使增强成为计算机视觉研究中的一个重要工具。
本篇文章将整理目前比较主流的文本数据增强办法:
词汇替换
基于词典的替换
- 在这种技术中,我们从句子中随机取出一个单词,并使用同义词词典将其替换为同义词。例如,我们可以使用WordNet的英语词汇数据库来查找同义词,然后执行替换。它是一个手动管理的数据库,其中包含单词之间的关系。
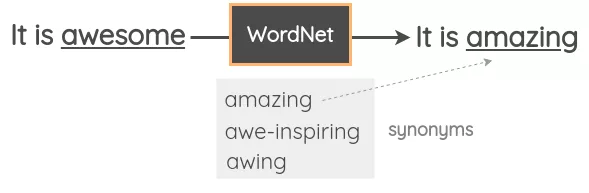
- Zhang et al.在其2015年的论文“Character-level Convolutional Networks for Text Classification”中使用了这一技术。Mueller et al.使用了类似的策略来为他们的句子相似模型生成了额外的10K训练样本。
基于词向量的替换
在这种方法中,我们采用预先训练好的单词嵌入,如Word2Vec、GloVe、FastText、Sent2Vec,并使用嵌入空间中最近的相邻单词替换句子中的某些单词。Jiao et al.在他们的论文“TinyBert”中使用了这种技术,以提高他们的语言模型在下游任务上的泛化能力。Wang et al.使用它来增加学习主题模型所需的tweet。

例如,你可以用三个最相似的单词来替换句子中的单词,并得到文本的三个变体。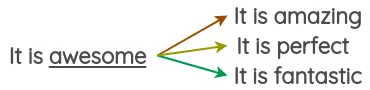
Masked Language Model
- 像BERT、ROBERTA和ALBERT这样的Transformer模型已经接受了大量的文本训练,使用一种称为“Masked Language Modeling”的预训练,即模型必须根据上下文来预测遮盖的词汇。这可以用来扩充一些文本。例如,我们可以使用一个预训练的BERT模型并屏蔽文本的某些部分。然后,我们使用BERT模型来预测遮蔽掉的token。
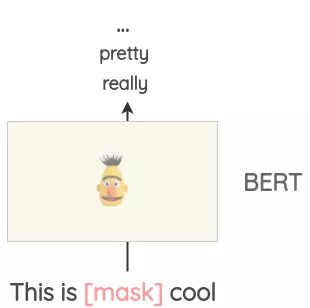
因此,我们可以使用mask预测来生成文本的变体。与之前的方法相比,生成的文本在语法上更加连贯,因为模型在进行预测时考虑了上下文。
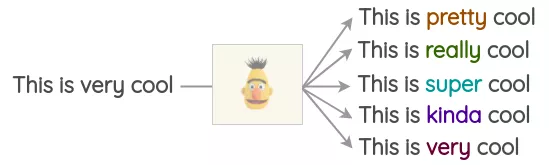
基于TF-IDF的词替换
- 这种增强方法是由Xie et al.在无监督数据增强论文中提出的。其基本思想是,TF-IDF分数较低的单词不能提供信息,因此可以在不影响句子的ground-truth的情况下替换它们。

反向翻译
在这种方法中,我们利用机器翻译来解释文本,同时重新训练含义。Xie et al.使用这种方法来扩充未标注的文本,并在IMDB数据集中学习一个只有20个有标注样本的半监督模型。该方法优于之前的先进模型,该模型训练了25,000个有标注的样本。
反向翻译过程如下:
- 把一些句子(如英语)翻译成另一种语言,如法语
- 将法语句子翻译回英语句子。
- 检查新句子是否与原来的句子不同。如果是,那么我们使用这个新句子作为原始文本的数据增强。

你还可以同时使用不同的语言运行反向翻译以生成更多的变体。如下图所示,我们将一个英语句子翻译成三种目标语言:法语、汉语、意大利语,然后再将其翻译回英语。
这项技术也被用在了的Kaggle上的“Toxic Comment Classification Challenge”的第一名解决方案中。获胜者将其用于训练数据增强和测试期间,在测试期间,对英语句子的预测概率以及使用三种语言(法语、德语、西班牙语)的反向翻译进行平均,以得到最终的预测。
文本表面替换
这些是使用正则表达式的简单的模式匹配的转换,由Claude Coulombe在他的论文中介绍。
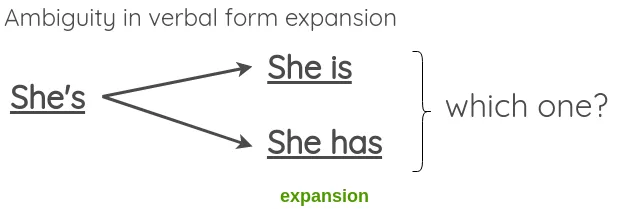
在本文中,他给出了一个将动词形式由简写转化为完整形式或者反过来的例子。我们可以通过这个来生成增强型文本。
既然转换不应该改变句子的意思,我们可以看到,在扩展模棱两可的动词形式时,这可能会失败,比如:
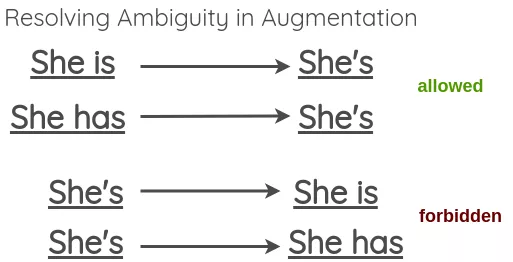
为了解决这一问题,本文提出允许模糊收缩,但跳过模糊展开。
随机噪声注入
这些方法的思想是在文本中加入噪声,使所训练的模型对扰动具有鲁棒性。
拼写错误注入
在这种方法中,我们在句子中的一些随机单词上添加拼写错误。这些拼写错误可以通过编程方式添加,也可以使用常见拼写错误的映射,如:https://github.com/makcedward/nlpaug/blob/master/model/spelling_en.txt。
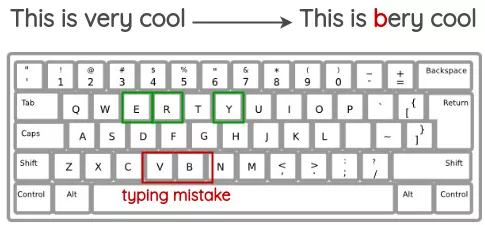
QWERTY键盘错误注入
该方法试图模拟在QWERTY布局键盘上输入时发生的常见错误,这些错误是由于按键之间的距离非常近造成的。错误是根据键盘距离注入的。
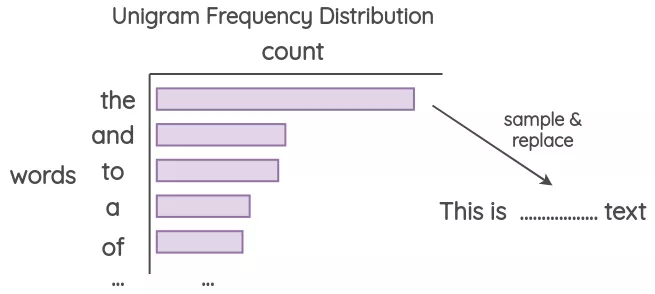
Unigram噪声
该方法已被Xie et al.和UDA论文所采用。其思想是用从单字符频率分布中采样的单词进行替换。这个频率基本上就是每个单词在训练语料库中出现的次数。
Blank Noising
这个方法是由Xie et al.在他们的论文中提出的。其思想是用占位符标记替换一些随机单词。本文使用“_”作为占位符标记。在论文中,他们将其作为一种避免特定上下文过拟合的方法,以及语言模型的平滑机制。该技术有助于提高perplexity和BLEU评分。

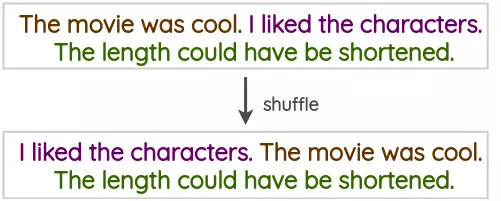
句子打乱这是一种朴素的技术,我们将训练文本中的句子打乱,以创建一个增强版本。
随机插入标点符号
在原始文本中随机插入标点符号,文中给出六种标点符号以供使用——“. : ? ; ! ,”。首先从1~n*/3(句长的三分之一)随机选取一个数字k,则向原始文本中随 随机插入k个标点符号。(文中表示,在保证有标点符号插入的同时,又不能插入过多的标点符号,避免产生过多的噪声数据进而对实验性能产生负面影响,所以提出了如此选择数字k的方法。)
实例交叉增强
这项技术是由Luque在他的关于TASS 2019情绪分析的论文中提出的。这项技术的灵感来自于遗传学中发生的染色体交叉操作。
该方法将tweets分为两部分,两个具有相同极性的随机推文(即正面/负面)进行交换。这个方法的假设是,即使结果是不符合语法和语义的,新文本仍将保留情感的极性。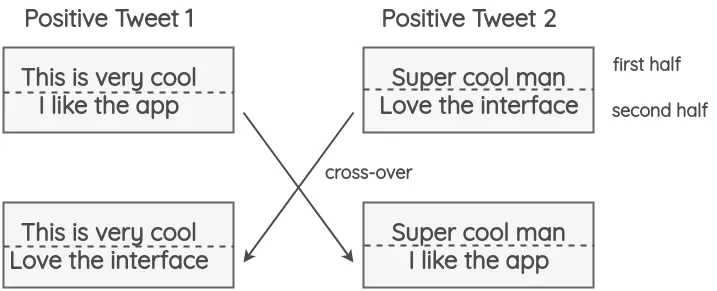
这一技术对准确性没有影响,但有助于论文中极少数类的F1分数,如tweets较少的中性类。

语法树操作
这项技术已经在Coulombe的论文中使用。其思想是解析和生成原始句子的依赖关系树,使用规则对其进行转换,并生成改写后的句子。
例如,一个不改变句子意思的转换是句子从主动语态到被动语态的转换,反之亦然。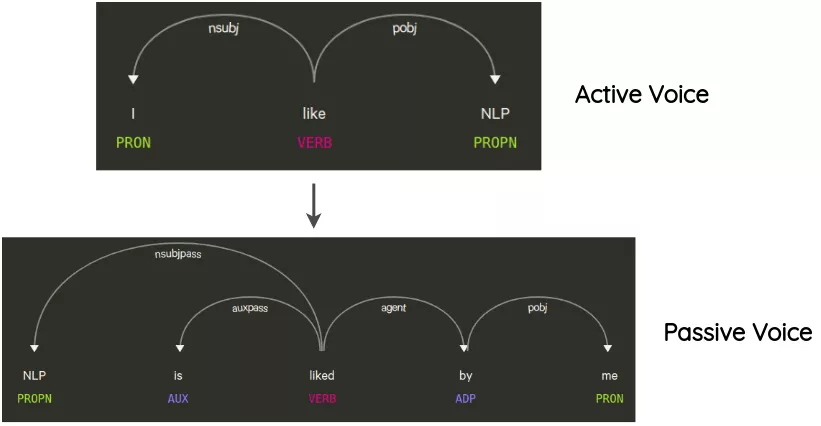
Mixup
Mixup一开始也是源于CV领域,它是利用线性插值的方式产生更多的训练样本,假设有两个训练样本  与
与  那么可以分别对输入与label进行插值产生训练样本
那么可以分别对输入与label进行插值产生训练样本 

在CV任务中模型的输入信息是RGB矩阵,这一直接做插值,但在NLP领域模型的input是文本或者token序列,如何做插值呢?这就利用到了embedding技术了,常见文本mixup的方式有两种:
- WordMixup:用zero padding的方式将所有句子padding到相同的长度,然后将两个训练样本的word embedding序列与label用上面公式进行插值得到增强样本,发生在模型的embedding层。
- SenMixup:在句子经过LSTM、CNN或者Transfomer处理后会得到整句话的sentence encoding,然后对两个样本的sentence encoding与label进行插值,最后将插值后的结果送到网络最末端的softmax层去处理。这种插值发生在网络的末端,可以复用之前encoding的结果,所以计算效率较高。


分别使用CNN与LSTM模型在多个文本分类数据集(Trec、SST-1、MR等)上做了对比实验,模型的word embedding是随机初始化的,并且可训练(RandomTune)。
可以看出使用Mixup进行数据增强,Accuracy均获得了显著的提升。

若有收获,就点个赞吧
0 人点赞

{kind=link}