第一章 MySQL数据库对象
第一节MySQL数据类型
MySQL数据类型
1.学习掌握常用的数据类型
整型
| 字节 | 位数 | 位数 | |
|---|---|---|---|
| tinyint | 1 | -128 | 127 |
| 0 | 255 | ||
| smallint | 2 | -32768 | 32767 |
| 0 | 65535 | ||
| mediumint | 3 | -8388608 | 8388607 |
| 0 | 16777215 | ||
| int | 4 | -2147483648 | 2147483647 |
| 0 | 4294967296 | ||
| bigint | 8 | ||
Int(11)与int(21)的区别
存储范围,空间都相同,但是使用int(11)插入1会为记录补上10个零int(21)会补上20个零
浮点型
l Float(M,D) 四字节 单精度 非精确
l Double(M,D) 八字节 双精度 比float精度高
l 两种都是非精确类型-精度丢失-eg工资被四舍五入
Float,Double,两种类型存储,不会因为存储的的大小改变存储空间
Decimal:
l 高精度的数据类型,常用来存储交易相关的数据
l Decima(M,N),M代表别总精度,N代表小数点右侧的位数(标度)
l 1
Decimal类型存储,会随着存储的大小改变存储空间大小
2.针对业务类型选择合适的数据类型
存储性别、省份、类型等分类信息时选择tinnyint或者enum
Bigint存储空间更大,int和bingint之间通常选择bingnt
性别、省份类: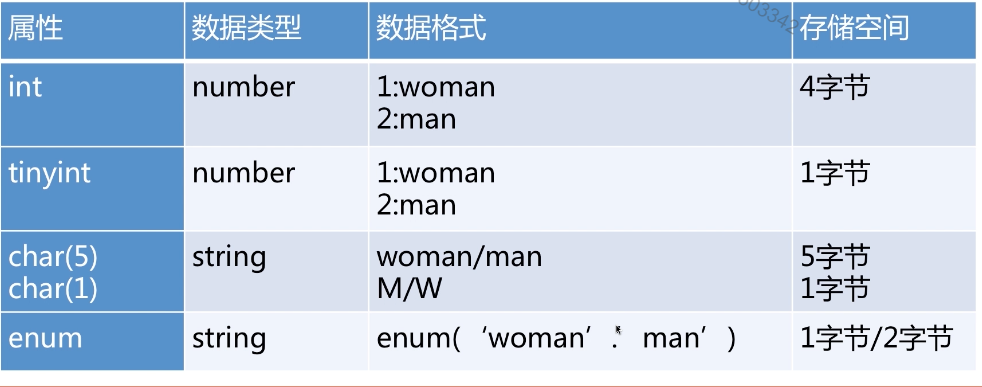
用户名的属性:char, varchar,text,
Char与varchar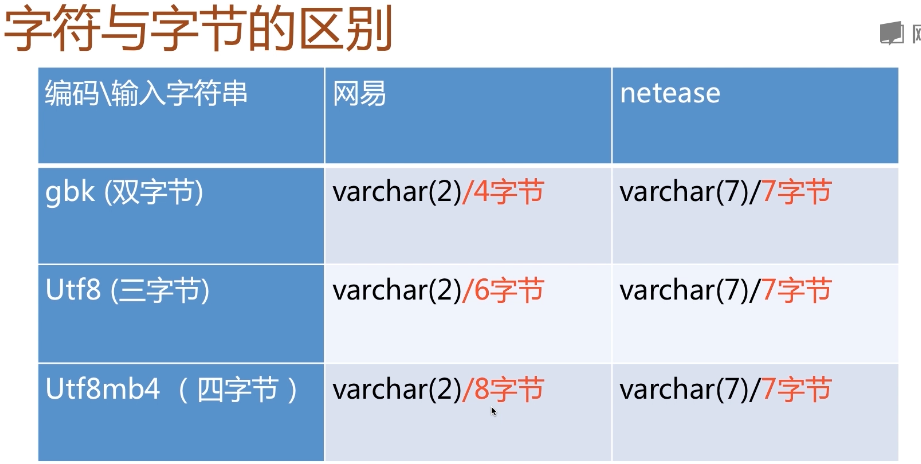
l 英文不管什么情况下都只占一个字节
l 移动端-表情-必须要使用utf8mb4
l Char存储定长,容易造成空间的浪费
l Varchar存储变成,节省空间
l 极端情况下,char与varchar都只存储一个字符时,char只占一个字符,varchar占两个(length)
Text与Char和VARCHAR的区别
l CHAR和VARCHAR存储单位为字符
l 文本存储单位为字节,总大小为65535字节,约为64 KB
l char数据类型最太为255字符
l varchar数据类型为变成存储,可以存储超过255个字符
l Text在数据库内大多存储格式为溢出页,效果不如char
小结:
l CHAR与VARCHAR定义的长度是字符长度不是字节长度
l 存储字符串推荐选择使用VARCHAR(N),N尽量小
l 虽然数据库可以存储二进制数据,但是性能低下,不要使用数据库存储文件音频等二进制数据
时间类型的区别在哪里
存储空间不同
l DATE三字节,如: 2015-05-01
l TIME三字节,如: 11:12:00
l TIMESTAMP四字节,如: 2015-05-01 11:12:00
l DATETIME八字节,如: 2015-05-01 11:12:00
Timestamp存储范围:1970-01-01 00:00:01 to 2038-01-19 03:14:07
Datetime 存储范围:1000-01-01 00:00:00 to 9999-12-31 23:59:59
TIMESTAMP会根据系统时区进行转换,DATETIME不会,国际化的项目使用TIMESTAMP
Bigint如何存储时间类型
Print tinme.time();编译时间
select fromunxtime(1439523443);解析时间
应用程序将时间转换为数字类型
第二节MySQL数据对象
MySQL数据对象
MySQL常见的数据对象
Database/schema相当于柜子、Table、Index
View(视图)/Trigger(触发器)/Function(函数)/Procedure(存储过程)
多database用途
l 业务隔离-不同业务数据库
l 资源的隔离
表上常用的数据对象;
索引:
l 索引就是数据库中数据的目录
l 可以针对一个属性或多个属性进行检索
l 索引和数据是两个对象
l 索引主要是用来提高数据库的查询效率
l 数据库中数据变更同样需要同步索引数据的变更
可以使用creat index;alter table;建立索引
约束
唯一约束
对一张表的某个字段或某几个字段设置唯一约束,保证在这个表里对应的数据必须唯一
创建唯一约束
l 唯一约束是一种特殊的索引
l 唯一约束可以是一个或多个字段
l 唯一约束可以在建表的时候建好,也可以后面再补上-当创建好后,若表中有违反唯一约束的数据的时候会报错,需要清理
l 主键也是一种唯一约束
l 视图、触发器、函数、存储过程
唯一约束有哪些:
主键约束(ID)
添加主键:alter table ‘order’ add primary key (id)
单键唯一索引(orderid)
添加唯一索引:alter table ‘order’ add unique key idx_uk_orderid(orderid);
组合唯一索引(userid+orderid)
外键约束:外键指定两张表的数据通过某种条件关联起来
使用外键的注意事项:
必须是innodb表,myisam和其他引擎不支持外键
相互约束的字段类型必须要一样
主键的约束字段要求有索引
约束名称必须要唯一,即使不在一张表上
View视图
l 视图将一组查询语句构成的结果集,是一种虚拟结构,并不是实际数据
l 视图能简化数据库的访问,能够将多个查询语句结构化为一个虚拟结构
l 视图可以隐藏数据库后端表结构,提高数据库的安全性
l 视图也是一种权限管理,只对用户提供部分数据
Eg: create view order_view as select from ‘order’ where status=1;
Trigger触发器
Trigger俗称触发器,指可以在数据写入表A之前或者之后可以做一些其他动作
使用Trigger在每次更新用户表的时候触发更新积分表
Function函数-可以实习很大业务需求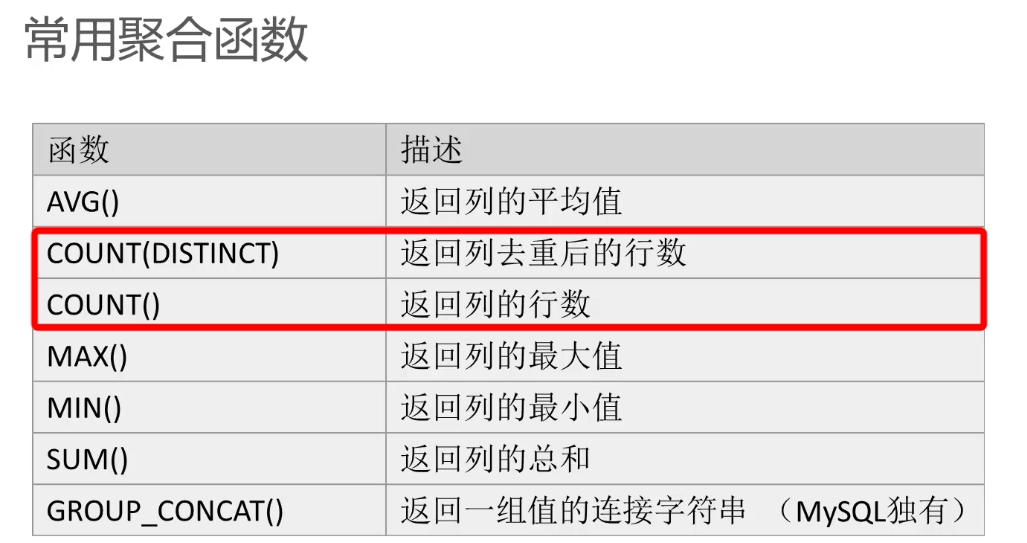
预定义函数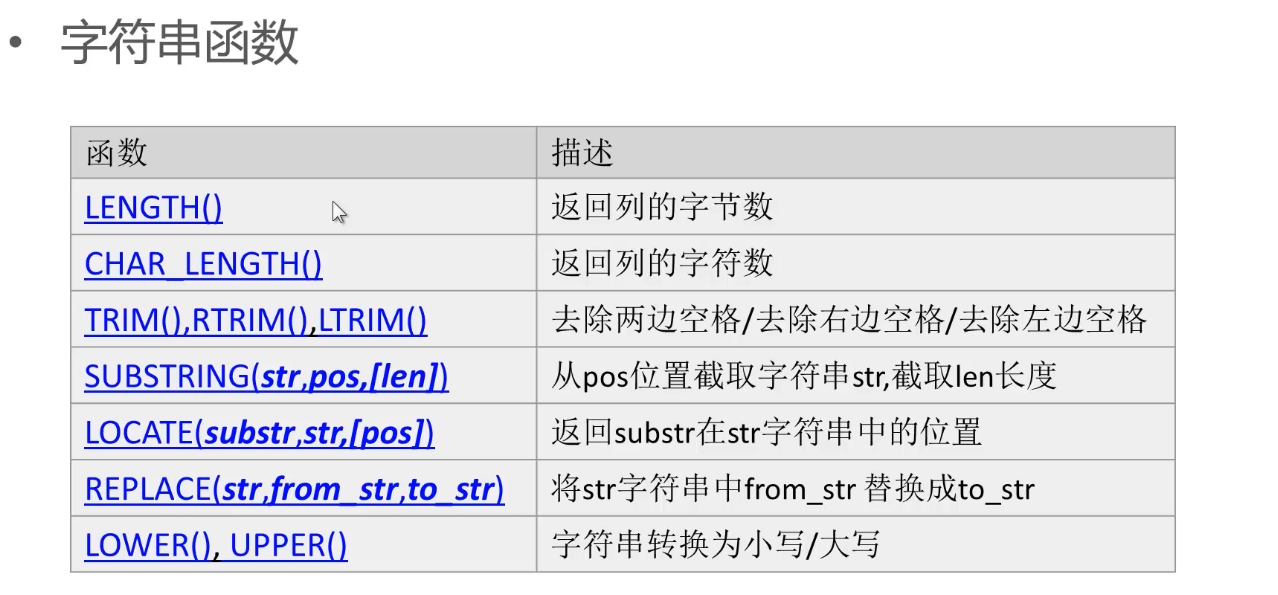
Procedure(存储过程)-可以包含很大判断逻辑
第三节MySQL权限管理
MySQL权限管理
MySQL赋权操作(grant)
权限粒度
Data Privileges
DATA(数据层次):select、insert、update、delete
Definition Privileges(应用于逻辑对象)
DateBase:create、alter、drop
Table:create、alter、drop
View/Function/Trigger/Procedure:create、alter、drop
Administrator Privileges(管理权限):
Shutdown DataBase
Replication Slave (搭建数据库主从结构)
Replication Client (搭建数据库主从结构)
File Privilege (文件权限)
MySQL权限验证流程
使用MySQL自带的命令,创建一个新用户并赋权
CREATE USER ‘netease’ @’localhost’ IDENTIFIED BY ‘netease163’; .
GRANT SELECT ON . TO ‘netease’ @’localhost’ WITH GRANTOPTION;
.:对这个数据库下的所有表赋权
Grant语句会判断是否存在该用户,如果不存在则新建,如果存在,会变成改密码
GRANT SELECT ON . TO ‘netease’ @’localhost’ IDENTIFIED BY
‘netease163’ WITH GRANT OPTION; .
查看用户权限信息:
Show grants:打印出当前用户的权限信息
Show grants for root@’localhost’;查看用户权限
如何更改用户的权限:
1. 回收不需要的权限
Revoke sekect from . on netease@’localhost’
2. 重新赋权
Grant inster on . to netease@’localhost’
更改用户的密码
1. 用新密码,grant语句重新赋权
2. 更改数据库记录,update user表的password字段
使用此方法需要flush privileges刷新权限信息,可能导致数据库无法连接
删除用户:drop user
With Grant Option-允许被授予权利的人把这个权力授予其他人
MySQL权限管理的秘密:
1. MySQL权限信息存储结构
MySQL权限信息是存储再数据库表中
MySQL账号对应的密码也加密存储在数据库表中
每种权限类型在源数据里都是枚举类型,表明是否有改权限
2. 权限相关的表
User表-存储用户名密码信息
Db表-存储库级别的信息
Tables_priv表-存储表级别的信息
Columns_priv-存储字段属性的信息
权限验证:
第一步:验证user表:select from mysql.user where user –‘netease’\G
第二部:验证db表:select from mysql.db where user =’netease’\G
第三部:验证table表:select from mysql.db where table =’netease’\G
第四部:验证表:select from mysql.db where columns =’netease’\G
小结:
MySQL权限信息都是以数据记录的形式存储在数据库表中的。
MySQL的权限验证相比网站登录验证多了白名单的环节,并且粒度更细们可以精确到表和字段。
使用Binary二进制安装管理用户没有设置密码
MySQL默认的test库不受权限控制,存在安全风险
权限相关的操作不要直接操作表,统一使用MySQL命令。
使用二进制安装MySQL后,需要重置管理用户(root)的密码。
线上数据库不要留test库。
*第二章 MySQL进阶SQL应用
第一节 SQL语言进阶
SQL语言进阶
1.SQL查询进阶语法
Order by:
用于根据指定的列对结果集进行排序,默认按照升序进行排序。
Distinct 去重数据:
distinct只能在select语句中使用
distinct必须在所有字段前面
如果有多个字段需要去重,则会对多个字段进行组合去重,即所有字段的数据重复才会被去重
SELECT DISTINCT <字段名>,<字段名>, FROM <表名>;
Like模糊查询:
Like的语法格式
LIKE ‘字符串’
NOT LIKE ‘字符串’
NOT:取反,不满足指定字符串时匹配
字符串:可以是精确的字符串,也可以是包含通配符的字符串
LIKE支持 % 和 两个通配符
Limit(限制查询结果的条数),offset初始位置
通过limit限制每次返回的数据量,可以有效减少查询时间和数据库压力
select from wsdbb-centos limit 2,2;
SELECT FROM wsdbb-centos LIMIT 5 OFFSET 150;
Case when用法
2.Join**连接与子查询*
连接-Join
Inner join 语法格式
SELECT <字段名> FROM <表1> INNER JOIN <表2> [ON子句]
inner join 可以连接 ≥ 两个的表
inner join 也可以使用 where 来指定连接条件,但是 inner join … on 是官方标准写法,而且 where 可能会影响查询性能
inner join 也可以只写 join 不加 inner
子查询:内层查询的结果作为外层的比较条件。一般子查询都可以转
换成连接,推荐使用连接。
select userid from play _fav where play id= (select id
from play. _list where play name =‘老男孩’ );
连接- left Join
LEFT JOIN从左表(play list) 返回所有的行,即使在右表(play fav) 中没有匹配的行。
select Ist.play name from play list Ist left join play favf on
Ist.id = f.play id where f.play id is null;
Union全连接
使用 union 连接的多条sql,每个 sql 查询出来的结果集的字段名称要一致
最终 union 连接查询的结果集的字段顺序会以第一个 sql 查出来结果集的字段顺序为基准
ALL:可选参数,返回所有结果集,包含重复数据
distinct:可选参数,删除结果集中重复的数据
3.DML进阶语法
l 多值插入: insert into table value (…),(…)
Insert主键重复则update
Insert into A values(2,40) on duplicate key update age=40;
l 覆盖插入: replace into table values (…)
l 忽略插入: insert ignore into table values (…)
l 查询插入: insert into table_ a select from table_ b
总结:
Select查询进阶语法
order by/distinct/group by having (聚合函数) /like ( %前缀后缀)
连接语法
内连接、左连接、右连接、Union [ALL]
DML进阶语法
Insert/连表update/连表delete
第二节 内置函数
内置函数
1.聚合函数
聚合函数面向一组数据,对数据进行聚合运算后放回单一的值
MySQL聚合函数基本语法:select function(列)from表
常用聚合函数:
| 函数 | 描述 |
|---|---|
| AVG() | 返回列的平均值 |
| COUNT(DISTINCT) | 返回列去重后的行数 |
| COUNT() | 返回列的行数 |
| MAX() | 返回列的最大值 |
| MIN() | 返回列的最小值 |
| SUM() | 返回列的总和 |
| GROUP_CONCAT() | 返回一组值得连接字符串(MySQL独有) |
select count() from song. list;
select count(1) from song. list;
select count(song. .name) from song. list;
count(“)和count(1)基本- 样。没有明显的性能差异
count()和count(song. name)差别在于count(song. name)会除去song. name is null的情
Groupconat(..)结合group by 来使用,进行显示
select album,group concat(song_ name) list
from song. _list group by album;
使用聚合函数做数据库行列转换:
实例:
select user,
|max(case when key’ = ‘age’ then value end) age,
max(case when “key’ =’sex’ then value end) sex,
max(case when “key = ‘dep’ then value end) dep
from tbl _testl
group by user;
2.预定义函数:
可以作为选择条件
预定义函数面向单值数据,返回- -对一-的处理结果(聚合函数可以理解成多对一)。
预定义函数基本语法:
SELECT function(列) FROM表
SELECT FROM表where列= function(value).
字符串函数:
| 函数 | 描述 |
|---|---|
| LENGTHO | 返回列的字节数 |
| CHAR LENGTHO | 返回列的字符数 |
| TRIMO(),RTRIMO(),LTRIM() | 去除两边空格/去除右边空格/去除左边空格 |
| SUBSTRING(str pos,(len) | 从pos位置截取字符事立截取len长度 |
| LOCATE(substr.str,[pos]) | 返回substr在str字符串中的位置 |
| REPLACE(str,from ,str, to_str) | 将str字符串中from str 替换成to_str |
| LOWER(), UPPER() | 字符串转换为小写/大写 |
实例:substring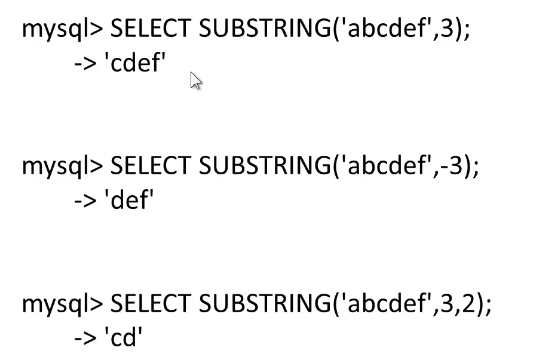
Locate:
时间处理函数:
| 函数 | 描述 |
|---|---|
| CURDATE() | 当前日期 |
| CURTIME() | 当前时间 |
| NOW() | 显示当前时间日期(常用) |
| UNIX_TIMESTAMP() | 当前时间戳 |
| DATE_FROMAT(date,format) | 按指定格式显示时间 |
| DATEA_ADD(date,INTERVAL UNIT) | 计算指定日期向后加一段时间的日期 |
| DATE_SUB(date,INTEERVAL unit) | 计算指定日期向前减去一段时间的日期 |
时间日期运算:
date + INTERVAL expr unit
date - INTERVAL expr unit
DATE ADD(date,INTERVAL expr unit)
DATE SUB(date,INTERVAL expr unit)
数字处理函数:
| 函数 | 描述 |
|---|---|
| ABS() | 返回数值的绝对值 |
| CEIL() | 对小数向上取整CELL(1.2)=2 |
| ROUND() | 四舍五入 |
| POW(num,n) | Num的n次幂POW(2,2)=2 |
| Floor() | 对小数向下取整CELL(1.2)=1 |
| MOD(n,m) | 取模(放回n除以m的余数)=N%M |
| RAND() | 取0~1之间的一个随机数 |
3.算数,逻辑运算
比较运算:
Is true 判定真假 is not false 判断值是否为空 is null判断值是否为空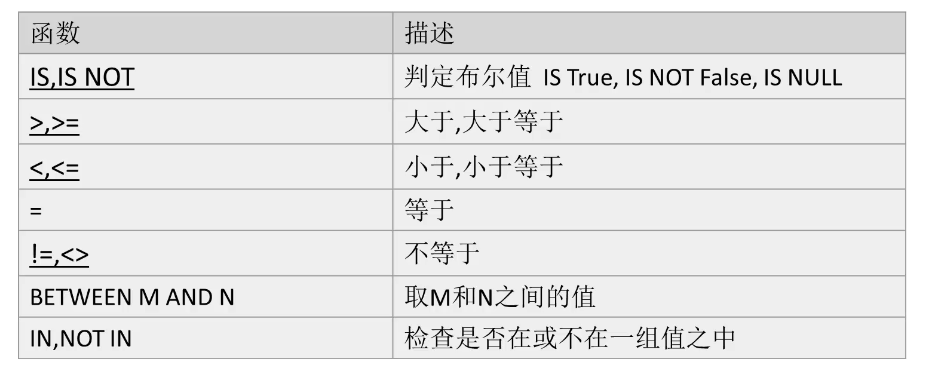
第三节 触发器与存储过程
触发器与存储过程
目标:掌握触发器与存储过程的基本语法,可以用触发器、存储过程、自定义函数完成常见的业务需求。
1. 触发器
触发器是加在表上的一个特殊程序,当表上出行特定的事件(INSERT/UPDATE/DELETE)时触发该程序执行。
可以进行数据订正;迁移表;实现特定的业务逻辑。
触发器基本语法:
CREATE
[DEFINER = { user | CURRENTUSER }]
TRIGGER trigger_name
trigger_time trigger_event
ON tbl_name FOR EACH ROW
[trigger_order]
trigger_body
trigger_time: { BEFORE | AFTER }
trigger_event: { INSERT | UPDATE | DELETE }
trigger_order: { FOLLOWS | PRECEDES } other_trigger_name
触发器对性能有损耗,应慎重使用。
l 同一类事件在一一个表中只能创建一-次。
l 对于事务表 ,触发器执行失败则整个语句回滚。
l Row格式主从复制 ,触发器不会在从库上执行。
l 使用触发器时应防止递归执行。
2. 存储过程
定义:
存储过程是存储在数据库端的一组SQL语句集。用户可以通过存储过程名和传参多次调用的程序模块。
特点:
l 使用灵活 ,可以使用流控制语句、自定义变量等完成复杂的业务逻辑。
l 提高数据安全性,屏蔽应用程序直接对表的操作.易于进行审计。
l 减少网络传输。
l 提高代码维护的复杂度,实际使用中要评估场景是否适合。
存储过程基本语法:

存储过程-流控制语言
3. 自定义函数-带返回值
自定义函数与存储过程类似,但是必须带有返回值( RETURN )。
自定义函数与sum(),max()等MySQL原生函数使用方法类似:
SELECT func(val);
SELECT from tbl where col=func(val);
由于自定义 函数可能在遍历数据中使用,要注意性能损耗。
小结:
互联网场景:触发器和存储过程不利于水平扩展,多用于统计和运维操作中。
触发器和存储过程都是在数据库端执行的-数据库端计算压力大-大多应用在统计和运维操作中。
第四节 实践课 SQL进阶应用
SQL应用
*第三章 MySQL程序开发
第一节 MySQL字符集
理解掌握字符集的基础知识和使用方法,具备处理常见字符集问题的能力
1.MySQL字符集
数据库中的字符集包括两层含义:
各种文字和符号的集合,包括各国家文字、标点符号、图形符号、数字等。
字符的编码方式,即二进制数据与字符的映射规则。
字符集分类:
l ASCII :美国信息互换标准编码;英语和其他西欧语言;单字节编码,7位( bits )表示一个字符,共128字符。
l GBK:汉字内码扩展规范;中日韩汉字、英文、数字;双字节编码;共收录了21003个汉字, GB2312的扩展。
l UTF-8: Unicode标准的可变长度字符编码; Unicode标准(统- -码) , 业界统一标准,包含世界上数十种文字的系统; UTF-8使用一至四个字节为每个字符编码。
l 其他常见字符集: UTF-32 , UTF-16 , Big5,latin1
2.MySQL字符集与字符序
MySQL字符集:
Show character set —查看字符集
字符集与字符序(charset和collation)
Collation:字符序、字符的排序与比较规则,每个人字符集都有对应的多套字符序。
不同的字符序决定了字符串在比较排序中的精度和性能不同。
MySQL的字符序遵从命名惯例:以_ci(表示大小写不敏感),以_cs(表示大小写敏感),以_bin(表示用编码值进行比较)。MySQL默认情况下是以_ci结尾
3.字符集设置级别-(默认使用服务器字符集)
charset 和collation的设置级别:
服务器级>>数据库级>>表级>>列级
服务器级
系统变量(可动态设置) :
- character set server :默认的内部操作字符集。
- character set system :系统元数据(字段名等)字符集
服务器级:
配置文件设置:
[mysqld]
cha racter set server-utf 8
collation server=utf8 general ci
数据库级:CREATE DATABASE dbname CHARACTER SET latin1 COLLATE latin1_swedish_ci ;
数据存储字符集使用规则:
l 使用列集的CHARACTER SET设定值;
l 若列级字符集不存在,则使用对应表级的DEFAULT CHARACTER SET设定值;
l 若表级字符集不存在,则使用数据库级的DEFAULT CHARACTER SET设定值;
l 若数据库级符集不存在,则使用服务器级character. set _server设定值。
4.客户端字符集
连接与字符集:
l character set client :客户端来源数据使用的字符集。
l character. _set connection :连接层字符集。
l character set results :查询结果字符集。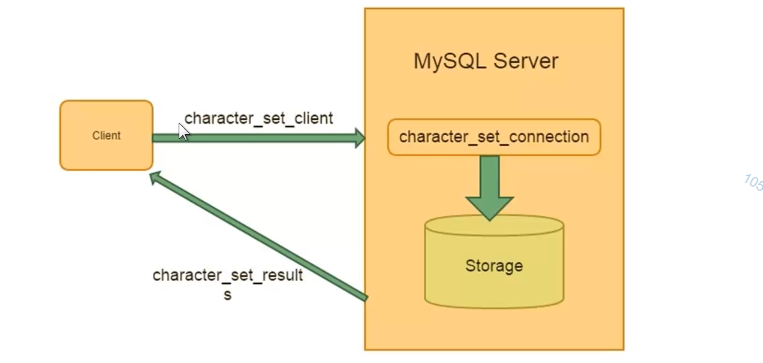
常见乱码原因:
l 数据存储字符集不能正确编码(不支持) client发来的数据:
client ( utf8 ) > storage ( latin1 )
l 程序连接使用的字符集与通知mysql的character set .client等不一致或不兼容。
第二节 程序连接MySQL
程序连接MySQL
1.程序连接MySQL基本原理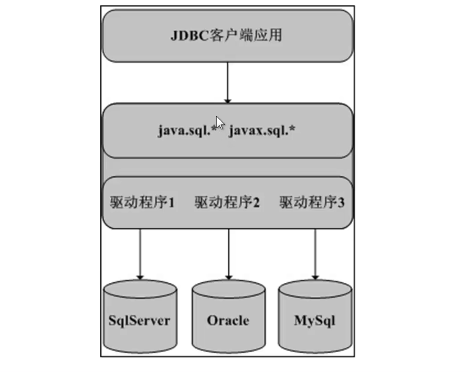
3. JAVA连接代码示例
结构:
DriverManager
Dirver(是驱动程序对象的接口,指向具体数据库驱动程序对象=DriverManager.get分iver(String URL))
Connection(是连接对象接口,指向具体数据库连接对=Drivermanager.getConnection(String URL))
Statement(执行静态SQL语句接口,=Connection.CreateStatement())
ResultSet(是指向结果集对象的接口,=Statement.excuteXXX())
4. JDBC使用技巧
1. Statement与PreparedStatement的区别。
l PreparedStatement 在数据库端预编译,效率高,可以防止SQL注入。
l 对数据库只执行一次性存取的时侯,用Statement对象进行处理。
l 线上业务推荐使用PreparedStatement。
2. connection,Statement与ResultSet关闭的意义。
l MySQL数据库端为connection、ResultSet维护内存状态,一直不关闭会占用服务端资源。
l MySQL最大连接数受max_connections限制,不能无限创建连接,所以用完要及时关闭。
l JDBC connection关闭后ResultSet .Statement会自动关闭。但是如果使用连接池将不会关闭,因此推荐主动关闭。
3. jdbc连接参数的使用。
字符集设置
超时设置
4. ResultSet游标的使用(setFetchSize )
l 默认的 ResultSet对象不可更新,仅有一个向前移动的指针。因此,只能迭代它一次,并且只能按从第一行到最后一行的顺序进行。可以生成可滚动和/或可更新的ResultSet对象。
l setFetchSize()
是设置ResultSet每次向数据库取的行数,防止数据返回量过大将内存爆掉。
5. Python连接MySQL
Python脚本语言,无需编译、易开发
DBA使用Python的一般场景是编写自动化运维工具、报表、数据迁移
ython MySQL驱动: python-mysqldb
Linux安装驱动:
~#apt-get install python-mysqldb
第三节DAO框架的使用
DAO框架的使用
1. DAO框架
原理图:
DAO模式是标准J2EE 设计模式之一。开发人员用这种模式将底层数据访问操作与高层业务逻辑分离开。一个典型的DAO框架实现有以下组件:
l 一个DAO工厂类
l 一个DAO接口( select/insert/delete/update)
l 一个实现了DAO 接口的具体类
l 数据传输对象
DAO框架的特点:
l 屏蔽底层数据访问细节,实现业务逻辑和数据访问逻辑的分离。
l 简化代码开发,提高代码复用率。
l 相较原生的SQL可能会带来额外的性能损耗(利用反射机制封装对象,sql转换等)
2. MyBatis简介
l 接口丰富、使用简单。
l 相较于hibernate更加轻量级,支持原生的sql语句。
l 支持查询缓存。
3.MyBatis-工作流程
(1)加载配置并初始化,内部生成MappedStatement对象。
(2)调用MyBatis提供的API ( SqlSession.select/insert…..),将
SQL ID与数据对象传递给处理层。
(3)处理层解析MappedStatement对象,获取MySQL的连接,
执行相应SQL语句,接收返回结果。
(4)MyBatis将接收到的返回结果封装成对应的数据对象返回。

若有收获,就点个赞吧
0 人点赞
