第一章 数据库事务
第一节数据库事务
1. 什么是事务
一系列有序的数据库操作:
l 要么全部成功.
l 要么全部回退到操作前状态.
l 中间状态对其他连接不可见.
事务的基本操作:
Start transaction;开始事务
Commit ;提交(全部完成)
Rollback;回滚(回到初始状态)
自动提交
autocommit可以在session级别设置
每个DML操作都自动提交
DDL永远是自动提交,无法通过rollback回滚
2. 2.事务的四个基本属性(ACID)
l 原子性(Atomicity)
包含在事务中的操作要么全部被执行,要么都不执行。
中途数据库或应用发生异常,未提交的事务都应该被回滚。
l —致性(Consistency)
数据的正确性,合理性,完整性
数据一致性应该符合应用需要规则:
余额不能是负数?
交易对象必须先有账号?
用户账号不能重复?
事务的结果需要满足数据的一致性约束
l 隔离性(Isolation)
数据库事务在提交完成前,中间的任何数据变化对其他的事务都是不可见的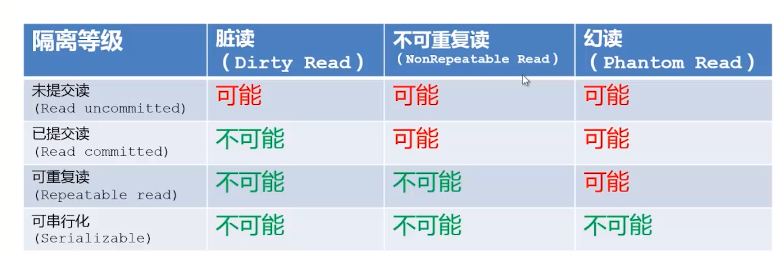
l 持久性(Durability)
提交完成的事务对数据库的影响必须是永久性的
数据库异常不会丢失事务更新
通常认为成功写入磁盘的数据即为持久化成功
3.MySQL的事务隔离级别
l InnoDB默认标记为可重复读(Repeatable read)
l InnoDB并不是标准定义上的可重复读
l InnoDB默认在可重复读的基础上避免幻读
4.MySQL事务隔离级别设置
l 可在global/session/下个事务,级别分别进行设置
l 建议使用Read committed(同oracle)
l 或者建议使用默认的Repeatable read
5.事务与并发写
某个正在更新的记录在提交或回滚前不能被其他事务同时更新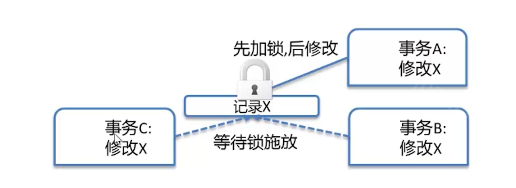
6.事务回滚的实现
回滚段(rollback segment)与数据前像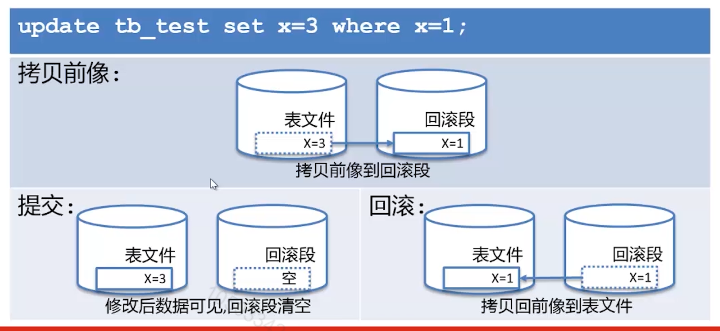
第二章 MySQL存储引擎
第一节 存储引擎描述
MySQL程序层次架构
内存实例
存储引擎——分为服务层
——存储引擎层
1. 什么是MySQL的存储引擎
服务层——接收消息
存储引擎层——数据源存储记录
有多种可选方案,可插拔,可修改存储引擎。
2. 介绍MySQL主要存储引擎的特点及适用场景
l InnoDB存储引擎
索引组织表
支持事务
支持行级锁
数据块缓存
日志持久化
稳定可靠,性能好,线上请尽量使用InnoDB
l MyISAM存储引擎
堆表
不支持事务
只维护索引缓存池,表数据缓存交给操作系统
锁粒度较大
数据文件可以直接拷贝,偶尔可能会用上
不建议线上业务数据使用,写锁力度大,并发性非常差
MEMORY存储引擎
l 数据全内存存放,无法持久化
l 性能较高
l 不支持事务
l 适合偶尔作为临时表使用
l create temporary table tmp (id int) engine = memory ;
BLACKHOLE存储引擎
l 数据不作任何存储
l 利用MySQL Replicate,充当日志服务器
l 在MySQL Replicate环境中充当代理主
TokuDB
l 分形树存储结构
l 支持事务
l 行锁
l 压缩效率较高
l 适合大批量insert的场景
MySQL Cluster
l 多主分布式集群
l 数据节点间冗余,高可用
l 支持事务
l 设计上易于扩展
l 面向未来,线上慎用
第二节InnoDB存储引擎
1. lnnoDB存储引擎架构
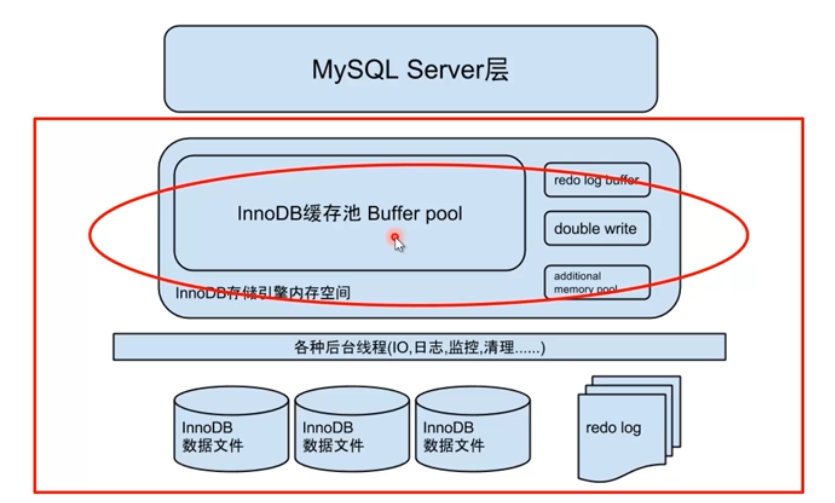
2. InnoDB系统表空间文件
l ibdata1里存放什么:
l 回滚段
l 所有InnoDB表元数据信息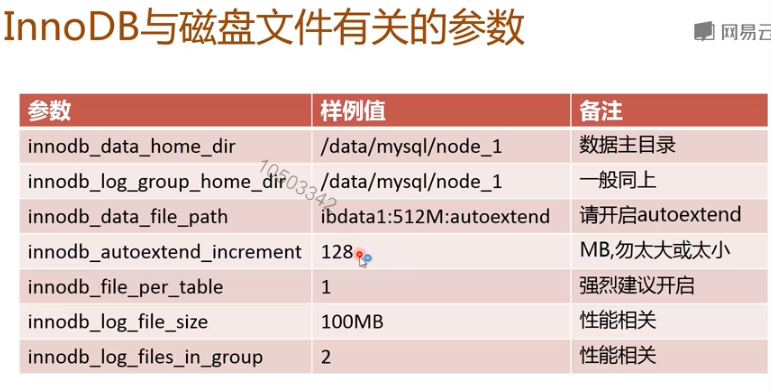
l Double Write,Insert buffer dump等等
自动扩展机制
3. InnoDB数据文件存储结构
l 索引组织表(聚簇表)—一颗平衡二叉树
l 根据表逻辑主键排序
l 数据节点每页16K
4. InnoDB数据文件存储结构
根据主键寻址速度很快
主键值递增的insgrt插入效率较好
主键随机insert插入操作效率差
因此,InnoDB表必须指定主键,建议使用自增数字
5. InnoDB数据块缓存池
l 数据的读写需要经过缓存
l 数据以整页(16K)为单位
l 读取到缓存中
l 缓存中的数据以LRU策略换出
l IO效率高,性能好
6. InnoDB数据持久化与事务日志
l 事务日志实时持久化
l 内存变化数据(脏数据)增
l 量异步刷出到磁盘
l 实例故障靠重放日志恢复
l 性能好,可靠,恢复快
INnoDB日志持久化相关参数:innodb_flush_log_at_trx_commit
设置为:
0:每隔1s写入并持久化一次日志
1:每次commit都写入并持久化日志
2:每次提交日志写到内存,每1s持久化一次
7. InnoDB行级锁
l 写不阻塞读
l 不同行间的写互相不阻塞
l 并发性能好
8. InnoDB与事务ACID
事务ACID特性完整支持
l 回滚段失败回滚 (A)
l 支持主外键约束 (C)
l 事务版本+回滚段=MVCC (I)
l 事务日志持久化 (D)
默认可重复读隔离级别,可以调整
第三节InnoDB事务锁
1. 什么是数据库锁
分为两大类:
| lock | Latch/mutex | |
|---|---|---|
| 对象 | 事务 | 线程 |
| 保护 | 数据库逻辑内容 | 内存数据结构 |
| 持续时间 | 事务过程中部 | 临界资源争抢 |
事务锁粒度
行锁
InnoDB,Oracle
页锁
.SQL Server
表锁
MyISAM,Memory
锁升级
2. InnoDB锁机制
InnoDB存储引擎中的锁模式与粒度
四种基本锁模式
l 共享锁(S)–读锁-行锁
l 排他锁(X)一写锁-行锁
l 意向共享锁(IS)-表级
l 意向排他锁(IX)一表级
意向锁
l 意向锁总是自动先加,并且意向锁自动加自动释放
l 意向锁提示数据库这个session将要在接下来将要施加何种锁
l 意向锁和X/S锁级别不同,除了阻塞全表级别的X/S锁外其他任何锁
3. InnoDB锁实现与注意事项
通过索引项加锁实现
l 只有条件走索引才能实现行级锁
l 索引上有重复值,可能锁住多个记录
l 查询有多个索引可以走,可以对不同索引加锁
l 是否对索引加锁实际上取决于MySQL执行计划
自增主键做条件更新,性能最好
InnoDB的gap lock
什么是幻读
gap lock消灭幻读
InnoDB消灭幻读仅仅为了确保statement模式replicate的主从一致性
小心gap lock
自增主键做条件更新,性能最好
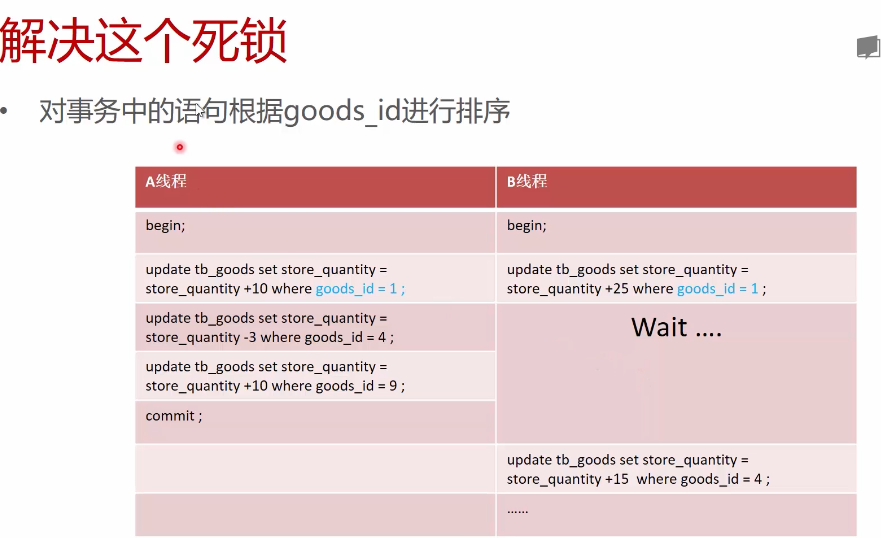
4. 死锁
事务进入等待
死锁数据库自动解决
数据库挑选冲突事务中回滚代价较小的事务回滚
死锁预防
单表死锁可以根据批量更新里的更新条件排序
可能冲突的跨表事务尽量避免并发
尽量缩短事务长度
死锁完全不是数据库的问题,是应用程序的问题
5. 什么时候需要事务和锁
l 需要保证操作”原子性”
l 需要利用”锁”避免业务纠纷
l 选购商品操作中的事务和锁:
-查询库存→更新订单→扣除库存,需要原子性
-查询库存判断有充足商品后直到扣除库存成功前;一般不希望库存再生变化,
因此查询库存的时候经常for update人工加锁
悬挂事务与锁超时的排查
l 查看数据库中尚未提交的innodb活跃事务
l select trx_mysql_thread_id, trx_state, now() - trx_started, trx_rows_locked from information_schema.INNODB_TRX;
l MySQL中比较难知道正在持有锁的SQL语句的具体内容
l 和开发合作排查相关线上问题

若有收获,就点个赞吧
0 人点赞
