socket fd 长什么样子?
什么是 socket fd ?粗糙的来讲,就是网络 fd,比如我们最常见的 C/S 客户端服务端的编程模式,就是网络通信的一种方式。撇开底层和协议细节,网络通信和文件读写从接口上有本质区别吗?
其实没啥区别,不就是读过来和写过去嘛,简称 IO 。
我们先看一下 socket fd 是什么样子的?随便找了个进程
root@ubuntu:~# ll /proc/1583/fdtotal 0lrwx------ 1 root root 64 Jul 19 12:37 7 -> socket:[18892]lrwx------ 1 root root 64 Jul 19 12:37 8 -> socket:[18893]
这里我们看到 fd 7、8 都是一个 socket fd,名字:socket:[18892]
整数句柄后面一般会跟一些信息,用于帮助我们了解这个 fd 是什么。举个例子,如果是文件 fd,那么箭头后面一般是路径名称。现在拆解一下这个名字:
- socket :标识这是一个 socket 类型的 fd
[18892]:这个是一个 inode 号,能够唯一标识本机的一条网络连接;
思考下,这个 inode 号,还能再哪里能看到呢?
在 proc 的 net 目录下,因为我这个是一个走 tcp 的服务端,所以我们看一下 /proc/net/tcp 文件。这个文件里面能看到所有的 tcp 连接的信息。
root@ubuntu:~# grep -i "18892" /proc/net/tcp18: 00000000:1F93 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0 0 18892 1 ffff880197fba580 100 0 0 10 0root@ubuntu:~# grep -i "18893" /proc/net/tcp28: 00000000:1F7C 00000000:0000 0A 00000000:00000000 00:00000000 00000000 0 0 18893 1 ffff880197fbad00 100 0 0 10 0
知识点又来了,/proc/net/tcp 这个文件记录了 tcp 连接的信息,这份信息是非常有用的。包含了 TCP 连接的地址(16进制显示),inode 的信息,连接的状态等等。
socket fd 是什么?
环境声明:
Linux 内核版本 4.19
为了方便,如果没特意说明协议,默认 TCP 协议;
socket 可能你还没反应过来,中文名:套接字 是不是更熟悉点。Linux 网络编程甚至可以叫做套接字编程。
有些概念你必须捋一捋 。我们思考几个小问题:
socket 跟 tcp/ip 有什么区别?
就不该把这两个东西放在一起比较讨论,就不是一个东西。tcp/ip 是网络协议栈,socket 是操作系统为了方便网络编程而设计出来的编程接口而已。
理论基础是各种网络协议,协议栈呀,啥的。但是如果你要进行网络编程,落到实处,对程序猿来讲就是 socket 编程。
对于网络的操作,由 socket 体现为 open -> read/write ->close 这样的编程模式,这个统一到文件的一种形式。
socket 的 open 就是
socket(int domain, int type, int protocol),和文件一样,都是获取一个句柄。
网络抽象层次
网络模型一般会对应到两种:
- 完美理论的 OSI 七层模型;
- 现实应用的 5 层模型;
对应关系如下图(取自 Unix 套接字编程)
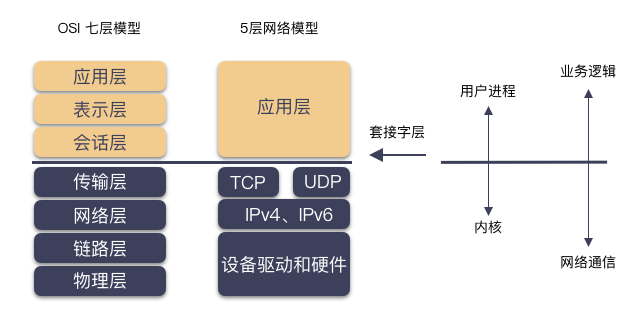
不同层次做不同的事情,不断的封装,不断的站在巨人的肩膀上,你将能做的更多。
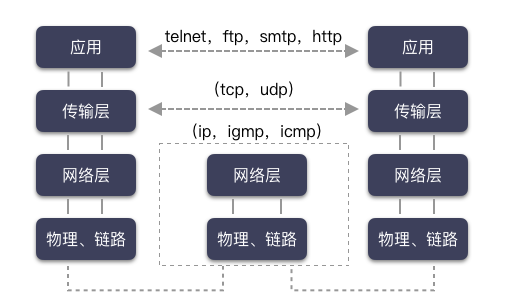
今天,奇伢剖析的只聚焦在套接字这一层,这是程序猿摸得到的一层,位于所有网络协议之上的一层封装,网络编程又叫套接字编程,这并不是空穴来风。
套接字,是内核对贼复杂的网络协议栈的 API 封装,使得程序猿能够用极简的姿势进行网络编程。比如写一个基于 Tcp 的 C/S 的网络程序,需要用到啥?我们大概畅想下:
- 客户端和服务端都用
socket调用创建套接字; - 服务端用
bind绑定监听地址,用listen把套接字转化为监听套接字,用accept捞取一个客户端来的连接; - 客户端用
connect进行建连,用write/read进行网络 IO;
程序猿用着好简单!因为内核把事扛了。
socket fd 的类型
上面我们提到了套接字,这是我们网络编程的主体,套接字由 socket() 系统调用创建,但你可知套接字其实可分为两种类型,监听套接字和普通套接字。而监听套接字是由 listen() 把 socket fd 转化而成。
1. 监听套接字
对于监听套接字,不走数据流,只管理连接的建立。accept 将从全连接队列获取一个创建好的 socket( 3 次握手完成),对于监听套接字的可读事件就是全连接队列非空。对于监听套接字,我们只在乎可读事件。
2. 普通套接字
普通套接字就是走数据流的,也就是网络 IO,针对普通套接字我们关注可读可写事件。在说 socket 的可读可写事件之前,我们先捋顺套接字的读写大概是什么样子吧。
套接字层是内核提供给程序员用来网络编程的,程序猿读写都是针对套接字而言,那么 write( socketfd, /* 参数 */) 和 read( socketfd, /* 参数 */) 都会发生什么呢?
- write 数据到 socketfd,大部分情况下,数据写到 socket 的内存 buffer,就结束了,并没有发送到对端网络(异步发送);
- read socketfd 的数据,也只是从 socket 的 内存 buffer 里读数据而已,而不是从网卡读(虽然数据是从网卡一层层递上来的);
也就是说,程序猿而言,是跟 socket 打交道,内核屏蔽了底层的细节。
那说回来 socket 的可读可写事件就很容易理解了。
- socketfd 可读:其实就是 socket buffer 内有数据(超过阈值 SO_RCLOWAT );
- socketfd 可写:就是 socket buffer 还有空间让你写(阈值 SO_SNDLOWAT );
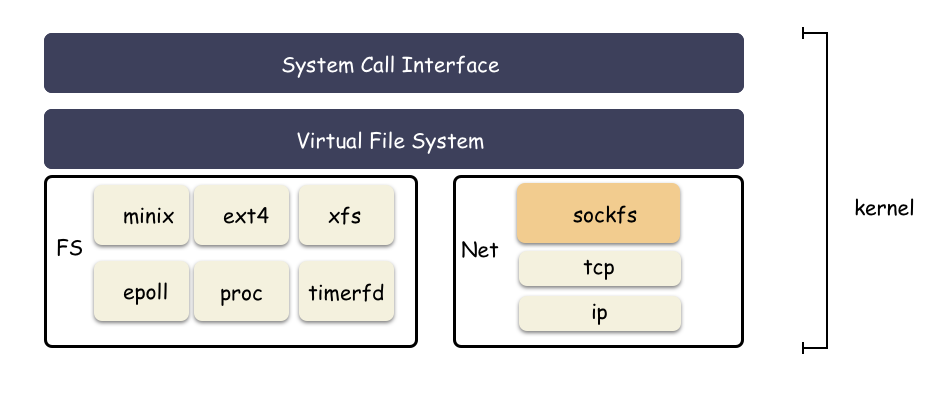
sockfs 文件系统
socket fd 为什么能具备“文件”的语义,从而和 eventfd,ext2 fd 这样的句柄一样,统一提供对外 io 的样子?
核心就是:sockfs ,这也是个文件系统,只不过普通用户看不见,这是只由内核管理的文件系统,位于 vfs 之下,为了封装 socket 对上的文件语义。
// net/socket.cstatic int __init sock_init(void){// 注册 sockfs 文件系统err = register_filesystem(&sock_fs_type);// 内核挂载sock_mnt = kern_mount(&sock_fs_type);}
其中最关键的是 sock_mnt 这个全局变量里面的超级块的操作表 sockfs_ops 。
// net/socket.cstatic const struct super_operations sockfs_ops = {.alloc_inode = sock_alloc_inode,.destroy_inode = sock_destroy_inode,.statfs = simple_statfs,};
这个是每个文件系统的核心函数表,如上指明了 inode 的分配规则(这里又将体现依次结构体内嵌组合+类型强转的应用)。
读者朋友还记得 inode 和 ext4_inode_info 的关系吗?在 Linux fd 究竟是什么?一文中有提到这个:
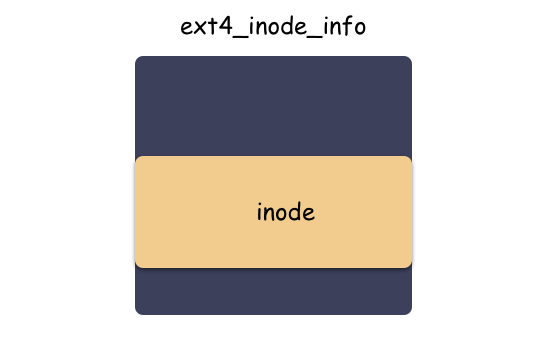
inode 是 vfs 抽象的适配所有文件系统的结构体,但分配其实是有下层具体文件系统分配出来的,以 ext4 文件系统来说,使用 ext4_alloc_inode 函数分配出 ext4_inode_info 这个大结构体,然后返回的是 inode 的地址而已。
划重点:**struct inode** 内嵌于具体文件系统的 “inode” 里,vfs 层使用的是 inode,ext4 层使用的是 **ext4_inode_info** ,不同层次通过地址的强制转化类型来切换结构体。
那么类似,sockfs 也是如此,sockfs 作为文件系统,也有自己特色的 “inode”,这个类型就是 struct socket_alloc ,如下:
struct socket_alloc {struct socket socket;struct inode vfs_inode;};
这个结构体关联 socket 和 inode 两个角色,是“文件”抽象的核心之一。分配 struct socket 结构体其实是分配了 struct socket_alloc 结构体,然后返回了 socket_alloc->socket 字段的地址而已。
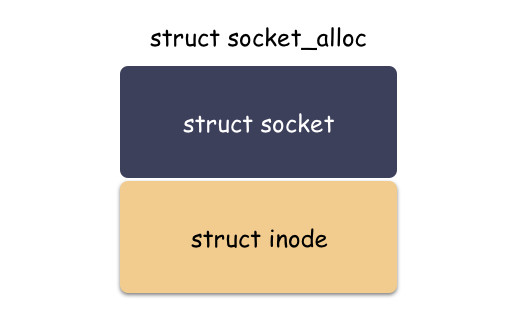
划重点:vfs 层用的时候给 inode 字段的地址,socket 层的时候给 socket 字段的地址。不同抽象层面对于同一个内存块的理解不同,强制转化类型,然后各自使用
从文件的角度来看 socket,模块如下:
回调唤醒的通用做法?
先铺垫一个小知识点:内核里面有回调唤醒的实现,里面有用到一种 wait queue 的做法,其实很简单的原理。
大白话原理:你要走可以,把联系方式留下,我搞好之后通知你(调用你留下的函数,传入你留下的参数)。
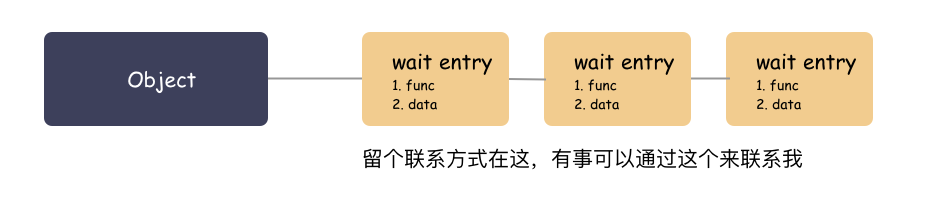
拿 socket 来说,struct sock 里面就有个字段 sk_wq ,这是个表头,就是用来挂接等待对象的。
谁会挂?
就以 epoll 池来说,epoll_ctl 注册 socket fd 的时候,就会挂一个 wait 对象到 sk->sk_wq 里。回调参数为 ep_poll_callback ,参数为 epitem 。
这样 epoll 给 socket 留下联系方式了( wait 对象 ),socket 有啥事就可以随时通知到 epoll 池了。
能有什么事?
socket 可读可写了呗。sk buffer 里面有数据可以读,或者有空间可以写了呗。对于监听类型的 socket,有新的连接了呗。epoll 监听的不就是这个嘛。
socket 编程 ?
服务端:
socket( )创建出 socketfd;bind( )绑定一个端口(和客户端约定好的知名端口号);listen( )讲套接字转化成监听套接字;accept( )等待客户端的建连请求;- 建连之后 read/write 处理数据即可(一般和监听线程并发);
客户端:
socket( )创建出 socketfd;connect( )向指定机器、端口发起建连请求;- 建连之后,read/write 处理数据;
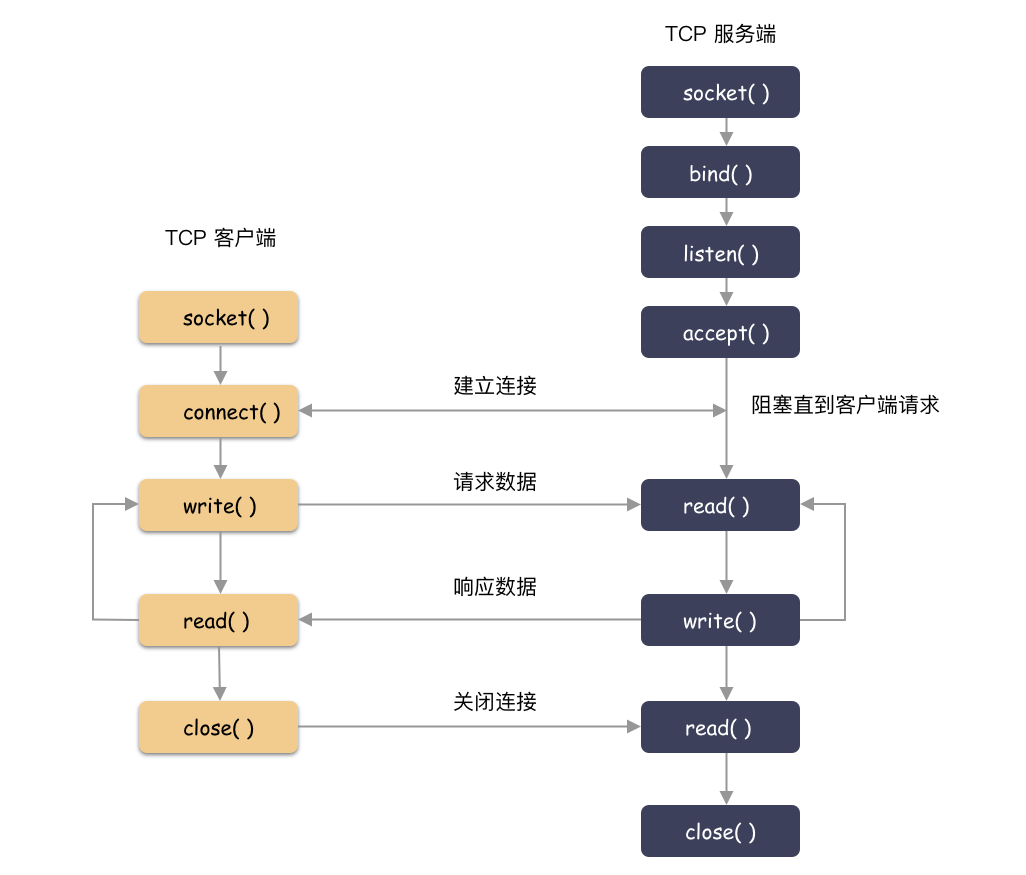
下面就几个关键函数做个简要实现。
1. socket 函数
定义原型:
#include<sys/socket.h>int socket(int family, int type, int protocol)
简要跟踪下内部实现:
socket 系统调用对应了 __sys_socket 这个函数。这个函数主要做两件事情:
- 第一件事:调用
socket_create函数创建好 socket 相关的结构体,主要是struct socket,还有与之关联的socket sock结构,再往下就是具体网络协议对应的结构体(旁白:这里实现细节过于复杂,不在文章主干,故略去 10 万字); - 第二件事:调用
sock_map_fd函数创建好struct file这个结构体,并与第一步创建出的struct socket关联起来;
涉及的一些函数调用:
__sys_socket// 创建 struct socket 结构体-> sock_create// 创建 struct socket 结构,并且关联特殊 inode-> sock_alloc// pf 是根据 family 从 net_families 这个全局表中取出的操作函数表,用来创建具体网络协议结构的;// 比如 IPv4 对应的 family 就是 AF_INET ,对应的函数是 inet_create// 在这里面会赋值 sock->ops 为对应协议族的操作函数表(比如 inet_stream_ops)-> pf->create// struct sock 结构体的创建(sk->sk_prot 的赋值就在这里,比如 tcp_prot )-> sk_alloc// struct sock 结构体的初始化(比如 sk_receive_queue, sk_write_queue, sk_error_queue 就是在这里初始化的)// 可读写的关键函数 sock_def_readable,sock_def_write_space 也是在这里赋值的-> sock_init_data// 创建 struct file 结构体,并且关联 struct socket-> sock_map_fd
先说 socket 函数::
socket( )函数只负责创建出适配具体网络协议的资源(内存、结构体、队列等),并没有和具体地址绑定;socket( )返回的是非负整数的 fd,与struct file对应,而struct file则与具体的struct socket关联,从而实现一切皆文件的封装的一部分(另一部分 inode 的创建处理在 sock_alloc 的函数里体现);
再简要说下内部细节:
sock_create 函数里,会根据协议族查找对应的操作表,以 AF_INET 协议族举例,pf->create 是 inet_create ,主要做两件事:
- 把
sock->ops按照协议类型赋值成具体的函数操作表,比如 tcp 的就是inet_stream_ops; - 创建了
struct sock对象,并且把struct sock初始化,并和struct socket进行关联;
着重提一点,sock_init_data 函数( net/core/sock.c )主要是初始化 struct sock 结构体的,提两点最关键的:
第一点:接收队列和发送队列在这里初始化;
- sk_receive_queue:套接字接收到的数据(sk_buff 里面是纯粹的用户数据哦,没有 header 啥信息);
- sk_write_queue:套接字要发送的数据;
- sk_error_queue:挂接一些 pengding 的 error 信息;
第二点:socket 的唤醒回调在这个地方设置;
sk->sk_data_ready = sock_def_readable;sk->sk_write_space = sock_def_write_space;
为什么这里很重要,因为这个跟 socket fd 可读可写的判断逻辑,数据到了之后的唤醒路径息息相关。简述下回调链路(以套接字层为主干,其他的流程简略描述):
sk->sk_data_ready(数据到了,该通知留下过联系方式的人了)tcp_v4_rcv(具体协议栈处理函数)软中断硬中断
再说下结构体:
继续说 struct sock ,这个对象有意思了,这个也是以组合的方式往下兼容的,同一个地址强转类型得到不同层面的结构体。原理就在于:他们是一块连续的内存空间,起始地址相同。
sock -> inet_sock -> inet_connection_sock-> tcp_sock
示意图:
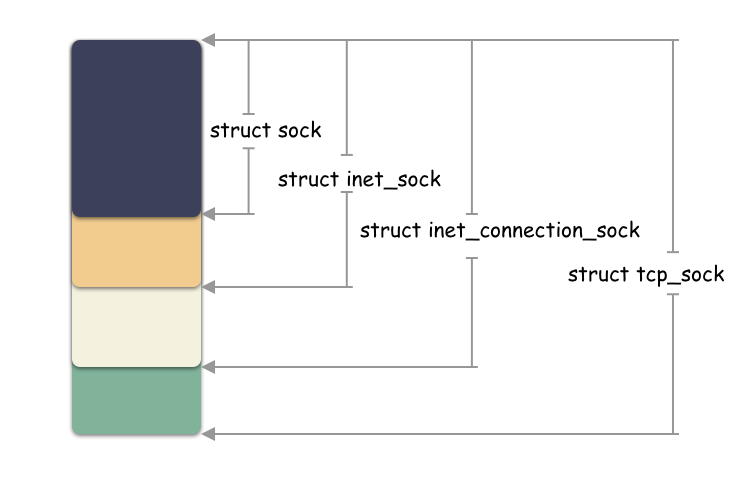
小思考:**struct socket** 和 **struct sock** 是两个不同的结构体?
是的。这两个是不同的结构体。属于套接字层的两个维度的描述,一个面向上层,一个面向下层。
struct socket 在内核的注释为:
struct socket - general BSD socket
struct sock 在内核的注释为:
struct sock_common - minimal network layer representation of sockets
struct socket 是内核抽象出的一个通用结构体,主要作用是放置了一些跟 fs 相关的字段,而真正跟网络通信相关的字段结构体是 struct sock 。它们内部有相互的指针,可以获取到对方的地址。
struct socket 这个字段出生的时候其实就和一个 inode 结构体伴生出来的,由 socketfs 的 sock_alloc_inode 函数分配。
struct sock 这个结构体是 socket 套阶字核心的结构(注意,还有个结构是 struct socket,这两个是不同的结构体哦)。这个是对底下具体协议做的一层抽象封装,比如在分配 struct sock 的时候,如果是 tcp 协议,那么 sk->sk_prot 会赋值为 tcp_prot ,udp 协议赋值的是 udp_prot ,之后的一系列协议解析和处理就是调用到对应协议的回调函数。
小思考:socket fd 可以和文件一样用 **write(fd, /\*xxxx\*/ )** 这行的调用,为什么?
write(fd, /*xxxx*/) 进到内核首先是到 vfs 层,也就是调用到 vfs_write ,在这个里面首先获取到 file 这个结构体,然后调用下层注册的回调,比如 file->f_op->write_iter ,file->f_op->write ,所以,关键在 file->f_op 这个字段,对吧?
现在的问题是,这个字段是啥呢?
这个字段在 file 结构体生成的时候,根据你的“文件”类型赋值的,这个在之前文件系统章节提过这个,比如 ext2 的文件,那么就是 ext2_file_operations ,socketfd 是 socket_file_ops。
vfs_write =>-> socket_file_ops (sockfs)-> ext2_file_operations (ext2)-> ext4_file_operations (ext4)-> eventfd_fops
可以看下 socket_file_ops 的定义:
static const struct file_operations socket_file_ops = {.llseek = no_llseek,.read_iter = sock_read_iter,.write_iter = sock_write_iter,.poll = sock_poll,// ...}
所以,vfs_write 调用到的将是 sock_write_iter,而这个里面就是调用到 sock_sendmsg ,从而走到网络相关的处理流程。
// sock_sendmsg 实际调用;static inline int sock_sendmsg_nosec(struct socket *sock, struct msghdr *msg){int ret = sock->ops->sendmsg(sock, msg, msg_data_left(msg));return ret;}
还记得上面在 socket 初始化的时候 socket->ops 和 sock->sk_prot 两个回调函数操作表的赋值吗( tcp ):
socket->ops=>inet_stream_opssock->sk_prot=>tcp_prot
这样从 vfs 进来,转接到具体的协议处理模块去了。
2. bind 函数
对应内核 __sys_bind 函数,做的事情很简单:
- 先通过 fd 找到对应的
struct socket结构体; - 然后把 address 和 socket 绑定对应起来(调用
sock->ops->bind函数);
tcp 连接的对应的 bind 函数是 inet_bind,里面做的事情很简单,就是简单的查一下端口有没有被占用,没有被占用的话端口就赋值给 inet_sock->inet_sport 这个字段。
inet_sock 则是由 sk 强转类型得到。
思考个小问题:在上面的图中,bind 这个函数只在服务端用到?
为啥客户端没用这个函数呢?
其实,客户端也是可以用 bind 这个函数,但是没必要。
理解下 bind 函数的作用:给这个 socketfd 绑定地址(IP:Port)用的。客户端不需要是因为:如果没设置,内核在建连的时候会自动选一个临时的端口号作为本次 TCP 连接的地址。一般客户端也不在意端口号,只要能和服务端正常通信就好,所以客户端一般没有 bind 调用。
服务端必须要用这个是因为服务端必须提前明确指定监听的 IP 和 Port (不然谁知道向哪里发起连接呢)。
3. listen 函数
其实 socket( ) 创建出来的套接字并无客户端和服务端之分,是 listen 函数让 socket 有了不一样的属性,成为监听套接字。
listen 系统调用主要做两件事:
- 通过 fd 找到
struct socket结构体; - 调用
sock->ops->listen函数(对应inet_listen);
inet_listen 做啥了?内核注释:
Move a socket into listening state.
简单看下 inet_listen 的实现功能:
- 检查 socket 状态,类型,必须为流式套接字才能转化成监听套接字;
- 调用
inet_csk_listen_start;
inet_csk_listen_start 做啥了?
- 初始化请求队列
icsk->icsk_accept_queue; - 套接字状态设置成
TCP_LISTEN; - 获取到之前 bind 的端口,如果没有设置,那么就会用个临时的端口;
- 把监听套接字加入到全局 hash 表中;
划重点:套接字的转变就在于此。
4. accept 函数
inet_accept ( net/ipv4/af_inet.c )注释:
Accept a pending connection. The TCP layer now gives BSD semantics.
这个主要是从队列 icsk->icsk_accept_queue 中取请求,如果队列为空,就看 socket 是否设置了非阻塞标识,非阻塞的就直接报错 EAGAIN,否则阻塞线程等待。
所以,监听套接字的可读事件是啥?
icsk_accept_queue 队列非空。
这个队列什么时候被填充的?
tcp_child_process-> tcp_rcv_state_process
这个也是底层网络协议回调往上调用的,tcp 三次握手之后,建立好的连接就在一个队列中 accept_queue ,队列非空则为只读。由 tcp 的协议栈往上调用,对应到 socket 层,还是会调用到 sk->sk_data_ready 。
这里还是以 epoll 管理监听套接字来举例。这个跟上面讲的数据来了一样,都是把挂接在 socket 本身上的 wait 对象进行唤醒(调用回调),这样就会到 ep_poll_callback ,ep_poll_callback 就会把监听套接字对应的 ep_item 挂到 epoll 的 ready 队列中,并且唤醒阻塞在 epoll_wait 的线程,从而实现了监听套接字的读事件的触发的流程。
5. connect 函数
这个没啥讲的,就是由客户端向服务端发起连接的时候调用,一般也和 epoll 配合不起来,略过。
句柄事件
在 深入剖析 epoll 篇 我们就提到过,epoll 池可以管理 socket fd ,用于监听 socket fd 的可读,可写事件。那么问题来了,socket fd 的可读可写事件分别是啥?代表了什么含义?
这个要把服务端的监听类型的 socket fd 和传输数据的 socket fd 分开来说。
监听类型的 fd:
- 有 client 建连,则触发可读事件;
- 句柄被 close ,则触发可读事件;
数据类型的 fd:
- sk buffer 有可读的数据,触发可读事件;
- sk buffer 有可写的空间,触发可写事件;
- 句柄杯 close,连接关闭的时候,也是可读的;
还有,如果 socket 之上有 pending 的 error 待处理,那么也会触发可读事件。
epoll 池怎么配合?
最后,我们再回忆一下,epoll 池管理的 socket fd 是怎么及时触发唤醒的呢?
换句话说,socket fd 数据就绪之后,怎么能及时的唤醒被阻塞在 epoll_wait 的线程?
还记得套接字 buffer 数据来了的时候的回调吗?
调用的是 sk->sk_data_ready 这个函数指针,这个字段在 socket 初始化的时候被赋值为 sock_def_readable ,这个函数里面会依次调用所有挂接到 socket 的 wait 队列的对象( 表头:sk->sk_wq ),在这个 wait 队列中存在和 epoll 关联的秘密。
回忆下,在 深入剖析 epoll 篇 提到,epoll_ctl 的时候,在把 socket fd 注册进 epoll 池的时候,会把一个 wait 对象挂接到这个 socket 的 sk->sk_wq 中 ,回调函数就是 ep_poll_callback 。
这个wait 对象就是数据就绪时候的联系方式,这样把 socket 数据就绪的流程和 epoll 关联上了。
也就是说,sk->sk_data_ready 会调用到 ep_poll_callback ,ep_poll_callback 这个函数处理很简单,做两件事情:
- 把 socket 对应的 ep_item 挂接到就绪队列中;
- 把阻塞在
epoll_wait的线程(Linux 进程和线程本质无区别)投递到就绪队列中,等待内核调度(也就是所谓的唤醒,实现机制很简单,就是epoll_wait阻塞切走之前,会创建出一个 wait 对象,挂到 epoll 池上,后续唤醒就能以此为依据);
ep_poll_callbacksk->sk_data_readytcp_v4_rcv(具体协议栈处理函数)软中断硬中断数据来了
最后用一张简要的图展示结构体之间的关系:
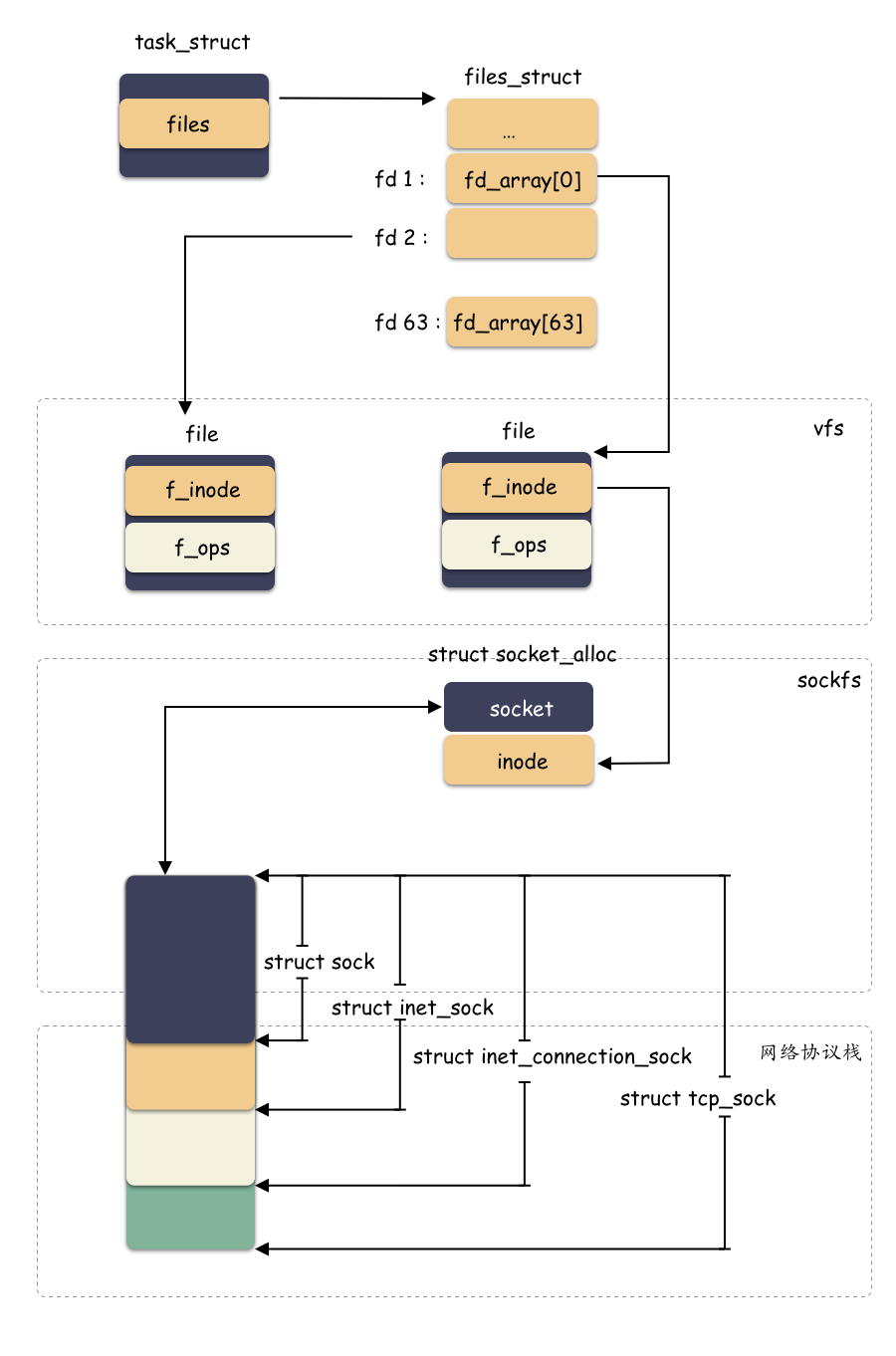
总结
- vfs 下有一个 sockfs 的抽象层,是把 socket 抽象成“文件” fd 的关键之一;
- socket fd 能够和文件 IO 一样,使用 write/read 等系统调用,就得益于 vfs 帮你做的转接。那
socket()函数调用是不是就和 open 文件 fd 的效果是一样的呀?是的,都是构建并关联各种内核结构体; - epoll 池能管理 socketfd,因为 socket fd 实现 poll 接口;
- epoll_ctl 注册 socket fd 的时候,挂了个 wait 对象在 socket 的 sk_wq 里,所以数据就绪的时候,socket 才能通知到 epoll;
- epoll_wait 切走的时候挂了个 wait 对象在 epoll 上,所以 epoll 就绪的时候,才能有机会唤醒阻塞的线程;
- 套接字由
**socket()**创建出来,客户端和服务端都是,listen()调用可以把套接字转化成监听套接字; - 监听套接字一般只监听可读事件,关注连接的建立,普通套接字走数据流,关注数据的读写事件;

若有收获,就点个赞吧
0 人点赞
