什么是内存对齐
所谓内存对齐,就是将数据存放到一个是字的整数倍的地址指向的内存之中。处理器在执行指令去操作内存中的数据,这些数据通过地址来获取。不论什么数据都有一定的大小,当一个数据所在的地址和它的大小对齐的时候,就说这个数据自然对齐了(naturally aligned),否则就是没对齐。
怎么理解数据的地址和它的大小对齐这句话呢?例如有一个地址a,它是n的整数倍,并且这个n是2的幂,这时候我们就可以说a和n个字节对齐了。举个栗子:当 a = 0x00000008,n = 4,22 = 4 的时候,就说地址a和4字节对齐了[2]。
套用到数据的地址和它的大小对齐这句话,例如一个long变量,它占用4个字节,也就是他的大小是4字节,如果这个变量的地址为 0x00000004、0x00000008 等,那么这个变量就和4字节对齐了,而如果它的地址是0x00000006 之类的,那么它就没对齐。
下面的表格给出了一个不同数据是否对齐的例子:
当存取一个地址对齐了它数数据大小的数据结构的时候,就说这是一次对齐存取。上面的例子说的是基本数据类型,当一个复杂的数据结构中的所有成员都自然对齐了,我们就说这个数据结构对齐了,为了能让复杂数据结构对齐,编译器一般会对数据结构做一些填充,使得它的成员都能对齐。
以一个例子来说明,以64位系统为例
type test struct {a int32b byte}func main() {fmt.Println(unsafe.Sizeof(test{})) // 8}
理论上int32占4个字节,byte占一个字节,test结构体应该占5个字节才对。但实际上占了8个字节,这就是进行了字节对齐。
为什么会出现字节对齐
CPU访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问。比如32位的CPU,字长为4字节,那么CPU访问内存的单位也是4字节。
这么设计的目的,是减少CPU访问内存的次数,加大CPU访问内存的吞吐量。比如同样读取8个字节的数据,一次读取4个字节那么只需要读取2次。
下面我们来看看,编写程序时,变量在内存中是否按内存对齐的差异。假设我们有如下结构体: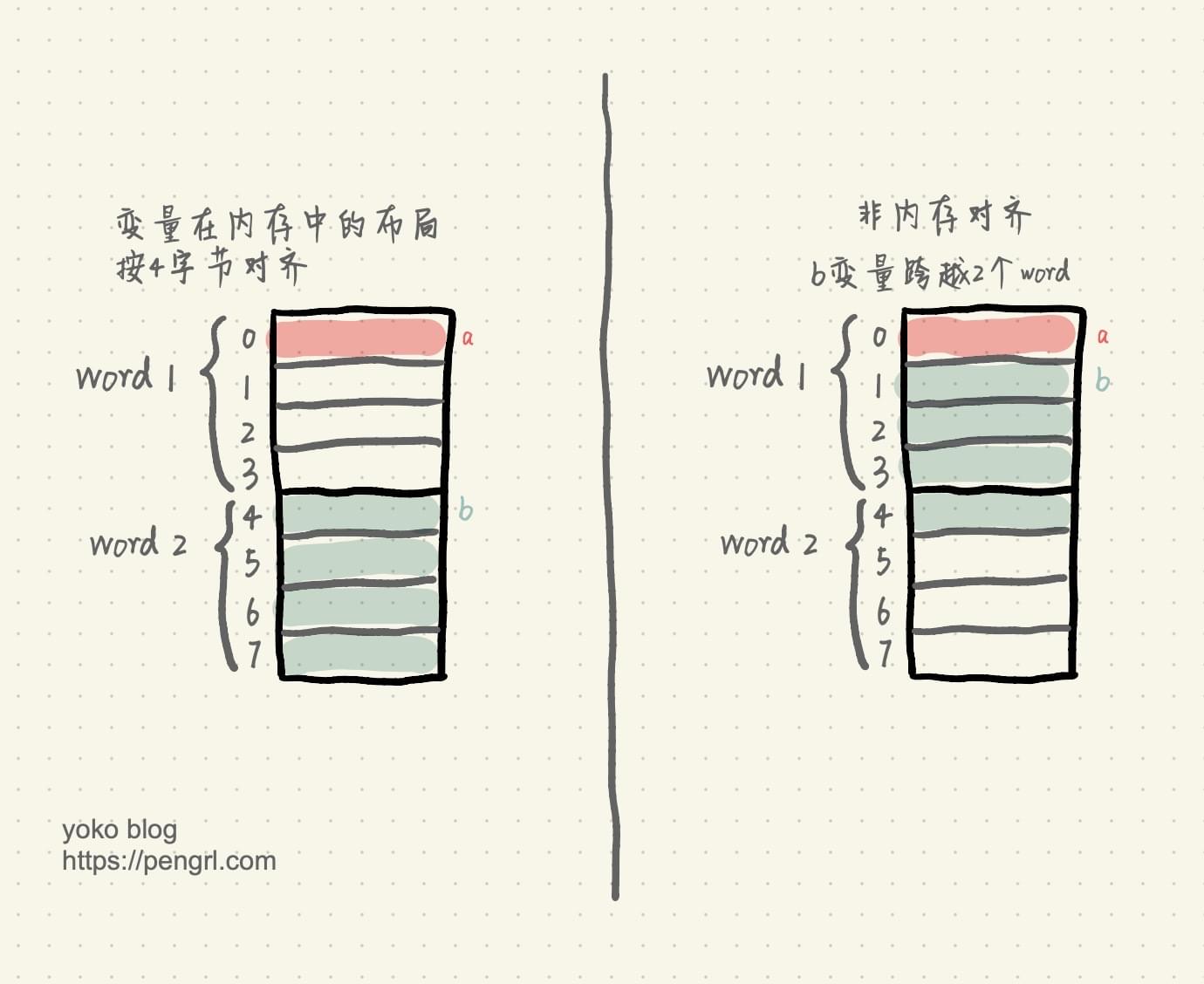
如果变量在内存中的布局按4字节对齐,那么读取a变量只需要读取一次内存,即word1;读取b变量也只需要读取一次内存,即word2。
如果变量不做内存对齐,那么读取a变量也只需要读取一次内存,即word1;但是读取b变量时,由于b变量跨越了2个word,所以需要读取两次内存,分别读取word1和word2的值,然后将word1偏移取后3个字节,word2偏移取前1个字节,最后将它们做或操作,拼接得到b变量的值。
显然,内存对齐在某些情况下可以减少读取内存的次数以及一些运算,性能更高。另外,由于内存对齐保证了读取b变量是单次操作,在多核环境下,原子性更容易保证。
但是内存对齐提升性能的同时,也需要付出相应的代价。由于变量与变量之间增加了填充,并没有存储真实有效的数据,所以占用的内存会更大。这也是一个典型的空间换时间的应用场景。
现代计算机中内存空间都是按照 byte 划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但是实际的RAM内存中存放的位置有限制,它们会要求这些数据的首地址的值是某个数k(通常它为4或8)的倍数,这和RAM的存储原理有关。感兴趣可以去看这个视频。
尽管内存是以字节为单位,但是大部分处理器并不是按字节块来存取内存的。它一般会以2字节,4字节(32位),8字节(64位),16字节甚至32字节为单位来存取内存,我们将上述这些存取单位称为内存存取粒度.
内存存取粒度又称 对齐粒度(也叫对齐模数) 或称 寄存器宽度 或称 机器字长 或称 总线宽度 。gcc中默认#pragma pack(4),可以通过预编译命令#pragma pack(n),n = 1,2,4,8,16来改变这一系数。
假如没有内存对齐机制,数据可以任意存放,现在一个int变量存放在从地址1开始的连续的4个字节地址中,该处理器去取数据时,要先从0地址开始读取第一个4字节块,剔除不想要的字节(0地址),然后从地址4开始读取下一个4字节块,同样剔除不要的数据(5,6,7地址),最后留下的两块数据合并放入寄存器。这会多做很多工作。所以就出现了对齐机制。
- 某些处理器只能存取对齐的数据,存取非对齐的数据可能会引发异常;
- 某些处理不能保证在存取非对齐数据的时候的操作是原子的;
- 相对于存取对齐的数据,存取非对齐的数据需要额外花费更多的时钟周期;
- 有些处理器虽然支持非对齐的数据访问,但是会引发对齐陷阱;
- 某些处理只支持简单数据指令非对齐存取,不支持复杂数据指令非对齐存取。
总结:
- 提升效率和避免出错。减少CPU访问内存的次数,加大CPU访问内存的吞吐量。
- 内存对齐提升性能的同时,也需要付出相应的代价。由于变量与变量之间增加了填充,并没有存储真实有效的数据,所以占用的内存会更大。这也是一个典型的空间换时间的应用场景。
建议看完上面的视频再来看下面的例子。
对齐规则
go语言中对齐规则和c语言的一样。 下面所有的描述都是对64位来说。
- 对于简单类型,如果该类型大小超过8个字节,用8个字节对齐;小于8个字节按该类型的大小对齐,即按小的对齐
- 对于结构体类型,它的默认对齐方式就是它的所有成员使用的对齐参数中最大的一个,这样在成员是复杂类型时,可以最小化长度。
- 对齐后的长度必须是成员中最大的对齐参数的整数倍,这样在处理数组时可以保证每一项都边界对齐。
- 对于数组,比如char a[1024];它的对齐方式和分别写1024个char 是一样的。虽然他的占用大小超过了8,但他的对齐值仍然是1。
对于32位机器来说,机器字长是4;对于128位或更高的机器来说,可能是16,32,64…。
几个例子
- 顺序不同,最后的占用大小不同
type User struct {a uint8b uint64c uint16d uint32}type User2 struct {a uint8c uint16d uint32b uint64}func main() {fmt.Println(unsafe.Sizeof(User{})) // 24fmt.Println(unsafe.Sizeof(User2{})) // 16}
- 结构体中包含结构体 的时候的对齐案例
type User struct {a uint8 //按1对齐 0%1=0 从0开始到1 占1个字节b uint32 //按4对齐 4%4=0 从4开始到8 占4个字节c uint16 //按2对齐 8%2=0 从8开始到10 占2个字节//User 按最大的元素大小对齐,即uint32=4//User到10,10不是4的倍数,往后扩充,所以User占12,对齐值是4}type User2 struct {a uint8 // 按1对齐 0%1=0 0-1 占1 注意是:[0, 1)下同c uint16 // 按2对齐 2%2=0 2-4 占2 [2, 4)//User:占12个字节,对齐值为4u User // 按4对齐 4%4=0 4-16 占12d uint32 // 按4对齐 16%4==0 16-20 占4b uint64 // 按8对齐 24%4==0 24-32 占8//User2 按最大的元素大小对齐,即uint64=8//User2到32 32是8的倍数,所以User2占32,对齐值是8}func main() {fmt.Println(unsafe.Sizeof(User{})) // 12fmt.Println(unsafe.Sizeof(User2{})) // 32}
- 结构体中包含数组
type two struct {s [100]byte // 按byte=1对齐,//two按最大的元素大小 byte=1 对齐,//two到100 100是1的倍数,所以two占100,对齐值是1}type User2 struct {a uint8 // 按1对齐 0%1=0 0-1 占1c uint16 // 按2对齐 2%2=0 2-4 占2//two:占100个字节,但是按元素中最大的对齐(按1对齐),s two // 按1对齐 4%1=0 4-104 占100d uint32 // 按4对齐 104%4=0 104-108 占4b uint64 // 按8对齐 108不行,往后找 112%4=0 112-120 占8//User2按最大的元素大小 8 对齐,//User2到120 120正好是8的倍数,所以User2占120}func main() {fmt.Println(unsafe.Sizeof(two{})) // 100fmt.Println(unsafe.Sizeof(User2{})) // 120}
- 结构体包含的结构体中包含数组和其他元素
type two struct {s [101]byte // 按byte=1对齐,0-101b uint64 // 按8对齐 104%8=0 104-112 占8//two按最大的元素大小 8 对齐,//two到112 112是8的倍数,所以two占112,对齐值为8}type User2 struct {a uint8 // 按1对齐 0%1=0 0-1 占1c uint16 // 按2对齐 2%2=0 2-4 占2//two:占112个字节,但是按元素中最大的对齐(按8对齐),s two // 按8对齐 8%8=0 8-120 占112d uint32 // 按4对齐 120%4=0 120-124 占4b uint64 // 按8对齐 128%8=0 128-136 占8//User2按最大的元素大小 8 对齐,//User2到136 136正好是8的倍数,所以User2占136}func main() {fmt.Println(unsafe.Sizeof(two{})) // 112fmt.Println(unsafe.Sizeof(User2{}))// 136}
推荐阅读

若有收获,就点个赞吧
0 人点赞
