1.简述
1.1.计算机基本概念
(1)CPU:中央处理器,处理速度最快。
(2)memory:内存,临时性存储设备,处理速度次之,但数据不保存。
(3)disk:硬盘,持久性存储设备,处理速度最慢,但数据永久保存。
1.2.什么叫IO流
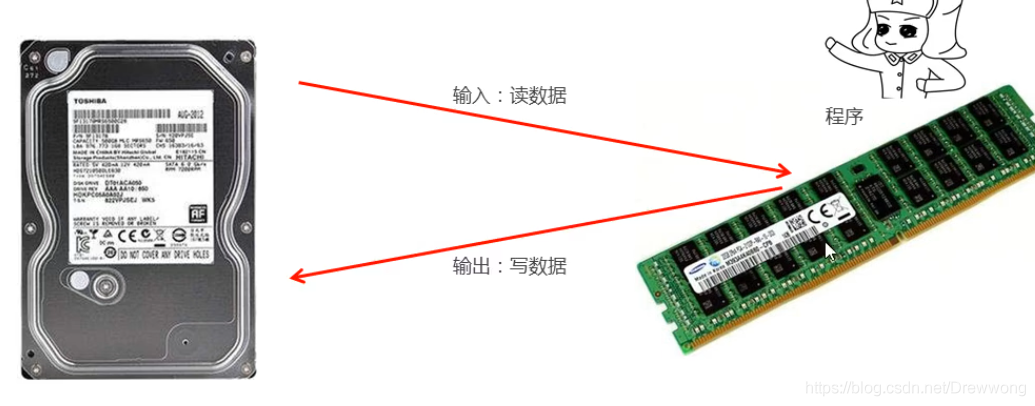
I/O(Input/Output的缩写)流就是用于处理设备之间的数据传输问题。如:把数据写到文件中实现数据持久化存储,读取文件中的已有的数据,网络通信等,常见的应用有:文件复制、文件下载、文件上传等。
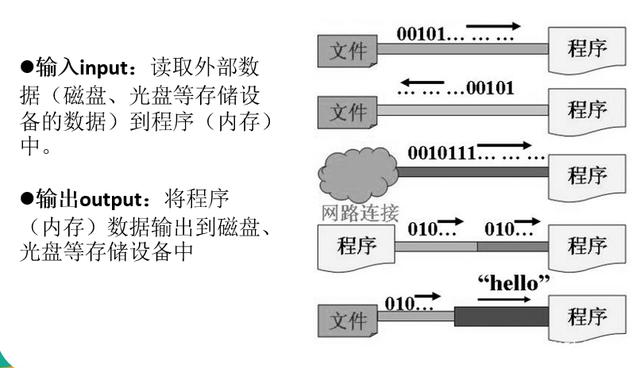
要想实现数据持久化存储,就要把内存中的数据存储到持久化设备(硬盘、光盘、U盘等)上,这个动作称为输出(写)Output操作。而读取持久设备上的数据到内存中的这个动作称为输入(读)Input操作。因此我们把这种输入(读)和输出(写)动作称为IO操作,IO操作都是在内存上进行的。
流是一种抽象的概念,是对数据传输的总称,也就是说数据在设备之间的传输称为流,流的本质就是数据传输。IO的数据传输可以简单的看做是以内存为参考物的一种数据的流动,Java对数据的操作是通过流(Stream)的方式。
简单的来说,输入流,就是用于读文件的流,InputStream类是字节输入流的抽象类,是所有字节输入流的父类。Reader类是字符输入流的抽象类,是所有字符输入流的父类。输出流,就是用于写文件的流,OutputStream类是字节输出流的抽象类,是所有字节输出流的父类。Writer类是字符输出流的抽象类,是所有字符输出流的父类。
1.3.I/O流步骤
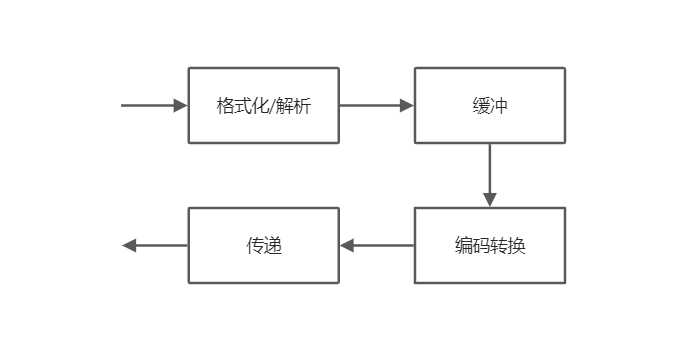
(1)格式化/解析:在内部数据表示(以字节为单位)与外部数据表示(以字符为单位)之间进行双向转换。例如一个2字节的整数10002,就需要5个字符来表示。
(2)缓冲:用于在格式/解析与传递之间缓存字符序列。对于输出,较短的字符序列格式化之后并不马上输出,而是保存在缓冲区里,待累积到一定规模之后再传递到外部设备。相反,从外部设备读入的大量数据也是先放在缓冲区,然后逐步取出完成输入。默认时,IO流的输入输出都是经过缓冲的,也可以让IO流工作在无缓冲模式下。
(3)编码转换: 是将一种字符表达式转换成另一种字符表达式。如果格式化产生的字符表达式与外部字符表达式不同(输出时),或者外部表达式与IO流能解析的表达式不同(输入时),就必须进行编码转换。如多字节编码与宽字符编码之间的转换等。多数情况下并不需要进行编码转换。
(4)传递:主要是与外部设备进行通信。输出时,传递负责将经过格式化、缓冲即编码转换后的字符序列发送到外部设备;输入时,则负责将外部设备抽取数据,为其后进行的编码转换、缓冲及解析提供字符序列。
1.4.流(Stream)
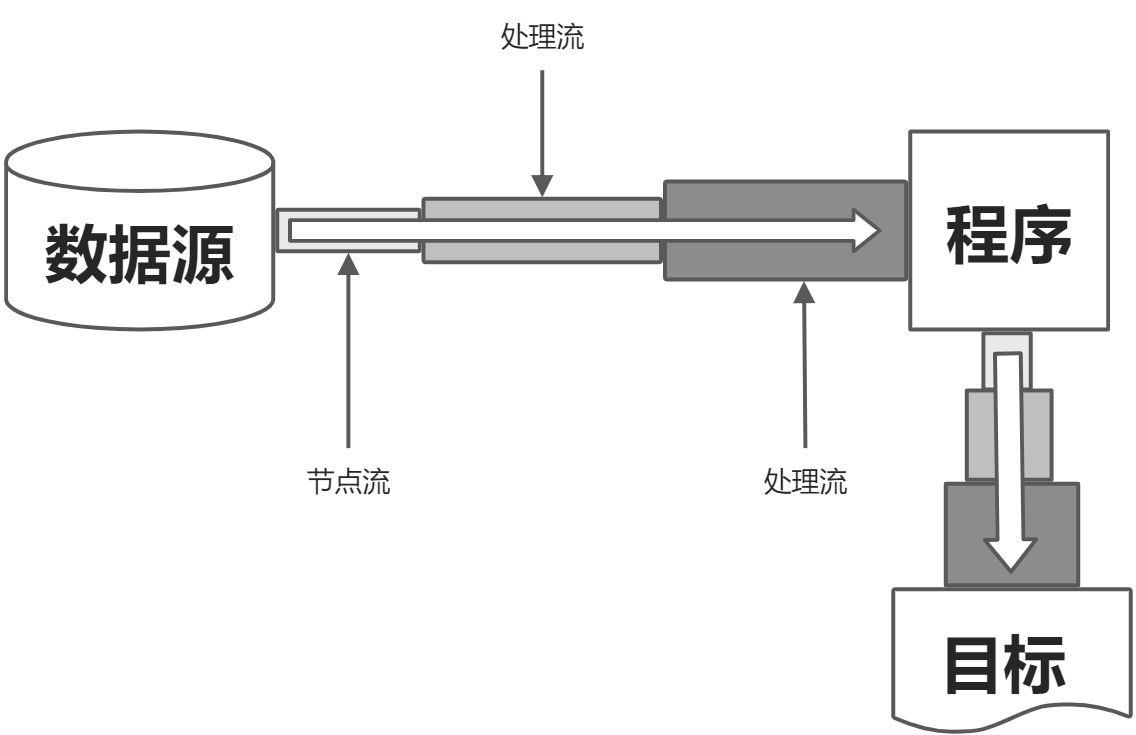
流是一个抽象、动态的概念,是一连串连续动态的数据集合。流是一组有序的数据序列,根据操作的类型,可分为输入流和输出流两种。为进行数据的输入/输出操作,Java中把不同的输入/输出源(键盘、文件、网络连接,压缩包,其他数据源等)抽象表述为“流”(Stream),Stream是从起源(source)到接收(sink)的有序数据。对于输入流而言,数据源就像水箱,流就像水管中流动着的水流,程序就是我们的最终用户,我们通过流将数据源的数据输送到程序当中。对于输出流而言,目标数据源就是目的地,我们通过流将程序中的数据输送到目的地数据源中。
2.流的分类
(1)根据处理数据类型(数据单位)的不同可以分为字节流和字符流。字节流以字节为单位读写文件,操作二进制文件,当传输的资源文件有中文时,就会出现乱码。字符流以字符为单位读写文件,操作文本文件。
(2)根据数据流向不同分为可以分为输入流和输出流。这里的输入输出是相对于代码程序而言,从本地文件、网络上资源等获取资源输入到程序中,这称之为输入流,从程序中输出到本地文件、网络等,这称之为输出流。
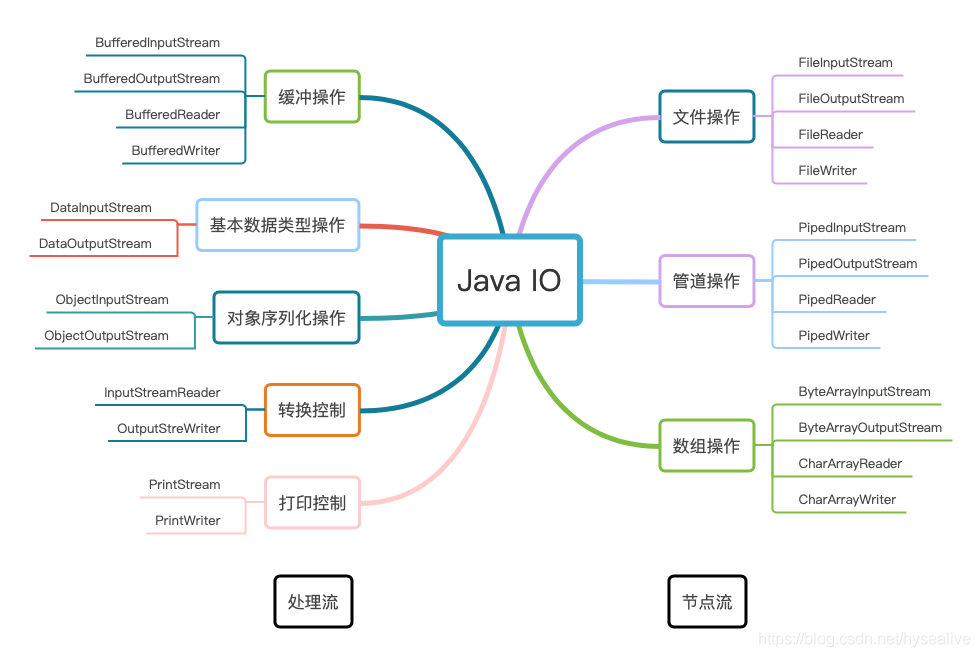
(3)根据功能(角色)不同可以分为节点流和处理流。节点流可以直接从或向一个特定的数据源读写数据,例:FileInputStream、FileReader、DataInputStream等。处理流不直接连接到数据源或目的地,是“连接”在已存在的流(节点流或处理流)之上,是对已存在的流进行连接和封装,通过所封装的流的功能调用实现数据的读写,例:BufferedReader、BufferedInputStream等。处理流的构造方法总是要带一个其他的流对象做参数,一个流对象可以经过其他流的多次包装,所以说处理流也叫包装流。
一般来说,我们说的IO流分类是按照数据类型(数据单位)来进行划分的。简单的区分,把流输出到文件,用windows记事本打开,可以读懂的就是字符流,读不懂的就是字节流。
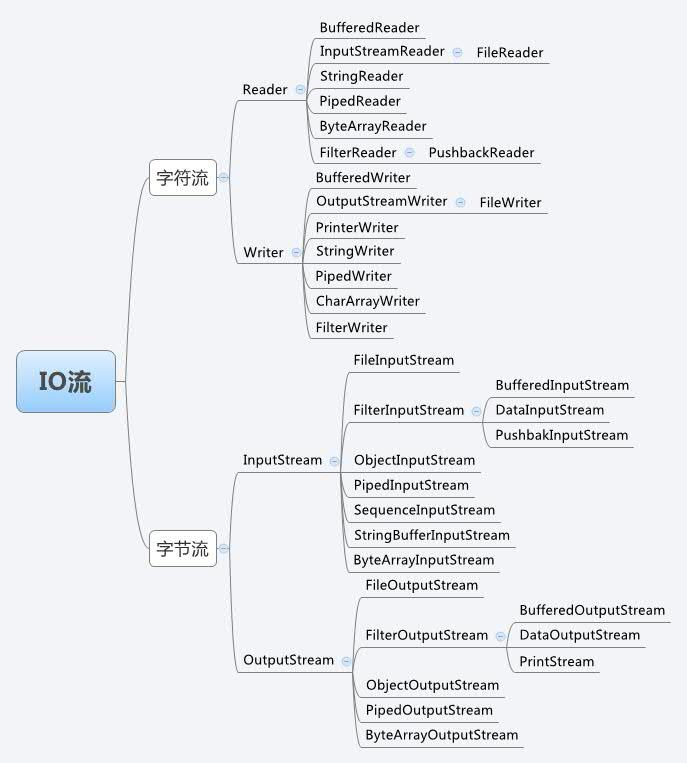
| 分类 | 字节流 | 字符流 | |||
|---|---|---|---|---|---|
| 字节输入流 | 字节输出流 | 字符输入流 | 字节输出流 | ||
| 抽象基类 | InputStream | OutputStream | Reader | Writer | 节点流 |
| 访问文件 | FileInputStream | FileOutputStream | FileReader | FileWriter | |
| 访问数组 | ByteArrayInputStream | ByteArrayOutputStream | CharArrayReader | CharArrayWriter | |
| 访问管道 | PipedInputStream | PipedOutputStream | PipedReader | PipedWriter | |
| 访问字符串 | StringReader | StringWriter | |||
| 缓冲流 | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter | 处理流 |
| 转换流 | InputStreamReader | OutputStreamWriter | |||
| 对象流 | ObjectInputStream | ObjectOutputStream | |||
| 抽象基类 | FilterInputStream | FilterOutputStream | FilterReader | FilterWriter | |
| 打印流 | PrintStream | PrintWriter | |||
| 推回流入流 | PushbackInputStream | PushbackReader | |||
| 特殊流 | DataInputStream | DataOutputStream |
3.字节流
3.1.简述
3.1.1介绍
字节流,一切皆为字节。文件数据(文本、图片、视频等)在存储时,都是以二进制数字(0101100…)的形式保存,都可以通过使用字节流传输。字节流传输的单位是字节(8bit)。
3.1.2.分类
按照流向可以分为:字节输入流和字节输出流。
(1)字节输出流:java.io.OutputStream抽象类是表示字节输出流的所有类的超类,将指定的字节信息写出到目的地,它定义了字节输出流的基本共性功能方法。
(2)字节输入流:java.io.InputStream抽象类是表示字节输入流的所有类的超类,可以读取字节信息到内存中,它定义了字节输入流的基本共性功能方法。
InputStream和OutputStream都属于字节流的超类,是抽象类,不能直接使用,需要用它们相应的子类来实例化,在Java API中所有以这两个类为后缀的类均属于字节流。
3.1.3.拷贝文件示意图
拷贝test.txt文件示例图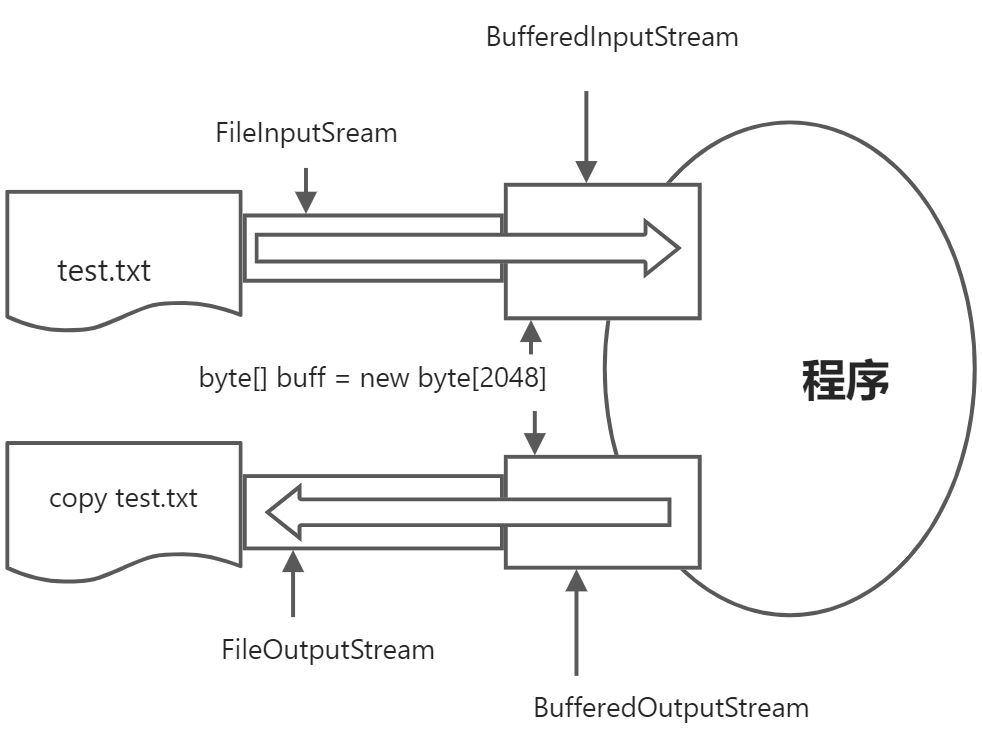
拷贝文件缓冲思想:
BufferedInputStream内置了一个缓冲区数组,从其中读取一个字节时,它会一次性从文件中读取n(字符数组长度)个字节,存在缓冲区中,返回给程序一个字节,程序再次读取时,就不用找文件了,直接从缓冲区中读取,直到缓冲区中的所有都被使用过,才重新从文件中读取n(字符数组长度)。BufferOutputStream也内置了一个缓冲区数组,程序想流中写出字节时,不会直接写出文件,先写到缓冲区,直到缓冲区写满,他才把程序一次性写到文件里面。
字节流一次读写一个数组的速度明显比一次读一个字节的速度快很多,这是加入了数组这样的缓冲区效果,java本身在设计的时候也考虑到了这样的设计思想(装饰设计模式)所以提供了字节缓冲区流。
3.2.字节输入流
3.2.1.方法
| Modifier and Type | Method and Description |
|---|---|
| int | available() 返回从该输入流中可以读取(或跳过)的字节数的估计值,而不会被下一次调用此输入流的方法阻塞。 |
| void | close() 关闭此输入流并释放与流相关联的任何系统资源。 |
| void | mark(int readlimit) 标记此输入流中的当前位置。 |
| boolean | markSupported() 测试这个输入流是否支持 mark和 reset方法。 |
| abstract int | read() 从输入流读取数据的下一个字节。 |
| int | read(byte[] b) 从输入流读取一些字节数,并将它们存储到缓冲区 b 。 |
| int | read(byte[] b, int off, int len) 从输入流读取最多 len字节的数据到一个字节数组。 |
| void | reset() 将此流重新定位到上次在此输入流上调用 mark方法时的位置。 |
| long | skip(long n) 跳过并丢弃来自此输入流的 n字节数据。 |
3.2.2.字节输入流子类
(1)FileInputSream:介质流,用于对文件进行读取操作。
(2)PipedInputStream:管道字节输入流,能实现多线程间的管道通信。
(3)ByteArrayInputStream:字节数组输入流,从字节数组(byte[])中进行以字节为单位的读取,也就是将资源文件都以字节的形式存入到该类中的字节数组中去。
(4)FilterInputStream:装饰流,作用是对节点流进行封装,实现一些特殊功能。
(5)DataInputStream:数据输入流,它是用来装饰其它输入流,作用是“允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型”。
(6)BufferedInputStream:缓冲流,对节点流进行装饰,内部会有一个缓存区,用来存放字节,每次都是将缓存区存满然后发送,而不是一个字节或两个字节这样发送,效率更高。
(7)ObjectInputStream:对象输入流,用来提供对基本数据或对象的持久存储。通俗点说,也就是能直接传输对象,通常应用在反序列化中。它也是一种处理流,反序列化先前使用ObjectOutputStream序列化的对象。
3.2.3.读数据步骤
(1)创建字节输入流对象。
(2)调用字节输入流对象的读数据方法。
(3)释放资源。(当完成流的操作时,必须调用close()方法,释放系统资源)
3.3.字节输出流
3.3.1.方法
| Modifier and Type | Method and Description |
|---|---|
| void | close() 关闭此输出流并释放与此流相关联的任何系统资源。 |
| void | flush() 刷新此输出流并强制任何缓冲的输出字节被写出。 |
| void | write(byte[] b) 将 b.length字节从指定的字节数组写入此输出流。 |
| void | write(byte[] b, int off, int len) 从指定的字节数组写入 len个字节,从偏移 off开始输出到此输出流。 |
| abstract void | write(int b) 将指定的字节写入此输出流。 |
3.3.2.字节输出流子类
(1)ByteArrayOutputStream:介质流,向Byte数组中写入数据。
(2)FileOutputStream:介质流,向本地文件中写入数据。
(3)PipedOutputStream:管道字节输入流,向与其它线程共用的管道中写入数据。
(4)ObjectOutputStream:对象输出流,将JAVA对象序列化。
(5)FilterOutputStream:装饰流,作用是对节点流进行封装,实现一些特殊功能。
(6)DataOutputStream:数据输出流,它是用来装饰其它输出流,作用是“允许应用程序以与机器无关方式从底层输出流中读取基本 Java 数据类型”。
(7)BufferedOutputStream:缓冲流,对节点流进行装饰,内部会有一个缓存区,用来存放字节。
3.3.3.写数据步骤
(1)创建字节输出流对象(调用系统功能创建了文件,创建字节输出流对象,让字节输出流对象指向文件)。
(2)调用字节输出流对象的写数据方法。
(3)释放资源。
4.字符流
4.1.简述
4.1.1.介绍
学习字符流之前先提出一个疑问:既然字节流都可以进行读写操作,为什么还要学习字符流?
计算机的所有信息都是以二进制的形式存储。按照某种规则把字符存储到计算机中,称为编码。将计算机中的二进制按照某种规则解析展示出来,称为解码。在编码和解码的过程中,就会很容易出现编码问题(乱码)。字节流读数据的单位是字节,字符流读数据的单位是字符。字节流读字符的时候是先读到字节数据,再转为字符。同样,如果是写字符,那么就先把字符转为字节,再写出。字节流虽然可以读取任意文件,但是当读取文本文件的时候遇到非英文的语言(大部分是中文)会出现乱码现象,而字符流读取能有效的避免编码问题。
注意:字符流操作的是文本文件,不能操作其他类型的文件。
字节流在操作时是不会用到缓冲区(内存)的,是对文件进行直接操作的。而字符流是使用缓冲区的,通过缓冲区再进行操作。
证明1:使用字节流,不执行关闭操作,但是文件中依然存在输出内容,所以说字节流是直接操作文件本身的,不会用到缓冲区(内存)。
证明2:使用字符流,不执行关闭操作,文件中没有任何内容,所以说字符流在操作中用到了缓冲区(内存),关闭字符流时,强制把缓冲区(内存)内容输出到文件。
4.1.2.分类
按照流向可以分为:字符输入流和字符输出流。
(1)字符输入流:java.io.Reader抽象类是表示字符输入流的所有类的超类。
(2)字符输出流:java.io.Writer抽象类是表示字符输出流的所有类的超类。Reader和Writer都属于字符流的超类,是抽象类,不能直接使用,需要用它们相应的子类来实例化,在Java API中所有以这两个类为后缀的类均属于字符流。
4.1.3.什么时候使用字符流
(1)只读取一段文本时,因为读取的时候是按大小读取的,所以不会出现半个中文的现象。
(2)只写出一段文本时,因为写出的时候可以直接按字符串写出,不用像字节流一样把字节数据转换为字符数据。
4.2.字符输入流
4.2.1.方法
| Modifier and Type | Method and Description |
|---|---|
| abstract void | close() 关闭流并释放与之相关联的任何系统资源。 |
| void | mark(int readAheadLimit) 标记流中的当前位置。 |
| boolean | markSupported() 告诉这个流是否支持mark()操作。 |
| int | read() 读一个字符 |
| int | read(char[] cbuf) 将字符读入数组。 |
| abstract int | read(char[] cbuf, int off, int len) 将字符读入数组的一部分。 |
| int | read(CharBuffer target) 尝试将字符读入指定的字符缓冲区。 |
| boolean | ready() 告诉这个流是否准备好被读取。 |
| void | reset() 重置流。 |
| long | skip(long n) 跳过字符 |
4.2.2.字符输入流子类
(1)InputStreamReader:转换流,是从字节流到字符流的桥梁:它读取字节,并使用指定的charset将其解码为字符 。
(2)FileReader:介质流,用于对文件进行读取操作。
(3)BufferedReader:缓冲流,从字符输入流读取文本,缓冲字符,以提供字符,数组和行的高效读取。
4.3.字符输出流
4.3.1.方法
| Modifier and Type | Method and Description |
|---|---|
| Writer | append(char c) 将指定的字符附加到此作者。 |
| Writer | append(CharSequence csq) 将指定的字符序列附加到此作者。 |
| Writer | append(CharSequence csq, int start, int end) 将指定字符序列的子序列附加到此作者。 |
| abstract void | close() 关闭流,先刷新。 |
| abstract void | flush() 刷新流。 |
| void | write(char[] cbuf) 写入一个字符数组。 |
| abstract void | write(char[] cbuf, int off, int len) 写入字符数组的一部分。 |
| void | write(int c) 写一个字符 |
| void | write(String str) 写一个字符串 |
| void | write(String str, int off, int len) 写一个字符串的一部分。 |
4.3.2.字符输出流子类
(1)InputStreamWriter:转换流,是从字符流到字节流的桥梁:向其写入的字符编码成使用指定的charset字节。
(2)FileWriter:介质流,用于对文件进行写入操作。
(3)BufferedWriter:缓冲流,将文本写入字符输出流,缓冲字符,以提供单个字符,数组和字符串的高效写入。
注意:write方法只把数据写到内存缓冲区中,并不会直接写到文件中,需要调用flush方法将缓冲区中数据刷到文件中,或者close时会全部刷过去后再释放资源。
5.File类
5.1.简述
Java File类(文件类)以抽象的方式代表文件名和目录路径名,File对象代表磁盘中实际存在的文件和目录。在程序中操作文件和目录(文件和目录的创建、文件的查找和文件的删除等),都可以通过File类来完成。需要注意的是,不管是文件还是目录都是使用File来操作的,File能新建、删除、重命名文件和目录,但是File不能访问文件内容本身。如果需要访问文件内容本身,则需要使用输入/输出流。
windows和DOS系统默认使用”\”来表示,UNIX和URL使用”/“来表示。 Java程序支持跨平台运行,因此路径分隔符要慎用。为了解决这个隐患,File类提供了一个常量:public static final String separator,根据操作系统,动态的提供分隔符。
5.2.方法
| Modifier and Type | Method and Description |
|---|---|
| boolean | canExecute() 测试应用程序是否可以执行此抽象路径名表示的文件。 |
| boolean | canRead() 测试应用程序是否可以读取由此抽象路径名表示的文件。 |
| boolean | canWrite() 测试应用程序是否可以修改由此抽象路径名表示的文件。 |
| int | compareTo(File pathname) 比较两个抽象的路径名字典。 |
| boolean | createNewFile() 当且仅当具有该名称的文件尚不存在时,原子地创建一个由该抽象路径名命名的新的空文件。 |
| static File | createTempFile(String prefix, String suffix) 在默认临时文件目录中创建一个空文件,使用给定的前缀和后缀生成其名称。 |
| static File | createTempFile(String prefix, String suffix, File directory) 在指定的目录中创建一个新的空文件,使用给定的前缀和后缀字符串生成其名称。 |
| boolean | delete() 删除由此抽象路径名表示的文件或目录。 |
| void | deleteOnExit() 请求在虚拟机终止时删除由此抽象路径名表示的文件或目录。 |
| boolean | equals(Object obj) 测试此抽象路径名与给定对象的相等性。 |
| boolean | exists() 测试此抽象路径名表示的文件或目录是否存在。 |
| File | getAbsoluteFile() 返回此抽象路径名的绝对形式。 |
| String | getAbsolutePath() 返回此抽象路径名的绝对路径名字符串。 |
| File | getCanonicalFile() 返回此抽象路径名的规范形式。 |
| String | getCanonicalPath() 返回此抽象路径名的规范路径名字符串。 |
| long | getFreeSpace() 返回分区未分配的字节数 named此抽象路径名。 |
| String | getName() 返回由此抽象路径名表示的文件或目录的名称。 |
| String | getParent() 返回此抽象路径名的父 null的路径名字符串,如果此路径名未命名为父目录,则返回null。 |
| File | getParentFile() 返回此抽象路径名的父,或抽象路径名 null如果此路径名没有指定父目录。 |
| String | getPath() 将此抽象路径名转换为路径名字符串。 |
| long | getTotalSpace() 通过此抽象路径名返回分区 named的大小。 |
| long | getUsableSpace() 返回上的分区提供给该虚拟机的字节数 named此抽象路径名。 |
| int | hashCode() 计算此抽象路径名的哈希码。 |
| boolean | isAbsolute() 测试这个抽象路径名是否是绝对的。 |
| boolean | isDirectory() 测试此抽象路径名表示的文件是否为目录。 |
| boolean | isFile() 测试此抽象路径名表示的文件是否为普通文件。 |
| boolean | isHidden() 测试此抽象路径名命名的文件是否为隐藏文件。 |
| long | lastModified() 返回此抽象路径名表示的文件上次修改的时间。 |
| long | length() 返回由此抽象路径名表示的文件的长度。 |
| String[] | list() 返回一个字符串数组,命名由此抽象路径名表示的目录中的文件和目录。 |
| String[] | list(FilenameFilter filter) 返回一个字符串数组,命名由此抽象路径名表示的目录中满足指定过滤器的文件和目录。 |
| File[] | listFiles() 返回一个抽象路径名数组,表示由该抽象路径名表示的目录中的文件。 |
| File[] | listFiles(FileFilter filter) 返回一个抽象路径名数组,表示由此抽象路径名表示的满足指定过滤器的目录中的文件和目录。 |
| File[] | listFiles(FilenameFilter filter) 返回一个抽象路径名数组,表示由此抽象路径名表示的满足指定过滤器的目录中的文件和目录。 |
| static File[] | listRoots() 列出可用的文件系统根。 |
| boolean | mkdir() 创建由此抽象路径名命名的目录。 |
| boolean | mkdirs() 创建由此抽象路径名命名的目录,包括任何必需但不存在的父目录。 |
| boolean | renameTo(File dest) 重命名由此抽象路径名表示的文件。 |
| boolean | setExecutable(boolean executable) 为此抽象路径名设置所有者的执行权限的便利方法。 |
| boolean | setExecutable(boolean executable, boolean ownerOnly) 设置该抽象路径名的所有者或每个人的执行权限。 |
| boolean | setLastModified(long time) 设置由此抽象路径名命名的文件或目录的最后修改时间。 |
| boolean | setReadable(boolean readable) 一种方便的方法来设置所有者对此抽象路径名的读取权限。 |
| boolean | setReadable(boolean readable, boolean ownerOnly) 设置此抽象路径名的所有者或每个人的读取权限。 |
| boolean | setReadOnly() 标记由此抽象路径名命名的文件或目录,以便只允许读取操作。 |
| boolean | setWritable(boolean writable) 一种方便的方法来设置所有者对此抽象路径名的写入权限。 |
| boolean | setWritable(boolean writable, boolean ownerOnly) 设置此抽象路径名的所有者或每个人的写入权限。 |
| Path | toPath() 返回从此抽象路径构造的java.nio.file.Path对象。 |
| String | toString() 返回此抽象路径名的路径名字符串。 |
| URI | toURI() 构造一个表示此抽象路径名的 file: URI。 |
5.3.封装工具
6.标准I/O
6.1.简述
Java通过系统类System实现标准输入/输出的功能,我们经常用到System类的System.in,System.out这种控制台输入输出,这就是所谓的标准流。因为标准流是基于原始的输入输出流实现的子类,所以标准输入输出流本质上仍是一个字节输出/输出流。标准流简单来说,标准流就是从控制台读取或输出数据。
6.2. 标准输入流
可以使用System.in对象从标准输入设备(通常是键盘)读取数据。当用户输入数据并按Enter键时,输入的数据用read()方法每次返回一个字节的数据。
6.3. 标准输出流
使用System.out 从标准输出设备(控制台)打印输出数据。
7.序列化与反序列化
7.1.简述
序列化:把Java对象转换为字节序列的过程。对象序列化的最主要的用处就是在传递和保存对象的时候,保证对象的完整性和可传递性。序列化是把对象转换成有序字节流,以便在网络上传输或者保存在本地文件中。序列化后的字节流保存了Java对象的状态以及相关的描述信息。序列化机制的核心作用就是对象状态的保存与重建。
反序列化:把字节序列恢复为Java对象的过程。客户端从文件中或网络上获得序列化后的对象字节流后,根据字节流中所保存的对象状态及描述信息,通过反序列化重建对象。
简单来说,序列化就是把实体对象状态按照一定的格式写入到有序字节流,反序列化就是从有序字节流重建对象,恢复对象状态。
7.2.作用
当对象需要考虑到持久化存储或者进行网络传输时,就需要通过序列化方式转换成可以存储或者进行网络传输的字节序列。在某些场景下,比如说当对象只需要在 JVM (准确来说是实例化对象的线程)内部使用,可以不用考虑到序列化。
7.2.1.持久化对象
将对象状态信息持久化,即把对象的字节序列永久地保存到硬盘上(通常存放在文件里,或者数据库中),此时其他有需要的应用或者 JVM 是可以共用的。
一种很常见的就是,大量数据进行处理且内存不足的时候(排序等),可以把中间过程数据先序列化存储在文件中,等需要用到再重新还原,继续使用。
7.2.2.网络传输对象
在网络上传输对象信息,跨进程共享对象,实现进程间的远程通信【RMI(远程方法调用 Remote Method Invocation)、RPC协议,JMS,Socket通信】。当两个进程在进行远程通信时,彼此可以发送各种类型的数据信息,例如文本、图片、音频、视频等。无论是何种类型的数据,都会以二进制序列的形式进行网络传输。发送方需要通过序列化把这个Java对象转换为字节序列,才能在网络上传送,而接收方则需要把字节序列反序列化恢复为 Java 对象才能使用。
7.2.3.深度拷贝对象
通过序列化和反序列化实现对象的深度克隆拷贝。既然序列化之后的字节序列可以保存对象信息,反序列化则恢复对象状态,那利用这个就可以进行对象的复制和克隆,从而拥有对象的一份深拷贝,这对于需要使用拷贝对象的场景来说也是一种可选方案。不过这里要注意的是,这种对象会受Java序列化机制限制,它本身及其相关属性等都需要实现 Serializable 接口,都可序列化才行。可用于普通数据对象的深度复制拷贝。
7.3.工具
目前JAVA常用的序列化有XML 、 JSON 、 Hession 、 Protobuf 、 kryo 、avro 、 ProtoStuff 、 Thrift 、 FST(Fast Serialization) 、 MsgPack(MessagePack)等很多解决方案。
7.3.1.Serializable
7.3.2.Protobuf
7.3.3.JSON
JSON:用途最广泛,序列化方式还衍生了阿里的fastjson,谷歌的GSON,jackson,美团的MSON等更加优秀的转码工具。现在越来越多的网站采用JSON来交换数据,在Json.org网站上,Java可以使用的解析Json的组件就有超过20种。
7.3.4.Kryo
是一个快速高效的二进制序列化框架,号称是 Java 领域最快的。它的特点是序列化速度快、体积小、接口易使用。
7.4.原理
像序列化和反序列化,无论这些可逆操作是什么机制,都会有对应的处理和解析协议,例如加密和解密,TCP的粘包和拆包,序列化机制是通过序列化协议来进行处理的,和 class 文件类似,它其实是定义了序列化后的字节流格式,然后对此格式进行操作,生成符合格式的字节流或者将字节流解析成对象。
Java序列化机制中的字节码定义主要参考 java.io.ObjectStreamConstants 中的相关定义。

若有收获,就点个赞吧
0 人点赞
