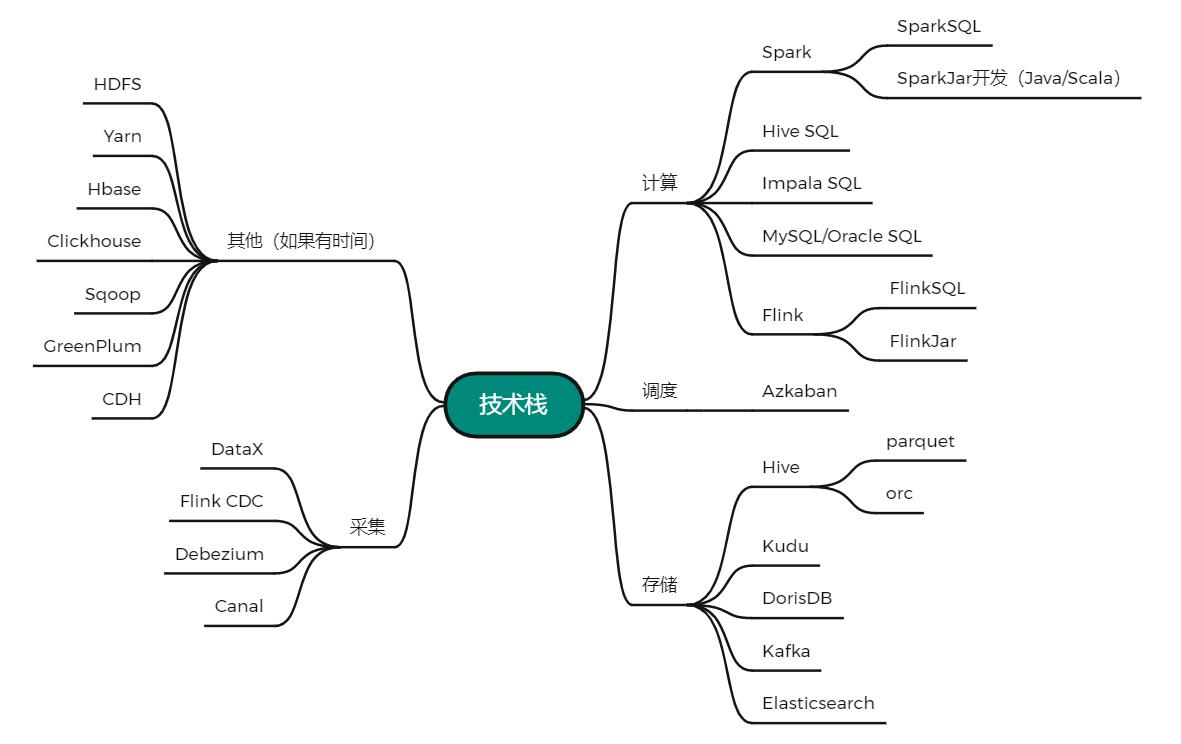
技术栈
HIVE
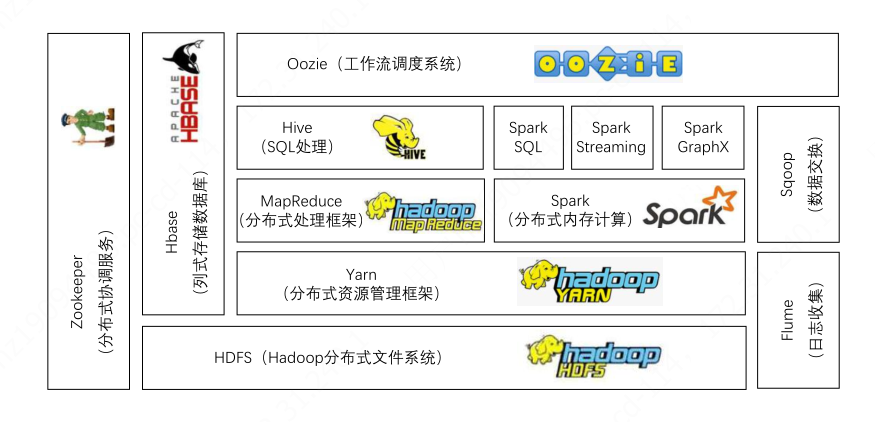
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储,查询和分析存储在Haoop中的大规模数据的机制• 操作接口采用类SQL语法,学习成本低• 避免了去写MapReduce,开发效率高• 适用于海量结构化数据离线分析• 可用于构建离线数据仓库
HBase
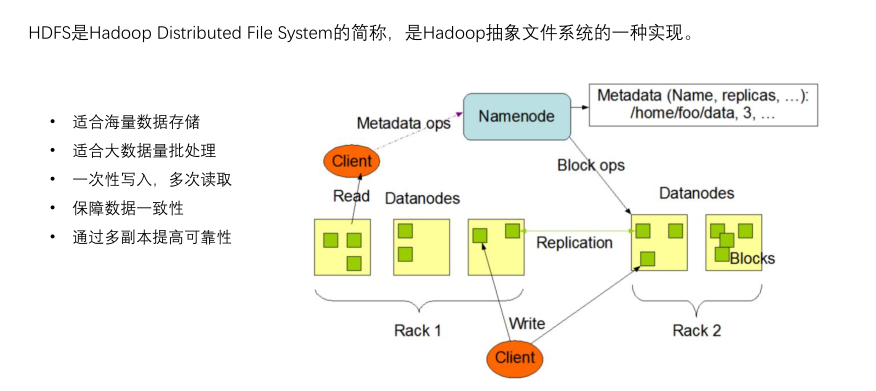
Hbase是一个高可靠、高性能、面向列、可伸缩的分布式数据库,是谷歌BigTable的开源实现,主要用来
存储非结构化和半结构化的松散数据
• 海量存储,列式存储,高并发
• 极易扩展,可以横向添加RegionServer的机器,进行水平扩展
• 可以支撑高并发KV查询场景
• 可以支撑实时或批量数据更新
Spark
Spark是基于内存计算的大数据并行计算框架,基于内存计算,提高了在大数据环境下数据处理的实时性。
• 是UC Berkeley AMP lab(加州大学伯克利分校AMP实验室)开源的Hadoop MapReduce的通用并行框架
• 专门用于大数据量下的迭代式计算
• 主要包括四个范畴的计算框架
DataX
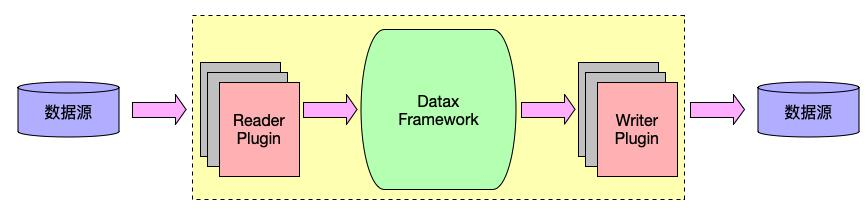
DataX是阿里云DataWorks数据集成的开源版本,在阿里内被广泛使用的离线数据同步工具/平台。其实现了包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、HBase、等异构数据源间高效的数据同步。
• 将不同数据源的同步抽象为从源头数据源读取数据的Reader插件和写入数据的Writer插件
• 理论上框架可以支持任意数据源类型的数据同步工作
• 通过多线程,支持高并发读写,提高数据同步效率
Azkaban
Azkaban是由LinkedIn开源,用于运行Hadoop任务的批量工作流任务调度工具。它实现自动解析任务依赖关系,提供web用户接口来管理任务工作流
• 兼容任意版本的Hadoop
• 提供web UI,易于上手和使用
• 基于web的workflow上传
• 基于工作流的任务调度
• 扩展性好,支持插件式
• 支持任务执行结果的告警
• SLA告警,并提供自动重试任务
Flink
Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎
• 可以提供低延迟、高吞吐、近乎逐项处理的能力
• 可通过多种方式对工作进行分析进而优化任务
• 提供了基于Web的调度视图

若有收获,就点个赞吧
0 人点赞
