360技术大牛PHP面试知识点梳理
- Linux
- 常用命令
- 系统安全:sudo、su、chmod、setfacl
- 进程管理:w、top、ps、kill、pkill、pstree、killall
- 用户管理:id、usermod、useradd、groupadd、userdel
- 文件系统:mount、umount、fsck、df、du
- 系统关机和重启:shutdown、reboot
- 网络应用:curl、telnete、mail、elinks
- 网络测试:ping、netstat、host
- 网络配置:hostname、ifconfig
- 常用工具:ssh、screen、clear、who、date
- 软件包管理:yum、rpm、apt-get
- 文件查找和比较:locate、find
- 文件内容查看:head、tail、less、more
- 文件处理:touch、unlink、rename、ln、cat
- 目录操作:cd、mv、rm、pwd、tree、cp、ls
- 文件权限:setfacl、chmod、chown、chgrp
- 压缩/解压:bzip/bunzip2、gzip/gunzip、zip/unzip、tar
- 文件传输:ftp、scp
- 定时任务
- crontab命令
- crontab -e
- crontab命令
- 常用命令
编辑定时任务
1. crontab -l
查看定时任务
1. at命令
1. at命令相比crontab来说是一次性的,只会执行一次
1. 明天两点执行do_job

- vi/vim 编辑器
- 模式:一般模式、编辑模式、命令模式
- 一般模式:删除、复制和粘贴
- 编辑模式:插入和替换
切换编辑模式:i、I、o、O、a、A、r、R
1. 命令模式:vi配置、内容查找、保存、关闭
切换命令模式::、/、?
1. 移动光标:ctrl+f、ctrl+b、0或者功能键Home、$或功能键End、G、gg、N+enter
1. 查找和替换:/word、?word;:n1,n2s/word1/word2/g
1. 删除、复制、粘贴:x,X、dd、ndd、yy、nyy、p、P、ctrl+r
1. 视图模式(vim):v、V、ctrl|v、y、d
1. 配置: 命令行模式 :setnu、:setnonu
- shell基础
- 标量(字符串、整数、浮点数、布尔) 复合(数组、对象) 特殊(资源、NULL)
- 字符串
- 单引号
- 单引号不解析变量
- 不能解析转义字符,只能解析单引号和斜杠本身
- 变量和变量,字符串和字符串, 变量和字符串,需要用“.”链接
- 双引号
- 双引号解析变量,变量可以使用特殊字符包含“{}”
- 双引号可以解析所有转义字符,也可以使用“.”链接
- 区别:双引号可以解析变量,单引号速度更快
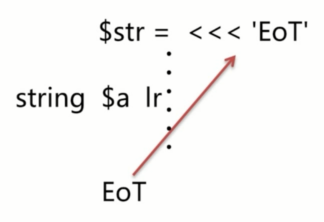
- Heredoc
- 用于处理大段文本,与双引号相似,可以解析变量
- 单引号
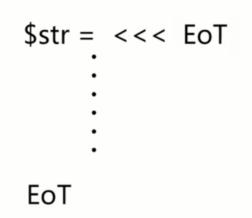
1. Newdoc
1. 与单引号类似,不支持解析变量
- 浮点型
- 浮点型 不能参与比较运算,因为计算机在转为二进制的时候会将浮点数转为一个不准确的数
- 布尔型
- 布尔值为false的情况
- 整型 0
- 浮点 0.0
- 空字符串 ‘’
- 0字符串 ‘0’
- 布尔型false
- 空数组 array()
- null
- 布尔值为false的情况
- 数组
- 超全局数组
- $GLOBALS 包含所有超全局数组内容
- $_GET get请求数据
- $_POST post请求数据
- $_FTLES文件上传
- $_REQUEST 可获取get、post以及文件上传
- $_SESSION session
- $_COOKIE cookie
- $_SERVER 获取服务器信息
- $_SERVER[‘SERVER_ADDR’] 服务器的IP地址
- $_SERVER[‘SERVER_NAME’] 服务器的名称
- $_SERVER[‘REQUSET_TIME’] 服务器的启动时间
- $_SERVER[‘QUERY_STRING’] url”?”后面的内容
- $_SERVER[‘HTTP_REFERER’] 上次请求的页面地址
- $_SERVER[‘HTTP_USER_AGENT’] 获取浏览器UA标识
- $_SERVER[‘REMOTE_ADDR’] 客户端ip地址
- $_SERVER[‘REQUEST_URL’] 获取访问的文件名
- $_SERVER[‘PATH_INFO’] 文件名后面的目录
- 超全局数组
- null
- null为空的情况
- 直接赋值为null
- 未定义的变量
- unset销毁变量
- 当echo null的时候将不会输出任何内容
- null为空的情况
- 常量
- 定义
- const() 更快,是语言结构,可以定义类的常量
- define() 是函数,不能定义类的常量
- 注意:常量定义后不能修改和删除
- 预定义常量
- FILE 所在文件路径
- DIR 所在文件目录
- LINE 所在行号
- FUNCTION 所在函数
- CLASS 所在类名
- METHOD 所在方法名+类名
- 定义
- 静态变量 (static)
- 仅初始化一次
- 初始化时需要赋值
- 每次执行函数都会保留改值
- statis修饰的变量是局部的,如果在函数内部使用,则只会在函数内部执行
- 可以记录函数的调用次数,从某些条件下终止递归
- 全局变量
- 在代码中声明的变量可以支持include和require引入文件的调用
- global $a 如果在函数内使用外部变量,需要使用关键字修饰
- $GLOBALS[‘a’] 也可以通过超全局变量$GLOBALS来使用,可以直接获取及赋值
- 函数
- 函数引用
- 在函数返回一个引用,必须在函数声明和指派返回值给一个变量时,都使用引用运算符
- $a引用函数,可与返回值共享引用空间

- include/require 文件引入
- 如果给出路径名按照路径名来找,否则从include_path中查找
- 如果include_path下也没有,则从调用脚本文件所在的目录和当前工作目录查找
- 当一个文件被包含时,其中所包含的代码继承了include所在行的变量范围
- 如果找不到加载的文件,include会发出一条警告,但程序还会执行,这一点和require不同,后者会发出一个致命错误,程序会中止运行
- include_once/require_once与普通的唯一区别是,php会检测文件是否被包含过,如果是则不会再次包含
- 时间函数
- date() 格式化一个时间戳
- strtotime() 将英文文本时间转换为时间戳
- mktime0 取一个日期的时间戳
- time() 取当前时间戳
- microtime() 返回当前时间的时间戳和微秒数
- date_default_timezone_set() 在当前脚本中设置时间函数的默认时区
- ip处理函数
- ip2long() 将ip转为数字格式
- long2ip() 将数字格式转为ip
- 打印输出
- print() 输出字符串,并返回输出的值
- echo() 输出字符串,没有返回值,比print快
- printf() 格式化输出字符串
- print_r() 格式化数组,对象并打印
- var_dump() 格式化数组,对象并输出,同时输出变量的类型
- var_export() 格式化输出数组,如果第二个参数是true则只返回不输出
- 序列化
- serialize() 序列号一个数组,对象
- unserialize() 反序列化
- 正则表达式
- 正则表达式作用:分隔,匹配,查找,替换字符串
- 分隔符
- 正斜线“/”
- hash符号”#”
- 以及取反符号(~)
- 通用原子
- \d 十进制的 0-9
- \D 非十进制的 0-9
- \w 数字字母下划线
- \W 非数字字母下划线
- \s 空白符(空格)
- \S 除了空白符
- 元字符
- “.” 除了换行符外的任意字符
- 匹配前面的内容,零次一次或多次
- ? 匹配前面的内容,零次或一次
- ^ 必须以此开头
- $ 必须以此结尾
- 出现一次或者多次
- {n} 只能出现n次
- {n,} 大于等于n次
- {n,m} 大于等于n次,小于等于m次
- [] 或,比如[123] 表示1或者2或者3
- () 表示一个整体
- [^] 取反[^123]除了1 除了2 除了3
- | 表示或的意思
- [-] 范围值,[0-9] 0到9
- 模式修正符
- i 不区分大小写
- m 每一行分别匹配
- s 修正换行 如果有换行符 就需要使用这个修正 否则 匹配不了
- U 取消贪婪模式
- x 忽略模式中的空白符
- A 必须以这个模式开头
- D 修正对\n的忽略
- u utf-8编码 中文匹配时有用
- 后向引用
- 把前面匹配到的内容后向引用,为了防止反斜线被转化掉需要用两个反斜线

- 贪婪模式
- 如果直接使用.*匹配则会直接匹配到最后一个,为了防止这样可以使用模式修正符或者?来禁止贪婪

- 正则函数
- preg_match() 执行正则表达式
- preg_match_all() 执行全局表达式
- preg_replace() 正则替换
- preg_split() 正则匹配搜索
- 中文匹配
- utf-8 0x4e00-0x9fa5
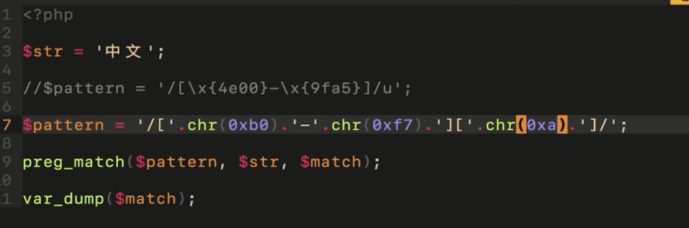
1. gb2312 0xb0-0xf7,0xa1-0xfe

- 运算符
- 运算符优先级
- 递增/递减>!取反>算数运算符>大小比较>(不)相等比较>引用>位运算符(^)>位运算符(|)>逻辑与>逻辑或>三目>赋值>and>xor>or
- 运算符优先级

- 用括号可以使代码增加可读性,推荐使用
- false和false的七种为空对比的结果是真
- 递增/递减不影响布尔值
- 递减NULL没有效果,递增会为1
- 递增/递减在前就先运算后返回,反之就是先返回后运算
- 逻辑或(||) 第一个为真,第二个则不会执行,其中一个为真即返回真
- 逻辑与(&&) 第一为假,第二个则不会执行,其中两个必须同时为真才返回真
- MYSQL部分
- 数据类型
- 整数类型
- TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT
- 长度:可以指定数据类型的指定宽度 例如INT(11) 不会限制合法范围 只会影响显示个数
- 实数类型
- DECIMAL可以存储比BIGINT还大的整数
- 可以用于存储精确地小数FLOAT和DOUBLE类型支持使用标准的浮点近似计算
- 字符串类型
- VARCHAR
- varchar使用一个或两个额外字节记录字符串的长度,列长度小于255字节用1个字节表示,否则用两个
- varchar 超出制定长度会被截断
- 用于存储可变长字符串,它比定常类型更节省空间
- CHAR
- char是定长 根据定义的字符串分配足够的空间
- char会根据需要采用空格进行填充以方便比较
- char 适合存储很短的字符串,或者所有值都接近同一个长度
- 超出指定的长度会被截断
- 对于经常变更的数据来说,char比VARCHAR更好,char不容易产生碎片
- 对于非常短的列,char在存储空间上更有效率
- 只有分配真正需要的空间 会消耗更长的内存
- 尽量避开使用BLOB、TEXT类型 查询会使用临时表导致严重的内存开销
- 枚举
- 用枚举代替常用的字符串类型
- 把不重复的合计存储称一个预定义的合集
- 非常紧凑,把一列值压缩到1到两个字节 使表的体积大大减少
- 内部存的是整数
- 尽量避免使用数组作为枚举的常量 易混乱
- VARCHAR
- 时间和日期类型
- 尽量使用TIMESTAMP,比DATETIME空间效率高
- 使用整数存时间戳格式不方便处理
- 如果需要存储微妙 可以使用bigint类型
- 整数类型
- 基础操作
- 常见操作
- mysql 链接 mysql
- -u 用户
- -p 密码
- -h 链接地址
- -P 端口
- 其他
- \G 数据垂直显示
- \c 取消当前mysql命令
- \q 退出
- \s mysql状态
- \h 帮助
- \d 执行符
- mysql 链接 mysql
- 常见操作
- 触发器
- 可通过数据库相关表实现级联更改
- 监控一张表中的某个字段的更改而做出相应处理
- 某些业务编号的生成等
- 滥用会造成数据库及应用程序的维护困难111
- 数据库引擎
- innDB引擎
- 支持事务,性能优秀
- 数据存储在共享表空间,可通过配置分开
- 对于主键查询性能高于其他引擎
- 读取数据时自动在内存构建hash索引,插入数据时自动构建插入缓冲区
- 通过一些机制和工具支持真正的热备份
- 支持崩溃后的安全恢复
- 支持行级锁
- 支持外键
- MyISAM
- 5.1版本前,MyISAM是默认的存储引擎
- 拥有全文索引 空间函数 和压缩
- 不支持事务和行级锁 不支持崩溃后的安全恢复
- 表存储在两个文件MYD和MTI
- 设计简单,某些场景下性能很好
- 其他索引
- Archive
- Blackhole
- CSV
- Memory
- 引擎选择优先使用所InnDB索引
- innDB引擎
- 锁机制
- 概念:
- 多个用户对同一个数据进行读取或修改时发生阻塞,会产生并发控制的问题
- 锁分为共享锁和排它锁 其实就是读锁和写锁
- 读锁:共享的,不堵塞多个用户可以同时读一个资源,互不干扰
- 写锁:排它的,只允许一个人进行写入,防止其他用户读取正在写入的资源
- 表锁:开销最小 锁定整整表,MyISAM是表锁
- 行锁:最大尺度的支持并发处理,但是页是带来了最大的锁开销,InnoDB是行级锁
- 概念:
- 索引
- 索引对性能的影响
- 大大减少服务器需要扫描的数据量
- 帮助服务器减少排序和临时表
- 将随机io变为顺序io
- 大大提高查询速度降低写的速度,占用磁盘
- 索引使用场景
- 对于数据量小的表 扫描效率会更高
- 大到中型表,索引非常有效
- 特大型表建立和使用索引的代价随之增长,可使用分区技术来解决
- 索引类型
- 普通索引 : 没有任何限制 最基本的索引
- 唯一索引 : 与普通表类似,但是具有唯一性约束
- 主键索引 : 特殊的唯一索引 不允许有空值
- 一个表只有一个主键索引但是可以有多个唯一索引
- 主键索引一定是唯一索引,唯一索引不一定是主键索引
- 主键可以与外键构成完整性约束,防止数据不一致
- 组合索引 : 将多个列组合在一起创建索引,可以覆盖多个列
- 外键索引: 只支持InnoDB类型的表才可以使用外键索引,保证数据的一致性完整性和实现和级联操作
- 全文索引 : mysql自带的全文索引只支持MyISA并且只能对英文进行全文索引
- 索引创建原则
- 最适合索引的列是出现在where子句中的列 而不是select关键字后的列
- 索引列的基数越大索引的效果越好、
- 对字符串进行索引,应该制定一个前缀长度,可以节省大量的索引空间
- 根据情况创建复合索引,复合索引可以提高查询效率
- 避免创建过多的索引,索引会额外占用磁盘空间,降低写操作效率
- 主键尽可能选择较短的数据类型,可以有效减少索引的磁盘占用,提高查询效率
- 注意事项
- 复合索引遵循前缀原则
- like查询,%不能在在前,可以使用全文索引
- columin is null可以使用索引
- 如果mysql估计使用索引比全表扫描更慢,会放弃使用索引
- 如果or前的瞧见中的列有索引,后面没有,索引都不会被用到
- 列类型是字符串,查询是一定要给值加引号 否则索引失效
- 索引对性能的影响
- 关联操作
- 交叉链接 (cross Join)
- select * from A,B(,c)
- select * from across join B(cross join c)
- 没有任何的关联条件,结果是笛卡尔积,结果集很大,没有意义,很少使用
- 联合查询 union与union all
- 就是把多个结果集集中在一起,union前端 结果为基准,需要注意的是联合查询的列数是相等相同的记录行会合并
- 如果使用 union all 不会合并重复的记录行
- 全连接 full join
- 内连接 (inner join)
- 外连接(leftjoin/right join)
- left outer join 以左表为主 先查询出左表 按照on后的关联条件匹配有表 没匹配到的用null填充 可简写left join
- right outer join 以右表为主 先查询出右表 按照on后的关联条件匹配有表 没匹配到的用null填充 可简写right join
- 交叉链接 (cross Join)
- 优化
- 避免使用以下sql语句
- 查询不需要的记录,用limit解决
- 多表关联返回全部列指定a.id a.name b.age
- 总数取出全部咧 select * 会让优化器无法完成索引覆盖扫描的优化
- union all的效率要高于union
- 注意
- 重复查询相同的数据,可以缓存数据,下次直接读取缓存
- php端尽量使用PDO操作数据库,PDO拥有对预处理语句很好的支持 mysqli也有但是扩展性不如pdo,效率要高于pdo,mysql函数在新版本中一加趋向于淘汰,不建议使用,但是而且还没有很好的支持预处理
- 避免使用以下sql语句
- 分区
- 表非常大,无法全部存在内存,或者只在表的最后有热点数据,其他的都是历史数据。
- 分区表的数据更容易维护,可以对独立分区进行独立的操作
- 分区的数据可以分布在多个机器上从而搞笑的使用资源
- 可以使用分区表来避免某些特殊的瓶颈
- 可是备份和恢复独立的分区
- 一个表只能有1024个分区
- 5.1版本中分区表表达式必须是整数,5.5可以使用列分区
- 分区字段中如果有逐渐喝唯一索引,那么主键列和唯一列都必须包含进来
- 分区表中无法使用外键约束
- 需要对现有表的结构进行修改
- 所有分区都必须使用相同的存储引擎
- 分区函数中可以使用的函数和表达式会有一些限制
- 某些存储引擎不支持分区
- 对于MyISAM表,不能使用load index into cache
- 对于MyISAM表,使用分区表是需要打开更多的文件描述符
- 安全
- 使用预处理语句防止SQL注入
- 写入数据库的数据需要进行特殊字符的转义
- 查询的错误信息不要返回给用户,将错误记录到日志中
- 定期做数据备份
- 不给查询用户root权限,合理分配权限
- 关闭远程访问数据库的权限
- 改变root用户的名称
- 限制一般的用户访问其他库
- 限制用户对数据文件的访问权限
- 功能设计类
- 数据库设计

- 建表语句

- PHP链接mysql方式
- PDO 可扩展性好 支持预处理 面向对象 [推荐 易考]
- MYSQLi:只支持Mysql操作,支持预处理,面向对象和过程,效率较高
- mysql:只支持mysql数据库,不支持预处理,面向对象 【极不推荐】
- PDO操作数据库代码

- MVC
- 模板引擎
- php是一种html内嵌式的在服务器执行的脚本语言,但是在php有很多可以使php代码和html代码分开的模版引擎,例如Smarty Twig Haml Liquid等
- 原理:一个庞大的正则表达式替换库
- 单入口
- 有一个处理程序的文件处理所有的http请求,根据请求似的参数不同区分不同的模块和操作的请求
- 所有的文件都经过index.php 可以做一个统一的安全性检查
- 集中的处理程序
- URL不美观需要重写URL
- 处理数据的效率稍低
- MCV框架
- ThinkPHP Yii2 CI Phalcon
- 工作原理
- Model 数据模型层
- View() 视图层
- Controller(控制器) 业务逻辑层
- 模板引擎
- 常见框架
- Yii2框架
- Yii是一款非常优秀的通用web后端框架,结构简单优雅,实用功能丰富,扩展性墙,性能高是它最突出的优点
- 缺点:学习成本较高,量级较重
- Yaf框架:
- yaf框架使用php扩展的形式写的一个php框架,也就是以C语言为底层编写的,性能上要比php写的代码快一个数量级
- 优点:执行效率高,轻量级框架,可扩展性强
- 缺点:高版本兼容性差,底层代码可读性差,需要安装扩展,功能单一,开发需要编写大量的插件
- Yii2框架
- 算法
- 概念
- 什么是算法
- 1+2+3+4+..+n的值是多少
- 解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列,并且每条指令表示一个或多个操作
- 一个问题可以有多个算法,每种算法都有不同的效率
- 五个特征
- 有穷性:可以计算完,不是无限计算
- 确切性:每一步都是有意义的
- 输入项:有输入项,比如输出1到100想家
- 输出项:有结果
- 可行性:每一步都是正确克制执行的
- 什么是算法
- 空间复杂度
- 计算算法需要消耗的内存空间 记做S(n)=O(f(n))
- 包括程序代码所占用的空间,输入数据作占用的空间和辅助变量所占用的空间这三方面
- 计算嗯哼表示方式和时间复杂度类似,一般用于复杂度的渐进性来表示
- 用空间换取时间
- 冒泡排序的元素交换,空间复杂度O(1)
- 时间复杂度
- 执行算法所需要的计算工作量,一般来说,计算机算法是问题规模N的函数f(n)
- 算法的时间复杂度因此被记做T(n)=O(f(n))
- 算法评估
- 算法分析的目的是在于选择合适的算法和改进算法
- 一个算法的评价主要是从时间复杂度和空间复杂度来考虑的
- 查找算法
- 二分法:从数组的中间元素开始,如果中间元素正好是要查找的元素,搜索结束,如果某一个特定的元素大于或小于中间元素,则在数组中大于或小于中间元素的那一边中查找,而且从中间开始比较,如果某一步骤数组为空,代表找不到
- 顺序查找:按照一定的顺序检查数组中的每一个元素,找到找到特定的值为止
- 排序算法
- 冒泡排序:两两相邻的数进行比较,如果反序就交换,否则不交换
- 直接插入排序:从无序表中取出第一个元素,把他插入有序表中合适的位置,时有序表然有序
- 希尔排序:把待排序的数据增量分成几个子序列,对子序列进行插入排序,直到增量为1,直接插入排序;增量的排序,一般是数组的长度的一般,在变为原来增量的一半,直到增量为1
- 选择排序:每次从待排序的原诵读中华选出最小(或者最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完
- 快速排序:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据逗比另一部分的所有数据要小,然后在按照此方法对两部分数据分别进行快速排序,整个排序可用递归完成
- 堆排序
- 归并排序将两个以上的有序列表合并成一个新的有序表,即把排序序列分为若干个有序的子序列,再把有序列的子序列合并为有序序列
- 概念
- 数据结构
- Array(数组)
- 最简单而且应用最广泛的数据结构之一
- 使用连续的内存来存储,数组中的所有元素都必须是同类型的或者类型的衍生,元素可以通过下标来访问
- linkdlist(链表)
- 线性表的一种,最基本最简单也是最常用的数据结构之一
- 元素之间的关系是一对一的关系(除了第一个和最后一个元素,剩下的都是首尾相接)、顺序存储结构和链式存储结构两种存储方式
- Stack(栈)
- 和队列相似,一个带有数据存储特性的数据结构
- 存储数据是先进后出的,栈只有一个出口,只能从栈顶部增加和移除元素
- heap(堆)
- 一般情况下,又称为二叉堆,近似完全二叉树的数据结构
- 子节点的兼职或者索引总是小于它的父节点,每一个节点的左右子树又是一个二叉堆,根节点最大的堆叫做最大堆或者大根堆,最小的堆叫最小堆和小根堆
- list(线性表)
- 有零或者多个数据元素组成的有限序列
- 线性表是一个序列,0个元素构成的线性表搜索空表。第一个元素无先驱,最后一个元素无后继,其他元素都只有一个先驱和后继,有长度,长度是元素的个数,长度有限
- doubly-linked-list(双向链表)
- 每一个元素都是一个对象,每一个对象都有一个关键字key和两个指针(next和prev)
- queue(队列)
- 先进先出(FIFO)、并发中使用,可以安全的将对象从一个任务传给另一个任务
- set(集合)
- 保存不重复的元素
- map(字典)
- 关联数组也被称之为字典或者键值对
- graph(图)
- 通常使用邻接矩阵和邻接表来表示,前者容易实现单对于稀疏的矩阵会浪费比较多的空间,后者使用链表的方式存储信息,单对图搜索时间复杂度较高
- Array(数组)
- 高并发
- 什么是并发?
- 通常是指并发访问,也就是在某个时间点,有多少个访问同时到来。
- 什么是高并发?
- 如果一个系统的日PV在千万以上,有可能是一个高并发系统
- 有些公司完全不走技术路线,全靠机器堆。
- QPS :每秒请求或者查询的数量,在互联网领域值每秒的请求数
- 吞吐量:单位时间内处理的请求数量(通常有QPS与并发数决定)
- 响应时间:数据从请求到返回的时间,一个http请求的时间
- PV:综合浏览量(Page Viiew),即页面的点击量,一个访客在24小时内访问的页面数量
- 什么是并发?
同一个人浏览你网站的同一个页面,只记做1次PV
1. UV:独立访客(UniQue Visitor),即一定时间范围内相同访客多次访问网站,只能算1个独立访客
1. 带宽:计算带宽大小需要关注两个指标,峰值流量和页面的平均大小
1. 日网站带宽=PV/统计时间(换算成秒)*平均页面大小(KB)*8
1. 峰值一般是平均值的倍数
1. QPS不等于并发连接数,QPS是每秒http请求数量,并发连接数是系统同时处理的请求数量
1. 高并发计算:(总PV数*80%)/(6小时秒数*20%)=峰值每秒请求数(QPS)
80%的访问量集中在20%的时间
- 高并发应该关心什么?
- 压力测试
- 测试能承受的最大并发数
- 测试最大能承受的QPS峰值
- 性能测试工具
- ab 全称apache benchmark 是apache官方推出的工具 原理是模拟多个访问者同时对一个URL地址访问。
- 模拟请求100次 总共请求5000次
- ab -c 100 -n 5000 带测试的网站
- 测试机器与被测试机器分开(否则结果不稳定)
- 不要对线上服务器做压力测试
- 观察测试工具db所在的机器,以及被检测的前端机的CPU 内存 网络等都不要超过最高限度是75%
- wrk
- http_load
- web bench
- siege
- Apache JMeter
- ab 全称apache benchmark 是apache官方推出的工具 原理是模拟多个访问者同时对一个URL地址访问。
- 压力测试
- QPS优化
- QPS达到50:小型网站,一般的服务器可以应付
- QPS达到100
- 假设关系型数据库每秒在0.01秒完成
- 假设单页面只有一个SQL查询,那么100QPS意味着在1秒钟需要完成100次,但是我们并不能保证数据库查询能完成100次,。
- 解决方案:数据库缓存,数据库的负载均衡、
- QPS达到800
- 假设我们使用的是百兆带宽,意味着网站实际带宽是8MB左右
- 假设一每个页面只有10KB,在这个并发条件下,百兆带宽已经吃完了
- 方案:CDN加速,负载均衡
- QPS达到1000
- 假设使用Memcache缓存数据库查询受损,每个页面对Memcache的请求远大于DB的请求
- Memecache的悲观并发数在2w左右,但是有可能在之前内网的带宽一加被吃光了,出现不稳定情况
- 方案:静态HTML缓存
- QPS达到2000
- 这个级别下文件系统访问锁都成了灾难
- 方案,做业务分离,分布式存储
- 流量优化
- 防盗链处理
- 前端优化
- 减少http请求
- 添加异步请求
- 启用浏览器缓存和文件压缩
- CDN加速
- 建立独立的图片服务器
- 服务端优化
- 页面静态化
- 并发处理 多线程、异步处理
- 队列处理
- 数据库优化
- 数据库缓存
- 分库分表,分区操作
- 读写分离
- 负载均衡
- 服务器优化
- 负载均衡
- 防盗链
- 概念
- 盗链:指在自己的页面上展示一些并不在自己服务器上的内容
- 获得他人服务器上的资源地址,绕过别人的资源展示页面,直接在自己的页面上向最终的用户提供此内容
- 常见的是小站盗大站的图片、音乐、视频等资源
- 通过盗链可以减轻自己服务器的负担,因为真是的空间和流量来自别人的服务器
- 防盗链:防止别人通过一些技术手段绕过本站的资源展示页面,盗用本站的资源,让绕开的资源展示页面的资源链接失效
- 可以减轻服务器的压力
- 原理
- 通过Referer或者签名,网站可以检测目标访问页面的来源页面,如果是资源文件,则可以跟踪到显示他的页面地址
- 一旦检测到来源不是本站则进行阻止或返回指定的页面
- Referer
- Nginx模块ngx_http_referer_module用于阻挡来源非法的域名请求
- Nginx指令Valid_Referers,全局变量$invalid_referer
- valid_referers(下面是参数 通过管道符链接)
- none (Referer是否为空,选填)
- blocked (Referer的来源地址不为空,但是里面的植被代理或者防火墙删掉了,这些值都不是以http或者https开头的)
- server_names (Referer来源包含当前的server_names)
- string…..

- 加密签名
- Referer可以伪造,可以使用加密签名来解决
- 使用第三方模块,httpAccessKeyModule实现Nginx防盗链
- accesskey on | off 模块开关
- accesskey_hashmethod md5 | sha-1 签名加密方式
- accesskey_arg GET参数名称
- accesskey_signature 加密规则
- 例子:

1. <br />
- 减少HTTP请求
- 为什么要减少HTTP请求
- 只有10%-20%的最终用户响应时间花在请求HTML文档上,剩下的80%-90%的时间花在了HTML文档所引用组件(图片 js css flash)进行的HTTP请求上
- 查找DNS缓存也需要时间,多个缓存就要查找多次有可能缓存会被清楚
- HTTP协议规定只能串行发送,也就是说一百个请求必须依次逐个发送,当前面的一个请求完成后才开始下个请求
- 如何改善
- 改善HTTP响应时间的最简单有效的方法是减少组件的数量,并由此减少HTTP请求
- CSS Sprites
- CSS Spites 中文翻译CSS精灵,通过使用合并图片,通过指定的css的background-image和background-position来显示元素
- bacground -position:x y;x和y可以写负值也可以写正直,图片左上角为(0,0),以(0,0)坐标向右是为负数的X轴,向下是为负数的Y轴
- 图片地图
- 图片地图允许你在一个图片上关联多个url,目标url的选择取决于用户点击了图片上的那个位置
- 将五个分开的图片合并成一张图片,然后以位置信息定位超链接
- 把http请求减少为1个,可以保证设计的完整性和功能的齐全性
- 性能影响
- 图片地图和CSS精灵的响应时间基本上相同,但比使用各自独立的图片方式快了50%以上
- 合并脚本和CSS样式
- 合并JavaScript和CSS
- 使用外部的js和css文件引用的方式,因为这样比直接写在页面中要更好一点
- 独立的一个jss比用多个js文件组成的页面载入快了38%
- 使用Base64编码
- 采用Base64编码将图片直接嵌入到网页中,而不是从外部载入
- 为什么要减少HTTP请求

若有收获,就点个赞吧
0 人点赞
