在现有的微服务体系架构下,一套大型软件系统可能涵盖几十种服务单元,各服务之间的调用错综复杂,可能1个客户请求需要调用N个服务才能形成业务闭环。遇到 bug 时,开发人员不得不对各服务日志一一进行排查,整个过程耗时耗力、效率低下,甚至可能因此导致系统长时间处于不可用状态,直接造成一大笔业务损失。
针对这种现象,谷歌开发了开源 Dapper 链路追踪组件,并且在2010年发表了论文《 Dapper , a Large-Scale Distributed Systems Tracing Infrastructure 大规模分布式系统的基础跟踪设施》。这篇文章自发表后,一直是业内实现链路追踪的标杆和理论基础,具有非常大的参考价值。像大家熟知的链路追踪组件—— Uber 的 Jeager , Twitter 的 Zipkin ,阿里的 Eagleeye (鹰眼), Skywalking 与 ddtrace 等,都是基于这篇论文开发出来的。
简单来说,链路追踪即通过跟踪一个请求从发布到被响应的整个过程,了解到每个请求的详细经过,比如有哪些服务参与,参与顺序是什么,各服务调用了多少次数据库等。如此一来,当出现异常问题,开发就能快速定位问题根源,快速解决问题。
链路追踪优点:
- 服务关系:可以很清晰地展现服务间的依赖或者调用关系;
- 故障定位:在系统出现故障时候可以快速高效定位问题;
- 系统监测:在系统服务性能变差时可以及时发现,提前采取预防措施;
- 系统瓶颈分析与优化:基于全链路分析,很容易找出系统性能瓶颈点并作出优化改进,验证优化措施是否奏效。
链路追踪技术受到市场的热烈欢迎,相关监测产品层出不穷,但由于技术细节的实现各有特点(比如数据编码格式不同( json / protobuf / thrift 等)、数据传输方式不同( http / udp / rpc 等)、相同语言 SDK 的 API 不同等),各产品、各客户端的互操作性很差。为解决这个问题, OpenTracing 出现了。 OpenTracing 制定了一套无关平台、无关厂商的链路追踪 API 规范,只要每个实现链路追踪技术的厂家都遵守规范,当需要从一种技术实现切换到另一种时,并不会产生特别多的额外工作量。开发者只需在初始化部分进行少量配置修改即可。
OpenTracing GitHub 网址:https://github.com/opentracing
OpenTracing 的出现减少了开发编码方面的工作量,然而随着云计算技术不断发展,企业系统、产品结构不断调整,企业仍然无法摆脱由于数据格式转换、存储方式、前端UI界面风格等不同,而导致的 bug 难定位、数据难监测的发展困境。
那现在有没有一款产品,既能兼容市面上主流的链路追踪技术,又能多维度分析与展示数据?
DataFlux:3步玩转链路追踪,轻松定位Bug!
来自国内的 DataFlux ——一站式数据监测云平台,不但可以兼容 Jeager 、Zipkin、Skywalking 与 ddtrace 等主流技术,而且能帮助用户专注于业务开发,更直观、更专业、更高效地展示数据监测分析结果。
在 DataFlux 上我们可以按以下三个步骤进行分布式链路追踪:
- 在Datakit开启链路数据采集;
- 开启需要监控的应用(有的需要代码埋点这具体取决于使用何种链路追踪技术);
- 在DataFlux前端页面查看链路数据。
1. DataKit 开启链路数据采集
在 DataFlux 中有专用于各种数据采集的工具—— DataKit 。针对链路数据,它提供了四种类型的采集器分别对应不同技术实现: traceJaeger 、 traceZipkin 、 traceSkywalking 和 ddtrace 。这里以 ddtrace 为例,其不需要代码埋点,我们介绍下它在 Linux 平台的基本使用。
安装好 DataKit 后,在 /usr/local/cloudcare/dataflux/datakit/conf.d/ddtrace/ 目录下,复制一份 ddtrace 链路数据采集配置
$ sudo cp ddtrace.conf.sample ddtrace.conf
编辑 ddtrace.conf:
#[inputs.ddtrace]# path = "/v0.4/traces" # ddtrace 链路数据接收路径,默认与ddtrace官方定义的路径相同# [inputs.ddtrace.tags] # 自定义标签组# tag1 = "tag1" # 自定义标签1# tag2 = "tag2" # 自定义标签2# tag3 = "tag3" # 自定义标签3# env = "your_env_name" # 设置环境名# version = "your_version" # 设置版本信息
至此,链路数据采集就配置好了,重新启动一下 DataKit 的即可。
2.开启需要监控的应用
通过 ddtarce 采集数据需要根据当前项目开发语言参考对应帮助文档 Datadog Tracing。
这里以 Python 应用作为示范
第一步,安装相关依赖包
pip install ddtrace
第二步,在应用初始化时设置上报地址
import osfrom ddtrace import tracer#通过环境变量设置服务名os.environ["DD_SERVICE"] = "your_service_name"#通过环境变量设置项目名,环境名,版本号os.environ["DD_TAGS"] = "project:your_project_name,env=test,version=v1"#设置链路数据datakit接收地址,tracer.configure(# datakit IP 地址hostname="127.0.0.1",# datakit http 服务端口号port="9529",)
第三步,开启应用
ddtrace-run python your_app.py
若通过 gunicorn 运行,需要在应用初始化时进行如下配置,否则会产生相同的 traceID
patch(gevent=True)
其他语言应用与此类似,配置成功后约 1-2 分钟即可在 DataFlux Studio 的 「链路追踪」中查看相关的链路数据。
除了在应用初始化时设置项目名,环境名以及版本号外,还可通过如下两种方式设置:
- 通过环境变量设置
export DD_TAGS="project:your_project_name,env=test,version=v1"
- 通过采集器自定义标签设置
[inputs.ddtrace]path = "/v0.4/traces" # ddtrace 链路数据接收路径,默认与ddtrace官方定义的路径相同[inputs.ddtrace.tags] # 自定义标签组project = "your_project_name" # 设置项目名env = "your_env_name" # 设置环境名version = "your_version" # 设置版本信息
3.查看链路数据采集
接下来,我们就能在 DataFlux 平台看到对应的链路数据了:
每个服务相关统计信息: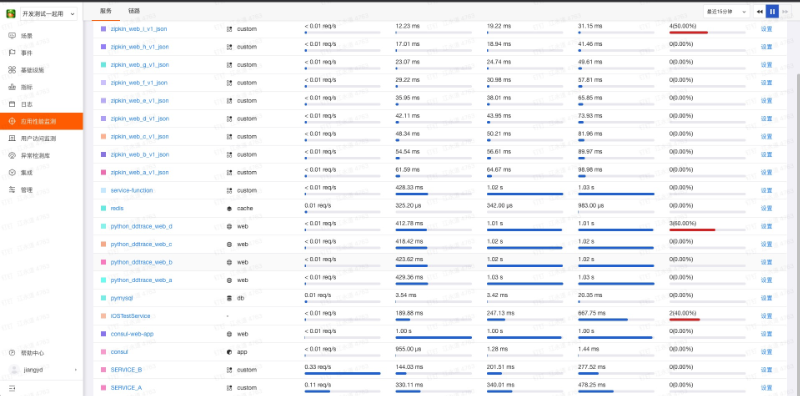
某次调用详细信息: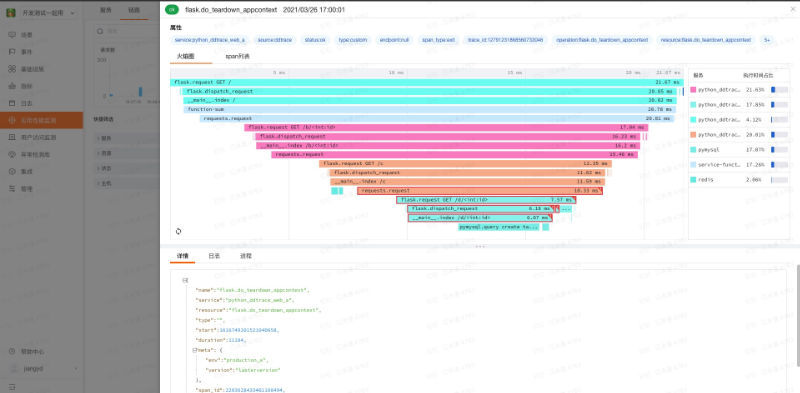
服务之间的调用关系: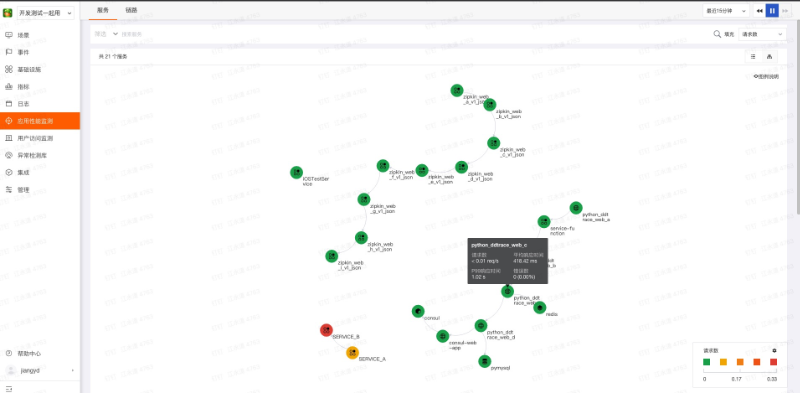
随着科技的普及与发展,链路追踪技术将直接对企业或个人的系统异常、业务 bug 等问题的解决产生重大影响,也将成为越来越多的企业或个人开发者的发展共识。

若有收获,就点个赞吧
0 人点赞
