随着Docker和容器技术的不断发展,越来越多的企业将Docker和容器应用到自身IT架构中,并投入测试和生产使用。这对企业的数据监测能力也提出了更高要求。
传统的监测方案会从每个服务器和运行应用中采集指标,这些服务器和应用一般是静态的,运行时间长,一台主机可能只需要监测150个指标;但容器却不一样,短期存活、动态调度,具有自己的环境、虚拟网络和不同的存储管理,哪怕在相同的主机上也可能会调度短期存活的批处理命令和长期存活的进程。
因此,当容器应用到IT架构中后,除需要采集的容器本身指标外,还要对在容器上运行的组件进行采集。如果没有一个比较完善的指标监控方式,对主机上几十甚至上百个Docker容器进行管控,将是一个非常浩大且费时费力的事情。
这里我们以Linux操作系统为例,给大家推荐几种常见的监测方案。

一、三种 Docker 监控指标的方式
1、读取CGroup文件
此方式是通过读取CGroup文件的方式获取指标。
通常情况下,这些文件都在/sys/fs/cgroup目录下,例如memory相关指标会在/sys/fs/cgroup/memory/docker/$CONTAINER_ID/memory.stat,$CONTAINER_ID就是容器的ID。
注意如果没有启动Docker,在memory目录下是找不到docker这个目录的。
打开memory.stat这个文件,会显示当前时间此容器的内存使用状况,包括各种指标等。
$> cat /sys/fs/cgroup/memory/docker/$CONTAINER_ID/memory.statcache 65925120rss 104542208rss_huge 0shmem 0mapped_file 30289920dirty 8192writeback 0pgpgin 44034pgpgout 2416pgfault 32187pgmajfault 312inactive_anon 0active_anon 73007104inactive_file 91582464active_file 5877760unevictable 0hierarchical_memory_limit 9223372036854771712#...
按照Linux系统中“一切皆文件”的说法,Docker容器的所有指标数据都可以使用读文件的方式拿到。
- 优点是基础指标齐全,面面俱到,扩展性强,可以自行计算新指标
- 缺点是太过硬核,缺乏汇总,很多指标意义晦涩难懂,大部分情况下都不会用到
2、DockerAPI
DockerAPI官方文档在此。
使用cURL对docker.sock访问(如果没有开放端口的话),url中的参数可以在文档中找到,示例如下。
$> sudo curl --unix-socket /var/run/docker.sock http://localhost/containers/b8d0c34bcb6c6fad49ca4a9341e9b0b54d0eb2a714e55617dbfe5fd02d8dac27/stats\?stream\=false\&one-shot\=false | jq{"id": "$CONTAINER_ID","memory_stats": {"limit": 8358457344,"max_usage": 176467968,"stats": {"active_anon": 36376576,"active_file": 5877760,"cache": 46292992,"dirty": 0,"hierarchical_memory_limit": 9223372036854772000,"hierarchical_memsw_limit": 0,"inactive_anon": 0,"inactive_file": 108650496,"mapped_file": 30408704,"pgfault": 32220,"pgmajfault": 312,"pgpgin": 44380,"pgpgout": 7538,"rss": 104611840,"rss_huge": 0,#...},"usage": 156004352},#...}
和读取CGroup文件的方式相比,这种方式显然可读性稍好一些,对各种基础领域比如CPU、内存、磁盘I/O、网络I/O进行汇总,并且增加了Docker的一些基本信息,比如容器的开启时间,容器名等。
- 优点是对各项指标进行汇总,不必挨个儿去读文件,添加了一些人性化指标(容器时间、容器名等)
- 缺点是太过冗长,该查询API会返回一个巨长的JSON,而且可读性没有得到提升,许多常用指标依然要自己计算
3、Docker命令行
使用Docker命令是最简单快捷的方式,只需要在命令行中输入命令即可。
$> docker stats
作为最常用的查看Docker容器运行指标的方式,docker stats足够轻巧和简单,但是或许它又有点太简单,如此常用的命令只有寥寥10个指标,而且限于终端输出的方式,偶尔看一下还不错,用来做Docker容器指标的长期监控似乎有点不足。
如前所述,Docker容器指标采集是一件很复杂的事,要解决如下几个问题:
- 指标数据足够齐全,需要定制一些可读性较高的指标
- 数据存储
- 指标数据的展示以及查询
二、DataFlux监测方案
我们这里向大家介绍第四种解决方案——DataFLux,在一个平台上实现对多种数据源的统一实时监测。
在 DataFlux 中有专用于各种数据采集的工具——DataKit,它提供了对Docker容器指标的采集能力。我们仍旧以Linux平台为例,介绍 DataKit 采集器的基本使用。
首先,我们查看官方提供的文档,按照操作步骤把采集器DataKit安装好。
安装好 DataKit 后,在 /usr/local/cloudcare/dataflux/datakit/conf.d/docker/ 目录下,复制一份 docker_containers 采集配置
$ sudo cp docker_containers.conf.sample docker_containers.conf
编辑 docker_containers.conf:
[[inputs.docker_containers]]endpoint = "unix:///var/run/docker.sock"interval = "5m"# 是否采集所有容器,包括 Exited 状态all = false# 还可以采集 K8S pod![inputs.docker_containers.kubernetes]url = "http://127.0.0.1:10255"
至此,Docker 容器的指标采集就配置好了,重新启动一下 DataKit 的即可(注意:数据需要稍等一会才能在 Dataflux 平台看到)。
最后我们在DataFlux后台,点击左侧菜单栏“指标”-“标签”,即可看到对应的数据结果: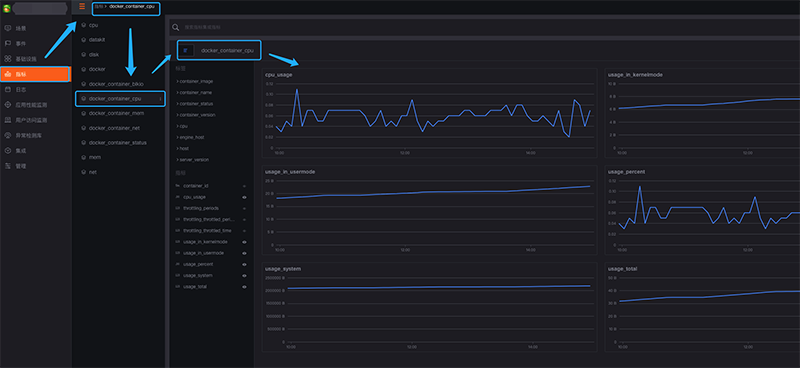
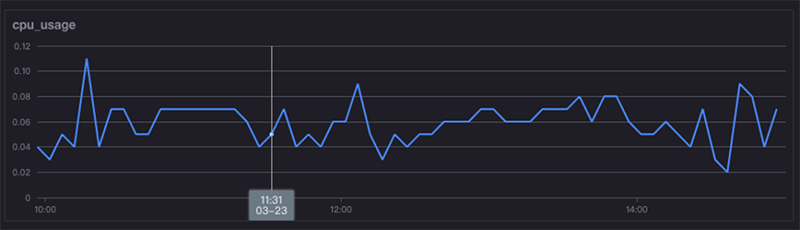
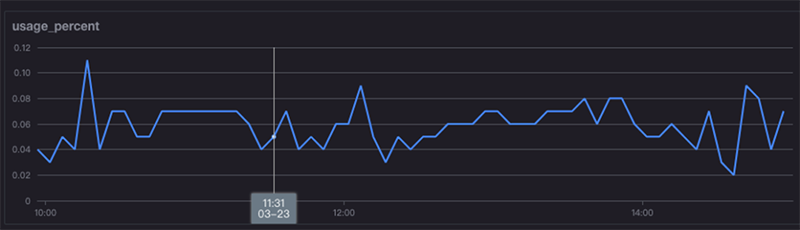
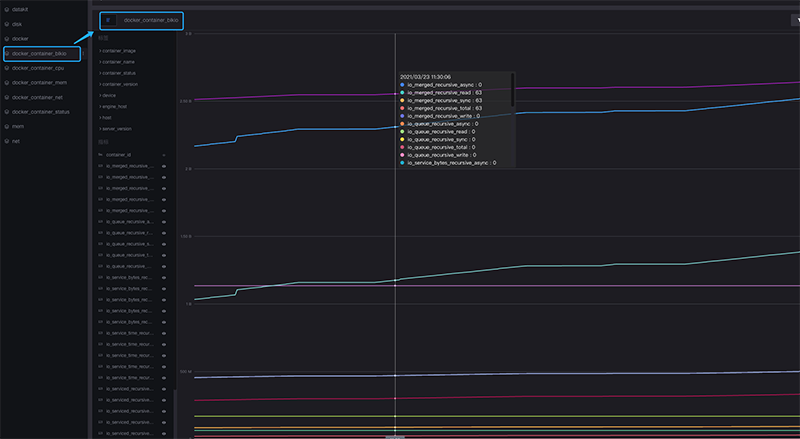
从图中可以看到,Docker容器的各项指标已经采集到,并且在图表中绘制出来。后续可以根据container_id进行更多操作,比如跟Docker日志联结等等。
更多DataFlux的采集指标和视图模板,大家可以直接从官方文档中查看。

若有收获,就点个赞吧
0 人点赞
