今天,我们来了解一下:
1、计算机视觉是什么
2、计算机视觉的应用
3、目标检测的数据形式
4、如何评价检测算法的效果
1.计算机视觉
计算机视觉(Computer Vision,CV)是深度学习应用中的重要研究方向之一,是解决如何使机器“看”这个问题的科学。因为视觉对人类来说毫不费力,但是对计算机来说这个任务却充满了挑战。深度学习中有许多针对计算机视觉的细分研究和应用方向,图像分类(Image Classification)、物体检测(Object Detection)、图像分割(Image Segmentation)、人脸识别(Face Recognition)、OCR(Optical Character Recognition,光学字符识别)等。
通过以下几个计算机视觉的典型问题和应用,我们可以快速了解计算机视觉能够解决的问题。
计算机视觉的典型问题和应用
(1)图像分类
图像分类问题的输入是一张图片,输出图片中要识别的物体类别。自从2012年以来,CNN和其他深度学习技术就已经占据了图像识别的主流地位。在图像识别领域有一些公开的数据集和竞赛驱动着整体技术的发展,例如,ImageNet是目前世界上最大的图像识别数据库,是由美国斯坦福的计算机科学家,模拟人类的识别系统而建立的。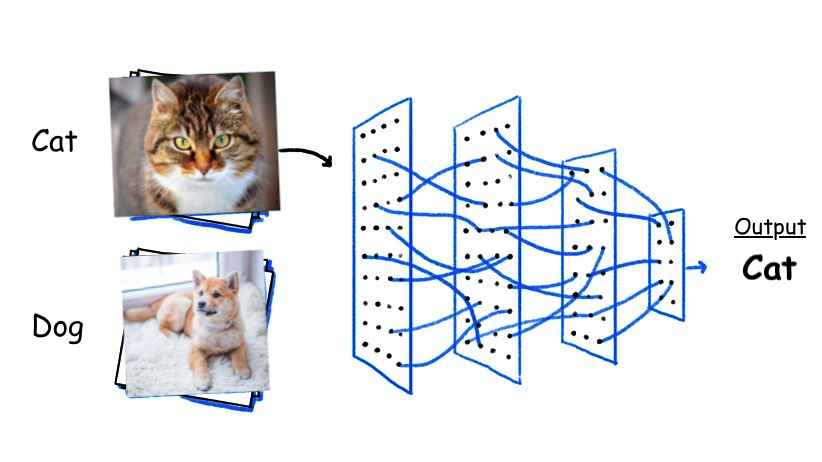
(2)物体检测
物体检测问题的输入是一张图片,输出的是待检测物体的类别和所在位置的坐标,通过深度学习方式可以解决。有的研究方法将问题建模为分类问题,有的将其建模为回归问题。如下图中物体检测可以识别图像中的狗、汽车、自行车。

(3)图像分割
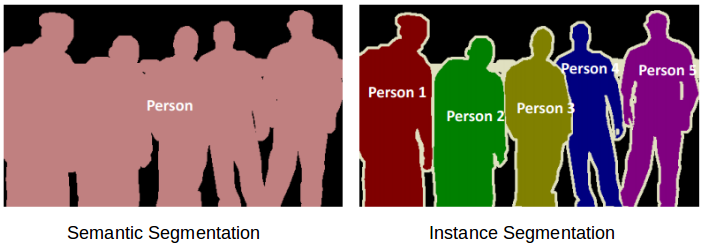
图像分割是把图像里的目标分割出来,可以想象为抠图的过程。图像分割对图像中的每个像素点做分类,是像素级别的图像分类。图像分割任务可以更精细地划分为:语义分割(Semantic Segmentation)与实例分割(Instance Segmentation)。语义分割是将图像像素分割成各自类别的过程。例如下图左图中每个像素都属于特定类别(背景或人物),属于一个类别的所有像素都用相同的颜色表示(背景为黑色,人为粉红色)。实例分割也是将图像中指定类别的目标分割出来,不过与语义分割不同的是,实例分割区分相同类别的目标。如下图右图中,同一类别的不同对象具有不同的颜色(人员1为红色,人员2为绿色,背景为黑色等)。
(4)人脸识别
人脸识别是给定一张图片,检测数据库中与之最相似的人脸,给出数据库里此人脸的身份信息。人脸识别又可以细分为很多子问题,例如,人脸检测是将一张图片中的人脸位置识别出来,人脸校准是将图片中人脸更细粒度的五官位置找出来。

(5)光学字符识别
光学字符识别是挖掘图像中的文本信息,需要对图像中的文字进行检测和识别。从二十世纪五十年代第一个识别英文字母的OCR产品面世以来,OCR的领域逐步扩展到数字、符号和很多语言文字。现如今,我们日常生活中见到的身份证号码识别、表单识别、增值税发票识别等都是基于OCR技术开发的。

接下来,我们选择一个常用的目标检测问题,深入了解数据形式及评价方式。
目标检测的数据形式
我们人眼看到计算机的图像是二维的平面,那么图像数据也就可以映射到一个二维的坐标空间内,其左上角是原点,从左至右是横坐标增长方向,从上至下是纵坐标增长方向。

有了这样的坐标空间,图像中的每个位置都可以用坐标来表示。图像中的框一样可以用坐标来表示。
表现形式是记录矩形框的左上角和右下角坐标,对于一个矩形框,以左上角为原点的二维坐标系中,左上角的坐标应该是x_min和y_min,分别代表着矩形框内x坐标的最小值以及y坐标的最小值。同理矩形框的右下角的坐标,x_max与y_max,分别对应x坐标的最大值与y坐标的最大值。

请运行下面的代码来看看,是不是能通过坐标在图像中画一个我们想要的框。
重新加载
Jerry:这里我有个疑问,这种形式只能表示水平状态的矩形,那如果一个人是歪的要如何检测呢?
Tom:好问题,真的有动脑子。其实在没有特殊要求的情况下,即使目标是歪的,还是使用水平的矩形框来进行检测或者表示。这是因为,本身目标检测问题,对于目标的位置是一个既具体又大概的形式,具体的是物体深处图像中的位置,大概的是不去描述其具体的细节,因为如果我们非常在意目标在图像中位置的细节信息,这可以用语义分割来来处理,语义分割对图像中每个像素进行分类是否是目标物体。所以从目的性出发,大部分目标检测的情况下都是使用水平矩形来表示的。
现在进行一个小测验,来看看我们的学习成果。目标检测中检测框的位置信息有几个数字来描述:检测框由左上角和右下角坐标确定,所以有4个数字。
目标检测中检测框的位置信息由4个数字来描述,分别为x_min、y_min、x_max、y_max。
如何评价目标检测算法的效果?
这里补充一个小的知识点,与如何评价模型算法好坏有关。下面我要讲一个重要的概念,样本。
样本是计算机视觉的评价中是非常重要的基本概念,计算公式的含义中很多都有样本的身影。样本分为正样本与负样本,简单点来说,正样本就是我们希望得到的,负样本是我们不希望得到的。具体这个样本在目标检测与语义分割中是不一样的。
在语义分割中,我们是对每个像素点进行分类,所以在语义分割中的样本指的是像素点,这个像素点在我们需要分割的物体中时,我们称之为正样本(Positive Sample),如果像素点是背景(不是要分割的物体中),我们称之为负样本(Negative Sample)
下面这张图,黄色部分就是负样本,其他颜色部分是正样本。
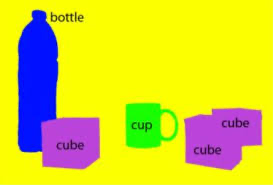
在目标检测中,情况有一些变化,不再是对像素点进行分类了。在目标检测中正样本比较好定义,就是我们的真实值(Ground Truth),也就是我们真实物体位置的检测框。负样本比较不好定义,我们可以先简单的去理解,不是我们要检测的区域是负样本。
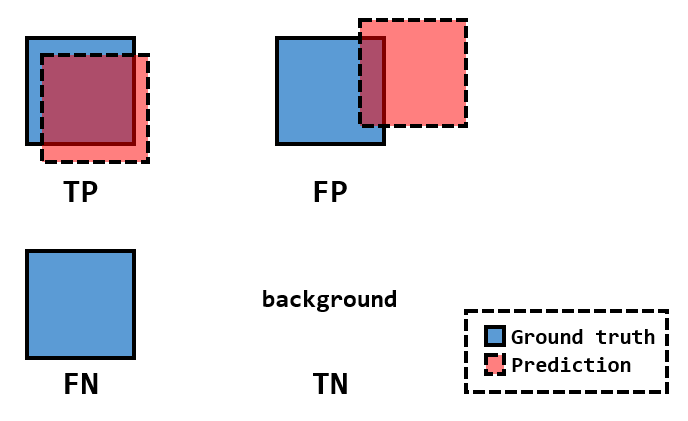
为什么要提出样本的概念,是对目标检测出的结果进行一个分类,这是评价模型算法好坏时经常用到的概念:真正样本(True positive, TP)、假正样本(False positive, FP)、假负样本(False Negative)、真负样本(True Negative, TN)。
Jerry:真正样本我知道,就是检测框与真实值重合的情况下是正样本,对不对?
Tom:em….大体正确,有点瑕疵的地方是如果以是否重合来判断是否匹配到真实值有点过于严苛,这里我们引入一个判断的指标,IoU,这是一个非常非常常用的知识点,一定要理解。
IoU(Intersection over Union)又称交并比。是计算机视觉中一个非常重要的基础算法,计算2个区域的重叠比,用2和区域的交集除以其并集,公式如下,DR表示检测结果,GT表示真实值(ground truth)。Iou = (DR交集GT )/(DR并集GT),直白一点,就是计算2个框重合的面积占总面积减去重合面积的比例。
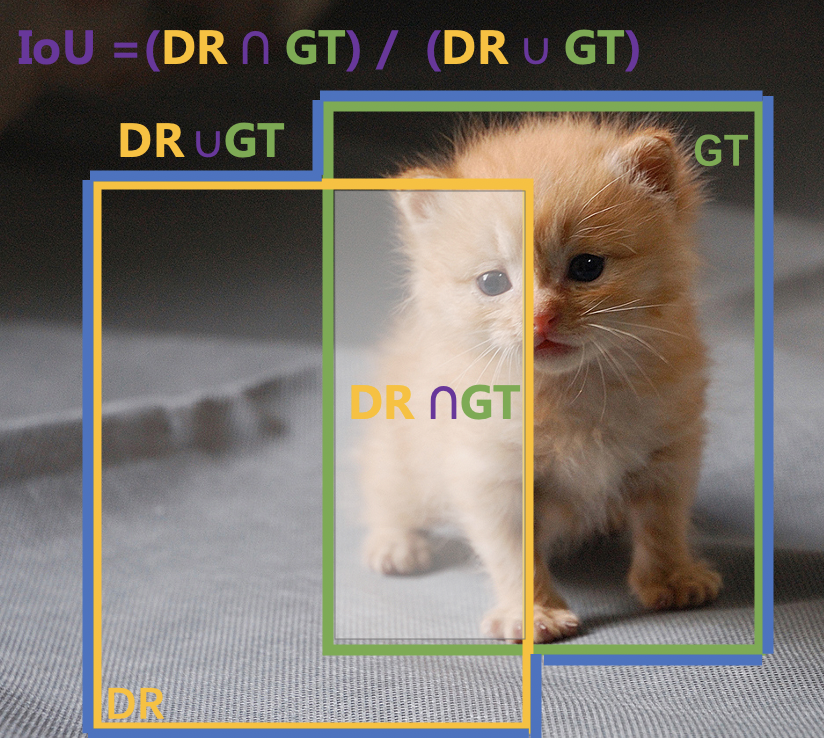
有了IoU的概念,我们再回到上面的4个定义。
- True Positive(TP):正样本被正确检测的数量。所谓的正确检测需要满足下面的条件:
- 1.置信度(confidence score,模型算法的预测会给出一个分类的评分,也是概率,比如此框是猫的概率为0.9)大于阈值,实际上我们预测出的所有的框都要满足这个条件;算法模型预测的分类与真实值(ground truth)的分类是一样的;
- 2.模型算法预测的框与真实值(Ground Truth)的IoU大于阈值(e.g. 0.5);
- 3.当有多个满足条件的预选框,则选择置信度最大的作为TP,其余的作为FP。
- False Positive(FP):负样本被检测出的数量,也称误报。预测的检测框与Ground Truth的IoU小于阈值 或者 预测的类型与标签类型不匹配。简单点说原本并不满足正确检测的条件,但是算法模型认为这里真的有物体,并产出了检测框,成为误报。
- False Negative(FN):正样本没被检测出的数量,也称漏报,指没有检测出的Ground Truth区域。
- True Negative(TN):是负样本且没被检测出的数量,这个数不好计算,具体算法模型的实现时给出真假样本的计算方式。
参考文献:
深度学习:核心技术、工具与案例解析,高彦杰
Image Segmentation with Machine Learning
Computer Vision Tutorial: A Step-by-Step Introduction to Image Segmentation Techniques (Part 1)
MXNet深度学习实战,魏凯峰
Facial Recognition Bans: What Do They Mean For AI (Artificial Intelligence)?
目标检测的评价指标(TP、TN、FP、FN、Precision、Recall、IoU、mIoU、AP、mAP)

若有收获,就点个赞吧
0 人点赞
