前言
Java 内省机制(Introspector)是 Java 对 JavaBean 类中属性以及事件的缺省处理方法,简单的说内省机制就是一种开发规范。
这种规范我们从学习 java 开始就一直在使用,唯一一点的就是大家可能都不知道这其实就是 JavaBean 的一种规范罢了。
比如下面的代码:
public class User {private String username;public String getUsername() {return username;}public void setUsername(String username) {this.username = username;}}
很简单的一个类,我们在初学 Java 时老师就对我们说:要将类中的成员变量设为私有(private),并创建两个可对外访问(public)的 getter/setter 方法。
但是这两个方法为什么要以 get 和 set 方法作为前缀老师似乎没有说对吗?这其实就是 Java 内省机制(一种 Java 内置的开发规范)。
在阿里巴巴出品的开发规范中对 Boolean 类型的属性有如下规范:
- 【强制】POJO 类中布尔类型的变量,都不要加 is 前缀,否则部分框架解析会引起序列化错误。
- 【强制】velocity 调用 POJO 类的属性时,建议直接使用属性名取值即可,模板引擎会自动按 规范调用 POJO 的 getXxx(),如果是 boolean 基本数据类型变量(boolean 命名不需要加 is 前缀),会自动调用 isXxx()方法。
如果大家看过阿里巴巴的开发规范的话一定会注意到这两条对 Boolean 属性的规范,可是为什么要这么规范呢?其实这也是 Java 内省机制的一部分。且听吾辈一一道来~
| 注意 |
|---|
| 这里说的 JavaBean 与 Spring 中的 Bean 没有任何关系,两者不能混为一谈。 |
抛砖引玉
在具体学习内省机制之前我们需要牢记的一点是:Java 内省机制并不关注类中的属性成员,而仅仅关注的是 **getter/setter/is** 等方法。
比如下面的这个类:我们没有在类中定义私有的属性 username ,而仅仅只保留一个 setUsername 方法
public class User {public void setUsername(String username) {// do something ...}}
对于内省机制而言,它会 “自作聪明” 的认为 User 这个类中是存在 username 这个属性的。因为 Java 内省机制只与类中定义的方法有关,而与内部属性无关。
但是,如果我将上面代码修改为如下示例 Java 内省机制就会 “认为” 没有 username 这个属性:
public class User {/** 有返回值的 setter 方法 */public String setUsername(String username) {return null;}}public class User {/** 无返回值无参数的 setter 方法 */public void setUsername() {}}public class User {/** 无返回值的 getter 方法 */public void getUsername() {}}public class User {/** 有返回值有参数的 getter 方法 */public String getUsername(String username) {return "username";}}
上面四个示例很简单,至于 Java 内省机制为什么没有 “自作聪明” 的认为 User 类中有 username 这个属性原因是上面四个示例 “都不符合我们最开始学习 Java 时的规范”。
再比如下面的示例代码,Java 内省机制解析得到的 “属性” 为 age 和 username:
public class User {public String getAge() {// do something ...}public void setUsername(String username) {// do something ...}}
再比如下面的示例代码,对于 Java 内省机制而言,“真正的属性” 还是 age、username。
public class User {private String profession;public String getAge() {// do something ...}public void setUsername(String username) {// do something ...}}
之所以会得到这样的结果是对于 Java 内省机制而言,在解析类中的方法时会做如下判断:
- 判断该方法是否为
public类型 - 如果无参:验证方法是否以
is或get开头。如果是以is为前缀的方法会继续判断返回类型是否为 Boolean,如果符合这些条件那么就截取get或is后的字符作为所谓的 “属性”,并将方法设置为 “读” 方法。 - 如果有参:验证方法是否有返回值,且方法只有一个参数且以
set开始,就截取set后面的字符作为所谓的 “属性”,并将方法设置为 “写” 方法。
上面只是简单的说下大概的判断逻辑,具体还是要看下下面的源码部分才能明白到底是什么意思。
之所以会有上面的解释是因为 Java 中提供了一套 API 用来访问某个属性的 getter/setter 方法,通过这些 API 可以使程序员不需要了解这个规则而进行读写操作。这些 API 都存放在 java.beans 包中,现在就来看下 JavaBean 的相关 API。
关于内省
先看下 维基百科 对 “内省” 的解释:
在计算机科学中,内省是指计算机程序在运行时(Runtime)检查对象(Object)类型的一种能力,通常也可以称作 “运行时类型检查”。一些编程语言如C++、Java、Ruby、PHP、Objective-C、Perl等等具有这种特性。
不应该将内省和反射混淆。相对于内省,反射更进一步,是指计算机程序在运行时(Runtime)可以访问、检测和修改它本身状态或行为的一种能力。一些编程语言比如 Java 具有反射特性,而C++不具有反射特性只具有内省特性。
简单地说:
反射是在运行状态下把 Class 中的各种成分映射为相应的 Java 类,可以动态的获取所有的属性以及动态的调用任意一个方法,强调的时运行状态。
而内省机制是基于反射来实现的,BeanInfo API 是用来暴露一个 JavaBean 的属性、方法和事件。得到这个 JavaBean 对象,我们就可以操作该 JavaBean 的属性。
内省 API
在 Java 内省中,用到的基本上就是如下几个类:
java.beans.Introspectorjava.beans.BeanInfojava.beans.FeatureDescriptorjava.beans.MethodDescriptorjava.beans.PropertyDescriptorjava.beans.BeanDescriptorjava.beans.EventSetDescriptor
如下图:
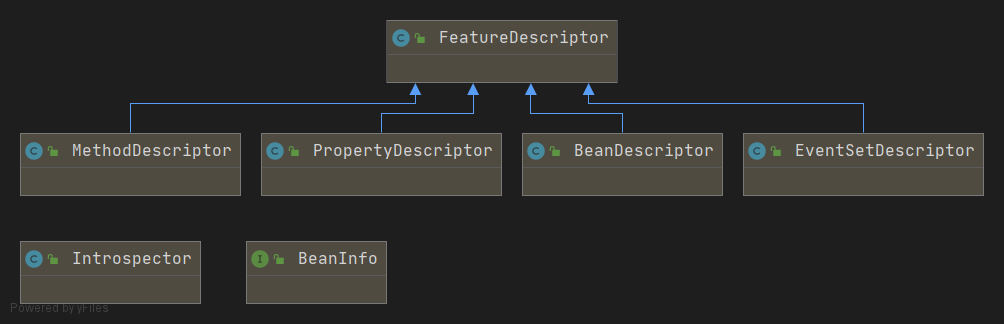
类 Introspector 通常是操作内省 API 的入口类,该类只有一个 “私有” 的构造方法:
private Introspector(Class<?> beanClass, Class<?> stopClass, int flags)throws IntrospectionException {// 私有的构造方法}
只有一个私有的构造方法也就意味着无法在外部创建一个 Introspector 类型的实例对象,查看源码后你会发现该类中仅仅有如下几个可对外操作的静态方法:
public static BeanInfo getBeanInfo(Class<?> beanClass){}public static BeanInfo getBeanInfo(Class<?> beanClass, int flags){}public static BeanInfo getBeanInfo(Class<?> beanClass, Class<?> stopClass){}public static BeanInfo getBeanInfo(Class<?> beanClass, Class<?> stopClass, int flags){}public static String decapitalize(String name){}public static void flushCaches(){}public static void flushFromCaches(Class<?> clz){}
而我们实际上关系的方法只有 getBeanInfo(),因为该方法可以得到一个 BeanInfo 类型的对象,先看下 BeanInfo 接口 “主要” 有哪些方法(只展示我们实际需要关心的方法):
public interface BeanInfo {BeanDescriptor getBeanDescriptor();MethodDescriptor[] getMethodDescriptors();PropertyDescriptor[] getPropertyDescriptors();EventSetDescriptor[] getEventSetDescriptors();}
这个一看,似乎发现了不得了的东西。 BeanInfo 接口内部定义的抽象方法返回的类型似乎都是上面 UML 图中 FeatureDescriptor 类的子类,而这些类又恰恰是我们实际需要关心的对象。
至于 decapitalize() 方法,我们仅仅需要将该方法当做工具类使用。因为该方法的主要作用是将变量首字母转小写,比如如下代码:
String uname = Introspector.decapitalize("Username");// uname 值为 username
至于 flushCaches 和 flushFromCaches 方法,不知道……….
现在我们就来看下 getBeanInfo 方法,首先定义一个普通的 Java 类:
public class User {private String username;private Integer age;private String profession;public String getUsername() {return username;}public void setUsername(String username) {this.username = username;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public String getProfession() {return profession;}public void setProfession(String profession) {this.profession = profession;}}
| 说明 |
|---|
注意上面类中的 getter/setter方法! |
我们现在就是用内省 API 来操作一下该类:
BeanInfo beanInfo = Introspector.getBeanInfo(User.class);
我们首先就得到 BeanInfo 对象。
而我们要注意的是 BeanInfo 这个对象,这个对象中定义的主要的四各方法所返回的对象都是我们需要关心的。而 FeatureDescriptor 又是这些类的父类,所以我们要首先看下这个类的信息:
FeatureDescriptor
FeatureDescriptor 这个类是 BeanDescriptor、MethodDescriptor、PropertyDescriptor 以及 EventSetDescriptor 四个类的父类。这个类主要是的作用是设置和获取基本信息。
public class FeatureDescriptor {private boolean expert;private boolean hidden;private boolean preferred;private String shortDescription;private String name;private String displayName;private Hashtable<String, Object> table;// getter/setter ...}
而我们之后用的最多的就是 name 这个方法了,其他的没什么必要解释的,事实上我们最需要关心的是它的子类 PropertyDescriptor。所以其他类都不做过多解释,自己简单看看源码就能明白了。
BeanDescriptor
BeanDescriptor beanDescriptor = beanInfo.getBeanDescriptor();
BeanDescriptor 对象指的就是 Class 的基本信息,比如名称:
System.out.println(beanDescriptor.getName());// 打印结果: User
现在看下 BeanDescriptor 对象创建的过程,在 BeanDescriptor 这个类中有一个私有的 getBeanInfo() 方法:
private BeanInfo getBeanInfo() throws IntrospectionException {BeanDescriptor bd = getTargetBeanDescriptor();MethodDescriptor mds[] = getTargetMethodInfo();EventSetDescriptor esds[] = getTargetEventInfo();PropertyDescriptor pds[] = getTargetPropertyInfo();int defaultEvent = getTargetDefaultEventIndex();int defaultProperty = getTargetDefaultPropertyIndex();return new GenericBeanInfo(bd, esds, defaultEvent, pds,defaultProperty, mds, explicitBeanInfo);}
| 说明 |
|---|
在这个方法中有四个 getTargetXx方法,这个是创建内省 API 对象的第一个调用栈,在之后不再做说明,之后只会直接说调用某个 getTargetXX方法。 |
其中 BeanDescriptor 对象就是通过调用 getTargetBeanDescriptor() 创建而来。这个方法的执行逻辑很简单:
private BeanDescriptor getTargetBeanDescriptor() {// Use explicit info, if available,if (explicitBeanInfo != null) {BeanDescriptor bd = explicitBeanInfo.getBeanDescriptor();if (bd != null) {return (bd);}}// 我们只需要关心这个 new BeanDescriptor() 即可return new BeanDescriptor(this.beanClass, findCustomizerClass(this.beanClass));}
在这个方法中直接调换用了 BeanDescriptor 的构造方法:
public class BeanDescriptor extends FeatureDescriptor {public BeanDescriptor(Class<?> beanClass) { }public BeanDescriptor(Class<?> beanClass, Class<?> customizerClass) { }}
很明显,我们要关心的是第二个有两个参数的构造方法的逻辑:
public BeanDescriptor(Class<?> beanClass, Class<?> customizerClass) {// ...String name = beanClass.getName();while (name.indexOf('.') >= 0) {name = name.substring(name.indexOf('.')+1);}setName(name);}
看一眼就明白了,直接获取类的权限定名,进行剥离,知道去除所有的包名。现在知道我们上面调用 beanDescriptor.getName() 为什么得到的是 User 了吧。
MethodDescriptor
MethodDescriptor[] methodDescriptors = beanInfo.getMethodDescriptors();
MethodDescriptor 对象主要包含的是信息类中方法的信息,这里返回的是一个数组对象的原因也很好理解:每个类中都存在多个方法。
创建该对象主要调用的是 java.beans.Introspector#getTargetMethodInfo 方法:
private MethodDescriptor[] getTargetMethodInfo() {if (methods == null) {methods = new HashMap<>(100);}// ...// 代码一: 注意这里的 superBeanInfoif (explicitMethods == null && superBeanInfo != null) {// 注意这个 superBeanInfo.getMethodDescriptors() 方法MethodDescriptor supers[] = superBeanInfo.getMethodDescriptors();for (int i = 0 ; i < supers.length; i++) {addMethod(supers[i]);}}// ...if (explicitMethods != null) {// ...} else {// 代码二: 注意这里只获取 public 方法Method methodList[] = getPublicDeclaredMethods(beanClass);// Now analyze each method.for (int i = 0; i < methodList.length; i++) {Method method = methodList[i];if (method == null) {continue;}// 代码三: 创建对象MethodDescriptor md = new MethodDescriptor(method);addMethod(md);}}// Allocate and populate the result array.MethodDescriptor result[] = new MethodDescriptor[methods.size()];result = methods.values().toArray(result);return result;}
这个方法的逻辑看起来很长,其实仔细看下来还是蛮简单的。
在 代码一 处有一个判断 explicitMethods == null && superBeanInfo != null 。这个判断怎么来的先不管,但是我们要先看下这个判断里面的处理逻辑:
MethodDescriptor supers[] = superBeanInfo.getMethodDescriptors();
这是不就是获取 superBeanInfo 中声明的方法呀,那么这个应用到底在哪呢?在之前我们不是已经获取到 methodDescriptors 对象了吗?看下下面的代码:
for (MethodDescriptor methodDescriptor : methodDescriptors) {// Method method = methodDescriptor.getMethod();System.out.println(methodDescriptor.getName());}
这里是不是就是打印方法名称呀(这个 getName() 与 BeanDescriptor 同理)?看下输出结果是什么:
getClasssetProfessionsetAgegetAgewaitnotifyAllnotifywaitgetUsernamehashCodesetUsernamegetProfessionwaitequalstoString
嗯….. 有点出乎意料,我们在 User 这个类中实际定义的了那些方法?为什么 getClass 、wait 方法都出来了?
实际上,该方法是 Object 中的方法。我们都知道 Object 是所有类的顶级父类,这个很好理解。至于为什么会得到父类的方法,还记得最开始说的 Java 内省的入口类 Introspector 只提供了一个私有的构造方法?看下该私有的构造方法干了什么事情:
private Introspector(Class<?> beanClass, Class<?> stopClass, int flags)throws IntrospectionException {// do something ....if (stopClass != null) {boolean isSuper = false;for (Class<?> c = beanClass.getSuperclass(); c != null; c = c.getSuperclass()) {if (c == stopClass) {isSuper = true;}}// do something ....}// 注意这里Class<?> superClass = beanClass.getSuperclass();if (superClass != stopClass) {int newFlags = flags;if (newFlags == IGNORE_IMMEDIATE_BEANINFO) {newFlags = USE_ALL_BEANINFO;}superBeanInfo = getBeanInfo(superClass, stopClass, newFlags);}// do something ....}
这么一看,似乎就明白了。它内部在获取自身的内省信息时同样调用了父类的信息:
Class<?> superClass = beanClass.getSuperclass();
想一下,这里调用了 beanClass.getSuperclass() 方法那我们这里 代码一 的条件判断是不就就成立了?条件成立是不是就走里面的判断逻辑获取方法了?这是不是就导致我们得到的 BeanInfo 中自然而然的就包括的父类的信息了?所以,代码一 的应用就在这里。
如何阻止父类的信息呢?还知道我们最开始创建 BeanInfo 对象执行的方法?
public static BeanInfo getBeanInfo(Class<?> beanClass){}public static BeanInfo getBeanInfo(Class<?> beanClass, int flags){}public static BeanInfo getBeanInfo(Class<?> beanClass, Class<?> stopClass){}
我们调用的是不是第一个方法?再看下构造方法获取父类内省信息时如何处理的:
if (superClass != stopClass) {int newFlags = flags;if (newFlags == IGNORE_IMMEDIATE_BEANINFO) {newFlags = USE_ALL_BEANINFO;}superBeanInfo = getBeanInfo(superClass, stopClass, newFlags);}
也就是说,放 superClass 不为 stopClass 时就回去父类。而第三个重载 getBeanInfo 方法是不是就支持该参数?所以,我们如果不想获取父类的内省信息时只需要使用第三个方法即可,比如不获取 Object 的内省信息:
BeanInfo beanInfo = Introspector.getBeanInfo(User.class, Object.class);
这样,我们再次打印 methodDescriptors 的名称时就没有 Object 类中定义的方法了:
setAgesetProfessiongetAgegetUsernamesetUsernamegetProfessiontoString
现在,再来看下看下 MethodDescriptor 类中的主要方法:
public class MethodDescriptor {public String getName() {}public synchronized Method getMethod() {}public ParameterDescriptor[] getParameterDescriptors(){}// 其他略 ...}
其中,getParameterDescriptors() 方法指的就是该方法的参数信息。getMethod() 方法返回的是一个 Method 对象,这个是反射的知识了,这里不多说。最后一个 getName() 方法指的是方法名:
for (MethodDescriptor methodDescriptor : methodDescriptors) {// Method method = methodDescriptor.getMethod();// 拿到这个 Method 对象还不是想干什么干什么?System.out.println(methodDescriptor.getName());}
当然,这里需要说明的一点是。我们能够通过 MethodDescriptor 对象获取到 Method 对象,而这个 Method 又可以利用反射,所以具体可以怎么使用就不必做过多解释了吧~
PropertyDescriptor
这个 API 可能是我们最需要关心的一个内省 API 了,因为 Spring 框架在解决依赖注入时就借助了该对象。
PropertyDescriptor[] propertyDescriptors = beanInfo.getPropertyDescriptors();
该对象中主要的方法如下四个方法:
public class PropertyDescriptor extends FeatureDescriptor {public synchronized Method getReadMethod(){};public synchronized void setReadMethod(Method readMethod){};public synchronized Method getWriteMethod() {}public synchronized void setWriteMethod(Method writeMethod){}}
在这个对象中是不是定义了几个方法?Read 和 Write,那这又是什么呢?想弄清楚这个问题我们还是要看下这个对象创建方法:java.beans.Introspector#getTargetPropertyInfo,我们在调用 API 时所谓的 Read/Write 方法都是在其内部处理的。
不过首先我们需要先说下在 Introspector 内部定义了几个常量:
public class Introspector {static final String ADD_PREFIX = "add";static final String REMOVE_PREFIX = "remove";static final String GET_PREFIX = "get";static final String SET_PREFIX = "set";static final String IS_PREFIX = "is";}
而这些常量都有什么作用呢?别急,看下 getTargetPropertyInfo() 方法就都明白了:
private PropertyDescriptor[] getTargetPropertyInfo() {// ...// 获取所有 public 方法Method methodList[] = getPublicDeclaredMethods(beanClass);for (int i = 0; i < methodList.length; i++) {Method method = methodList[i];if (method == null) {continue;}// 如果是静态方法就跳过int mods = method.getModifiers();if (Modifier.isStatic(mods)) {continue;}String name = method.getName();Class<?>[] argTypes = method.getParameterTypes();Class<?> resultType = method.getReturnType();int argCount = argTypes.length;PropertyDescriptor pd = null;if (name.length() <= 3 && !name.startsWith(IS_PREFIX)) {// Optimization. Don't bother with invalid propertyNames.continue;}try {// 代码一if (argCount == 0) {if (name.startsWith(GET_PREFIX)) {// Simple getterpd = new PropertyDescriptor(this.beanClass, name.substring(3), method, null);} else if (resultType == boolean.class && name.startsWith(IS_PREFIX)) {// Boolean getterpd = new PropertyDescriptor(this.beanClass, name.substring(2), method, null);}// 代码二} else if (argCount == 1) {if (int.class.equals(argTypes[0]) && name.startsWith(GET_PREFIX)) {pd = new IndexedPropertyDescriptor(this.beanClass, name.substring(3), null, null, method, null);} else if (void.class.equals(resultType) && name.startsWith(SET_PREFIX)) {// Simple setterpd = new PropertyDescriptor(this.beanClass, name.substring(3), null, method);if (throwsException(method, PropertyVetoException.class)) {pd.setConstrained(true);}}// 代码三} else if (argCount == 2) {if (void.class.equals(resultType) && int.class.equals(argTypes[0]) && name.startsWith(SET_PREFIX)) {pd = new IndexedPropertyDescriptor(this.beanClass, name.substring(3), null, null, null, method);if (throwsException(method, PropertyVetoException.class)) {pd.setConstrained(true);}}}} catch (IntrospectionException ex) {pd = null;}if (pd != null) {// do something ...}// do something ...}}
我们来看下这段代码逻辑。
首先,获取声明的说有 public 方法,这也验证了为什么 getter/setter 一定要是 public 了。之后在循环中第一部排除的就是静态方法。
之后在 代码一 处,判断当是无参方法时继续做两个判断。当方法以 get 开头就创建一个 PropertyDescriptor 对象。当方法返回类型是 Boolean 且方法以 is 作为前缀时同样创建一个 PropertyDescriptor 对象。我们现在要关心的是这个对象创建时调用的构造方法:
PropertyDescriptor(Class<?> bean, String base, Method read, Method write);
这么一看似乎都明白了什么是 Read 方法了是吧,同时这个构造方法 base 参数的值是不是就是方法去除前缀呀?现在再回头看我们定义的 getXx 方法突然就豁然开朗了。
再来看下 代码二,在这个判断中我们主要关心的是对于 setter 的判断逻辑:当方法只有一个参数,且无返回值时创建一个 PropertyDescriptor 对象。看参数顺序,这是有个 Write 方法。
至于 IndexedPropertyDescriptor,我们来看下这个类的继承关系以及构造方法:
public class IndexedPropertyDescriptor extends PropertyDescriptor {// ...IndexedPropertyDescriptor(Class<?> bean, String base, Method read, Method write, Method readIndexed, Method writeIndexed) throws IntrospectionException {super(bean, base, read, write);// 注意这里setIndexedReadMethod0(readIndexed);setIndexedWriteMethod0(writeIndexed);setIndexedPropertyType(findIndexedPropertyType(readIndexed, writeIndexed));}}
这个类继承至 PropertyDescriptor ,在内部定义了构造方法,看下这个构造方法对 readIndexed/writeIndexed 处理逻辑基本上就不需要做其他解释了。
现在再来看拿到这个 PropertyDescriptor 对象之后能干那些事情。首先,我能能够调用它的 getReadMethod()/getWriteMethod() 方法。这是不是又回到 MethodDescriptor 了?是不是可以利用反射操作对象?
到此,都应该明白了 Java 的内省机制了吧。同时,如果看过 Spring 的依赖注入源码部分的同学也应该明白为什么 Spring 的依赖注入模式 BY_NAME/BY_TYPE 为什么 setter 注入与 set 方法后面的名称无关了吧~
后记
学习本没有捷径,只有用最笨的方法坚持去学方有收获🌷🌷🌷🌷~

若有收获,就点个赞吧
0 人点赞
