Apache 的 Commons Compress 类库是专门为对处理文件解压缩而实现的 Java 类库。该类库定义了很多的 API,我们可以利用这些 API 实现各种类型的文档压缩与解压。
目前该类库(当前最新版本 v1.21)支持的归档文件格式很多,完全能够满足我们日常开发需要。下面是 Apache 官网说明能够支持的归档文件类型:
ar、cpio、Unix dump、tar、zip、gzip、XZ、Pack200、bzip2、7z、arj、lzma、snappy、DEFLATE、lz4、Brotli、Zstandard、DEFLATE64 and Z files。
我们在开发中使用 commons-compress 类库主要有创建压缩文件和解压压缩文件两个需求,下面就来简单介绍该类库。
Commons-Compress 类库官网地址是:https://commons.apache.org/proper/commons-compress
Commons-Compress GitHUb仓库地址是:https://github.com/apache/commons-compress
在项目中还用该类库我们需要将其依赖包添加到我们到项目中:
Maven 方式:
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-compress</artifactId><version>${version}</version></dependency>
Gradle 方式:
implementation group: 'org.apache.commons', name: 'commons-compress', version: '${version}'
压缩与解压类库说明
commons-compress 类库中用于创建压缩文件和解压文件的类都在 org.apache.commons.compress.archivers 包下。
用于创建压缩的类
用于创建压缩文件的基础类是 org.apache.commons.compress.archivers.ArchiveOutputStream,该类是一个抽象类,继承至 Java 标准类库的 java.io.OutputStream。另外,该类还有多个具体的子类,可用于创建具体的归档文件对象。
类继承图如下:
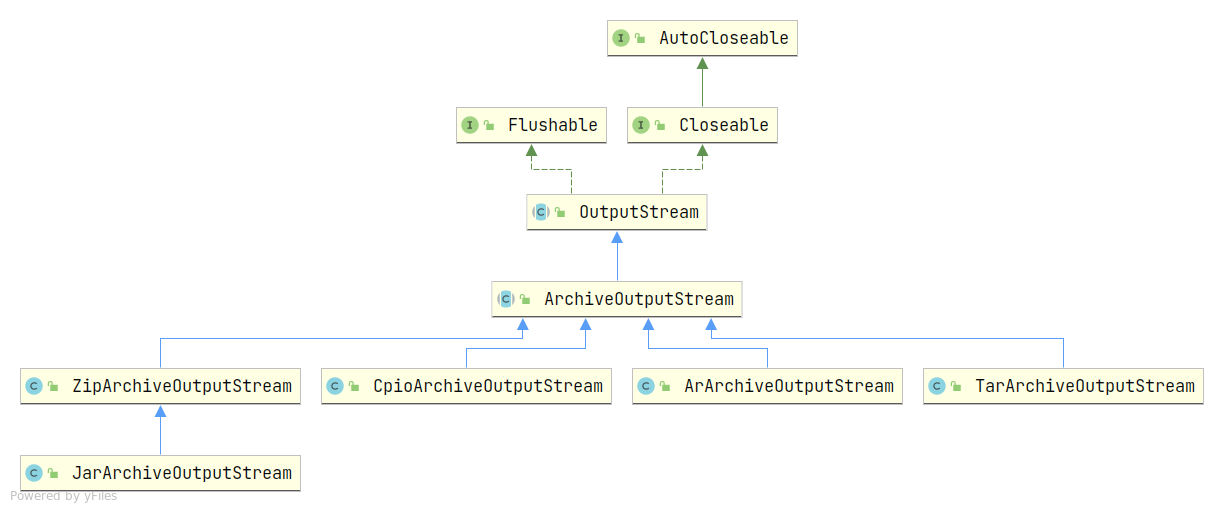
在使用时,我们需要根据要创建的压缩文件类型来创建具体的压缩对象,比如想要创建 zip 压缩文件就需要创建一个对应的 ZipArchiveOutputStream 对象即可。
另外, org.apache.commons.compress.archivers 包下还有一个工厂类 ArchiveStreamFactory。该工厂类提供了一个 createArchiveOutputStream(...) 方法可供我们使用,稍后会具体介绍。
用于解压文件的类
用于创建解压文件的基础类是:org.apache.commons.compress.archivers.ArchiveInputStream。与 ArchiveOutputStream 一样该类也有多个具体的扩展类,类图如下:
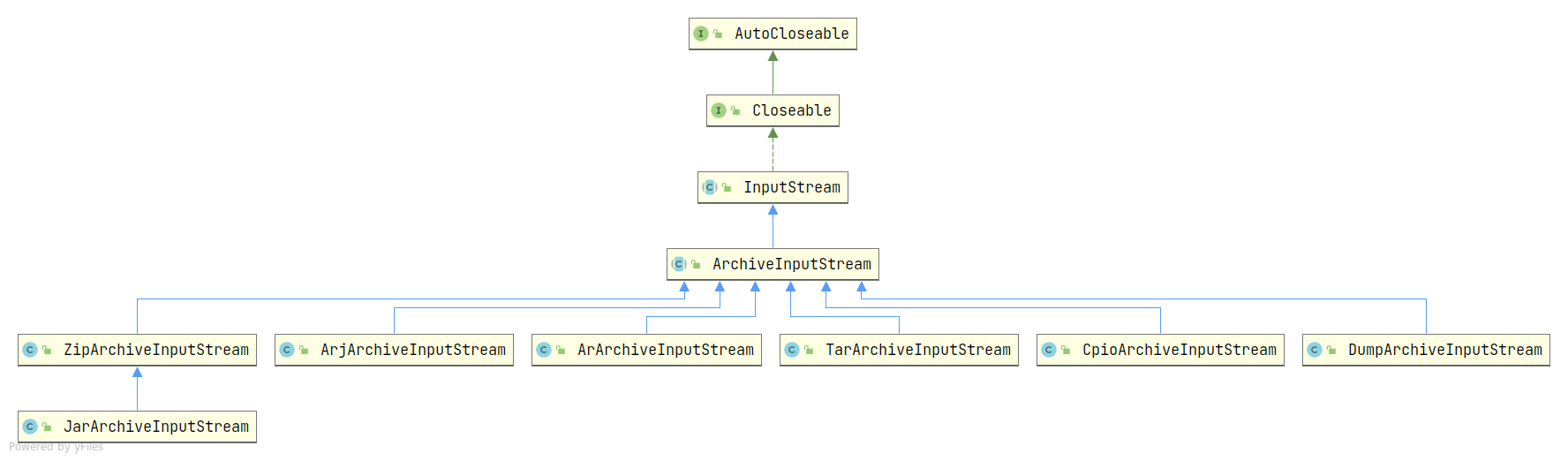
可以看到,该基础类有更多的扩展类。也就是说,相比较创建压缩文件而言,用于解压文件的类支持更多的类型。比如不支持创建 dump 类型压缩文件,但是而却支持解压 dump 类型文件。
而实际使用方法也很简单,创建一个具体的子类即可。如要解压 ZIP 文件,那就创建一个 ZipArchiveInputStream 对象即可。
另外前面说的用于创建压缩文件的工厂类 ArchiveStreamFactory 同样也支持创建用于解压文件的对象。
用于解压和压缩的工厂类
工厂类 ArchiveStreamFactory 是一个普通的类,内部也没有什么静态方法,在实际使用时还是需要使用 NEW 进行创建。在该工厂类内部定义了一些常量,这些常量就是该工厂方法支持的压缩类型(但不是全部),如下:
public static final String AR = "ar";public static final String ARJ = "arj";public static final String CPIO = "cpio";public static final String DUMP = "dump";public static final String JAR = "jar";public static final String TAR = "tar";public static final String ZIP = "zip";public static final String SEVEN_Z = "7z";
另外,该工厂类还实现了 ArchiveStreamProvider 接口,如下:
public class ArchiveStreamFactory implements ArchiveStreamProvider {// omit ...}
下面来说下接口类 ArchiveStreamProvider,该接口类定义了四个抽象方法。如下:
public interface ArchiveStreamProvider {/*** 创建解压对象*/ArchiveInputStream createArchiveInputStream(final String name, final InputStream in, final String encoding);/*** 支持解压缩的类型*/Set<String> getInputStreamArchiveNames();/*** 创建压缩对象*/ArchiveOutputStream createArchiveOutputStream(final String name, final OutputStream out, final String encoding);/*** 支持创建的压缩类型*/Set<String> getOutputStreamArchiveNames();}
这四个方法我们主要需要关注的是两个 create 方法,分别是用于创建压缩文件的 createArchiveOutputStream 方法和用于解压文件的 createArchiveInputStream 方法。
另外还有两个 get 方法,这两个返回的都是 Set 集合对象,分别是 createArchiveOutputStream 方法支持的压缩类型和 createArchiveInputStream 方法支持的解压类型,在实际使用中很有用。
现在来看下用于创建归档对象的 createArchiveOutputStream 方法:
创建压缩文件工厂方法 createArchiveOutputStream
用于创建压缩对象的方法 createArchiveOutputStream 有三个参数,如下:
ArchiveOutputStream createArchiveOutputStream(final String name, final OutputStream out, final String encoding)
参数 name 指的是具体的压缩类型,如 zip、jar。而不是压缩文件的名称,这点需要注意。在前面也说了工厂方法内部定义了多个常量,这个 name 的值就是那些常量中的其中一个。另外,也不是支持所有的压缩类型。该方法支持创建哪些类型的压缩文件还要看 getOutputStreamArchiveNames 方法内部的逻辑,该方法会返回一个集合,其中的值就是该方法支持的归档类型。实现类中的代码如下:
@Overridepublic Set<String> getOutputStreamArchiveNames() {return Sets.newHashSet(AR, ZIP, TAR, JAR, CPIO, SEVEN_Z);}
你会集合看到中有个 SEVEN_Z 常量,这个就是 7z 压缩类型的意思。但是实际上该方法并不支持创建 7z 的压缩文件,稍后会进行说明。
第二个参数 out 就是具体要创建的对象流。比如你如果想要将创建的压缩文件存储到磁盘,那就创建一个 FileOutputStream 对象即可,但是如果你想要用于网络下载的话,那就直接给 HttpServletResponse.getOutputStream() 对象传过来即可。
第三个参数 encoding 指的是编码,如 GBK、UTF-8。但是要注意,这个编码是有问题的,比如创建 ZIP 压缩时即使传递编码也会出现中文乱码的问题,这个在之后具体的示例中会做说明。
下载来看下实现类的方法,在实现类中除了有一个重写该抽象方法的方法之外还有一个对应的重载方法,如下:
public ArchiveOutputStream createArchiveOutputStream(final String archiverName, final OutputStream out)throws ArchiveException {return createArchiveOutputStream(archiverName, out, entryEncoding);}
该重载方法仅仅少了一个 encoding 参数,这个也就没必要说的。现在来具体看下重写方法,代码如下:
@Overridepublic ArchiveOutputStream createArchiveOutputStream(final String archiverName, final OutputStream out, final String actualEncoding)throws ArchiveException {// 验证压缩类型if (archiverName == null) {throw new IllegalArgumentException("Archivername must not be null.");}// 输出的io流if (out == null) {throw new IllegalArgumentException("OutputStream must not be null.");}// 判断是否是 ar 压缩文件if (AR.equalsIgnoreCase(archiverName)) {return new ArArchiveOutputStream(out);}// 判断是否是 zip 压缩文件if (ZIP.equalsIgnoreCase(archiverName)) {final ZipArchiveOutputStream zip = new ZipArchiveOutputStream(out);if (actualEncoding != null) {zip.setEncoding(actualEncoding);}return zip;}// 判断是否是 tar 压缩文件if (TAR.equalsIgnoreCase(archiverName)) {if (actualEncoding != null) {return new TarArchiveOutputStream(out, actualEncoding);}return new TarArchiveOutputStream(out);}// 判断是否是 jar 压缩文件if (JAR.equalsIgnoreCase(archiverName)) {if (actualEncoding != null) {return new JarArchiveOutputStream(out, actualEncoding);}return new JarArchiveOutputStream(out);}// 判断是否是 cpio 压缩文件if (CPIO.equalsIgnoreCase(archiverName)) {if (actualEncoding != null) {return new CpioArchiveOutputStream(out, actualEncoding);}return new CpioArchiveOutputStream(out);}// 🔔注意, 这里返回的不是 7z 压缩对象. 而是抛出一个异常if (SEVEN_Z.equalsIgnoreCase(archiverName)) {throw new StreamingNotSupportedException(SEVEN_Z);}// SPI 机制获取是否有符合的压缩类型final ArchiveStreamProvider archiveStreamProvider = getArchiveOutputStreamProviders().get(toKey(archiverName));if (archiveStreamProvider != null) {return archiveStreamProvider.createArchiveOutputStream(archiverName, out, actualEncoding);}// 上面都没有直接抛出异常throw new ArchiveException("Archiver: " + archiverName + " not found.");}
上面的代码比较简单,就是多个 if 判断,每个 if 都是判断是否是某个压缩类型,如果是的话就返回一个具体的压缩对象,这与我们直接创建也没啥区别不是?
另外,需要注意看对 7z 压缩的判断,如下:
if (SEVEN_Z.equalsIgnoreCase(archiverName)) {throw new StreamingNotSupportedException(SEVEN_Z);}
注意看,这里抛出的是一个异常,也就是说不支持创建 7z 压缩文件,但是再看一下 getOutputStreamArchiveNames 方法的实现:
@Overridepublic Set<String> getOutputStreamArchiveNames() {return Sets.newHashSet(AR, ZIP, TAR, JAR, CPIO, SEVEN_Z);}
你会发现居然包含 7z,这里就比较奇怪了,不知道为啥。
之后再看一下最后一个 if 的判断,这里是一个 SPI 机制,也就是说会读取 classpath 下 SPI 接口,要求是该接口与该工厂方法一样都实现了 ArchiveStreamProvider 接口。这就是一个扩展点不是?
final ArchiveStreamProvider archiveStreamProvider = getArchiveOutputStreamProviders().get(toKey(archiverName));if (archiveStreamProvider != null) {return archiveStreamProvider.createArchiveOutputStream(archiverName, out, actualEncoding);}
这么一看,除非使用了扩展点,否则还是直接使用具体类创建对象比较方便,当然也是个人建议吧~
接下来看下用于创建解压归档文件的工厂方法吧:
创建解压文件工厂方法 createArchiveInputStream
与创建压缩工厂方法一样,该方法处理逻辑也差不多。区别是不像创建压缩对象方法,该方法支持的解压对象更多。下看下 getInputStreamArchiveNames 方法的实现:
@Overridepublic Set<String> getInputStreamArchiveNames() {return Sets.newHashSet(AR, ARJ, ZIP, TAR, JAR, CPIO, DUMP, SEVEN_Z);}
注意看集合内容,工厂类上面定义的解压类型常量这里居然都支持(但是 7z 实际上还是不支持),与创建压缩有些小区别。来看下如何创建解压对象的:
@Overridepublic ArchiveInputStream createArchiveInputStream(final String archiverName, final InputStream in,final String actualEncoding) throws ArchiveException {if (archiverName == null) {throw new IllegalArgumentException("Archivername must not be null.");}if (in == null) {throw new IllegalArgumentException("InputStream must not be null.");}// 判断是否为 ar 解压if (AR.equalsIgnoreCase(archiverName)) {return new ArArchiveInputStream(in);}// 判断是否为 arj 解压if (ARJ.equalsIgnoreCase(archiverName)) {if (actualEncoding != null) {return new ArjArchiveInputStream(in, actualEncoding);}return new ArjArchiveInputStream(in);}// 判断是否为 zip 解压if (ZIP.equalsIgnoreCase(archiverName)) {if (actualEncoding != null) {return new ZipArchiveInputStream(in, actualEncoding);}return new ZipArchiveInputStream(in);}// 判断是否为 tar 解压if (TAR.equalsIgnoreCase(archiverName)) {if (actualEncoding != null) {return new TarArchiveInputStream(in, actualEncoding);}return new TarArchiveInputStream(in);}// 判断是否为 jar 解压if (JAR.equalsIgnoreCase(archiverName)) {if (actualEncoding != null) {return new JarArchiveInputStream(in, actualEncoding);}return new JarArchiveInputStream(in);}// 判断是否为 cpio 解压if (CPIO.equalsIgnoreCase(archiverName)) {if (actualEncoding != null) {return new CpioArchiveInputStream(in, actualEncoding);}return new CpioArchiveInputStream(in);}// 判断是否为 dump 解压if (DUMP.equalsIgnoreCase(archiverName)) {if (actualEncoding != null) {return new DumpArchiveInputStream(in, actualEncoding);}return new DumpArchiveInputStream(in);}// 🔔注意这里还是不支持 7z 解压if (SEVEN_Z.equalsIgnoreCase(archiverName)) {throw new StreamingNotSupportedException(SEVEN_Z);}// SPI 扩展点final ArchiveStreamProvider archiveStreamProvider = getArchiveInputStreamProviders().get(toKey(archiverName));if (archiveStreamProvider != null) {return archiveStreamProvider.createArchiveInputStream(archiverName, in, actualEncoding);}throw new ArchiveException("Archiver: " + archiverName + " not found.");}
嗯… 这没必要说了,与创建归档文件对象逻辑一样。唯一需要注意的是,该工厂方法同样不支持对 7z 文件的解压!!!!

若有收获,就点个赞吧
0 人点赞
