1 hello world
新建文件demo.py,添加如下内容
#!/usr/bin/pythonprint("hello world")print "who are you?"
运行
- python demo.py
- chmod a+x demo.py,给与demo.py执行权限, ./demo.py
运行结果

输出中文
#!/usr/bin/pythonprint("hello world")print "who are you?"print "你好"
非python3.x版本输出会报错,因为低版本版本中默认编码格式是ASCII格式,中默认的编码格式编码格式为ASCII格式,可以python文件中设置编码格式来消除次问题
第二行添加#-- coding:UTF-8 --或coding=utf-8即可
#!/usr/bin/env python#-*- coding:UTF-8 -*-

2 函数
规则:
- 以def关键字开头,后跟函数名和(),()中为参数列表通过”,”分隔
- 函数体以冒号起始,并且缩进
- 函数体不需要放到{}中
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None
def fun1(param1,param2):print "param1:",param1print "param2:",param2return "retstr"print fun1("111","222")
3 数据类型
Number
数字
- int,有符号整型
- long,有符号长整型
- float,浮点型
complex,复数,由实数部分和虚数部分组成,
 或complex(a,b)表示,a和b都是浮点型
或complex(a,b)表示,a和b都是浮点型
String
字符串,数字、字母、下划线组成,是编程语言中表示文本的数据类型。
字串列表有2种取值顺序:从左到右索引默认0开始的,最大范围是字符串长度少1
- 从右到左索引默认-1开始的,最大范围是字符串开头
可通过[头下标:尾下标] 的方截取字符串
str="0123456789"print strprint str[0:]print str[:3]print str[0:3]print str[-10:-7]

可通过[下标] 的方获取字符,和C/C++中类似
加号(+)是字符串连接运算符,
星号(*)是重复操作
str1="hello,"str2="world"str3=str1+str2print str3print str3*3

List
列表用 [ ] 标识,是 python 最通用的复合数据类型。
表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾。
list=["Mike",12,"Jone",13,"Jack",14,"Lucy",15]

列表截取时可以指定第三个参数,表示截取的步长,默认为1,步长为2时如下图所示
print list[0:4:2]
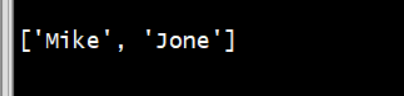
空列表添加元素
animal=[]animal.append("dog")animal.append("cat")animal.append("pig")print(animal)Len=len(animal) #列表长度为3
list长度
list=["Mike",12,"Jone",13,"Jack",14,"Lucy",15]`Len=len() #列表长度为3
Tuple
元组
元组是类似于 List,用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表
Dictionary
字典
列表为有序对象集合,字典为无序对象集合
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
dict={}dict["Mike"]="大狗"dict["Jone"]="二狗"dict["Jack"]="三狗"dict["Lucy"]="三狗"print "Mike=",dict["Mike"]print "Jone=",dict["Jone"]print "Jack=",dict["Jack"]print "Lucy=",dict["Lucy"]# 获取key的值,如key不存在,则返回default# get(,default)print "Mike=",dict.get("Mike","not found")

5 运算符
1. 算术运算符
| 运算符 | 描述 | 示例 | 优先级 | |
|---|---|---|---|---|
| 算术 | + | 加 | a+b (9+2=11) | |
| - | 减 | a-b (9-2) =7 | ||
| * | 乘 | ab (9 2)=18 | ||
| / | 除 | a/b (9 / 2)=4.5 | ||
| % | 取模 | a%b (9 % 2)=1 | ||
| ** | 幂 | ab (92) = 81 | ||
| // | 取整除(向下) | a//b (9//2) = 4 | ||
| 比较 | == | 等于 | ||
| != | 不等于 | |||
| > | 大于 | |||
| < | 小于 | |||
| >= | 大于等于 | |||
| <= | 小于等于 | |||
| 赋值 | = | 赋值 | ||
| += | 加赋值 | |||
| -= | 减赋值 | |||
| *= | 乘赋值 | |||
| /= | 除赋值 | |||
| %= | 取模赋值 | |||
| **= | 幂赋值 | |||
| //= | 取整除赋值 | |||
| 位运算 | & | 按位与 | ||
| | | 按位或 | |||
| ^ | 按位异或 | |||
| ~ | 按位取反 | |||
| << | 左移(高位丢失,低位补零) | |||
| >> | 右移 | |||
| 逻辑 | and | 逻辑与 | a and b(9 and 2 = 2, 2 and 9 = 9) |
|
| or | 逻辑或 | a or b(9 or 2=9, 2 or 9 = 2) |
||
| not | 逻辑非 | not a(not 2 = False, not False = True) |
||
| 成员 | in | 在指定序列 | ||
| not in | 未在指定序列 | |||
| 身份 | is | 引用同一对象 | ||
| not is | 引用不同对象 | |||
| () | ||||
| [ ] | ||||
| . |
6 条件语句
cond=Trueif cond:print("满足条件")else:print("不满足条件")
val=3if val==1:print("条件1")elif val==2:print("条件2")elif val==3:print("条件3")else:print("其它")
val = 3if val > 0 and val <5print("结果")if val <0 or val >5print("结果")
7 循环语句
for循环
#0-9for num in range(10):print(num)for letter in "Python":print(letter)animals=["dog","cat","snake"]for animal in animals:print(animal)
while循环
a=0while a < 10:a+=1print(a)
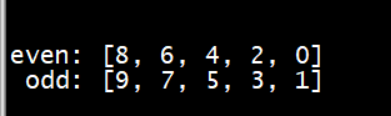
data=[0,1,2,3,4,5,6,7,8,9]even=[]odd=[]while len(data) != 0:n=data.pop()if(n%2 == 0):even.append(n)else:odd.append(n)print("even:",even)print(" odd:",odd)
8 文件I/O
从键盘输入
str=input("请输入:")print(str)
打开文件
# file object = open(file_name [, access_mode][, buffering])obj=open("hello.txt","w")#输出文件名print(obj.name)#查看文件是否关闭print(obj.closed)obj.write("hello\n")#关闭文件obj.close()
| mode | 描述 | |
|---|---|---|
| w | 只写模式,清空,创建新文件 | |
| r | 只读模式 | |
| w+ | 读写模式,清空,创建新文件 | |
| r+ | 读写模式 | |
| wb | 二进制只写模式,清空,创建新文件 | |
| rb | 二进制只读模式 | |
| wb+ | 二进制读写模式,清空,创建新文件 | |
| rb+ | 二进制只读写模式 | |
| a | 追加,创建新文件 | |
| ab | 二进制追加,创建新文件 | |
| a+ | 读写追加,创建新文件 | |
| ab+ | 二进制读写追加,创建新文件 |
9 异常
try:action 1expect err1:action 2expect err2:action3else:action4
10 模块学习
代码导入模块
import pexpect这种方法在使用模块函数时需要使用模块名称pexpect.spawn(ls -l)
命令行导入模块
>>> import pexpect>>> help(pexpect)>>> dir(pexpect) 打印该模块所有内容>>> help(pexpect.spawn) 查看帮助
1 pexpect模块
child=pexpect.spawn("ls -l")index=child.expect(["log.txt","tags"])expect的返回值index值为列表中元素索引,命中"log.txt"返回0.命中"tags"返回1,可以此开判断命中哪个期望child.before为命中expect值之前的部分,child.after为expect本身
11 符号
Python中 ''和 "" 单双引号含义相同,必要时可以规避转义
备注
提示缩减异常时需要确认对应行首是否有tab,将tag更换为空格可消除此问题
IndentationError: unexpected indent
字符串经split分割后为一个应该是一个字符串列表,通过len查看元素个数
12 bytes与hexStr转换
13 scapy
- 构造普通报文 ```python from scapy.all import *
pkts = []
payload=”\ \x46\x00\x00\x00\x54\x00\x00\x00\x65\x00\x10\x00\x00\x00\x41\x43\ \x50\x5a\x31\x30\x33\x31\x30\x39\x32\x35\x31\x57\x57\x57\x04\x00”
pkt = Ether()/IP(version=4,src=”124.89.180.152”)/TCP(sport=8911,dport=8890)/payload1
pkts.append(pkt); wrpcap(“test.pcap”, pkts)
- 显示报文```bash>>> p = rdpcap("get_doc.pcap") #打开报文>>> p[0] # 显示包0的内容

若有收获,就点个赞吧
0 人点赞
