简介
- HMaster所有的操作转换为程序,程序会有不同的阶段,这个阶段所处的状态就叫状态机
每个程序都有一个id,类似于PID,在Master的日志中就可以通过Pid跟踪这个程序
发现问题
MasterWebUI:在WebUI中可以看到表的状态,还可以看到Region的状态,如果表的状态的ENABLED,但是该表某个Region的状态不是OPEN,这就有问题了
Procedures & Locks:这个也是在MasterWebUI中,该页面展示了所有进行的Procedures和Locks,如果一个空闲的集群,Procedures & Locks依旧很多,那么就该排查排查问题了,使用下面两个命令也可以列出Procedures & Locks
$ echo "list_locks" | hbase shell &> /tmp/locks.txt$ echo "list_procedures" | hbase shell &> /tmp/procedures.txt
HbaseCanary:该工具主要是用来检查region assign的状态,命令使用如下
# -f false:遇到错误不要退出,继续执行# -t 6000000:最多运行的时间,毫秒hbase canary -f false -t 6000000 &>/tmp/canary.log
其他工具:要查看某张表所有Region的状态
echo "scan 'hbase:meta', {ROWPREFIXFILTER => 'tablename,', COLUMN => 'info:state'}" | hbase shell > /tmp/t.txt
修复原则
保证hbase:meta表是正常的,可以使用hbase hbck进行检查,然后将结果进行过滤,查看hbase:meta是否正常。因为后续的大多操作都是基于hbase:meta表来进行的
修复时要一张表一张表的进行修复
如果一个 Region 处于 CLOSING 状态,没有转换到CLOSED状态前,就不能被 assigned ,反之,如果它处于 OPENING 状态,那么它就不能被 unassigned。Region 状态必须总是从 CLOSED 到 OPENING 再到 OPEN 状态,然后再到 CLOSING 到 CLOSED 状态
如果表的状态为DISABLED,那么就无法分配该表的region,如果一个表的状态是DISABLED,但是该表有个Region出问题了状态时OPENING,那么就需要将该表的状态改为ENABLED,然后在对Region进行分配
修复问题
Assign/Unassign
- 一般 Assign/Unassign操作都会对Region持有一个排他锁,修复流程如下
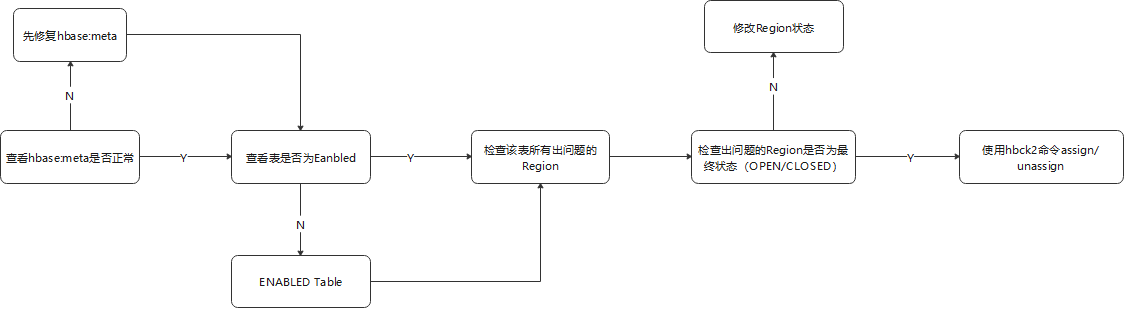
Missing Regions in hbase:meta
在某些情况下,hbase:meta会随机丢失一些region的信息,比较多的概率是使用了一些hbck1淘汰的命令如OfflineMetaRepair
这个命令还会输出一个assign命令,因为meta表中都没有该region的信息,所以region是需要重新分配的
使用hbck2的addFsRegionsMissingInMeta 进行修复,这条命令会扫描hdfs中Region目录的region_info的信息进行重建,最后在运行该命令输出的assign命令进行重新分配,修复流程如下

Extra Regions in hbase:meta
还有一些情况,表中的region数据已经删除,但是hbase:meta中还有该region的信息,这种情况有可能是split出问题,或者是手动将hdfs中的region数据给rm/mv了
使用hbck2的extraRegionsInMeta —fix进行修复,修复流程如下

hbase:meta 在线情况下的重建
如果hbase:meta不是损坏的特别严重,那么是可以进行在线修复的,可以使用scan命令来查询hbase:meta是否正常
echo "scan 'hbase:meta', {COLUMN=>'info:regioninfo'}" | hbase shell
如果上面的命令没有任何异常或者报错,就可以使用addFsRegionsMissingInMeta来修复元数据中丢失的region信息了
hbase:meta 不在线情况下的重建
如果出现以下日志,就说明hbase:meta都没有进行正常的assign了
2019-07-10 18:30:51,090 WARN [master/localhost:16000:becomeActiveMaster] master.HMaster: hbase:namespace,,1562808216225.725a0fe6c2c869d3d0a9ed82bfa80fa3. is NOT online; state={725a0fe6c2c869d3d0a9ed82bfa80fa3 state=CLOSED, ts=1562808619952, server=null}; ServerCrashProcedures=false. Master startup cannot progress, in holding-pattern until region onlined.
那么就需要手动进行assign了,要 assign hbase:namespace 表 Region 不能使用 hbase shell。如果使用 Hasee shell,将会发生 PleaseHoldException 异常,因为 Master 尚未启动(Master 只有等待 hbase:namespace 表上线后,才会声明自己为启动的)
必须使用 HBCK2 的 assigns 命令,还必须使用 -skip 命令来跳过 Master 版本检查(如果不使用 -skip 参数, HBCK2 调用也将引发使用 hbase shell 中 assign 命令的PleaseHoldException 异常,因为 Master 尚未启动)。操作示例如下
./bin/hbase org.apache.hbase.HBCK2 -skip assigns 725a0fe6c2c869d3d0a9ed82bfa80fa3
如果执行返回 “Connection refused”,那么就需要查看Master是否启动?如果 Master不能初始化自己,就会在一段时间后关闭自己。只需重新启动集群/Master并重新运行上面的 HBCK2 的 assigns 命令。
当 assigns 成功运行时,将看到它发出如下类似的信息。最后的 [48] 是分配过程 procedure 的pid。如果返回的pid是 [-1]就说明assign失败
18:40:43.817 [main] WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable18:40:44.315 [main] INFO org.apache.hbase.HBCK2 - hbck support check skipped[48]
重建 hbase:meta 表后增加的用户表处于 DISABLED 状态并且其 Region 处于 CLOSED 模式。需要重新 enable 用户表,使表的所有 Region 在线。
enable_all ".*"
总结
其实HBase-2.x版本的运维思路很简单,因为使用了procedure,集群出现meta跟regionserver不一致的状态是很少的,一般都是有procedure出问题了。那么我们主要就是看怎么解决这个有问题的procedure。
如果是table/namespace级别的修改,因为设计到很多region的锁,如果需要bypass的话需要找到root procedure然后使用bypass -or.
如果只是region级别的问题,则bypass -o即可。
bypass之后检查locks的页面,看看是不是锁都释放了,如果没有锁了则根据需求进行assign或者unassign,或者对table的属性进行还原

若有收获,就点个赞吧
0 人点赞
