图像识别的任务
目标识别:输出类别
目标检测:输出类别和在图像中的位置
目标分割:把物体形状描述出来,背景进行分割
目标检测概述
位置
一般有两种格式
- 极坐标(xmin,xmax,ymin,ymax)
-
目标检测技术发展
传统目标检测方法(候选区域+手工特征提取+分类器)
- HOG+SVM.DPM
- region proposal+CNN提取分类的目标检测框架
- (R-CNN,SPP-NET,Fast R-CNN,Faster R-CNN)
端到端的(End-to-End)的目标检测框架
两步走的目标检测:先进行区域推荐,而后进行目标分类
- 代表:RCNN,SPPnet,Fast RCNN,Faster RCNN
端到端的目标检测:采用一个网络一步到位
分类:输入图片得到类别和标签
- 定位:输入图片得到位置坐标,用IOU(交并比)计算偏差
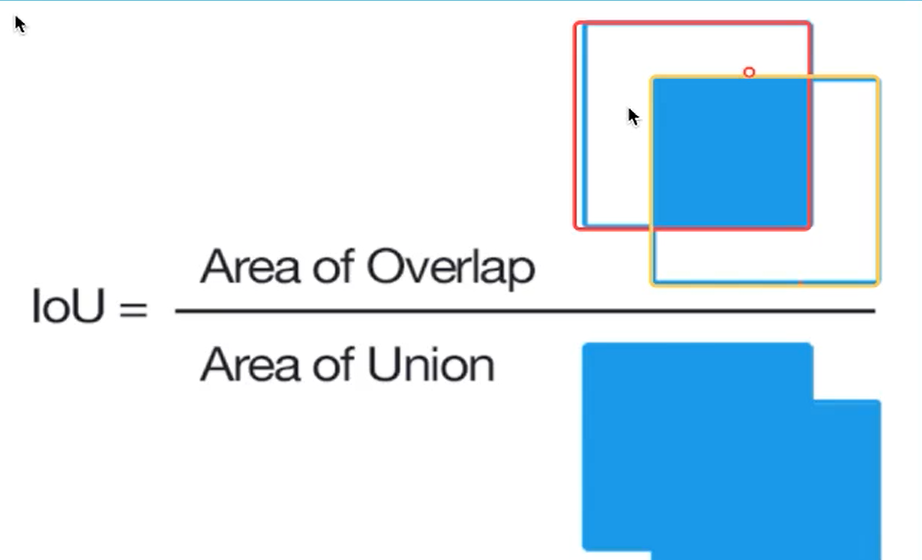
- 目标定位的简单实现


R- CNN——CVPR2014提出

对于一张照片里面多个目标,且目标数量不确定,多加一个全连接层的分类方法无法实现,即网络的输出不确定
RCNN步骤

- 找出可能存在的候选区域,得出2000个候选区域,进行图片大小调整适应AlexNet网络的输入大小227*227,
- 通过选择性搜索算法,候选区域,crop+warp调整图片大小

- 通过CNN对候选区域提取特征向量,2000个建议框的特征向量组成2000*4096维矩阵
- 将多维矩阵与20个SVM组成的409620权值矩阵相乘(20种分类,SVM是二分类器),得到200020维矩阵
- 分别对2000*20维矩阵进行非最大值抑制(NMS),这样剔除重叠建议框,得到得分最高的建议框
- 修正boundry box,对bbox做回归微调
训练过程








RCNN速度慢在哪里?
2000个候选区域都要经过卷积,图片变形,而SPPNet一张图片全部经过卷积,去掉crop+warp操作
SPPNet

两点改进,提出了SPP层
- 减少卷积计算
- 防止图片内容变形

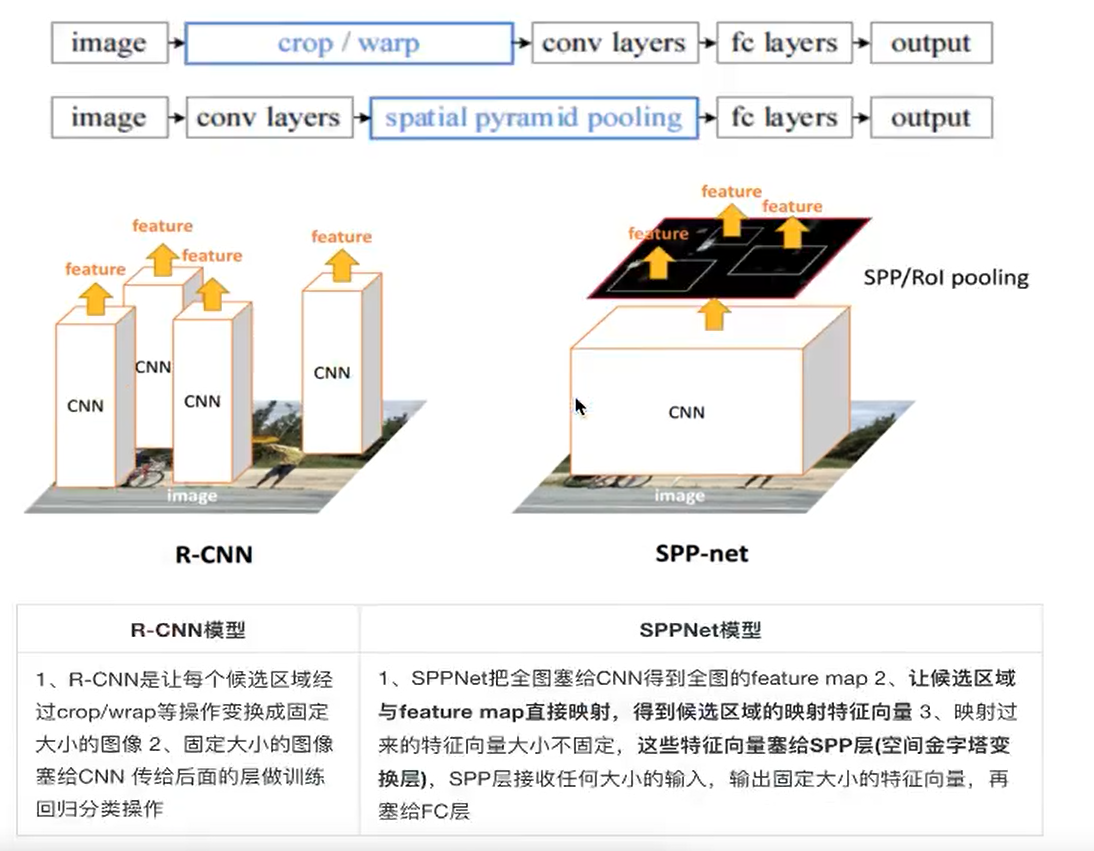
映射




Fast R-CNN

SPPNet的性能已经得到很大的改善,但是由于网络之间不统一训练,造成很大的麻烦,还要存储特征图
改进
提出RoI pooling,整合整个模型,把CNN,SPP变换层,分类器,bbox回归器,几个模块一起训练
svm替换成了softmax分类
步骤
- 首先将整张图片输入到一个基础的卷积网络,得到整张图的feature map
- 将region proposal 映射到feature map中
ROI pooling layer 提取一个固定长度的特征向量,每个特征会输入到一系列全连接层,得到一个ROI特征向量(此步骤是对每一个候选区域都会进行同样的操作)
输入一张图片,经过CNN输出特征图
- 特征图经过RPN得到候选区域
- 候选区域与特征图共同输入ROI pooling 得到每个后续安全区域的特征图,然后进softmax分了分类和bbox预测
RPN(区域推荐网络)原理



效果对比

优缺点

YOLO(you only look once)


结构

步骤



Faster R-CNN和YOLO比较


SSD(Single Shot MultiBox Detector )


结构

流程







若有收获,就点个赞吧
0 人点赞
