Linux网络收包总览
在TCP/IP网络分层模型里,整个协议栈被分成了物理层、链路层、网络层,传输层和应用层。物理层对应的是网卡和网线,应用层对应的是我们常见的Nginx,FTP等等各种应用。Linux实现的是链路层、网络层和传输层这三层。
在Linux内核实现中,链路层协议靠网卡驱动来实现,内核协议栈来实现网络层和传输层。内核对更上层的应用层提供socket接口来供用户进程访问。我们用Linux的视角来看到的TCP/IP网络分层模型应该是下面这个样子的。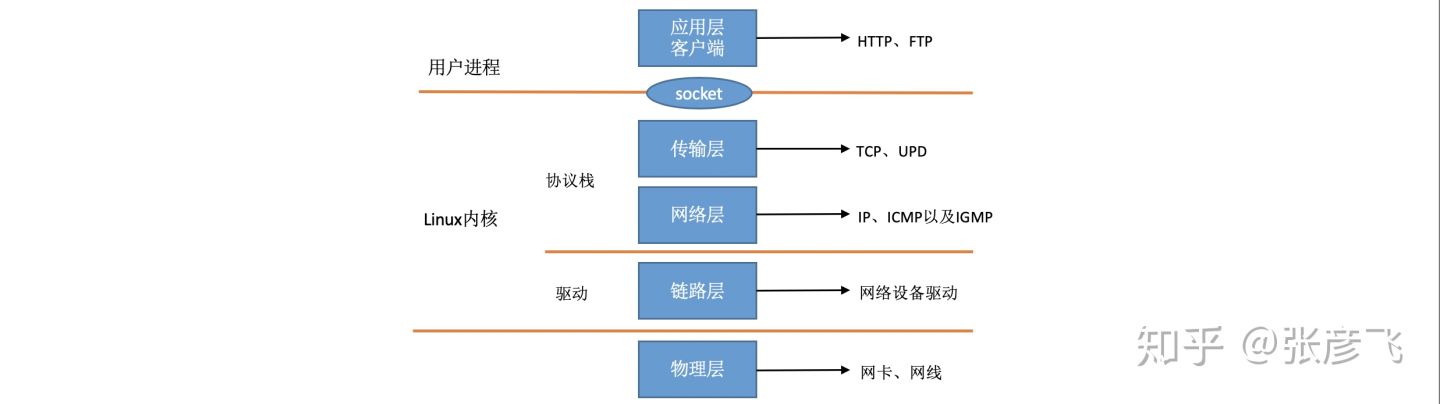
在Linux源代码中,网络设备驱动对应的逻辑位于proc/net/ethernet
内核和网络设备驱动是通过中断的方式来处理的。当设备上有数据到达的时候,会给CPU的相关引脚上触发一个电压变化,以通知CPU来处理数据。对于网络模块来说,由于处理过程比较复杂和耗时,如果在中断函数中完成所有的处理,将会导致中断处理函数(优先级过高)将过度占据CPU,将导致CPU无法响应其它设备。因此Linux中断处理函数是分上半部和下半部的。
上半部是只进行最简单的工作,快速处理然后释放CPU,接着CPU就可以允许其它中断进来。剩下将绝大部分的工作都放到下半部中,可以慢慢从容处理。2.4以后的内核版本采用的下半部实现方式是软中断,由ksoftirqd内核线程全权处理。和硬中断不同的是,硬中断是通过给CPU物理引脚施加电压变化,而软中断是通过给内存中的一个变量的二进制值以通知软中断处理程序。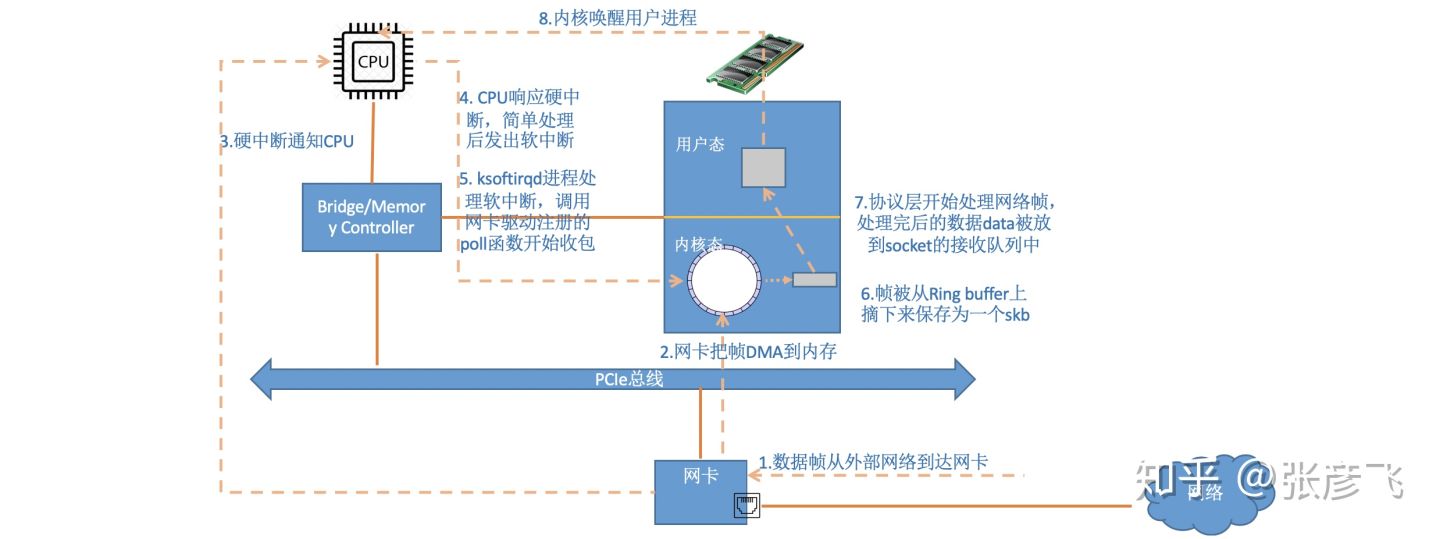
Linux启动
Linux驱动,内核协议栈等等模块在具备接收网卡数据包之前,要做很多的准备工作才行。比如要提前创建好ksoftirqd内核线程,要注册好各个协议对应的处理函数,网络设备子系统要提前初始化好,网卡要启动好。只有这些都Ready之后,我们才能真正开始接收数据包。
创建ksoftirqd
Linux的软中断都是在专门的内核线程(ksoftirqd)中进行的,因此我们非常有必要看一下这些进程是怎么初始化的,这样我们才能在后面更准确地了解收包过程。该进程数量不是1个,而是N个,其中N等于你的机器的核数。
系统初始化的时候在kernel/smpboot.c中调用了smpboot_register_percpu_thread, 该函数进一步会执行到spawn_ksoftirqd(位于kernel/softirq.c)来创建出softirqd进程。

当ksoftirqd被创建出来以后,它就会进入自己的线程循环函数ksoftirqd_should_run和run_ksoftirqd了,不停地判断有没有软中断需要被处理。这里需要注意的一点是,软中断不仅仅只有网络软中断,还有其它类型。
//file: include/linux/interrupt.henum{HI_SOFTIRQ=0,TIMER_SOFTIRQ,NET_TX_SOFTIRQ,NET_RX_SOFTIRQ,BLOCK_SOFTIRQ,BLOCK_IOPOLL_SOFTIRQ,TASKLET_SOFTIRQ,SCHED_SOFTIRQ,HRTIMER_SOFTIRQ,RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */NR_SOFTIRQS};
网络子系统初始化
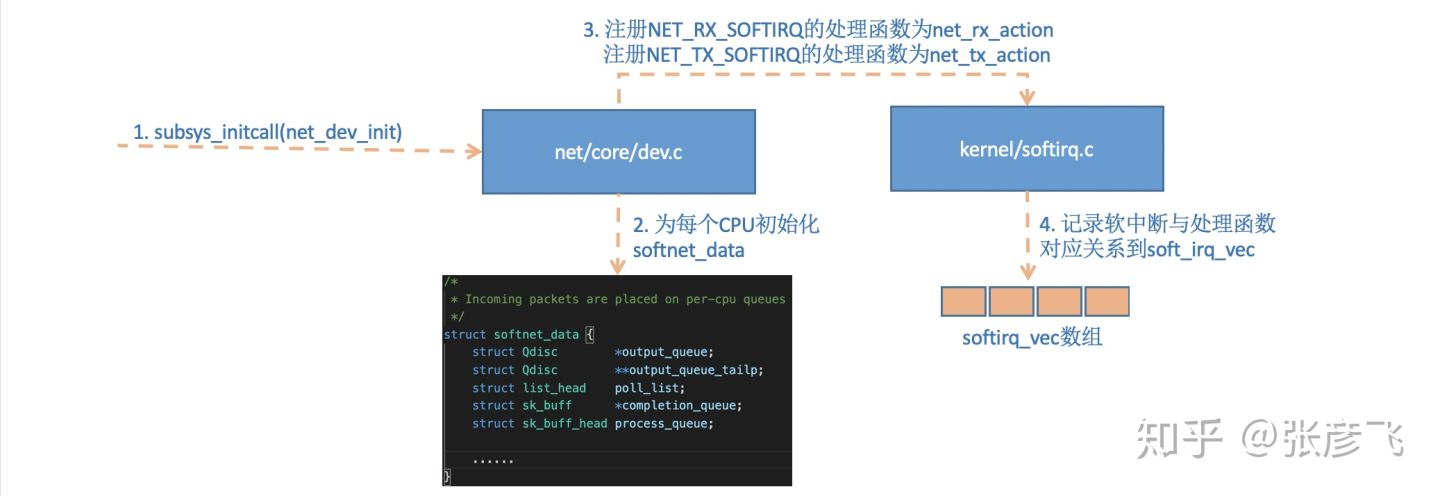
linux内核通过调用subsys_initcall来初始化各个子系统,在源代码目录里你可以grep出许多对这个函数的调用。这里我们要说的是网络子系统的初始化,会执行到net_dev_init函数。
//file: net/core/dev.cstatic int __init net_dev_init(void){......for_each_possible_cpu(i) {struct softnet_data *sd = &per_cpu(softnet_data, i);memset(sd, 0, sizeof(*sd));skb_queue_head_init(&sd->input_pkt_queue);skb_queue_head_init(&sd->process_queue);sd->completion_queue = NULL;INIT_LIST_HEAD(&sd->poll_list);......}......open_softirq(NET_TX_SOFTIRQ, net_tx_action);open_softirq(NET_RX_SOFTIRQ, net_rx_action);}subsys_initcall(net_dev_init);
在这个函数里,会为每个CPU都申请一个softnet_data数据结构,在这个数据结构里的poll_list是等待驱动程序将其poll函数注册进来,稍后网卡驱动初始化的时候我们可以看到这一过程。
协议栈注册
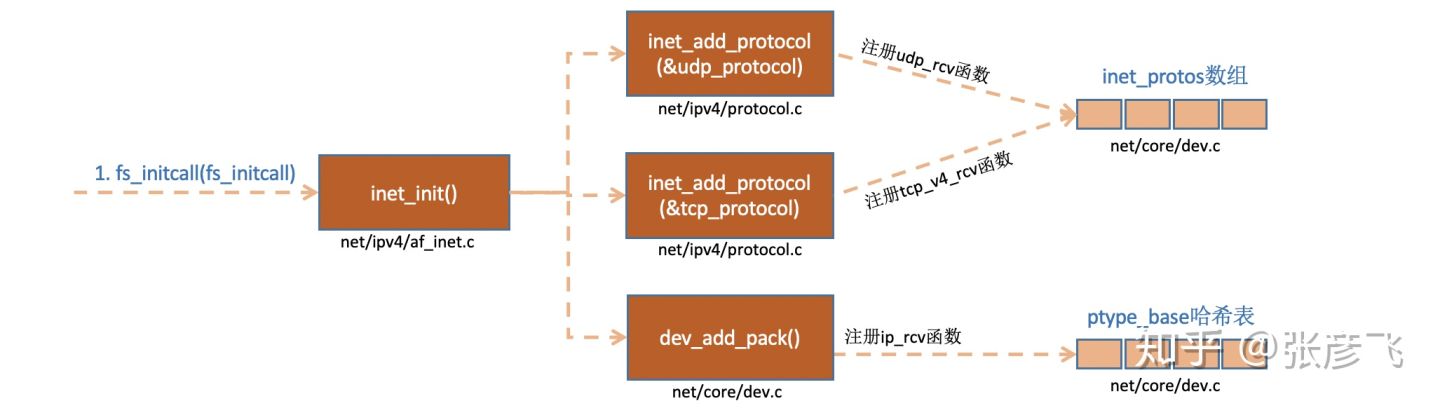
内核实现了网络层的ip协议,也实现了传输层的tcp协议和udp协议。这些协议对应的实现函数分别是ip_rcv(),tcp_v4_rcv()和udp_rcv()。和我们平时写代码的方式不一样的是,内核是通过注册的方式来实现的。 Linux内核中的fs_initcall和subsys_initcall类似,也是初始化模块的入口。fs_initcall调用inet_init后开始网络协议栈注册。 通过inet_init,将这些函数注册到了inet_protos和ptype_base数据结构中了。
网卡驱动初始化
每一个驱动程序(不仅仅只是网卡驱动)会使用 module_init 向内核注册一个初始化函数,当驱动被加载时,内核会调用这个函数。
驱动调用完成后,Linux内核就知道了该驱动的相关信息。当网卡设备被识别以后,内核会调用其驱动的probe方法,驱动probe方法执行的目的就是让设备ready
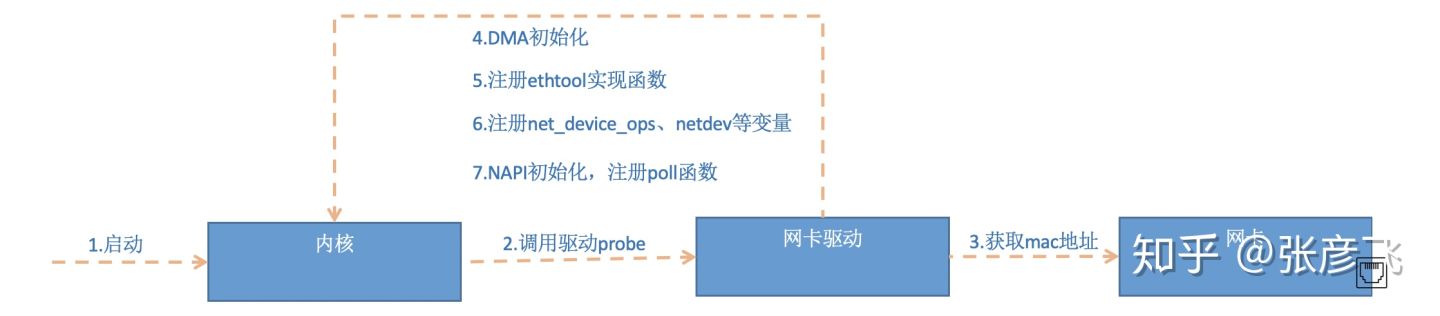
第5步中我们看到,网卡驱动实现了ethtool所需要的接口,也在这里注册完成函数地址的注册。当 ethtool发起一个系统调用之后,内核会找到对应操作的回调函数。
启动网卡
当上面的初始化都完成以后,就可以启动网卡了。我们在驱动初始化时,会将网卡启用、法宝、设置mac地址等回调函数注册。当启用一个网卡是,这些注册了的方法会被调用
数据到来
硬中断处理
首先当数据帧从网线到达网卡上的时候,第一站是网卡的接收队列。网卡在分配给自己的RingBuffer中寻找可用的内存位置,找到后DMA引擎会把数据DMA到网卡之前关联的内存里,这个时候CPU都是无感的。当DMA操作完成以后,网卡会像CPU发起一个硬中断,通知CPU有数据到达。
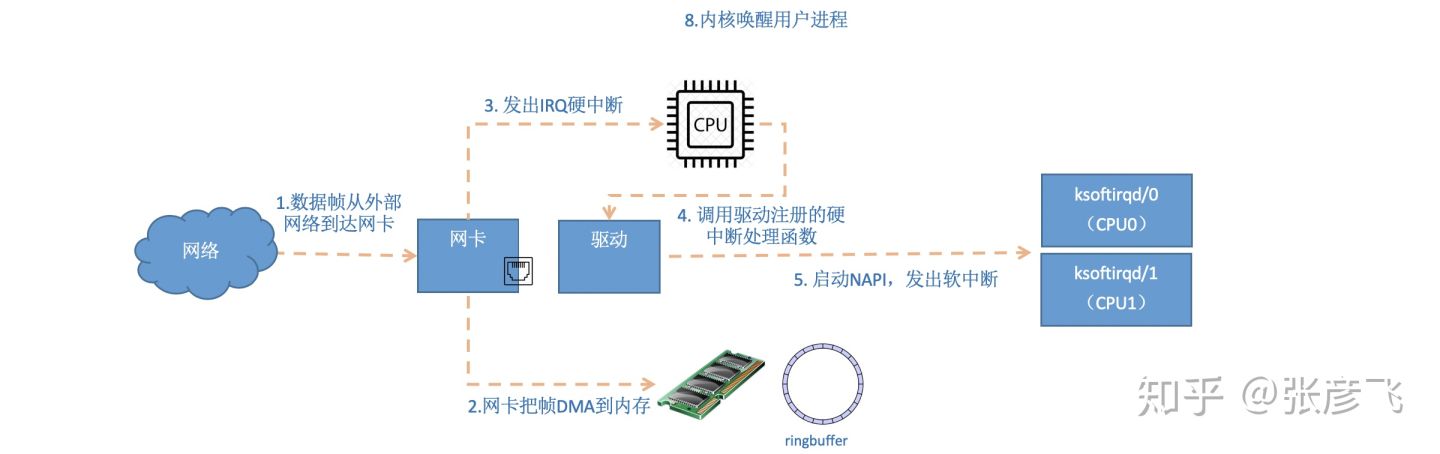
当RingBuffer满的时候,新来的数据包将给丢弃。ifconfig查看网卡的时候,可以里面有个
overruns,表示因为环形队列满被丢弃的包。如果发现有丢包,可能需要通过ethtool命令来加大环形队列的长度。
Linux在硬中断里只完成简单必要的工作,剩下的大部分的处理都是转交给软中断的。通过上面代码可以看到,硬中断处理过程真的是非常短。只是记录了一个寄存器,修改了一下下CPU的poll_list,然后发出个软中断。
ksoftirqd内核线程处理软中断
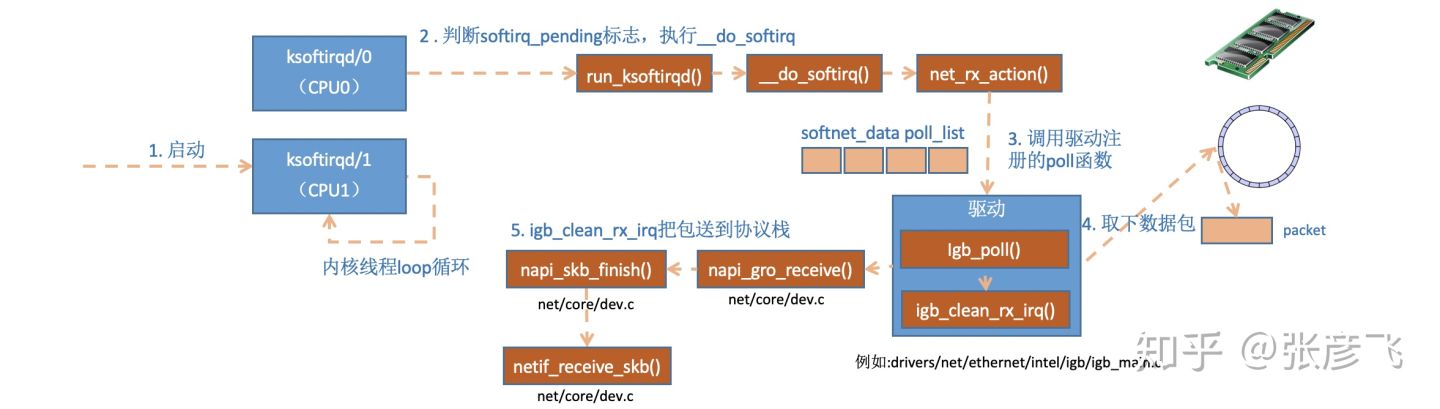
网络协议栈请求
netif_receive_skb函数会根据包的协议,假如是udp包,会将包依次送到ip_rcv(),udp_rcv()协议处理函数中进行处理。

IP协议层处理
这里将会根据包中的协议类型选择进行分发,在这里skb包将会进一步被派送到更上层的协议中,udp和tcp。
协议层处理
根据skb来寻找对应的socket,当找到以后将数据包放到socket的缓存队列里。
recvfrom系统调用
花开两朵,各表一枝。 上面我们说完了整个Linux内核对数据包的接收和处理过程,最后把数据包放到socket的接收队列中了。那么我们再回头看用户进程调用recvfrom后是发生了什么。 我们在代码里调用的recvfrom是一个glibc的库函数,该函数在执行后会将用户进行陷入到内核态,进入到Linux实现的系统调用sys_recvfrom。
所谓的读取过程,就是访问sk->sk_receive_queue。如果没有数据,且用户也允许等待,则将调用wait_for_more_packets()执行等待操作,它加入会让用户进程进入睡眠状态。
当用户执行完recvfrom调用后,用户进程就通过系统调用进行到内核态工作了。如果接收队列没有数据,进程就进入睡眠状态被操作系统挂起。这块相对比较简单,剩下大部分的戏份都是由Linux内核其它模块来表演了。
总结
首先在开始收包之前,Linux要做许多的准备工作:
- 创建ksoftirqd线程,为它设置好它自己的线程函数,后面就指望着它来处理软中断呢。
- 协议栈注册,linux要实现许多协议,比如arp,icmp,ip,udp,tcp,每一个协议都会将自己的处理函数注册一下,方便包来了迅速找到对应的处理函数
- 网卡驱动初始化,每个驱动都有一个初始化函数,内核会让驱动也初始化一下。在这个初始化过程中,把自己的DMA准备好,把NAPI的poll函数地址告诉内核
- 启动网卡,分配RX,TX队列,注册中断对应的处理函数
以上是内核准备收包之前的重要工作,当上面都ready之后,就可以打开硬中断,等待数据包的到来了。
当数据到来了以后,第一个迎接它的是网卡(我去,这不是废话么):
- 网卡将数据帧DMA到内存的RingBuffer中,然后向CPU发起中断通知
- CPU响应中断请求,调用网卡启动时注册的中断处理函数
- 中断处理函数几乎没干啥,就发起了软中断请求
- 内核线程ksoftirqd线程发现有软中断请求到来,先关闭硬中断
- ksoftirqd线程开始调用驱动的poll函数收包
- poll函数将收到的包送到协议栈注册的ip_rcv函数中
- ip_rcv函数再讲包送到udp_rcv函数中(对于tcp包就送到tcp_rcv)
理解了整个收包过程以后,我们就能明确知道Linux收一个包的CPU开销了。首先第一块是用户进程调用系统调用陷入内核态的开销。第二块是CPU响应包的硬中断的CPU开销。第三块是ksoftirqd内核线程的软中断上下文花费的。
相关链接

若有收获,就点个赞吧
0 人点赞
