_analyze是Elasticsearch一个非常有用的API,它可以帮助你分析每一个field或者某个analyzer/tokenizer是如何分析和索引一段文字。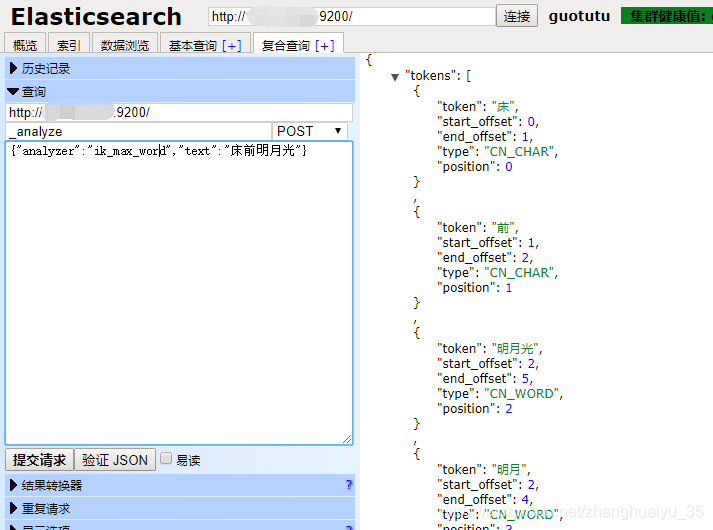

返回结果字段含义:
token是一个实际被存储在索引中的词
position指明词在原文本中是第几个出现的
start_offset和end_offset表示词在原文本中占据的位置。
1、默认analyzer
GET /_analyze?
{“analyzer” : “standard”, “text” : “床前明月光”}
{"tokens": [{"token": "床","start_offset": 0,"end_offset": 1,"type": "<IDEOGRAPHIC>","position": 0},{"token": "前","start_offset": 1,"end_offset": 2,"type": "<IDEOGRAPHIC>","position": 1},{"token": "明","start_offset": 2,"end_offset": 3,"type": "<IDEOGRAPHIC>","position": 2},{"token": "月","start_offset": 3,"end_offset": 4,"type": "<IDEOGRAPHIC>","position": 3},{"token": "光","start_offset": 4,"end_offset": 5,"type": "<IDEOGRAPHIC>","position": 4}]}
2、whitspace
GET /_analyze?
{“analyzer” : “whitespace”, “text” : “床前明月光”}
{"tokens": [{"token": "床前","start_offset": 0,"end_offset": 2,"type": "word","position": 0},{"token": "明月光","start_offset": 3,"end_offset": 6,"type": "word","position": 1}]}
3、使用ik分析器
GET /_analyze?
{“analyzer” : “ik_max_word”, “text” : “床前明月光”}
{"tokens": [{"token": "床前明月光","start_offset": 0,"end_offset": 5,"type": "CN_WORD","position": 0},{"token": "床前","start_offset": 0,"end_offset": 2,"type": "CN_WORD","position": 1},{"token": "明月光","start_offset": 2,"end_offset": 5,"type": "CN_WORD","position": 2},{"token": "明月","start_offset": 2,"end_offset": 4,"type": "CN_WORD","position": 3},{"token": "明","start_offset": 2,"end_offset": 3,"type": "CN_WORD","position": 4},{"token": "月光","start_offset": 3,"end_offset": 5,"type": "CN_WORD","position": 5},{"token": "月","start_offset": 3,"end_offset": 4,"type": "CN_WORD","position": 6},{"token": "光","start_offset": 4,"end_offset": 5,"type": "CN_CHAR","position": 7}]}
4、使用拼音分析器
GET /_analyze?
{“analyzer” : “pinyin”, “text” : “床前明月光”}
{"tokens": [{"token": "chuang","start_offset": 0,"end_offset": 1,"type": "word","position": 0},{"token": "cqmyg","start_offset": 0,"end_offset": 5,"type": "word","position": 0},{"token": "qian","start_offset": 1,"end_offset": 2,"type": "word","position": 1},{"token": "ming","start_offset": 2,"end_offset": 3,"type": "word","position": 2},{"token": "yue","start_offset": 3,"end_offset": 4,"type": "word","position": 3},{"token": "guang","start_offset": 4,"end_offset": 5,"type": "word","position": 4}]}


若有收获,就点个赞吧
0 人点赞
