安装
brew install kafka
实测,很慢很慢…
耐心等待。
安装信息如下:
Warning: You are using macOS 10.15.
We do not provide support for this pre-release version.
You will encounter build failures with some formulae.
Please create pull requests instead of asking for help on Homebrew’s GitHub,
Discourse, Twitter or IRC. You are responsible for resolving any issues you
experience while you are running this pre-release version.
==> Installing dependencies for kafka: zookeeper
==> Installing kafka dependency: zookeeper
==> Downloading https://homebrew.bintray.com/bottles/zookeeper-3.4.13.mojave.bottle.tar.gz
==> Downloading from https://akamai.bintray.com/d1/d1e4e7738cd147dceb3d91b32480c20ac5da27d129905f336ba51c0c01b8a476?__gda
######################################################################## 100.0%
==> Pouring zookeeper-3.4.13.mojave.bottle.tar.gz
==> Caveats
To have launchd start zookeeper now and restart at login:
brew services start zookeeper
Or, if you don’t want/need a background service you can just run:
zkServer start
==> Summary
🍺 /usr/local/Cellar/zookeeper/3.4.13: 244 files, 33.4MB
==> Installing kafka
==> Downloading https://homebrew.bintray.com/bottles/kafka-2.2.1.mojave.bottle.tar.gz
==> Downloading from https://akamai.bintray.com/51/518f131edae4443dc664b4f4775ab82cba4b929ac6f2120cdf250898e35fa0db?__gda
################################################### 71.4%
curl: (18) transfer closed with 15373632 bytes remaining to read
Error: Failed to download resource “kafka”
Download failed: https://homebrew.bintray.com/bottles/kafka-2.2.1.mojave.bottle.tar.gz
Warning: Bottle installation failed: building from source.
==> Downloading https://www.apache.org/dyn/closer.cgi?path=/kafka/2.2.1/kafka_2.12-2.2.1.tgz
==> Downloading from http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.2.1/kafka_2.12-2.2.1.tgz
######################################################################## 100.0%
==> Caveats
To have launchd start kafka now and restart at login:
brew services start kafka
Or, if you don’t want/need a background service you can just run:
zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties & kafka-server-start /usr/local/etc/kafka/server.properties
==> Summary
🍺 /usr/local/Cellar/kafka/2.2.1: 149 files, 54.4MB, built in 2 minutes 23 seconds
==> brew cleanup has not been run in 30 days, running now…
Removing: /Users/taoshilei/Library/Logs/Homebrew/redis… (64B)
==> Caveats
==> zookeeper
To have launchd start zookeeper now and restart at login:
brew services start zookeeper
Or, if you don’t want/need a background service you can just run:
zkServer start
==> kafka
To have launchd start kafka now and restart at login:
brew services start kafka
Or, if you don’t want/need a background service you can just run:
zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties & kafka-server-start /usr/local/etc/kafka/server.properties
从上面的安装信息,我们可以提取出 kafka 的启动命令:
- brew services start kafka
注意: 我本地忘记之前执行过后台启动这个命令了,ps -ef | grep kafka 之后,kill -9 pid 一直杀不掉。
应该使用 brew services stop kafka 关掉!
上面的是在后台启动,如果我们不需要让这两个服务在后台启动,我们可以使用下面的命令。
- zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties & kafka-server-start /usr/local/etc/kafka/server.properties
配置文件
查看下两个默认的配置文件:
查看 zookeeper 的: cat /usr/local/etc/kafka/zookeeper.properties
# Licensed to the Apache Software Foundation (ASF) under one or more# contributor license agreements. See the NOTICE file distributed with# this work for additional information regarding copyright ownership.# The ASF licenses this file to You under the Apache License, Version 2.0# (the "License"); you may not use this file except in compliance with# the License. You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.# the directory where the snapshot is stored.dataDir=/usr/local/var/lib/zookeeper# the port at which the clients will connectclientPort=2181# disable the per-ip limit on the number of connections since this is a non-production configmaxClientCnxns=0
查看 kafka 的:
# Licensed to the Apache Software Foundation (ASF) under one or more# contributor license agreements. See the NOTICE file distributed with# this work for additional information regarding copyright ownership.# The ASF licenses this file to You under the Apache License, Version 2.0# (the "License"); you may not use this file except in compliance with# the License. You may obtain a copy of the License at## http://www.apache.org/licenses/LICENSE-2.0## Unless required by applicable law or agreed to in writing, software# distributed under the License is distributed on an "AS IS" BASIS,# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.# See the License for the specific language governing permissions and# limitations under the License.# see kafka.server.KafkaConfig for additional details and defaults############################# Server Basics ############################## The id of the broker. This must be set to a unique integer for each broker.broker.id=0############################# Socket Server Settings ############################## The address the socket server listens on. It will get the value returned from# java.net.InetAddress.getCanonicalHostName() if not configured.# FORMAT:# listeners = listener_name://host_name:port# EXAMPLE:# listeners = PLAINTEXT://your.host.name:9092#listeners=PLAINTEXT://:9092# Hostname and port the broker will advertise to producers and consumers. If not set,# it uses the value for "listeners" if configured. Otherwise, it will use the value# returned from java.net.InetAddress.getCanonicalHostName().#advertised.listeners=PLAINTEXT://your.host.name:9092# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL# The number of threads that the server uses for receiving requests from the network and sending responses to the networknum.network.threads=3# The number of threads that the server uses for processing requests, which may include disk I/Onum.io.threads=8# The send buffer (SO_SNDBUF) used by the socket serversocket.send.buffer.bytes=102400# The receive buffer (SO_RCVBUF) used by the socket serversocket.receive.buffer.bytes=102400# The maximum size of a request that the socket server will accept (protection against OOM)socket.request.max.bytes=104857600############################# Log Basics ############################## A comma separated list of directories under which to store log fileslog.dirs=/usr/local/var/lib/kafka-logs# The default number of log partitions per topic. More partitions allow greater# parallelism for consumption, but this will also result in more files across# the brokers.num.partitions=1# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.# This value is recommended to be increased for installations with data dirs located in RAID array.num.recovery.threads.per.data.dir=1############################# Internal Topic Settings ############################## The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"# For anything other than development testing, a value greater than 1 is recommended for to ensure availability such as 3.offsets.topic.replication.factor=1transaction.state.log.replication.factor=1transaction.state.log.min.isr=1############################# Log Flush Policy ############################## Messages are immediately written to the filesystem but by default we only fsync() to sync# the OS cache lazily. The following configurations control the flush of data to disk.# There are a few important trade-offs here:# 1. Durability: Unflushed data may be lost if you are not using replication.# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.# The settings below allow one to configure the flush policy to flush data after a period of time or# every N messages (or both). This can be done globally and overridden on a per-topic basis.# The number of messages to accept before forcing a flush of data to disk#log.flush.interval.messages=10000# The maximum amount of time a message can sit in a log before we force a flush#log.flush.interval.ms=1000############################# Log Retention Policy ############################## The following configurations control the disposal of log segments. The policy can# be set to delete segments after a period of time, or after a given size has accumulated.# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens# from the end of the log.# The minimum age of a log file to be eligible for deletion due to agelog.retention.hours=168# A size-based retention policy for logs. Segments are pruned from the log unless the remaining# segments drop below log.retention.bytes. Functions independently of log.retention.hours.#log.retention.bytes=1073741824# The maximum size of a log segment file. When this size is reached a new log segment will be created.log.segment.bytes=1073741824# The interval at which log segments are checked to see if they can be deleted according# to the retention policieslog.retention.check.interval.ms=300000############################# Zookeeper ############################## Zookeeper connection string (see zookeeper docs for details).# This is a comma separated host:port pairs, each corresponding to a zk# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".# You can also append an optional chroot string to the urls to specify the# root directory for all kafka znodes.zookeeper.connect=localhost:2181# Timeout in ms for connecting to zookeeperzookeeper.connection.timeout.ms=6000############################# Group Coordinator Settings ############################## The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.# The default value for this is 3 seconds.# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.group.initial.rebalance.delay.ms=0%
启动 zk + kafka
zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties &kafka-server-start /usr/local/etc/kafka/server.properties
控制台,输出了很多信息,最后看到:
[2019-12-09 19:55:22,317] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)
就表示kafka启动成功了。
关闭 zk + kafka
zookeeper-server-stop /usr/local/etc/kafka/zookeeper.properties & kafka-server-stop /usr/local/etc/kafka/server.properties
列出 Topic
kafka-topics --list --bootstrap-server localhost:9092
创建 topic
kafka-topics --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
这个命令很简单,就是创建一个叫做 test 的主题,分区数和副本数都指定为 1 ,因为本地测试机器,指定 1 就足够了。
注意:kafka-topics.sh 如果提示没有这个命令,就换成 kafka-topic
查看数据
kafka-console-consumer --bootstrap-server localhost:9092 --topic test_flink_cdc_01 --from-beginning
发送数据
echo "hello" | kafka-console-producer --broker-list localhost:9092 --sync --topic test
其他命令
KAFKA_MANAGER
kafka-delegation-tokens
kafka-mirror-maker
kafka-streams-application-reset
kafka_manager_utils_zero-10_log-config
kafka-acls
kafka-delete-records
kafka-preferred-replica-election
kafka-tools
kafka_manager_utils_zero-10_log-config.bat
kafka-broker-api-versions
kafka-dump-log
kafka-producer-perf-test
kafka-topics
kafka_manager_utils_zero-11_log-config
kafka-cluster
kafka-features
kafka-reassign-partitions
kafka-verifiable-consumer
kafka_manager_utils_zero-11_log-config.bat
kafka-configs
kafka-leader-election
kafka-replica-verification
kafka-verifiable-producer
kafka_manager_utils_zero-90_log-config
kafka-console-consumer
kafka-log-dirs
kafka-run-class
kafka_manager_utils_one-10_log-config
kafka_manager_utils_zero-90_log-config.bat
kafka-console-producer
kafka-manager
kafka-server-start
kafka_manager_utils_one-10_log-config.bat
kafka-consumer-groups
kafka-manager.bat
kafka-server-stop
kafka_manager_utils_two-00_log-config
kafka-consumer-perf-test
kafka-metadata-shell
kafka-storage
kafka_manager_utils_two-00_log-config.bat
编写一个程序测试
package core;import org.apache.kafka.clients.consumer.KafkaConsumer;import org.apache.kafka.common.TopicPartition;import java.util.Arrays;import java.util.Properties;/*** @program: kafka_learning* @description: kafka 测试出现这种异常:Exception in thread "main" java.lang.IllegalStateException: No current assignment* @author: TSL* @create: 2019-12-08 23:14**/public class KafkaConsumerSimple {// 本地搭建一个简易的 kafka 服务。http://kafka.apache.org/quickstartpublic static void main(String[] args) {// 配置Properties properties = new Properties();properties.put("bootstrap.servers","localhost:9092");properties.put("group.id","test-0");properties.put("enable.auto.commit", "true");properties.put("auto.commit.interval.ms", "1000");properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");// 获取消费者实例KafkaConsumer kafkaConsumer = new KafkaConsumer(properties);kafkaConsumer.subscribe(Arrays.asList("test"));// 指定从topic的某个分区、某偏移量开始消费kafkaConsumer.seek(new TopicPartition("test",0),1L);}}
遇到的问题
1、key.deserializer
问题:
Exception in thread “main” org.apache.kafka.common.config.ConfigException: Missing required configuration “key.deserializer” which has no default value.
解决:
// 指定序列化方式properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
2、bootstrap.servers
问题:
org.apache.kafka.common.config.ConfigException: No resolvable bootstrap urls given in bootstrap.servers
解决:
// 指定 kafka server 的地址properties.put("bootstrap.servers","localhost:9092");
3、 No current assignment for partition test-0
No current assignment for partition test-0
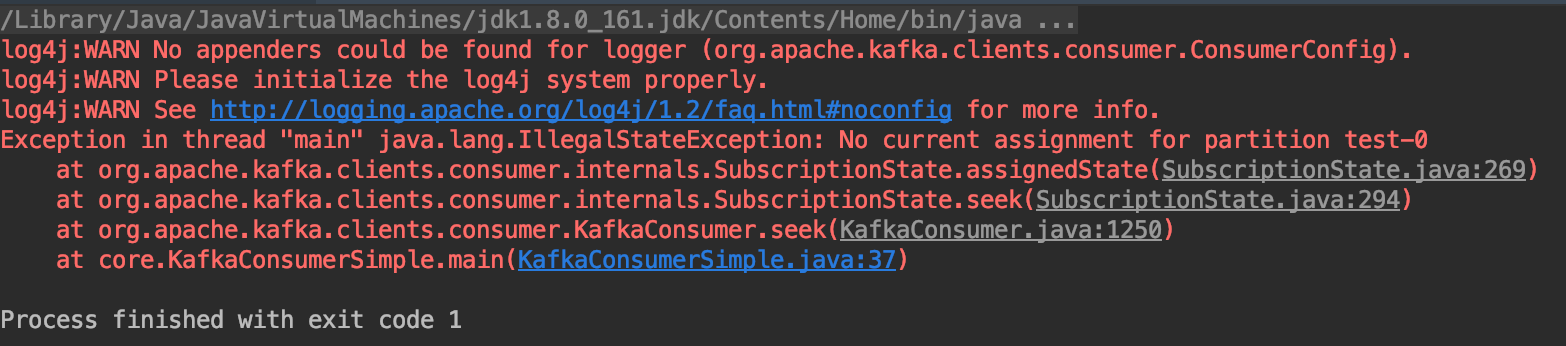
通过 debug 代码来理解这个错误是什么。

/* the partitions that are currently assigned, note that the order of partition matters (see FetchBuilder for more details) */private final PartitionStates<TopicPartitionState> assignment;
4、java.io.IOException: No snapshot found, but there are log entries. Something is broken!
把zookepper 的临时目录清一下。
5、ps -ef | grep kafka 之后 找到 kill -9 pid 杀不死kafak进程
使用 jps 看一下是不是存在一个kafka主程序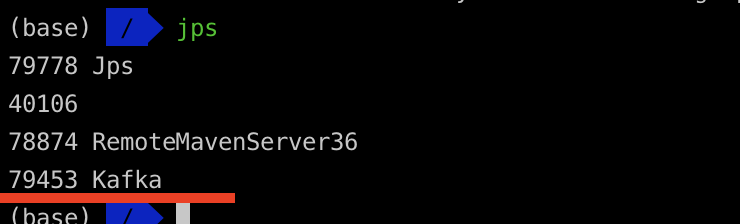

若有收获,就点个赞吧
0 人点赞
