QMIX 是多智能体强化学习中比较经典的算法之一,在 VDN 的基础上做了一些改进,与 VDN 相比,在各个 agent 之间有着较大差异的环境中,表现的更好。
摘要
在许多实际环境中,一组代理必须协调它们的行为,同时以一种去中心化的方式行动。 同时,在仿真或实验室环境中以集中的方式训练代理是可能的,在这种环境下,能够获得全局状态信息并且不再存在通信限制。以额外的状态信息为条件的联合动作价值学习是利用集中学习的一种有吸引力的方式,但随后提取分散政策的最佳策略还不清楚。我们的解决方案是QMIX,这是一种基于价值的新方法,可以以集中的端到端方式训练去中心化的策略。QMIX使用了一个网络,该网络将单个代理值的复杂非线性组合作为联合动作值进行估计,而每个代理值仅根据本地观测得到。我们在结构上强制每个代理的联合动作值是单调的,这使得在非策略学习中联合动作值的最大化能够实现,并保证了集中化和去中心化策略之间的一致性。我们在一组极具挑战性的星际争霸2微管理任务中对QMIX进行了评估,结果表明QMIX显著优于现有的基于价值的多智能体强化学习方法。
算法
由于 VDN 只是将每个智能体的局部动作值函数求和相加得到联合动作值函数,虽然满足联合值函数与局部值函数单调性相同的可以进行分布化策略的条件,但是其没有在学习时利用状态信息以及没有采用非线性方式对单智能体局部值函数进行整合,使得VDN算法还有很大的提升空间。
QMIX 就是采用一个混合网络对单智能体局部值函数进行合并,并在训练学习过程中加入全局状态信息辅助,来提高算法性能。
为了能够沿用 VDN 的优势,利用集中式的学习,得到分布式的策略。主要是因为对联合动作值函数取 ![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图1](/uploads/projects/crazyalltnt@rl-paper/07a3e7c124007781b8a692f68384f7d6.svg) 等价于对每个局部动作值函数取
等价于对每个局部动作值函数取 ![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图2](/uploads/projects/crazyalltnt@rl-paper/d5d614e1ef6907b9007b0e3de9bbbd8b.svg) ,其单调性相同,如下所示:
,其单调性相同,如下所示:![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图3](/uploads/projects/crazyalltnt@rl-paper/4288e07e4293f595dfc09bb5d0f85d22.svg)
因此分布式策略就是贪心的通过局部 ![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图4](/uploads/projects/crazyalltnt@rl-paper/3673ca9c0d2d1c32394992584612cdaf.svg) 获取最优动作。QMIX 将 (1) 转化为一种单调性约束,如下所示:
获取最优动作。QMIX 将 (1) 转化为一种单调性约束,如下所示:![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图5](/uploads/projects/crazyalltnt@rl-paper/2ba83c8013663031733cfee30141b040.svg)
若满足以上单调性,则 (1) 成立,为了实现上述约束,QMIX 采用混合网络(mixing network)来实现,其具体结构如下所示: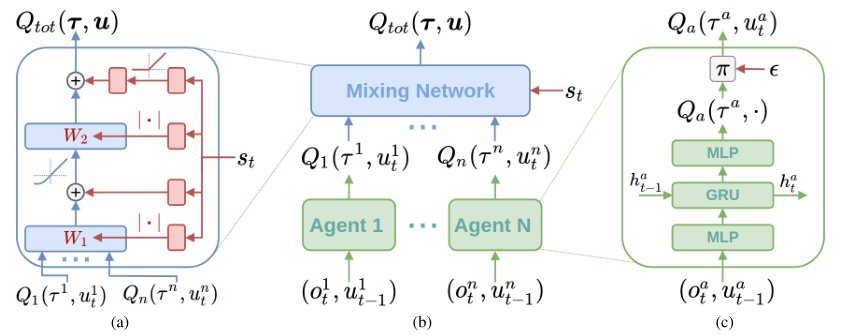
图 (c) 表示每个智能体采用一个 DRQN 来拟合自身的Q值函数的到 ![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图7](/uploads/projects/crazyalltnt@rl-paper/5fa140deee0b11fc4d17b60e357fb051.svg) ,DRQN 循环输入当前的观测
,DRQN 循环输入当前的观测 ![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图8](/uploads/projects/crazyalltnt@rl-paper/56f14d0f2362d6d6d9981a37e8b4f15a.svg) 以及上一时刻的动作
以及上一时刻的动作 ![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图9](/uploads/projects/crazyalltnt@rl-paper/7d4b9dab30156aef83c1f9fba4e067e5.svg) 来得到 Q 值。
来得到 Q 值。
图 (b) 表示混合网络的结构。其输入为每个DRQN网络的输出。为了满足上述的单调性约束,混合网络的所有权值都是非负数,对偏移量不做限制,这样就可以确保满足单调性约束。
为了能够更多的利用到系统的状态信息![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图10](/uploads/projects/crazyalltnt@rl-paper/d2fee40d9772331003894b796475e0c2.svg) ,采用一种超网络(hypernetwork),将状态
,采用一种超网络(hypernetwork),将状态 ![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图11](/uploads/projects/crazyalltnt@rl-paper/aa0280201359a638ef5b92660ca097d2.svg) 作为输入,输出为混合网络的权值及偏移量,如图 (a) 所示。为了保证权值的非负性,采用一个线性网络以及绝对值激活函数保证输出不为负数。对偏移量采用同样方式但没有非负性的约束,混合网络最后一层的偏移量通过两层网络以及ReLU激活函数得到非线性映射网络。由于状态信息
作为输入,输出为混合网络的权值及偏移量,如图 (a) 所示。为了保证权值的非负性,采用一个线性网络以及绝对值激活函数保证输出不为负数。对偏移量采用同样方式但没有非负性的约束,混合网络最后一层的偏移量通过两层网络以及ReLU激活函数得到非线性映射网络。由于状态信息 ![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图12](/uploads/projects/crazyalltnt@rl-paper/6a6a2c9779ff4df21a8d4376ec251357.svg) 是通过超网络混合到
是通过超网络混合到 ![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图13](/uploads/projects/crazyalltnt@rl-paper/d05b522f162c35327ba26e8a1793a3f3.svg) 中的,而不是仅仅作为混合网络的输入项,这样带来的一个好处是,如果作为输入项则
中的,而不是仅仅作为混合网络的输入项,这样带来的一个好处是,如果作为输入项则 ![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图14](/uploads/projects/crazyalltnt@rl-paper/6d714f835c887ff8c38cbe3834126be9.svg) 的系数均为正,这样则无法充分利用状态信息来提高系统性能,相当于舍弃了一半的信息量。
的系数均为正,这样则无法充分利用状态信息来提高系统性能,相当于舍弃了一半的信息量。
QMIX 最终的代价函数为![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图15](/uploads/projects/crazyalltnt@rl-paper/75361300775323a655a6e66904bc51d5.svg)
更新用到了传统的 DQN 的思想,其中 b 表示从经验记忆中采样的样本数量, ![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图16](/uploads/projects/crazyalltnt@rl-paper/14cf536611cec6538ddc42a2fa017be3.svg) ,
,![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图17](/uploads/projects/crazyalltnt@rl-paper/a934663eadbdc6bc7dbeac17da394947.svg) ,表示目标网络。
,表示目标网络。
由于满足上文的单调性约束,对 ![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图18](/uploads/projects/crazyalltnt@rl-paper/56b4d0bf17ae6ad8c2508e5450908141.svg) 进行
进行 ![📝[QMIX]QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning - 图19](/uploads/projects/crazyalltnt@rl-paper/fa406eab8ebd2b8e9be10d4215ca20a1.svg) 操作的计算量就不再是随智能体数量呈指数增长了,而是随智能体数量线性增长,极大的提高了算法效率。
操作的计算量就不再是随智能体数量呈指数增长了,而是随智能体数量线性增长,极大的提高了算法效率。
总结
在合作的环境中(注意 QMIX 的环境仅在合作的环境中使用),为了解决集中训练、分布执行中每个 agent 策略提取的问题,文章提出 QMIX 方法,使用一个组合的非线性的网络组合每个 agent 的 Q value,同时约束联合动作Qmix的value与每个agent的单调性一致,从而保证了集中训练与分布执行的一致性。实验表明 Qmix 效果超过了当前的value-based的方法。
参考
About

若有收获,就点个赞吧
0 人点赞
