概述
在监控体系里面,通常我们认为监控分为:白盒监控和黑盒监控。
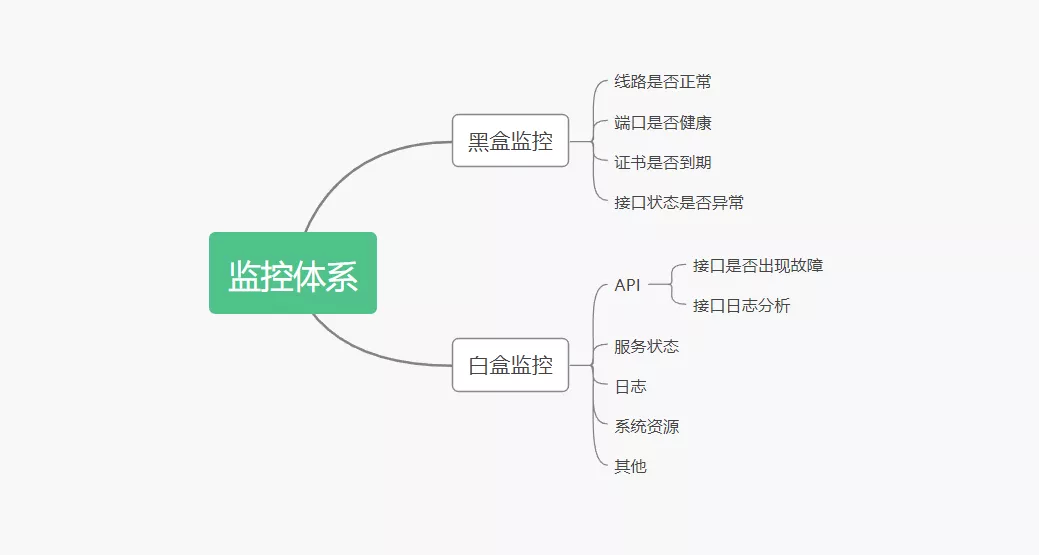
黑盒监控:主要关注的现象,一般都是正在发生的东西,例如出现一个告警,业务接口不正常,那么这种监控就是站在用户的角度能看到的监控,重点在于能对正在发生的故障进行告警。
白盒监控:主要关注的是原因,也就是系统内部暴露的一些指标,例如 redis 的 info 中显示 redis slave down,这个就是 redis info 显示的一个内部的指标,重点在于原因,可能是在黑盒监控中看到 redis down,而查看内部信息的时候,显示 redis port is refused connection。
Blackbox Exporter
Blackbox Exporter 是 Prometheus 社区提供的官方黑盒监控解决方案,其允许用户通过:HTTP、HTTPS、DNS、TCP 以及 ICMP 的方式对网络进行探测。
1、HTTP 测试
- 定义 Request Header 信息
- 判断 Http status / Http Respones Header / Http Body 内容
2、TCP 测试
- 业务组件端口状态监听
- 应用层协议定义与监听
3、ICMP 测试
- 主机探活机制
4、POST 测试
- 接口联通性
5、SSL 证书过期时间
安装Blackbox Exporter
(1)创建YAML配置文件(blackbox-deploymeny.yaml)
apiVersion: v1kind: Servicemetadata:name: blackboxnamespace: monitoringlabels:app: blackboxspec:selector:app: blackboxports:- port: 9115targetPort: 9115---apiVersion: v1kind: ConfigMapmetadata:name: blackbox-confignamespace: monitoringdata:blackbox.yaml: |-modules:http_2xx:prober: httptimeout: 10shttp:valid_http_versions: ["HTTP/1.1", "HTTP/2"]valid_status_codes: [200]method: GETpreferred_ip_protocol: "ip4"http_post_2xx:prober: httptimeout: 10shttp:valid_http_versions: ["HTTP/1.1", "HTTP/2"]valid_status_codes: [200]method: POSTpreferred_ip_protocol: "ip4"tcp_connect:prober: tcptimeout: 10sping:prober: icmptimeout: 5sicmp:preferred_ip_protocol: "ip4"dns:prober: dnsdns:transport_protocol: "tcp"preferred_ip_protocol: "ip4"query_name: "kubernetes.defalut.svc.cluster.local"---apiVersion: apps/v1kind: Deploymentmetadata:name: blackboxnamespace: monitoringspec:selector:matchLabels:app: blackboxtemplate:metadata:labels:app: blackboxspec:containers:- name: blackboximage: prom/blackbox-exporter:v0.18.0args:- "--config.file=/etc/blackbox_exporter/blackbox.yaml"- "--log.level=error"ports:- containerPort: 9115volumeMounts:- name: configmountPath: /etc/blackbox_exportervolumes:- name: configconfigMap:name: blackbox-config
(2)创建即可
kubectl apply -f blackbox-deploymeny.yaml
配置监控
由于集群是用的Prometheus Operator方式部署的,所以就以additional的形式添加配置。
(1)创建prometheus-additional.yaml文件,定义内容如下:
- job_name: "ingress-endpoint-status"metrics_path: /probeparams:module: [http_2xx] # Look for a HTTP 200 response.static_configs:- targets:- http://172.17.100.134/healthzlabels:group: nginx-ingressrelabel_configs:- source_labels: [__address__]target_label: __param_target- source_labels: [__param_target]target_label: instance- target_label: __address__replacement: blackbox.monitoring:9115- job_name: "kubernetes-service-dns"metrics_path: /probeparams:module: [dns]static_configs:- targets:- kube-dns.kube-system:53relabel_configs:- source_labels: [__address__]target_label: __param_target- source_labels: [__param_target]target_label: instance- target_label: __address__replacement: blackbox.monitoring:9115
(2)创建secret
kubectl -n monitoring create secret generic additional-config --from-file=prometheus-additional.yaml
(3)修改prometheus的配置,文件prometheus-prometheus.yaml
添加以下三行内容:
additionalScrapeConfigs:name: additional-configkey: prometheus-additional.yaml
完整配置如下:
apiVersion: monitoring.coreos.com/v1kind: Prometheusmetadata:labels:prometheus: k8sname: k8snamespace: monitoringspec:alerting:alertmanagers:- name: alertmanager-mainnamespace: monitoringport: webbaseImage: quay.io/prometheus/prometheusnodeSelector:kubernetes.io/os: linuxpodMonitorNamespaceSelector: {}podMonitorSelector: {}replicas: 2resources:requests:memory: 400MiruleSelector:matchLabels:prometheus: k8srole: alert-rulessecurityContext:fsGroup: 2000runAsNonRoot: truerunAsUser: 1000additionalScrapeConfigs:name: additional-configkey: prometheus-additional.yamlserviceAccountName: prometheus-k8sserviceMonitorNamespaceSelector: {}serviceMonitorSelector: {}version: v2.11.0storage:volumeClaimTemplate:spec:storageClassName: managed-nfs-storageresources:requests:storage: 10Gi
(4)重新apply配置
kubectl apply -f prometheus-prometheus.yaml
(5)reload prometheus
先找到svc的IP
# kubectl get svc -n monitoring -l prometheus=k8sNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEprometheus-k8s ClusterIP 10.99.93.157 <none> 9090/TCP 33m
使用以下命令reload
curl -X POST "http://10.99.93.157:9090/-/reload"
后面修改配置文件,使用以下三条命令即可
kubectl delete secret additional-config -n monitoringkubectl -n monitoring create secret generic additional-config --from-file=prometheus-additional.yamlcurl -X POST "http://10.99.93.157:9090/-/reload"
等待一段时间,即可在prometheus的web界面看到如下target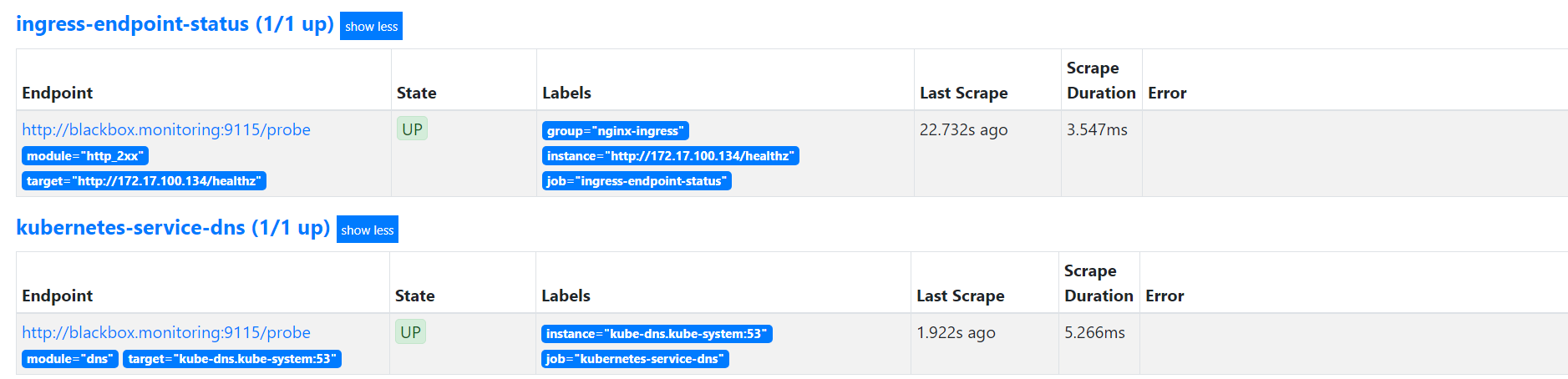
ICMP监控
ICMP主要是通过ping命令来检测目的主机的连通性。
配置如下:
- job_name: "node-icmp-status"metrics_path: /probeparams:module: [ping] # Look for a HTTP 200 response.static_configs:- targets:- 172.17.100.134- 172.17.100.50- 172.17.100.135- 172.17.100.136- 172.17.100.137- 172.17.100.138labels:group: k8s-node-pingrelabel_configs:- source_labels: [__address__]target_label: __param_target- source_labels: [__param_target]target_label: instance- target_label: __address__replacement: blackbox.monitoring:9115
然后重载配置文件
kubectl delete secret additional-config -n monitoringkubectl -n monitoring create secret generic additional-config --from-file=prometheus-additional.yamlcurl -X POST "http://10.99.93.157:9090/-/reload"
接下来可以看到监控成功,如下: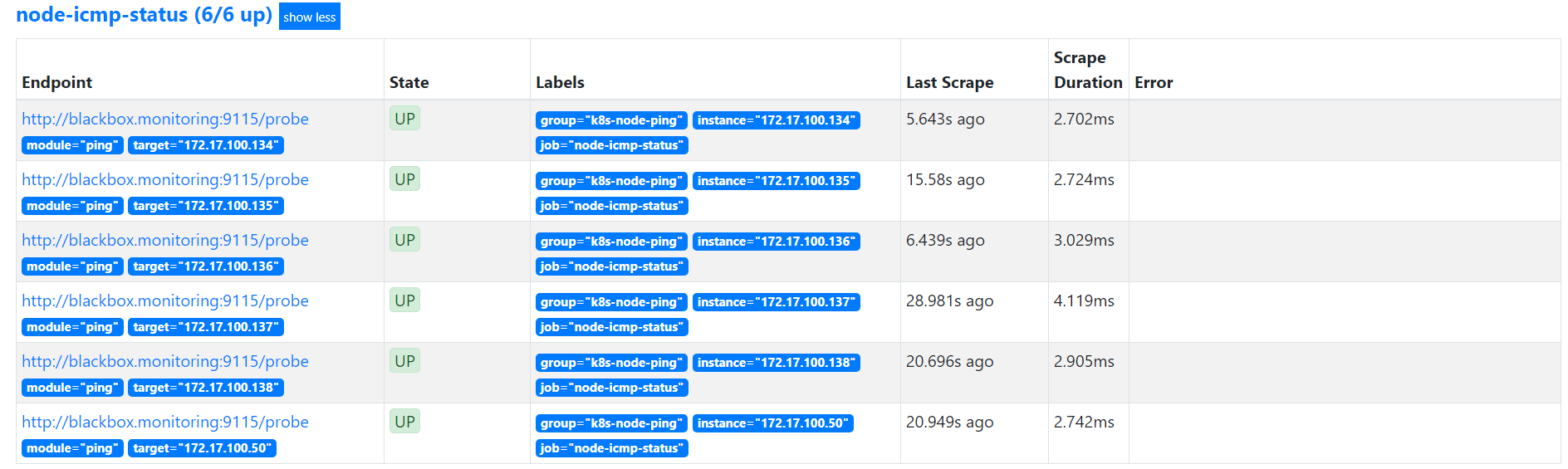
HTTP监控
HTTP就是通过GET或者POST的方式来检测应用是否正常。
这里配置GET方式。
- job_name: "check-web-status"metrics_path: /probeparams:module: [http_2xx] # Look for a HTTP 200 response.static_configs:- targets:- https://www.coolops.cn- https://www.baidu.comlabels:group: web-urlrelabel_configs:- source_labels: [__address__]target_label: __param_target- source_labels: [__param_target]target_label: instance- target_label: __address__replacement: blackbox.monitoring:9115
重载配置后可以看到监控如下:
TCP监控
TCP监控主要是通过类似于Telnet的方式进行检测,配置如下:
- job_name: "check-middleware-tcp"metrics_path: /probeparams:module: [tcp_connect] # Look for a HTTP 200 response.static_configs:- targets:- 172.17.100.135:80- 172.17.100.74:3306- 172.17.100.25:3306- 172.17.100.8:3306- 172.17.100.75:3306- 172.17.100.72:3306- 172.17.100.73:3306labels:group: middleware-tcprelabel_configs:- source_labels: [__address__]target_label: __param_target- source_labels: [__param_target]target_label: instance- target_label: __address__replacement: blackbox.monitoring:9115
重载配置文件后监控如下: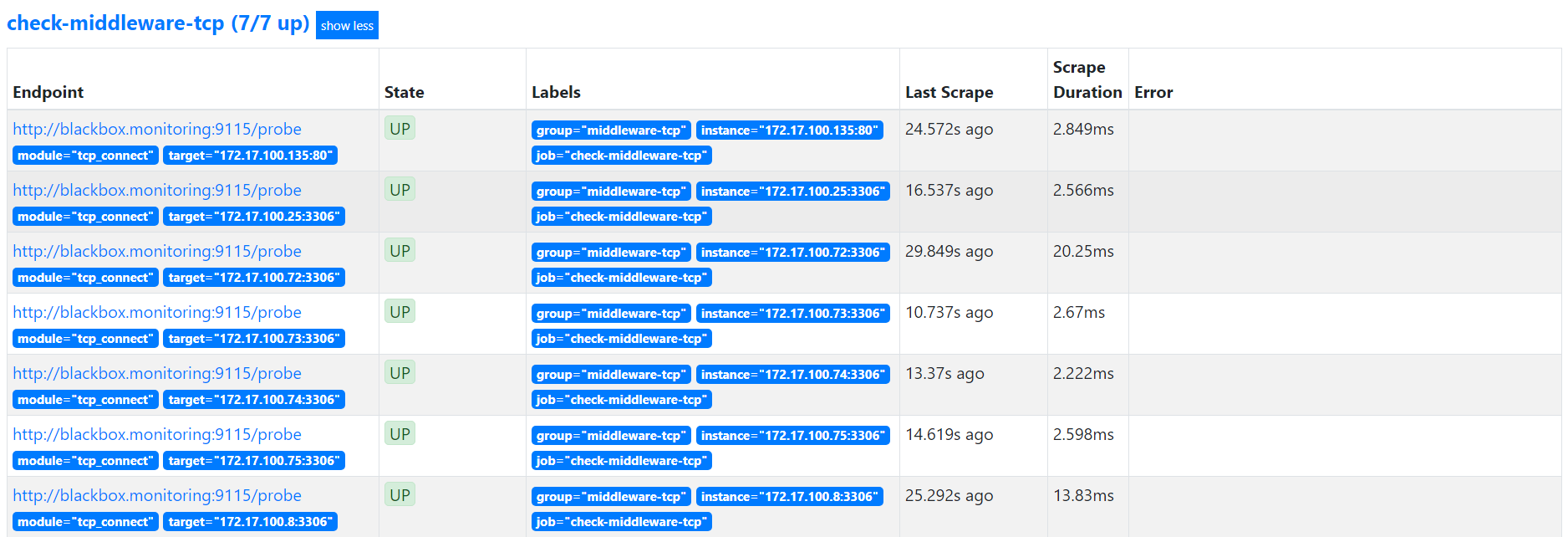
告警规则
1、业务正常性
- icmp、tcp、http、post 监测是否正常可以观察probe_success 这一指标
- probe_success == 0 ##联通性异常
- probe_success == 1 ##联通性正常
- 告警也是判断这个指标是否等于0,如等于0 则触发异常报警
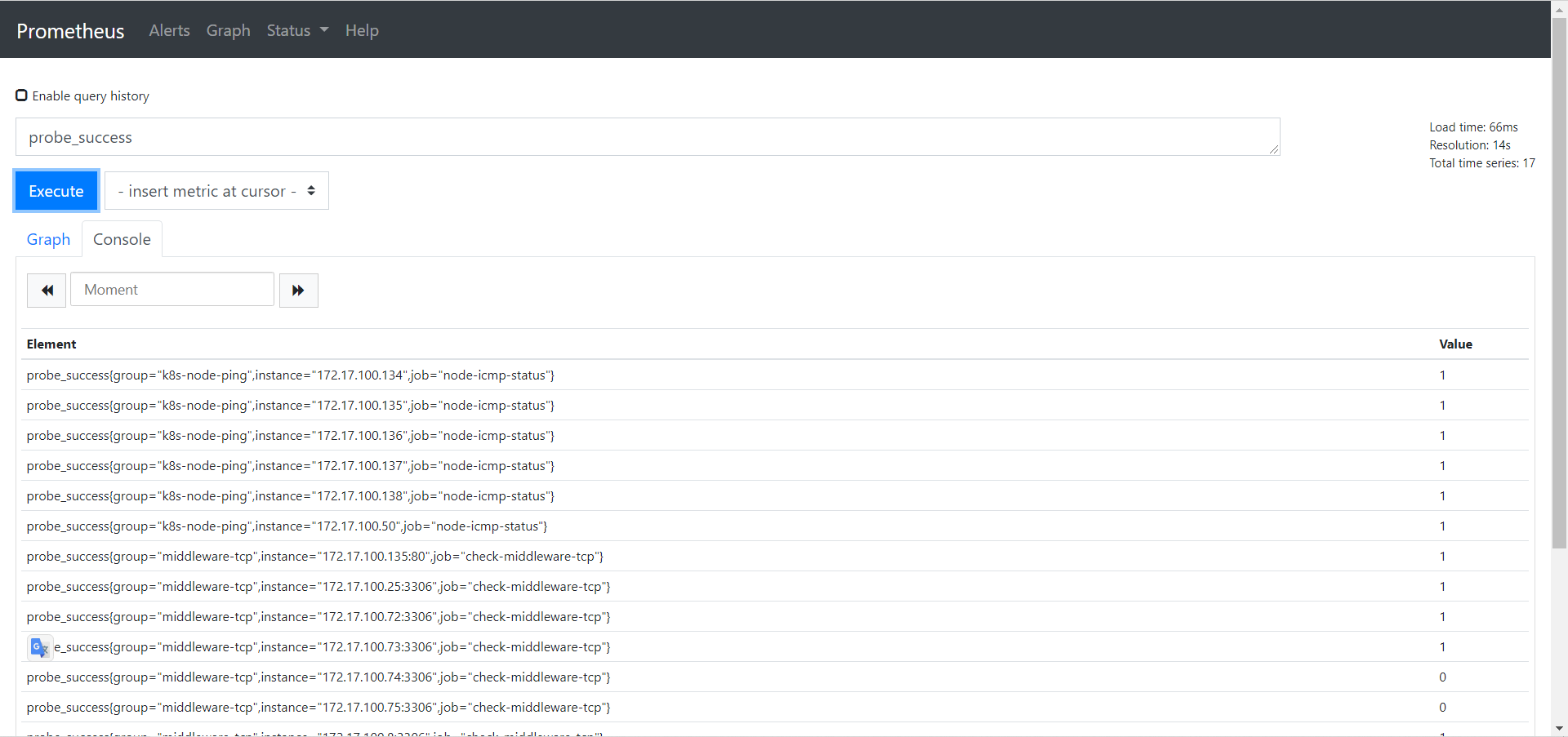
2、通过 http 模块我们可以获取证书的过期时间,可以根据过期时间添加相关告警
probe_ssl_earliest_cert_expiry :可以查询证书到期时间。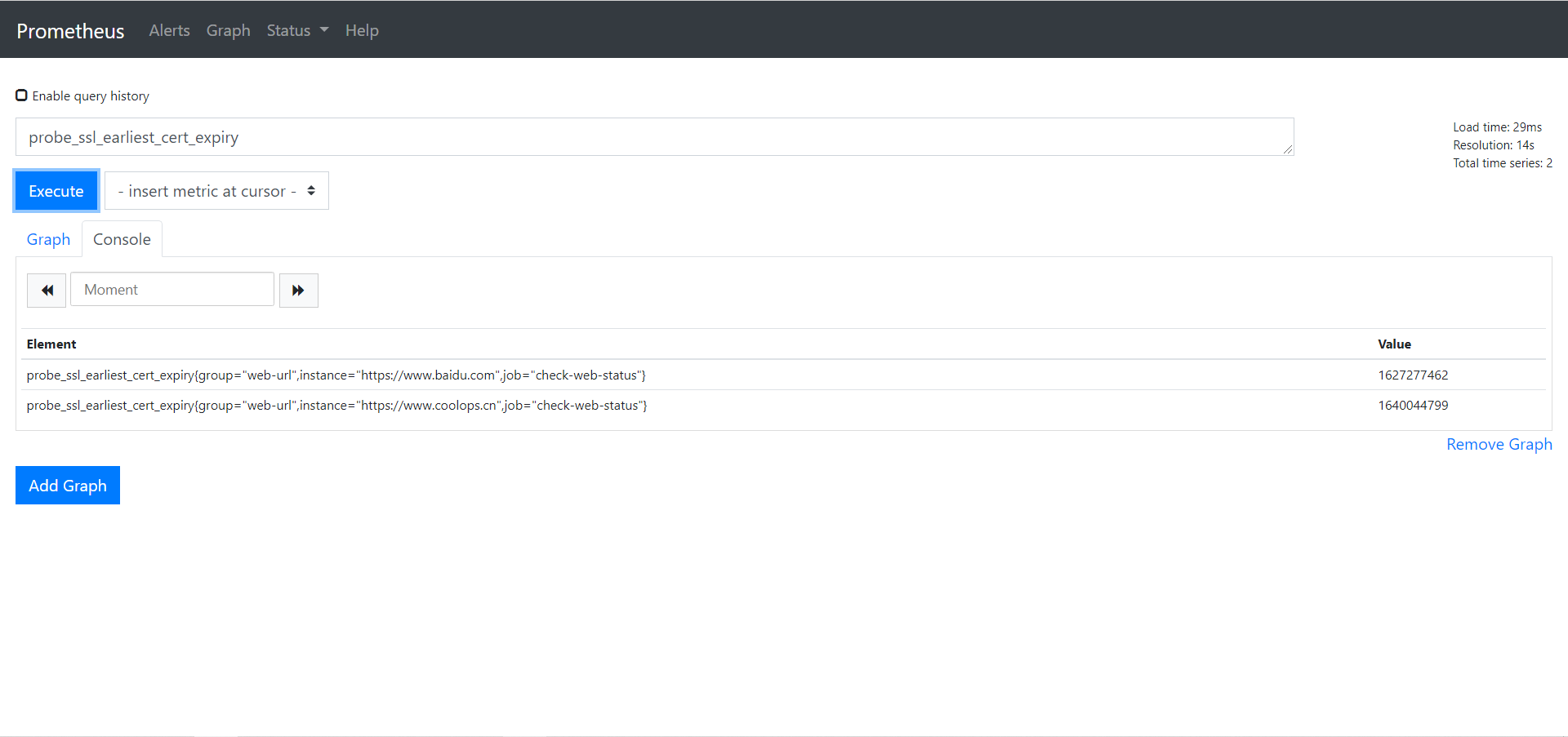
经过单位转换我们可以得到一下,按天来计算:(probe_ssl_earliest_cert_expiry - time())/86400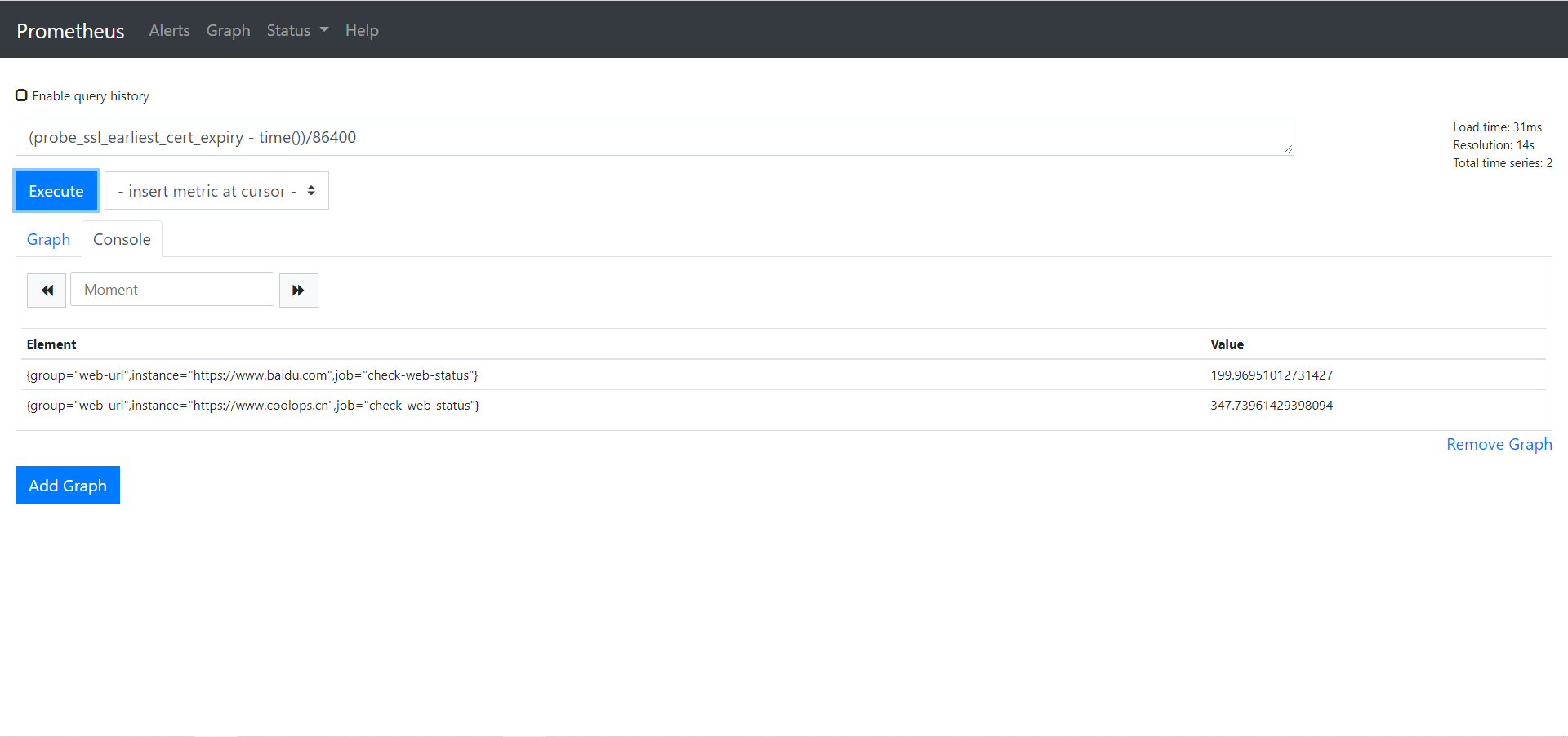
3、所以我们结合上面的配置可以定制如下告警规则
groups:- name: blackbox_network_statsrules:- alert: blackbox_network_statsexpr: probe_success == 0for: 1mlabels:severity: criticalannotations:summary: "接口/主机/端口 {{ $labels.instance }} 无法联通"description: "接口/主机/端口 {{ $labels.instance }} 无法联通"
ssl检测
groups:- name: check_ssl_statusrules:- alert: "ssl证书过期警告"expr: (probe_ssl_earliest_cert_expiry - time())/86400 <30for: 1hlabels:severity: warnannotations:description: '域名{{$labels.instance}}的证书还有{{ printf "%.1f" $value }}天就过期了,请尽快更新证书'summary: "ssl证书过期警告"
Grafana面板
直接使用12559,导入即可。
导入后就是这个样子。

若有收获,就点个赞吧
0 人点赞
