一、介绍
Operator是CoreOS公司开发,用于扩展kubernetes API或特定应用程序的控制器,它用来创建、配置、管理复杂的有状态应用,例如数据库,监控系统。其中Prometheus-Operator就是其中一个重要的项目。
其架构图如下: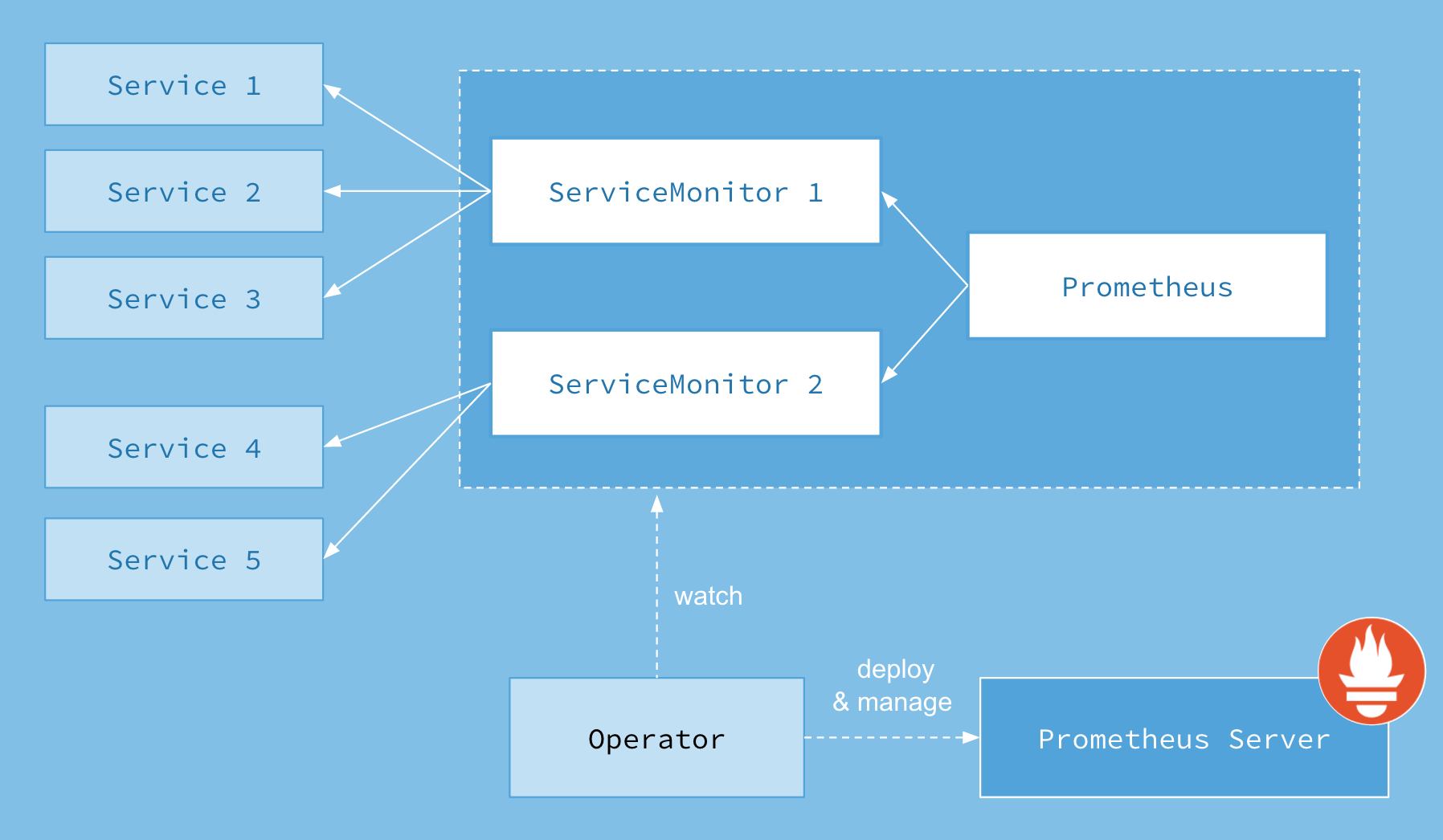
其中核心部分是Operator,它会去创建Prometheus、ServiceMonitor、AlertManager、PrometheusRule这4个CRD对象,然后会一直监控并维护这4个对象的状态。
- Prometheus:作为Prometheus Server的抽象
- ServiceMonitor:就是exporter的各种抽象
- AlertManager:作为Prometheus AlertManager的抽象
- PrometheusRule:实现报警规则的文件
上图中的 Service 和 ServiceMonitor 都是 Kubernetes 的资源,一个 ServiceMonitor 可以通过 labelSelector 的方式去匹配一类 Service,Prometheus 也可以通过 labelSelector 去匹配多个ServiceMonitor。
二、安装
注意集群版本的坑,自己先到Github上下载对应的版本。

我们使用源码来安装,首先克隆源码到本地:
# git clone https://github.com/coreos/kube-prometheus.git
我们进入kube-prometheus/manifests/setup,就可以直接创建CRD对象:
# cd kube-prometheus/manifests/setup# kubectl apply -f .
然后在上层目录创建资源清单:
# cd kube-prometheus/manifests# kubectl apply -f .
可以看到创建如下的CRD对象:
# kubectl get crd | grep coreosalertmanagers.monitoring.coreos.com 2019-12-02T03:03:37Zpodmonitors.monitoring.coreos.com 2019-12-02T03:03:37Zprometheuses.monitoring.coreos.com 2019-12-02T03:03:37Zprometheusrules.monitoring.coreos.com 2019-12-02T03:03:37Zservicemonitors.monitoring.coreos.com 2019-12-02T03:03:37Z
查看创建的pod:
# kubectl get pod -n monitoringNAME READY STATUS RESTARTS AGEalertmanager-main-0 2/2 Running 0 2m37salertmanager-main-1 2/2 Running 0 2m37salertmanager-main-2 2/2 Running 0 2m37sgrafana-77978cbbdc-886cc 1/1 Running 0 2m46skube-state-metrics-7f6d7b46b4-vrs8t 3/3 Running 0 2m45snode-exporter-5552n 2/2 Running 0 2m45snode-exporter-6snb7 2/2 Running 0 2m45sprometheus-adapter-68698bc948-6s5f2 1/1 Running 0 2m45sprometheus-k8s-0 3/3 Running 1 2m27sprometheus-k8s-1 3/3 Running 1 2m27sprometheus-operator-6685db5c6-4tdhp 1/1 Running 0 2m52s
查看创建的Service:
# kubectl get svc -n monitoringNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEalertmanager-main ClusterIP 10.68.97.247 <none> 9093/TCP 3m51salertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 3m41sgrafana ClusterIP 10.68.234.173 <none> 3000/TCP 3m50skube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 3m50snode-exporter ClusterIP None <none> 9100/TCP 3m50sprometheus-adapter ClusterIP 10.68.109.201 <none> 443/TCP 3m50sprometheus-k8s ClusterIP 10.68.9.232 <none> 9090/TCP 3m50sprometheus-operated ClusterIP None <none> 9090/TCP 3m31sprometheus-operator ClusterIP None <none> 8080/TCP 3m57s
我们看到我们常用的prometheus和grafana都是clustorIP,我们要外部访问可以配置为NodePort类型或者用ingress。比如配置为ingress:
prometheus-ingress.yaml
apiVersion: extensions/v1beta1kind: Ingressmetadata:name: prometheus-ingressnamespace: monitoringannotations:kubernetes.io/ingress.class: "traefik"spec:rules:- host: prometheus.joker.comhttp:paths:- path:backend:serviceName: prometheus-k8sservicePort: 9090
grafana-ingress.yaml
apiVersion: extensions/v1beta1kind: Ingressmetadata:name: grafana-ingressnamespace: monitoringannotations:kubernetes.io/ingress.class: "traefik"spec:rules:- host: grafana.joker.comhttp:paths:- path:backend:serviceName: grafanaservicePort: 3000
但是我们这里由于没有域名进行备案,我们就用NodePort类型。修改后如下:
# kubectl get svc -n monitoringNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEgrafana NodePort 10.68.234.173 <none> 3000:39807/TCP 3h1m 3h1mprometheus-k8s NodePort 10.68.9.232 <none> 9090:20547/TCP 3h1m
然后就可以正常在浏览器访问了。
三、配置
3.1、监控集群资源
我们可以看到大部分的配置都是正常的,只有两三个没有管理到对应的监控目标,比如 kube-controller-manager 和 kube-scheduler 这两个系统组件,这就和 ServiceMonitor 的定义有关系了,我们先来查看下 kube-scheduler 组件对应的 ServiceMonitor 资源的定义:(prometheus-serviceMonitorKubeScheduler.yaml)
apiVersion: monitoring.coreos.com/v1kind: ServiceMonitormetadata:labels:k8s-app: kube-schedulername: kube-schedulernamespace: monitoringspec:endpoints:- interval: 30s # 每30s获取一次信息port: http-metrics # 对应service的端口名jobLabel: k8s-appnamespaceSelector: # 表示去匹配某一命名空间中的service,如果想从所有的namespace中匹配用any: truematchNames:- kube-systemselector: # 匹配的 Service 的labels,如果使用mathLabels,则下面的所有标签都匹配时才会匹配该service,如果使用matchExpressions,则至少匹配一个标签的service都会被选择matchLabels:k8s-app: kube-scheduler
上面是一个典型的 ServiceMonitor 资源文件的声明方式,上面我们通过selector.matchLabels在 kube-system 这个命名空间下面匹配具有k8s-app=kube-scheduler这样的 Service,但是我们系统中根本就没有对应的 Service,所以我们需要手动创建一个 Service:(prometheus-kubeSchedulerService.yaml)
apiVersion: v1kind: Servicemetadata:namespace: kube-systemname: kube-schedulerlabels:k8s-app: kube-schedulerspec:selector:component: kube-schedulerports:- name: http-metricsport: 10251targetPort: 10251protocol: TCP
10251是
kube-scheduler组件 metrics 数据所在的端口,10252是kube-controller-manager组件的监控数据所在端口。
其中最重要的是上面 labels 和 selector 部分,labels 区域的配置必须和我们上面的 ServiceMonitor 对象中的 selector 保持一致,selector下面配置的是component=kube-scheduler,为什么会是这个 label 标签呢,我们可以去 describe 下 kube-scheduelr 这个 Pod:
$ kubectl describe pod kube-scheduler-master -n kube-systemName: kube-scheduler-masterNamespace: kube-systemNode: master/10.151.30.57Start Time: Sun, 05 Aug 2018 18:13:32 +0800Labels: component=kube-schedulertier=control-plane......
我们可以看到这个 Pod 具有component=kube-scheduler和tier=control-plane这两个标签,而前面这个标签具有更唯一的特性,所以使用前面这个标签较好,这样上面创建的 Service 就可以和我们的 Pod 进行关联了,直接创建即可:
$ kubectl create -f prometheus-kubeSchedulerService.yaml$ kubectl get svc -n kube-system -l k8s-app=kube-schedulerNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEkube-scheduler ClusterIP 10.102.119.231 <none> 10251/TCP 18m
创建完成后,隔一小会儿后去 prometheus 查看 targets 下面 kube-scheduler 的状态: promethus kube-scheduler error
promethus kube-scheduler error
我们可以看到现在已经发现了 target,但是抓取数据结果出错了,这个错误是因为我们集群是使用 kubeadm 搭建的,其中 kube-scheduler 默认是绑定在127.0.0.1上面的,而上面我们这个地方是想通过节点的 IP 去访问,所以访问被拒绝了,我们只要把 kube-scheduler 绑定的地址更改成0.0.0.0即可满足要求,由于 kube-scheduler 是以静态 Pod 的形式运行在集群中的,所以我们只需要更改静态 Pod 目录下面对应的 YAML 文件即可:
$ ls /etc/kubernetes/manifests/etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
将 kube-scheduler.yaml 文件中-command的—address地址更改成0.0.0.0:
containers:- command:- kube-scheduler- --leader-elect=true- --kubeconfig=/etc/kubernetes/scheduler.conf- --address=0.0.0.0
修改完成后我们将该文件从当前文件夹中移除,隔一会儿再移回该目录,就可以自动更新了,然后再去看 prometheus 中 kube-scheduler 这个 target 是否已经正常了: promethues-operator-kube-scheduler
promethues-operator-kube-scheduler
大家可以按照上面的方法尝试去修复下 kube-controller-manager 组件的监控。
3.2、监控集群外资源
很多时候我们并不是把所有资源都部署在集群内的,经常有比如ectd,kube-scheduler等都部署在集群外。其监控流程和上面大致一样,唯一的区别就是在定义Service的时候,其EndPoints是需要我们自己去定义的。
3.2.1、监控kube-scheduler
(1)、定义Service和EndPoints
prometheus-KubeSchedulerService.yaml
apiVersion: v1kind: Servicemetadata:name: kube-schedulernamespace: kube-systemlabels:k8s-app: kube-schedulerspec:type: ClusterIPclusterIP: Noneports:- name: http-metricsport: 10251targetPort: 10251protocol: TCP---apiVersion: v1kind: Endpointsmetadata:name: kube-schedulernamespace: kube-systemlabels:k8s-app: kube-schedulersubsets:- addresses:- ip: 172.16.0.33ports:- name: http-metricsport: 10251protocol: TCP
(2)、定义ServiceMonitor
prometheus-serviceMonitorKubeScheduler.yaml
apiVersion: monitoring.coreos.com/v1kind: ServiceMonitormetadata:name: kube-schedulernamespace: monitoringlabels:k8s-app: kube-schedulerspec:endpoints:- interval: 30sport: http-metricsjobLabel: k8s-appnamespaceSelector:matchNames:- kube-systemselector:matchLabels:k8s-app: kube-scheduler
然后我们就可以看到其监控上了:
3.2.2、监控kube-controller-manager
(1)、配置Service和EndPoints,
prometheus-KubeControllerManagerService.yaml
apiVersion: v1kind: Servicemetadata:name: kube-controller-managernamespace: kube-systemlabels:k8s-app: kube-controller-managerspec:type: ClusterIPclusterIP: Noneports:- name: http-metricsport: 10252targetPort: 10252protocol: TCP---apiVersion: v1kind: Endpointsmetadata:name: kube-controller-managernamespace: kube-systemlabels:k8s-app: kube-controller-managersubsets:- addresses:- ip: 172.16.0.33ports:- name: http-metricsport: 10252protocol: TCP
(2)、配置ServiceMonitor
prometheus-serviceMonitorKubeControllerManager.yaml
apiVersion: monitoring.coreos.com/v1kind: ServiceMonitormetadata:labels:k8s-app: kube-controller-managername: kube-controller-managernamespace: monitoringspec:endpoints:- interval: 30smetricRelabelings:- action: dropregex: etcd_(debugging|disk|request|server).*sourceLabels:- __name__port: http-metricsjobLabel: k8s-appnamespaceSelector:matchNames:- kube-systemselector:matchLabels:k8s-app: kube-controller-manager

3.2.3、监控etcd
很多情况下,我们的etcd都需要进行SSL认证的,所以首先需要将用到的证书保存到集群中去。
(根据自己集群证书的位置修改)
kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.key --from-file=/etc/kubernetes/pki/etcd/ca.crt
然后将上面创建的 etcd-certs 对象配置到 prometheus 资源对象中,直接更新 prometheus 资源对象即可:
# kubectl edit prometheus k8s -n monitoring
添加如下的 secrets 属性:
nodeSelector:beta.kubernetes.io/os: linuxreplicas: 2secrets:- etcd-certs
更新完成后,我们就可以在 Prometheus 的 Pod 中获取到上面创建的 etcd 证书文件了,具体的路径我们可以进入 Pod 中查看:
# kubectl exec -it prometheus-k8s-0 -n monitoring -- /bin/shDefaulting container name to prometheus.Use 'kubectl describe pod/prometheus-k8s-0 -n monitoring' to see all of the containers in this pod./prometheus $ ls /etc/prometheus/secrets/etcd-certs/ca.crt healthcheck-client.crt healthcheck-client.key/prometheus $
(1)、创建ServiceMonitor
prometheus-serviceMonitorEtcd.yamlns
apiVersion: monitoring.coreos.com/v1kind: ServiceMonitormetadata:name: k8s-etcdnamespace: monitoringlabels:k8s-app: k8s-etcdspec:jobLabel: k8s-appendpoints:- port: portinterval: 30sscheme: httpstlsConfig:caFile: /etc/prometheus/secrets/etcd-certs/ca.crtcertFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.crtkeyFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.keyinsecureSkipVerify: trueselector:matchLabels:k8s-app: k8s-etcdnamespaceSelector:matchNames:- kube-system
上面我们在 monitoring 命名空间下面创建了名为 k8s-etcd 的 ServiceMonitor 对象,基本属性和前面章节中的一致,匹配 kube-system 这个命名空间下面的具有 k8s-app=k8s-etcd 这个 label 标签的 Service,jobLabel 表示用于检索 job 任务名称的标签,和前面不太一样的地方是 endpoints 属性的写法,配置上访问 etcd 的相关证书,endpoints 属性下面可以配置很多抓取的参数,比如 relabel、proxyUrl,tlsConfig 表示用于配置抓取监控数据端点的 tls 认证,由于证书 serverName 和 etcd 中签发的可能不匹配,所以加上了 insecureSkipVerify=true.
然后创建这个配置清单:
# kubectl apply -f prometheus-serviceMonitorEtcd.yaml
(2)、创建Service
apiVersion: v1kind: Servicemetadata:name: k8s-etcdnamespace: kube-systemlabels:k8s-app: k8s-etcdspec:type: ClusterIPclusterIP: Noneports:- name: portport: 2379protocol: TCP---apiVersion: v1kind: Endpointsmetadata:name: k8s-etcdnamespace: kube-systemlabels:k8s-app: k8s-etcdsubsets:- addresses:- ip: 172.16.0.33ports:- name: portport: 2379protocol: TCP

然后在Grafana中导入3070的面板。
3.3、配置报警规则Rule
我们创建一个 PrometheusRule 资源对象后,会自动在上面的 prometheus-k8s-rulefiles-0 目录下面生成一个对应的
如下配置Ectd报警规则:
prometheus-etcdRule.yaml
apiVersion: monitoring.coreos.com/v1kind: PrometheusRulemetadata:name: etcd-rulesnamespace: monitoringlabels:prometheus: k8srole: alert-rulesspec:groups:- name: etcdrules:- alert: EtcdClusterUnavailableannotations:summary: etcd cluster smalldescription: If one more etcd peer goes down the cluster will be unavailableexpr: |count(up{job="etcd"} == 0) > (count(up{job="etcd"}) / 2 - 1)for: 3mlabels:severity: critical
然后我们创建这个配置清单:
# kubectl apply -f prometheus-etcdRule.yamlprometheusrule.monitoring.coreos.com/etcd-rules created
然后我们刷新页面,就可以看到已经生效了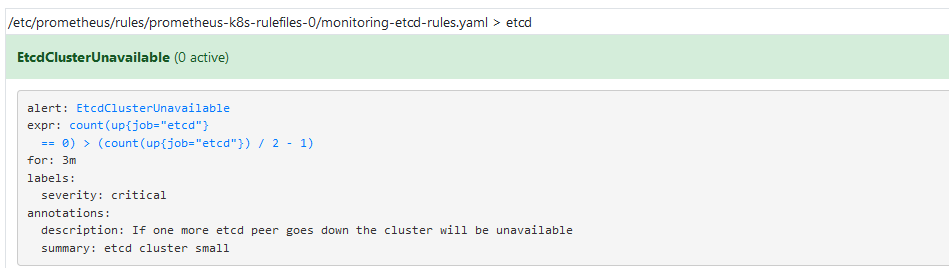
3.4、配置报警
首先我们将 alertmanager-main 这个 Service 改为 NodePort 类型的 Service,修改完成后我们可以在页面上的 status 路径下面查看 AlertManager 的配置信息:
# kubectl get svc -n monitoringNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEalertmanager-main NodePort 10.68.97.247 <none> 9093:21936/TCP 5h31m
然后在浏览器查看: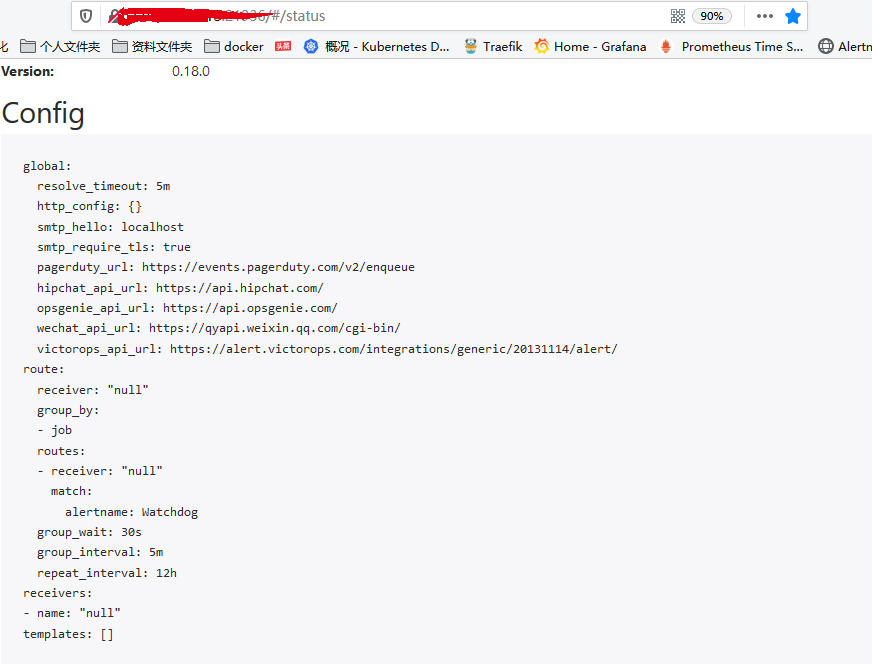
这些配置信息实际上是来自于我们之前在kube-prometheus/manifests目录下面创建的 alertmanager-secret.yaml 文件:
apiVersion: v1data:alertmanager.yaml: Imdsb2JhbCI6CiAgInJlc29sdmVfdGltZW91dCI6ICI1bSIKInJlY2VpdmVycyI6Ci0gIm5hbWUiOiAibnVsbCIKInJvdXRlIjoKICAiZ3JvdXBfYnkiOgogIC0gImpvYiIKICAiZ3JvdXBfaW50ZXJ2YWwiOiAiNW0iCiAgImdyb3VwX3dhaXQiOiAiMzBzIgogICJyZWNlaXZlciI6ICJudWxsIgogICJyZXBlYXRfaW50ZXJ2YWwiOiAiMTJoIgogICJyb3V0ZXMiOgogIC0gIm1hdGNoIjoKICAgICAgImFsZXJ0bmFtZSI6ICJXYXRjaGRvZyIKICAgICJyZWNlaXZlciI6ICJudWxsIg==kind: Secretmetadata:name: alertmanager-mainnamespace: monitoringtype: Opaque
可以将 alertmanager.yaml 对应的 value 值做一个 base64 解码:
# echo "Imdsb2JhbCI6CiAgInJlc29sdmVfdGltZW91dCI6ICI1bSIKInJlY2VpdmVycyI6Ci0gIm5hbWUiOiAibnVsbCIKInJvdXRlIjoKICAiZ3JvdXBfYnkiOgogIC0gImpvYiIKICAiZ3JvdXBfaW50ZXJ2YWwiOiAiNW0iCiAgImdyb3VwX3dhaXQiOiAiMzBzIgogICJyZWNlaXZlciI6ICJudWxsIgogICJyZXBlYXRfaW50ZXJ2YWwiOiAiMTJoIgogICJyb3V0ZXMiOgogIC0gIm1hdGNoIjoKICAgICAgImFsZXJ0bmFtZSI6ICJXYXRjaGRvZyIKICAgICJyZWNlaXZlciI6ICJudWxsIg==" | base64 -d"global":"resolve_timeout": "5m""receivers":- "name": "null""route":"group_by":- "job""group_interval": "5m""group_wait": "30s""receiver": "null""repeat_interval": "12h""routes":- "match":"alertname": "Watchdog""receiver": "null"
可以看到上面的内容和我们在网页上查到的是一致的。
如果要配置报警媒介,就可以修改这个模板:
alertmanager.yaml
global:resolve_timeout: 5msmtp_smarthost: 'smtp.163.com:465'smtp_from: 'fmbankops@163.com'smtp_auth_username: 'fmbankops@163.com'smtp_auth_password: '<邮箱密码>'smtp_hello: '163.com'smtp_require_tls: falseroute:group_by: ['job', 'severity']group_wait: 30sgroup_interval: 5mrepeat_interval: 12hreceiver: defaultroutes:- receiver: webhookmatch:alertname: CoreDNSDownreceivers:- name: 'default'email_configs:- to: '517554016@qq.com'send_resolved: true- name: 'webhook'webhook_configs:- url: 'http://dingtalk-hook.kube-ops:5000' # 这是我们自定义的webhooksend_resolved: true
然后我们更新secret对象:
# 先将之前的 secret 对象删除$ kubectl delete secret alertmanager-main -n monitoringsecret "alertmanager-main" deleted$ kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml -n monitoringsecret "alertmanager-main" created
然后就会收到报警信息: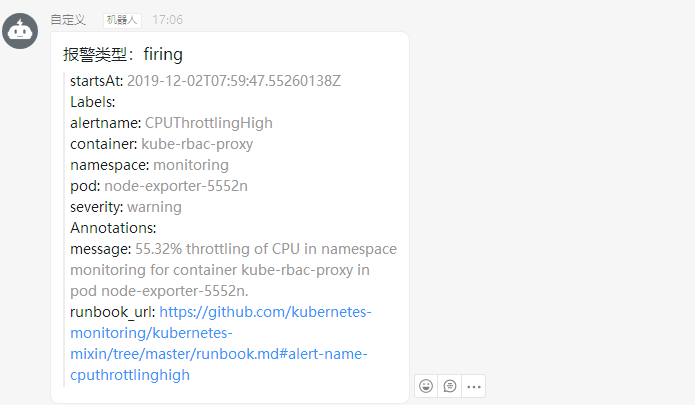
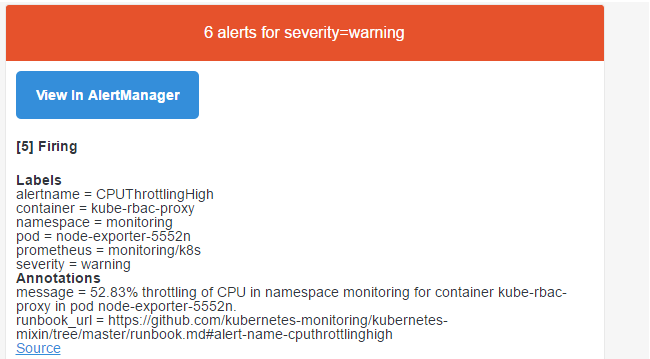
四、高级配置
4.1、自动发现规则配置
我们在实际应用中会部署非常多的service和pod,如果要一个一个手动的添加监控将会是一个非常重复,浪费时间的工作,这时候就需要使用自动发现机制。我们在手动搭建Prometheus的过程中曾配置过自动发现service,其主要的配置文件如下:
- job_name: 'kubernetes-service-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?)- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2- action: labelmapregex: __meta_kubernetes_service_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name
要想自动被发现,只需要在service的配置清单中加上annotations: prometheus.io/scrape=true。
我们将上面的文件保存为prometheus-additional.yaml,然后用这个文件创建一个secret。
# kubectl -n monitoring create secret generic additional-config --from-file=prometheus-additional.yamlsecret/additional-config created
然后我们在prometheus的配置清单中添加这个配置:
cat prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1kind: Prometheusmetadata:labels:prometheus: k8sname: k8snamespace: monitoringspec:alerting:alertmanagers:- name: alertmanager-mainnamespace: monitoringport: webbaseImage: quay.io/prometheus/prometheusnodeSelector:kubernetes.io/os: linuxpodMonitorSelector: {}replicas: 2resources:requests:memory: 400MiruleSelector:matchLabels:prometheus: k8srole: alert-rulessecurityContext:fsGroup: 2000runAsNonRoot: truerunAsUser: 1000additionalScrapeConfigs:name: additional-configkey: prometheus-additional.yamlserviceAccountName: prometheus-k8sserviceMonitorNamespaceSelector: {}serviceMonitorSelector: {}version: v2.11.0
然后更新一下prometheus的配置:
# kubectl apply -f prometheus-prometheus.yamlprometheus.monitoring.coreos.com/k8s configured
然后我们查看prometheus的日志,发现很多错误:
# kubectl logs -f prometheus-k8s-0 prometheus -n monitoring
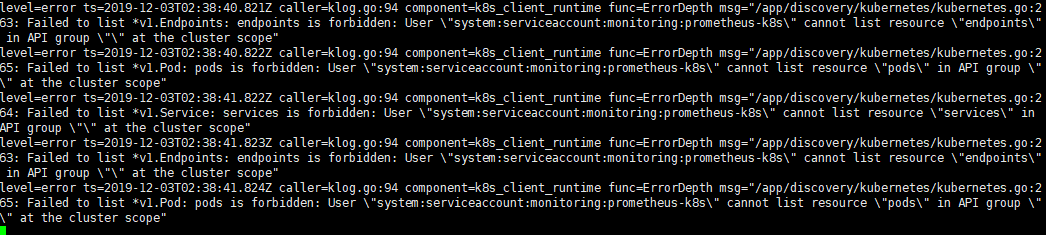
从日志可以看出,其提示的是权限问题,在kubernetes中涉及到权限问题一般就是RBAC中配置问题,我们查看prometheus的配置清单发现其使用了一个prometheus-k8s的ServiceAccount:
而其绑定的是一个叫prometheus-k8s的ClusterRole:
# kubectl get clusterrole prometheus-k8s -n monitoring -o yamlapiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata:annotations:kubectl.kubernetes.io/last-applied-configuration: |{"apiVersion":"rbac.authorization.k8s.io/v1","kind":"ClusterRole","metadata":{"annotations":{},"name":"prometheus-k8s"},"rules":[{"apiGroups":[""],"resources":["nodes/metrics"],"verbs":["get"]},{"nonResourceURLs":["/metrics"],"verbs":["get"]}]}creationTimestamp: "2019-12-02T03:03:44Z"name: prometheus-k8sresourceVersion: "1128592"selfLink: /apis/rbac.authorization.k8s.io/v1/clusterroles/prometheus-k8suid: 4f87ca47-7769-432b-b96a-1b826b28003drules:- apiGroups:- ""resources:- nodes/metricsverbs:- get- nonResourceURLs:- /metricsverbs:- get
从上面可以知道,这个clusterrole并没有service和pod的一些相关权限。接下来我们修改这个clusterrole。
prometheus-clusterRole.yaml
apiVersion: rbac.authorization.k8s.io/v1kind: ClusterRolemetadata:name: prometheus-k8srules:- apiGroups:- ""resources:- nodes/metrics- configmapsverbs:- get- apiGroups:- ""resources:- nodes- pods- services- endpoints- nodes/proxyverbs:- get- list- watch- nonResourceURLs:- /metricsverbs:- get
然后我们更新这个资源清单:
# kubectl apply -f prometheus-clusterRole.yamlclusterrole.rbac.authorization.k8s.io/prometheus-k8s configured
然后等待一段时间我们可以发现自动发现成功。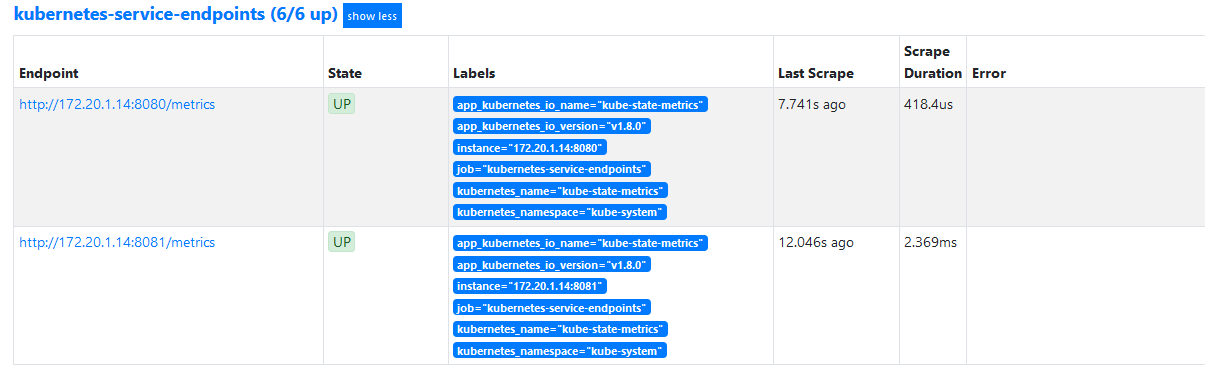
提示:配置自动发现,首先annotations里需要配置prometheus.io/scrape=true,其次你的应用要有exporter去收集信息,比如我们如下的redis配置:
apiVersion: extensions/v1beta1kind: Deploymentmetadata:name: redisnamespace: kube-opsspec:template:metadata:annotations:prometheus.io/scrape: "true"prometheus.io/port: "9121"labels:app: redisspec:containers:- name: redisimage: redis:4resources:requests:cpu: 100mmemory: 100Miports:- containerPort: 6379- name: redis-exporterimage: oliver006/redis_exporter:latestresources:requests:cpu: 100mmemory: 100Miports:- containerPort: 9121---kind: ServiceapiVersion: v1metadata:name: redisnamespace: kube-opsannotations:prometheus.io/scrape: "true"prometheus.io/port: "9121"spec:selector:app: redisports:- name: redisport: 6379targetPort: 6379- name: promport: 9121targetPort: 9121
4.2、数据持久化配置
如果我们直接git clone下来的,不做任何修改,Prometheus虽然使用的是statefuleSet,但是其用的存储卷是emptyDir,在删除Pod或者重建Pod,原始数据是会丢失的。所以在真实环境我们需要对其进行持久化,首先创建storageClass,如果是用NFS做持久化,详见第四章持久化存储中的storageClass部分。我们这里依然用的NFS做持久化。
创建StorageClass:
prometheus-storage.yaml
apiVersion: storage.k8s.io/v1kind: StorageClassmetadata:name: prometheus-storageprovisioner: rookieops/nfs
其中provisioner需要指定我们在创建nfs-client-provisioner中指定的名字,不能随意修改。
配置prometheus的配置清单:
prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1kind: Prometheusmetadata:labels:prometheus: k8sname: k8snamespace: monitoringspec:alerting:alertmanagers:- name: alertmanager-mainnamespace: monitoringport: webstorage:volumeClaimTemplate:spec:storageClassName: prometheus-storageresources:requests:storage: 20GibaseImage: quay.io/prometheus/prometheusnodeSelector:kubernetes.io/os: linuxpodMonitorSelector: {}replicas: 2resources:requests:memory: 400MiruleSelector:matchLabels:prometheus: k8srole: alert-rulessecurityContext:fsGroup: 2000runAsNonRoot: truerunAsUser: 1000additionalScrapeConfigs:name: additional-configkey: prometheus-additional.yamlserviceAccountName: prometheus-k8sserviceMonitorNamespaceSelector: {}serviceMonitorSelector: {}version: v2.11.0
然后就可以正常使用持久化了,建议在部署之初就做更改。

若有收获,就点个赞吧
0 人点赞
