Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,而且很容易做到告警信息进行去重,降噪,分组等,是一款前卫的告警通知系统。
一、安装
(1)、配置configMap配置清单
alertmanager-config.yaml
apiVersion: v1kind: ConfigMapmetadata:name: alertmanager-confignamespace: kube-opsdata:alertmanager.yml: |-global:# 在没有报警的情况下声明为已解决的时间resolve_timeout: 5m# 配置邮件发送信息smtp_smarthost: 'smtp.163.com:25'smtp_from: 'xxxs@163.com'smtp_auth_username: 'xxx@163.com'smtp_auth_password: 'xxxx'smtp_hello: '163.com'smtp_require_tls: false# 所有报警信息进入后的根路由,用来设置报警的分发策略route:# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面group_by: ['alertname', 'cluster']# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。group_wait: 30s# 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。group_interval: 5m# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们repeat_interval: 5m# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器receiver: default# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。routes:- receiver: emailgroup_wait: 10smatch:team: nodereceivers:- name: 'default'email_configs:- to: 'baidjay@163.com'send_resolved: true- name: 'email'email_configs:- to: '565361785@qq.com'send_resolved: true
创建ConfigMap对象:
# kubectl apply -f alertmanager-config.yamlconfigmap/alertmanager-config created
然后配置alertmanager容器:
alertmanager-deploy.yaml
apiVersion: extensions/v1beta1kind: Deploymentmetadata:name: alertmanagernamespace: kube-opsspec:selector:matchLabels:app: alertmanagerreplicas: 2template:metadata:labels:app: alertmanagerspec:containers:- name: alertmanagerimage: prom/alertmanager:v0.19.0imagePullPolicy: IfNotPresentresources:requests:cpu: 100mmemory: 256Milimits:cpu: 100mmemory: 256MivolumeMounts:- name: alert-configmountPath: /etc/alertmanagerports:- name: httpcontainerPort: 9093volumes:- name: alert-configconfigMap:name: alertmanager-config
配置service:
alertmanager-svc.yaml
apiVersion: v1kind: Servicemetadata:name: alertmanager-svcnamespace: kube-opsannotations:prometheus.io/scrape: "true"spec:selector:app: alertmanagerports:- name: httpport: 9093
在Prometheus中配置AlertManager地址:
prom-configmap.yaml
apiVersion: v1kind: ConfigMapmetadata:name: prometheus-confignamespace: kube-opsdata:prometheus.yaml: |global:scrape_interval: 15sscrape_timeout: 15salerting:alertmanagers:- static_configs:- targets: ["alertmanager-svc:9093"]scrape_configs:- job_name: 'prometheus'static_configs:- targets: ['localhost:9090']......
然后重载配置文件,reload Prometheus:
# kubectl apply -f prom-configmap.yaml# curl -X POST "http://10.68.254.74:9090/-/reload"
二、配置报警规则
上面我们只是配置了报警器,并没有配置任何报警,所以到目前其并没有其任何作用。警报规则允许你基于 Prometheus 表达式语言的表达式来定义报警报条件,并在触发警报时发送通知给外部的接收者。
首先,定义报警规则,我们依然用ConfigMap的形式,就配置在Prometheus的configMap中:
prom-configmap.yaml
apiVersion: v1kind: ConfigMapmetadata:name: prometheus-confignamespace: kube-opsdata:prometheus.yaml: |global:scrape_interval: 15sscrape_timeout: 15salerting:alertmanagers:- static_configs:- targets: ["alertmanager-svc:9093"]rule_files:- /etc/prometheus/rules.yamlscrape_configs:- job_name: 'prometheus'static_configs:- targets: ['localhost:9090']- job_name: 'redis'static_configs:- targets: ['redis.kube-ops.svc.cluster.local:9121']- job_name: 'kubernetes-nodes'kubernetes_sd_configs:- role: noderelabel_configs:- source_labels: [__address__]regex: '(.*):10250'replacement: '${1}:9100'target_label: __address__action: replace- action: labelmapregex: __meta_kubernetes_node_label_(.+)- job_name: "kubernetes-kubelet"kubernetes_sd_configs:- role: nodescheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtinsecure_skip_verify: truebearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- job_name: "kubernetes_cAdvisor"kubernetes_sd_configs:- role: nodescheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- target_label: __address__replacement: kubernetes.default.svc:443- source_labels: [__meta_kubernetes_node_name]regex: '(.+)'replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisortarget_label: __metrics_path__- job_name: "kubernetes-apiserver"kubernetes_sd_configs:- role: endpointsscheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]action: keepregex: default;kubernetes;https- job_name: "kubernetes-scheduler"kubernetes_sd_configs:- role: endpoints- job_name: 'kubernetes-service-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?)- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2- action: labelmapregex: __meta_kubernetes_service_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_namerules.yaml: |groups:- name: test-rulerules:- alert: NodeMemoryUsageexpr: (sum(node_memory_MemTotal_bytes) - sum(node_memory_MemFree_bytes + node_memory_Buffers_bytes+node_memory_Cached_bytes)) / sum(node_memory_MemTotal_bytes) * 100 > 5for: 2mlabels:team: nodeannotations:summary: "{{$labels.instance}}: High Memory usage detected"description: "{{$labels.instance}}: Memory usage is above 5% (current value is: {{ $value }}"
上面我们定义了一个名为NodeMemoryUsage的报警规则,其中:
- for语句会使 Prometheus 服务等待指定的时间, 然后执行查询表达式。
- labels语句允许指定额外的标签列表,把它们附加在告警上。
- annotations语句指定了另一组标签,它们不被当做告警实例的身份标识,它们经常用于存储一些额外的信息,用于报警信息的展示之类的。
然后更新configmap,并重新reload:
# kubectl apply -f prom-configmap.yaml# curl -X POST "http://10.68.140.137:9090/-/reload"
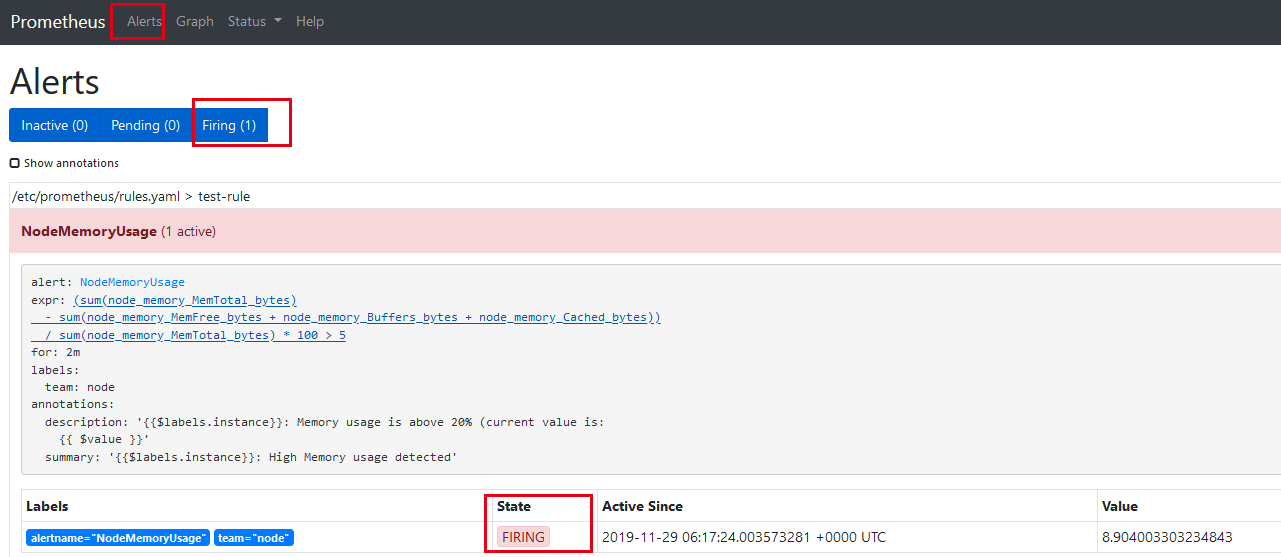
我们可以看到页面中出现了我们刚刚定义的报警规则信息,而且报警信息中还有状态显示。一个报警信息在生命周期内有下面3种状态:
- inactive: 表示当前报警信息既不是firing状态也不是pending状态
- pending: 表示在设置的阈值时间范围内被激活了
- firing: 表示超过设置的阈值时间被激活了
然后就会收到报警: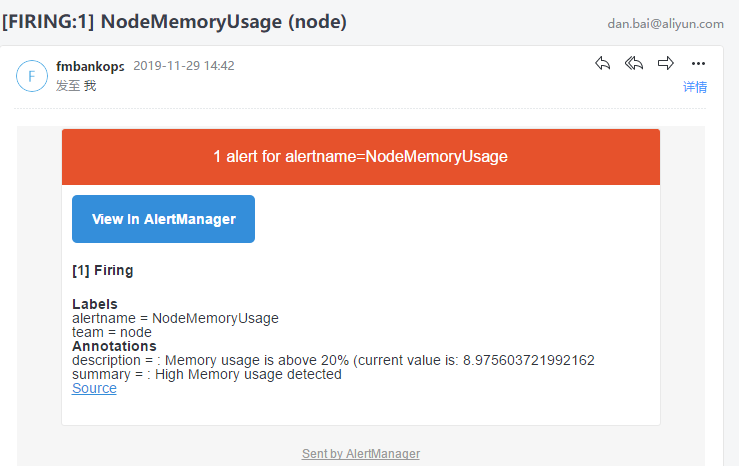
三、webhook报警
3.1、python
用Flask编写一个简单的钉钉报警程序:
#!/usr/bin/python# -*- coding:utf-8 -*-import osimport jsonimport requestsfrom flask import Flaskfrom flask import requestapp = Flask(__name__)@app.route('/', methods=['POST', 'GET'])def send():if request.method == 'POST':post_data = request.get_data()post_data = format_message(bytes2json(post_data))print(post_data)send_alert(post_data)return 'success'else:return 'weclome to use prometheus alertmanager dingtalk webhook server!'def bytes2json(data_bytes):data = data_bytes.decode('utf8').replace("'", '"')return json.loads(data)def format_message(post_data):EXCLUDE_LIST = ['prometheus', 'endpoint']message_list = []message_list.append('### 报警类型:{}'.format(post_data['status']))# message_list.append('**alertname:**{}'.format(post_data['alerts'][0]['labels']['alertname']))message_list.append('> **startsAt: **{}'.format(post_data['alerts'][0]['startsAt']))message_list.append('#### Labels:')for label in post_data['alerts'][0]['labels'].keys():if label in EXCLUDE_LIST:continueelse:message_list.append("> **{}: **{}".format(label, post_data['alerts'][0]['labels'][label]))message_list.append('#### Annotations:')for annotation in post_data['alerts'][0]['annotations'].keys():message_list.append('> **{}: **{}'.format(annotation, post_data['alerts'][0]['annotations'][annotation]))message = (" \n\n ".join(message_list))title = post_data['alerts'][0]['labels']['alertname']data = {"title": title, "message": message}return datadef send_alert(data):token = os.getenv('ROBOT_TOKEN')if not token:print('you must set ROBOT_TOKEN env')returnurl = 'https://oapi.dingtalk.com/robot/send?access_token=%s' % tokensend_data = {"msgtype": "markdown","markdown": {"title": data['title'],"text": "{}".format(data['message'])}}req = requests.post(url, json=send_data)result = req.json()print(result)if result['errcode'] != 0:print('notify dingtalk error: %s' % result['errcode'])if __name__ == '__main__':app.run(host='0.0.0.0', port=5000)
代码非常简单,通过一个 ROBOT_TOKEN 的环境变量传入群机器人的 TOKEN,然后直接将 webhook 发送过来的数据直接以文本的形式转发给群机器人。
Dockerfile内容:
FROM python:3.6.4# set working directoryWORKDIR /src# add appADD . /src# install requirementsRUN pip install -r requirements.txt# run serverCMD python app.py
requirements.txt
certifi==2018.10.15chardet==3.0.4Click==7.0Flask==1.0.2idna==2.7itsdangerous==1.1.0Jinja2==2.10MarkupSafe==1.1.0requests==2.20.1urllib3==1.24.1Werkzeug==0.14.1
我们在集群中部署服务:
创建token的secret,将token保存在文件中(钉钉自定义机器人):
#kubectl create secret generic dingtalk-secret --from-literal=token=xxxxxx -n kube-ops
dingtalk-hook.yaml
---apiVersion: extensions/v1beta1kind: Deploymentmetadata:name: dingtalk-hooknamespace: kube-opsspec:template:metadata:labels:app: dingtalk-hookspec:containers:- name: dingtalk-hookimage: registry.cn-hangzhou.aliyuncs.com/joker_kubernetes/dingtalk-hook:v0.3imagePullPolicy: IfNotPresentports:- containerPort: 5000name: httpenv:- name: ROBOT_TOKENvalueFrom:secretKeyRef:name: dingtalk-secretkey: tokenresources:requests:cpu: 50mmemory: 100Milimits:cpu: 50mmemory: 100Mi---apiVersion: v1kind: Servicemetadata:name: dingtalk-hooknamespace: kube-opsspec:selector:app: dingtalk-hookports:- name: hookport: 5000targetPort: http
创建配置清单:
# kubectl apply -f dingtalk-hook.yamldeployment.extensions/dingtalk-hook created
然后我们修改alertmanager的configmap,增加webhook:
alertmanager-config.yaml
......- receiver: webhookgroup_wait: 10smatch:filesystem: nodereceivers:- name: 'webhook'webhook_configs:- url: "http://dingtalk-hook.kube-ops.svc:5000"send_resolved: true......
更新配置文件,重新创建alertmanager-deploy.yaml
# kubectl apply -f alertmanager-config.yaml# kubectl delete -f alertmanager-deploy.yamldeployment.extensions "alertmanager" deleted# kubectl apply -f alertmanager-deploy.yamldeployment.extensions/alertmanager created
然后我们在Prometheus中添加rules,如下:
- alert: NodeFilesystemUsageexpr: (sum(node_filesystem_size_bytes{device="rootfs"}) - sum(node_filesystem_free_bytes{device="rootfs"}) ) / sum(node_filesystem_size_bytes{device="rootfs"}) * 100 > 10for: 2mlabels:filesystem: nodeannotations:summary: "{{$labels.instance}}: High Filesystem usage detected"description: "{{$labels.instance}}: Filesystem usage is above 10% (current value is: {{ $value }}"
然后我们更新Prometheus的configmap,并reload Prometheus:
# kubectl apply -f prom-configmap.yaml# curl -X POST "http://10.68.140.137:9090/-/reload"
然后我们可以看到已经触发: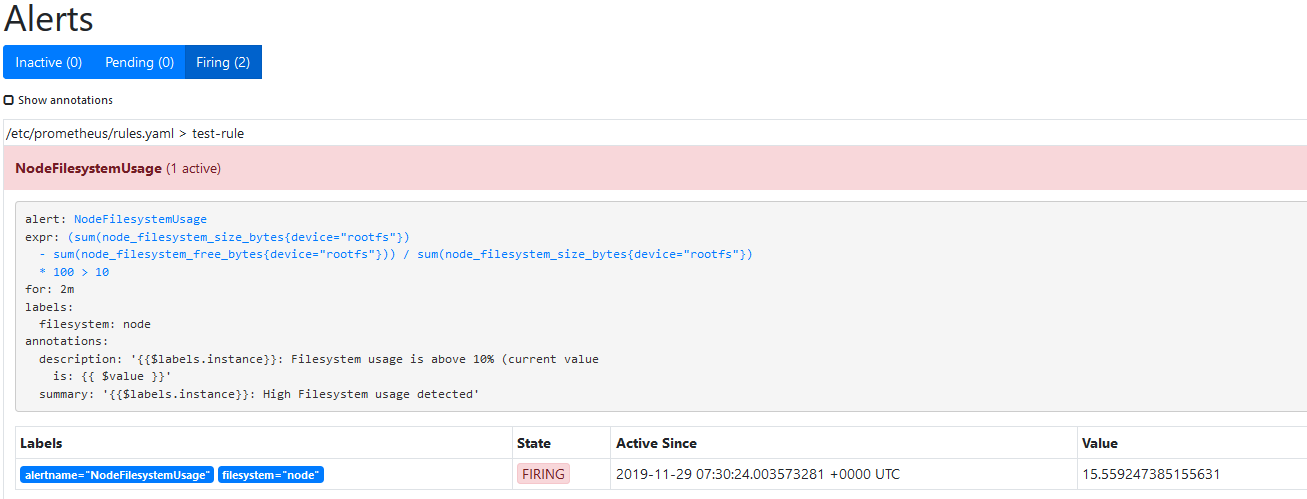

3.2、go
一个比较好的模板:https://github.com/timonwong/prometheus-webhook-dingtalk

若有收获,就点个赞吧
0 人点赞
