1、信息收集概述
渗透的本质就是在做信息收集,目标资产信息收集的程度,决定渗透过程的复杂程度。目标主机信息收集的深度,决定后渗透权限持续把控。
渗透的本质是信息收集,而信息收集整理为后续的情报跟进提供了强大的保证。
什么是信息收集:通过各种方式获取所需要的信息,以便在后续的渗透过程更好的进行。因为只有我们掌握了目标网站或目标主机足够多的信息之后,才能更好地对其进行漏洞检测。正所谓,知己知彼百战百胜。
信息收集的方式
主动收集:与目标主机进行直接交互,从而拿到目标信息,缺点是会记录自己的操作信息
被动收集:不与目标主机进行直接交互,通过搜索引擎或者社会工程等方式间接的获取目标主机的信息收集内容包含如下但不限于:
服务器的配置信息
网站的信息(包括网站注册人、目标网站系统、目标服务器系统、目标网站相关子域名、目标服务器所开放的端口等)
只要与目标网站相关联的信息,都应该尽量去搜索等。
常见的信息收集内容: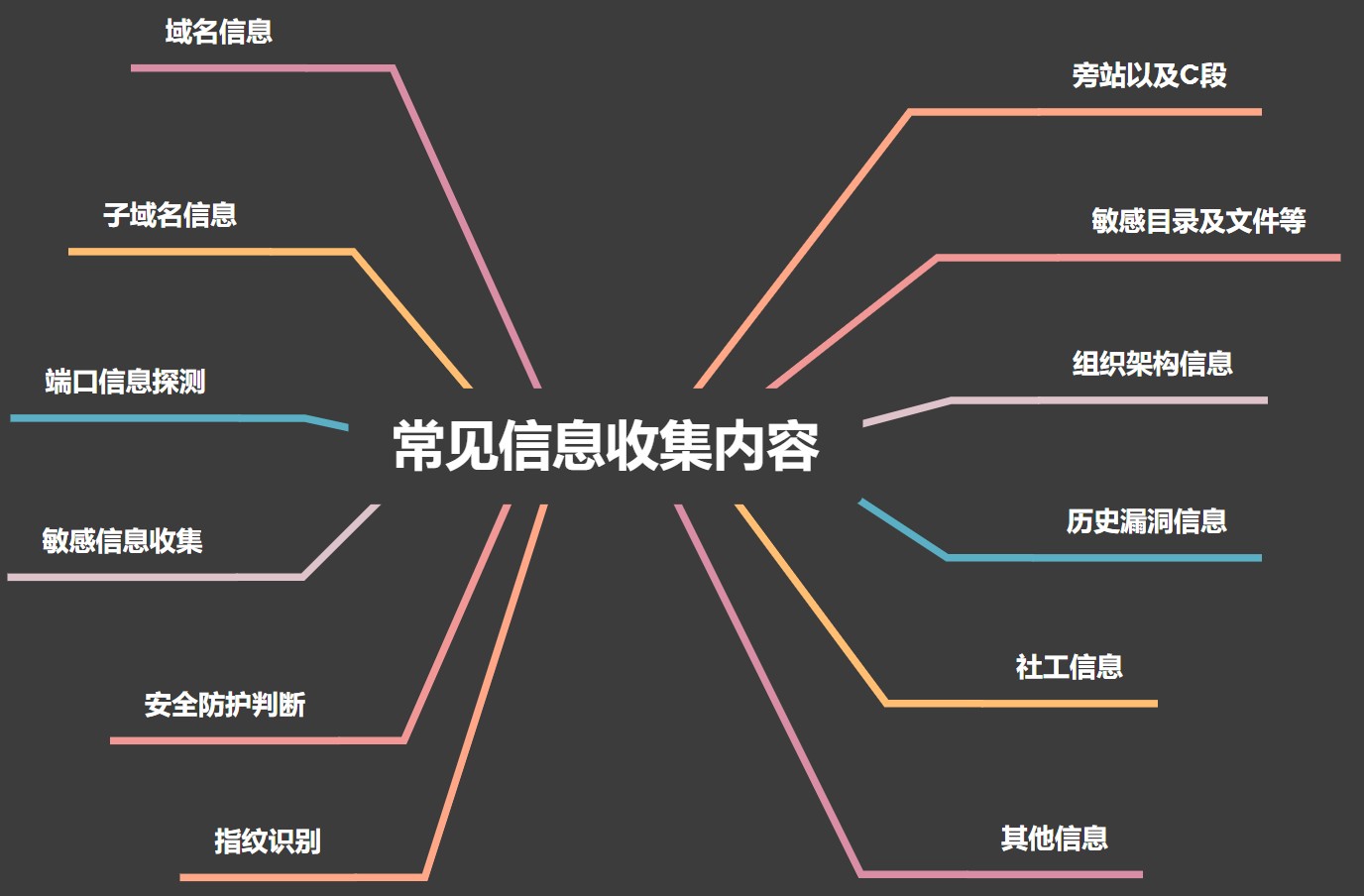
域名信息:收集域名相关的信息,如URL、IP、注册商家、注册人联系方式等;
子域名:收集指定域名的二级、三级、四级等子域名信息,主要结合业务去收集,采用爆破、搜索引擎、证书等方法去实施采集;
端口信息探测:探测目标服务上开启的服务,以及服务的banner 信息;
敏感信息收集:探测目标资源的站点服务架构、JS 接口、页面包含的链接、客户信息、邮箱等内容;
安全防护判断:通过工具和手工的方式判断目标资源中开启的防护设备,如不同类型的WAF、防火墙、EDR、杀软等;
指纹识别:识别目标资源的站点CMS 类型、中间件类型、容器类型、服务类型、系统类型等;
旁站以及C 段:收集目标站点上开启的其他的网站信息,一台服务器上可能搭建多个站点,C 段也是考虑到目标公司可能同时购买多个同段IP,C 段探测有助于资产探测和安全测试;
敏感目录和文件:目标站点中可能存在敏感文件和目录,通过目录扫描工具获取这些敏感文件和目录,如phpinfo、robots.txt、readme.md、备份文件等等;
组织架构信息:获取目标对象的内容人力资源架构,可实施社工、近源攻击等测试;
历史漏洞信息:通过目标资源的banner 信息来判断目标可能存在的漏洞问题,如根据CMS 版本来查找exploit;
社工信息:以欺骗、诱导等方式获取的社工信息,如目标人的身份信息、邮箱信息、管控系统的密码等;
其他信息:微信小程序、APP、合作商、外包商、VPN 等等
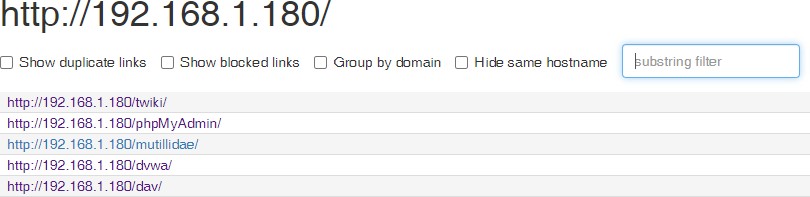
我们以随机选择的一个企业网站为例,简单讲解通过目标站点收集信息的方法。
(特别说明:课程演示需要,请不要非法测试该站点)
2、DNS 信息收集
DNS(Domain Name System:域名系统),是因特网的一项核心服务,它作为将域名和 ip 地址相互映射的一种分布式数据库,能够使人们更方便的访问互联网,而不用去记住能够被机器直接读取的地址。
主机记录(A 记录):
A 记录是用于名称解析的重要记录,它将特定的主机名映射到对应主机的IP 地址上。
IPv6 主机记录(AAAA 记录):
与A 记录对应,用于将特定的主机名映射到一个主机的IPv6 地址。
别名(CNAME 记录):
CNAME 记录用于将某个别名指向到某个A 记录上,这样就不需要再为某个新名字另外创建一条新的A 记录。
电子邮件交换记录(MX 记录):
记录一个邮件域名对应的IP 地址
域名服务器记录 (NS 记录):
记录该域名由哪台域名服务器解析
反向记录(PTR 记录):
也即从IP 地址到域名的一条记录
SOA 记录
SOA 叫做起始授权机构记录,NS 用于标识多台域名解析服务器,SOA 记录用于在众多 NS 记录中那一台是主服务器。 SOA 记录表示此域名的权威解析服务器地址。 当要查询的域名在所有递归解析服务器中没要域名解析的缓存时,就会回源来请求此域名的SOA 记录,也叫权威解析记录。
TXT 记录:
记录域名的相关文本信息
DNS 服务器分为主服务器,备份服务器,缓存服务器。
备份服务器需要利用“域传送”从主服务器上复制数据,然后更新自身的数据库,以达到数据同步的目的,这样是为了增加冗余,万一主服务器挂了还有备份服务器顶着。
而“域传送”漏洞则是由于dns 配置不当,本来只有备份服务器能获得主服务器的数据,由于漏洞导致任意client 都能通过“域传送”获得主服务器的数据(zone 数据库信息)。
这样,攻击者就能获得某个域的所有记录,甚至整个网络拓扑都暴露无遗,凭借这份网络蓝图,攻击者可以节省很多扫描时间以及信息收集的时间,还提升了准确度等等。
2.1 Windows 下使用nslookup
1、非交互式模式下,查看对应主机域的域名服务器查询 12306.cn 的 DNS 服务器
C:\WINDOWS\system32>nslookup -type=ns 12306.cn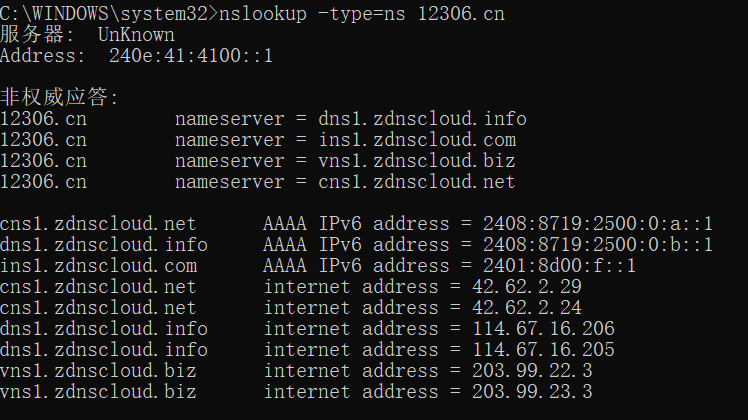
查询 12306.cn 的 SOA 记录
C:\WINDOWS\system32>nslookup -type=ns 12306.cn
主DNS 服务器是:dns1.wsglb0.org
2、进入交互模式,指定域名服务器,列出域名信息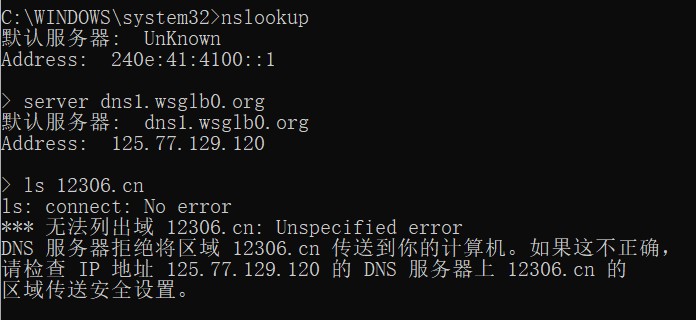
如果提示无法列出域,那就说明此域名不存在域传送漏洞。
2.2 Kali 下使用 dig、dnsenum
这里涉及 dig 一个重要的命令axfr,axfr 是q-type 类型的一种,axfr 类型是Authoritative Transfer 的缩写,指请求传送某个区域的全部记录。
我们只要欺骗dns 服务器发送一个axfr 请求过去,如果该dns 服务器上存在该漏洞,就会返回所有的解析记录值。
dig 的整体利用步骤基本和nslookup 一致。查询主DNS 服务器
┌──(root㉿kali)-[~]
└─# dig 114nz.com soa
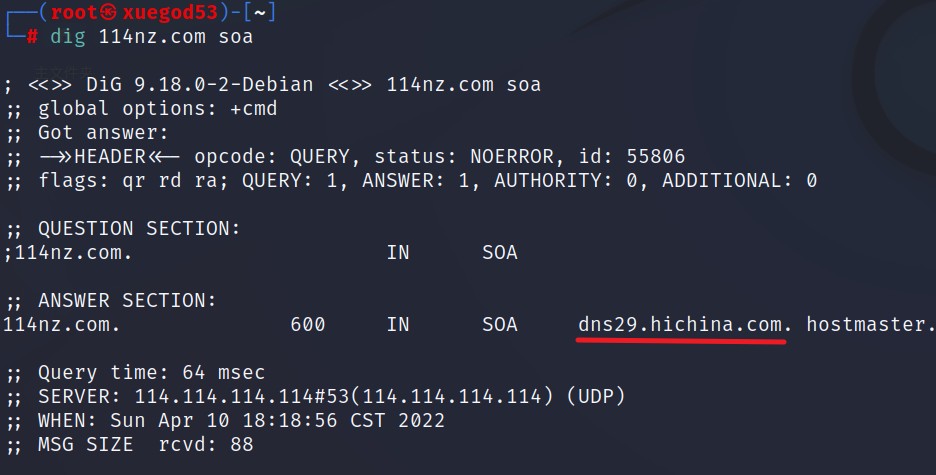
得到主DNS 服务器是:dns29.hichina.com
向该域名发送axfr 请求
└─# dig axfr @dns29.hichina.com 114nz.com
dnsenum 这个工具相较于之前的方法要为简单,一行命令即可
└─# dnsenum -enum 114nz.com dnsenum VERSION:1.2.6
——- 114nz.com ——-
Host’s addresses:
114nz.com. 1 IN A 121.40.37.245
……………………………………
Trying Zone Transfer for 114nz.com on dns29.hichina.com …
AXFR record query failed: timed out
3、域名注册和备案信息
很多网站上都可以收集到whois 信息,主要关注:注册商、注册人、邮件、DNS 解析服务器、注人联系电话。
有需要的还可以查企业的备案信息,国外的服务器一般来说是查不到的,因为他们不需要备案。国内的基本上都可以查到。
3.1 域名注册信息查询
国外的who.is:https://who.is/
站长之家:http://whois.chinaz.com/
爱站:https://whois.aizhan.com/
微步:https://x.threatbook.cn/
3.2 备案信息查询
http://icp.chinaz.com/
https://icp.aizhan.com/
https://beian.tianyancha.com/
https://beian.miit.gov.cn/#/Integrated/index
4、子域名收集
子域名是在顶级域名下的域名,收集的子域名越多,我们测试的目标就越多,渗透的成功率也越大。往往在主站找不到突破口的时候,我们从子域名入手。
子域名爆破:
1、dnsub:https://github.com/yunxu1/dnsub
2、dome:https://github.com/v4d1/Dome
3、Layer 子域名挖掘机:https://github.com/euphrat1ca/LayerDomainFinder
4、OneForAll:https://github.com/shmilylty/OneForAll
5、SubDomainsBrute:https://github.com/lijiejie/subDomainsBrute
7、ESD:https://github.com/FeeiCN/ESD
8、Dnsprobe:https://github.com/projectdiscovery/dnsprobe
9、Subfinder:https://github.com/projectdiscovery/subfinder
10、Massdns:https://github.com/blechschmidt/massdns
搜索引擎:
1、https://www.google.com
2、https://www.bing.com
3、https://www.baidu.com
4、https://fofa.info
在线子域名:
https://dnsdumpster.com/
http://tool.chinaz.com/subdomain
https://phpinfo.me/domain/
https://www.virustotal.com/
https://crt.sh/
5、查找真实 IP
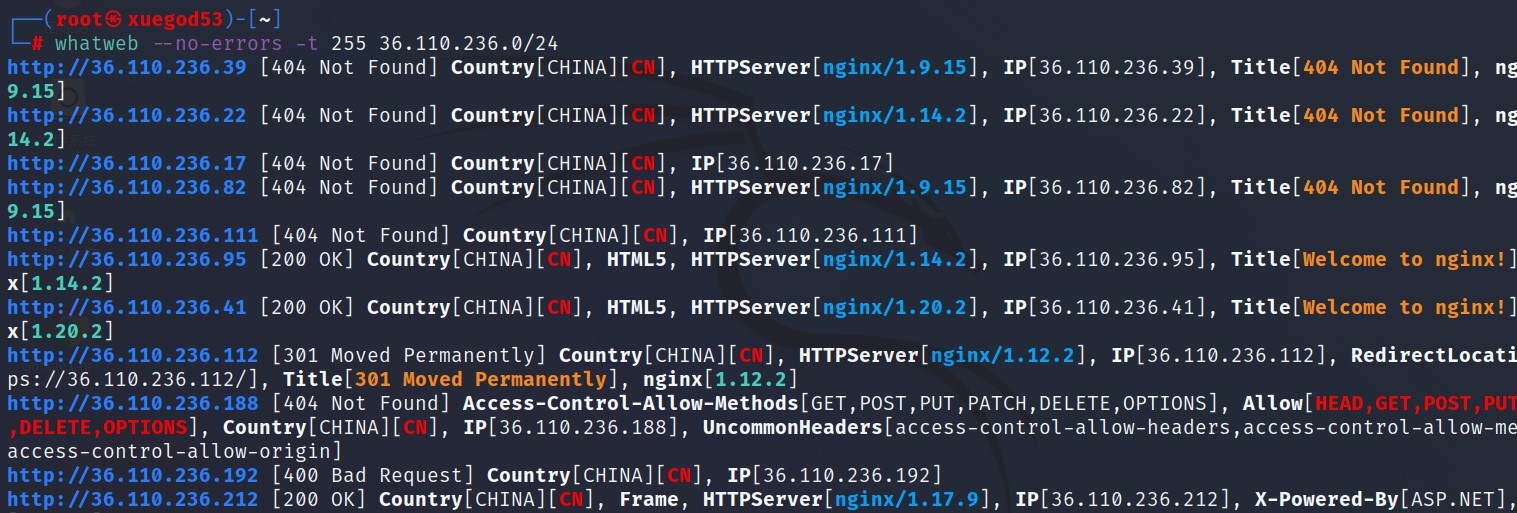
正常情况下,通过cmd 命令可以快速找到域名对应 IP,最常见的命令如 ping、nslookup。但很多站点出于用户体验和安全的角度,使用CDN 加速,将域名解析到CDN,这时候就需要绕过CDN 来查找真实IP。
CDN 的全称是Content Delivery Network,即内容分发网络。其基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。通过在网络各处放置节点服务器所构成的在现有的互联网基础之上的一层智能虚拟网络,CDN 系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上。
CDN 的基本原理是广泛采用各种缓存服务器,将这些缓存服务器分布到用户访问相对集中的地区或网络中,在用户访问网站时,利用全局负载技术将用户的访问指向距离最近的工作正常的缓存服务器上, 由缓存服务器直接响应用户请求。
CDN 的基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。通过在网络各处放置节点服务器所构成的在现有的互联网基础之上的一层智能虚拟网络,CDN 系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上。其目的是使用户可就近取得所需内容,解决Internet 网络拥挤的状况,提高用户访问网站的响应速度。
5.1 CDN 判断
查看不同时段不同地域下ping 或者nslookup 的结果,ip 不一样,则说明可能存在CDN。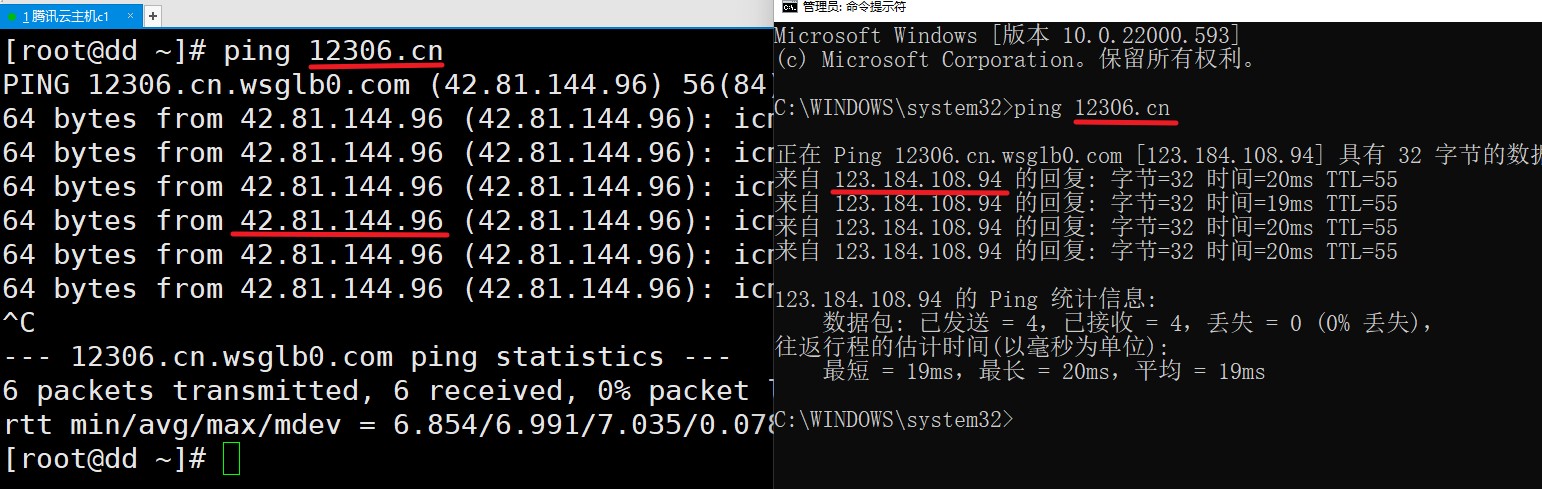
在线平台检测是否存在CDN:
Ping 检测-站长工具:http://ping.chinaz.com/
17CE:https://www.17ce.com/
国内在线CDN 云观测:http://cdn.chinaz.com
国外在线CDNplanet:https://www.cdnplanet.com
脚本探测xcdn:https://github.com/3xp10it/xcdn
5.2 绕过CDN 查找真实IP
5.2.1 DNS 历史解析记录
查询域名的历史解析记录,可能会找到网站使用CDN 前的解析记录,从而获取真实 ip。相关查询的网站有:
iphistory:https://viewdns.info/iphistory/
DNS 查询:https://dnsdb.io/zh-cn/
微步在线:https://x.threatbook.cn/
域名查询:https://site.ip138.com/
DNS 历史查询:https://securitytrails.com/
Netcraft:https://sitereport.netcraft.com/
5.2.2 查找子域名
很多时候,一些重要的站点会做CDN,而一些子域名站点并没有加入CDN,而且跟主站在同一个C段内,这时候,就可以通过查找子域名来查找网站的真实IP。
常用的子域名查找方法和工具:
1、搜索引擎查询:如 Google、baidu、Bing 等传统搜索引擎,site:http://baidu.com inurl:http://baidu.com,搜target.com 或公司名字。
2、一些在线查询工具,如:
https://dnsdumpster.com/
http://tool.chinaz.com/subdomain
https://phpinfo.me/domain/
https://www.virustotal.com/
https://crt.sh/
3、子域名爆破工具
Layer 子域名挖掘机
dnsub https://github.com/yunxu1/dnsub
dome https://github.com/v4d1/Dome
5.2.3 网站邮件头信息
比如说,邮箱注册,邮箱找回密码、RSS 邮件订阅等功能场景,通过网站给自己发送邮件,从而让目标主动暴露他们的真实的IP,查看邮件头信息,获取到网站的真实IP。
5.2.4 网络空间安全引擎搜索
通过关键字或网站域名,就可以找出被收录的 IP,很多时候获取到的就是网站的真实 IP。
钟馗之眼:https://www.zoomeye.org
Shodan:https://www.shodan.io
Fofa:https://fofa.info
5.2.5 利用SSL 证书寻找真实IP
证书颁发机构(CA)必须将他们发布的每个SSL/TLS 证书发布到公共日志中,SSL/TLS 证书通常包含域名、子域名和电子邮件地址。因此SSL/TLS 证书成为了攻击者的切入点。
SSL 证书搜索引擎:
https://search.censys.io/
5.2.6 国外主机解析域名
大部分CDN 厂商因为各种原因只做了国内的线路,而针对国外的线路可能几乎没有,此时我们使用国外的DNS 查询,很可能获取到真实 IP。
国外多PING 测试工具:
http://host-tracker.com/
http://www.webpagetest.org/
https://dnscheck.pingdom.com/
5.2.7 扫描全网
通过zmap、masscan 等工具对整个互联网发起扫描,针对扫描结果进行关键字查找,获取网站真实IP。
1、zmap 号称是最快的互联网扫描工具,能够在 45 分钟扫遍全网。
https://github.com/zmap/zmap
2、masscan 号称是最快的互联网端口扫描器,最快可以在六分钟内扫遍互联网。
https://github.com/robertdavidgraham/masscan
5.2.8 配置不当导致绕过
在配置CDN 的时候,需要指定域名、端口等信息,有时候小小的配置细节就容易导致CDN 防护被绕过。
案例 1:为了方便用户访问,我们常常将www.test.com 和 test.com 解析到同一个站点,而CDN 只配置了www.test.com,通过访问 test.com,就可以绕过 CDN 了。
例:www.sp910.com、www.xueersi.com
案例 2:站点同时支持http 和https 访问,CDN 只配置 https 协议,那么这时访问http 就可以轻易绕过。
6、端口信息收集
开放端口——开放代表可通信,端口决定服务。
服务类型探测——服务类型决定了该服务可能存在的漏洞。
端口协议——自定义端口可迷惑扫描器,需要根据返回信息判断协议。
端口即服务,服务即端口。
6.1 常见端口及其脆弱点
- FTP (21/TCP)
- 默认用户名密码 anonymous:anonymous
- 暴力破解密码
- VSFTP 某版本后门
- SSH (22/TCP)
- 部分版本SSH 存在漏洞可枚举用户名
- 暴力破解密码
- Telent (23/TCP)
- 暴力破解密码
- 嗅探抓取明文密码
- SMTP (25/TCP)
- 无认证时可伪造发件人
- DNS (53/UDP)
- 域传送漏洞
- DNS 劫持
- DNS 缓存投毒
- DNS 欺骗
- SPF / DMARC Check
- DDoS
- DNS Query Flood
- DNS 反 弹
- DNS 隧 道
- DHCP 67/68
- 劫持/欺骗
- TFTP (69/TCP)
- HTTP (80/TCP)
- Kerberos (88/TCP)
- 主要用于监听KDC 的票据请求
- 用于进行黄金票据和白银票据的伪造
- POP3 (110/TCP)
- 爆破
- RPC (135/TCP)
- wmic 服务利用
- NetBIOS (137/UDP & 138/UDP)
- 未授权访问
- 弱口令
- NetBIOS / Samba (139/TCP)
- 未授权访问
- 弱口令
- SNMP (161/TCP)
- Public 弱口令
- LDAP (389/TCP)
- 用于域上的权限验证服务
- 匿名访问
- 注入
- HTTPS (443/TCP)
- SMB (445/TCP)
- Windows 协议簇,主要功能为文件共享服务
- net use \192.168.1.1 /user:xxx\username password
- Linux Rexec (512/TCP & 513/TCP & 514/TCP)
- 弱口令
- Rsync (873/TCP)
- 未授权访问
- RPC (1025/TCP)
- NFS 匿名访问
- Java RMI (1090/TCP & 1099/TCP)
- 反序列化远程命令执行漏洞
- MSSQL (1433/TCP)
- 弱密码
- 差异备份 GetShell
- SA 提 权
- Oracle (1521/TCP)
- 弱密码
- NFS (2049/TCP)
- 权限设置不当
- showmount
- ZooKeeper (2171/TCP & 2375/TCP)
- 无身份认证
- Docker Remote API (2375/TCP)
- 未限制IP / 未启用TLS 身份认证
- http://docker.addr:2375/version
- MySQL (3306/TCP)
- 弱密码
- 日志写WebShell
- UDF 提权
- MOF 提权
- RDP / Terminal Services (3389/TCP)
- 弱密码
- Postgres (5432/TCP)
- 弱密码
- 执行系统命令
- VNC (5900/TCP)
- 弱密码
- CouchDB (5984/TCP)
- 未授权访问
- WinRM (5985/TCP)
- Windows 对WS-Management 的实现
- 在Vista 上需要手动启动,在 Windows Server 2008 中服务是默认开启的
- Redis (6379/TCP)
- 无密码或弱密码
- 绝对路径写 WebShell
- 计划任务反弹 Shell
- 写 SSH 公 钥
- 主从复制 RCE
- Windows 写启动项
- Kubernetes API Server (6443/TCP && 10250/TCP)
- JDWP (8000/TCP)
- 远程命令执行
- ActiveMQ (8061/TCP)
- Jenkin (8080/TCP)
- 未授权访问
- Elasticsearch (9200/TCP)
- Memcached (11211/TCP)
- 未授权访问
- RabbitMQ (15672/TCP & 15692/TCP & 25672/TCP)
- MongoDB (27017/TCP)
- 无密码或弱密码
- Hadoop (50070/TCP & 50075/TCP)
- 未授权访问
除了以上列出的可能出现的问题,暴露在公网上的服务若不是最新版,都可能存在已经公开的漏洞。
6.2 常用工具
1、Nmap
常见的扫描语句:
#扫描整个网段
nmap 192.168.1.0/24
#扫描指定的网络
nmap 192.168.1.10-200
#扫描 10,100,200-300 的网络
nmap 192.168.1.10,100,200-230
#扫描不同网段
nmap 192.168.1.0/24 10.10.10.0/24
#使用TCP 全连接的方式,扫描过程需要三次握手建立连接则说明端口开放,扫描速度慢
nmap -sT 192.168.1.1
#使用SYN 的数据包去检测,如果接收到ACK,则说明端口开放了nmap-sS 192.168.1.1
#NULL 扫描,发出的数据包不设置任何标识位
nmap -sN 192.168.1.1
注意∶上述扫描的端口默认都是 1-1000,-p 后跟指定端口 -p20,21,22,80,3306
-p- = -p1-65535
#探测服务版本
nmap -sV 192.168.1.1
#将扫描结果保存到result.txt 文件
nmap 192.168.1.1 > ./result.txt
#将扫描结果保存到result.xml 文件
nmap 192.168.1.1 -oX result.xml
#获取目标所有的详细结果,全面扫描nmap -A 192.168.1.1
#探测操作系统类型nmap -O 192.168.1.1
—script 使用脚本去探测漏洞
nmap —script smb-vuln-ms17-010 192.168.1.1 #永恒之蓝
nmap —script smb-vuln-ms08-067 192.168.1.1 #MS08-067
nmap -script ssl-heartbleed 192.168.1.1 #心脏滴血
#扫描端口并且标记可以爆破的服务
nmap 目 标 —script=ftp-brute,imap-brute,smtp-brute,pop3-brute,mongodb- brute,redis-brute,ms-sql-brute,rlogin-brute,rsync-brute,mysql-brute,pgsql-brute,oracle- sid-brute,oracle-brute,rtsp-url-brute,snmp-brute,svn-brute,telnet-brute,vnc-brute,xmpp- brute
#判断常见的漏洞并扫描端口nmap 目 标 —script=auth,vuln
#-sV 服务版本,-sP 发现扫描网络存活主机
nmap -sV -sP 192.168.1.0/24
#-sS 隐蔽扫描(半开syn),-sV 服务版本,-T 时间优化(0-5)等级,数字越大力度越强,-A 综合扫描,-p-全端口(1-65535)
nmap -sS -sV -T5 -A -p- 192.168.1.63
nmap -iL dns_result.txt —script=auth,vuln,ftp-brute,imap-brute,smtp-brute,pop3- brute,mongodb-brute,redis-brute,ms-sql-brute,rlogin-brute,rsync-brute,mysql- brute,pgsql-brute,oracle-sid-brute,oracle-brute,rtsp-url-brute,snmp-brute,svn- brute,telnet-brute,vnc-brute,xmpp-brute > scan.txt
#批量扫描端口和漏洞检测,根据对应开放的端口进行针对性漏洞挖掘
2、Advanced_Port_Scanner
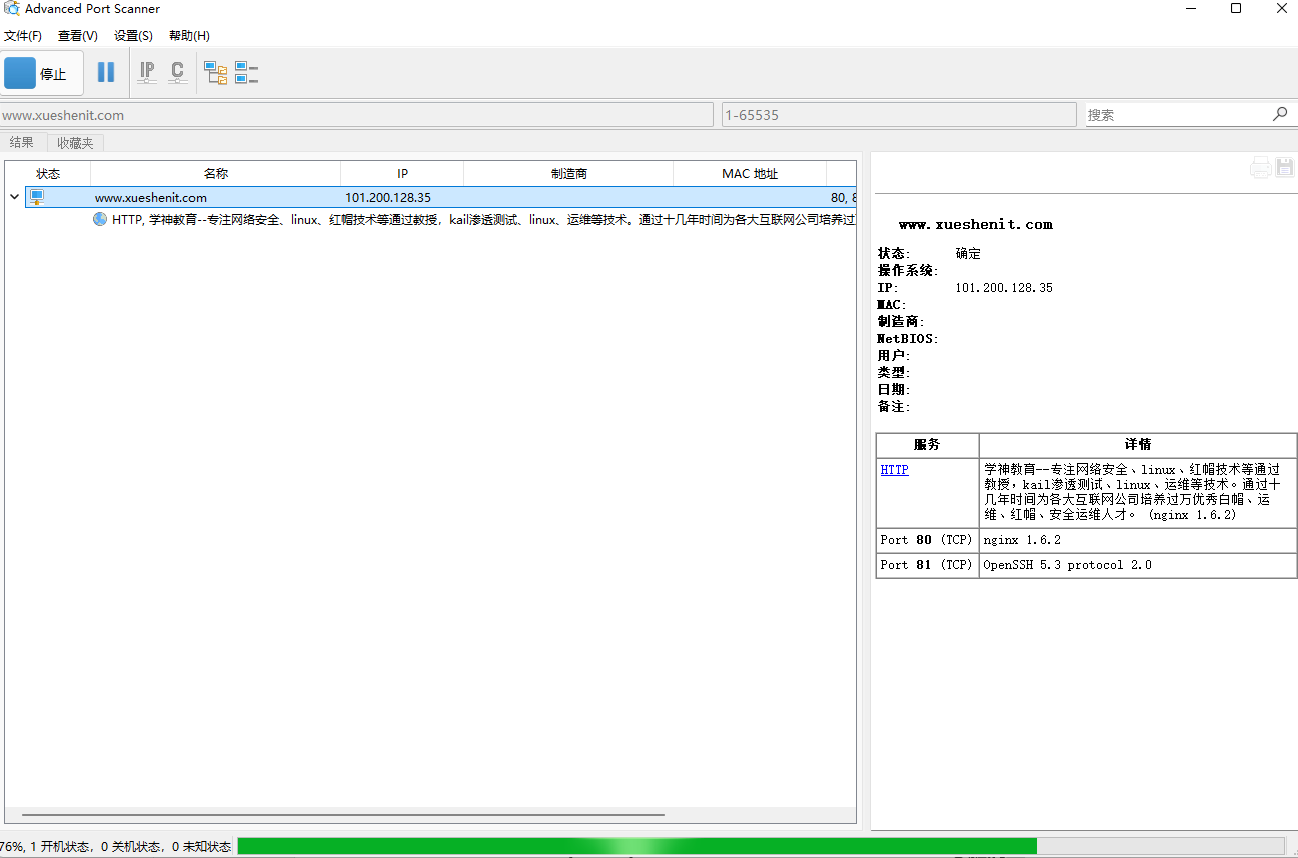
3、masscan
7、Google Hacking
Google Hacking 作为常用且方便的信息收集搜索引擎工具,它是利用谷歌搜索强大,可以搜出不想被看到的后台、泄露的信息、未授权访问,甚至还有一些网站配置密码和网站漏洞等。掌握了 Google Hacking 基本使用方法,或许下一秒就是惊喜。
7.1 Google Hacking 基础使用方法
site:找到与指定网站有联系的URL
inurl:将返回url 中含有关键词的网页
intext:寻找正文中含有关键字的网页
intitle:寻找标题中含有关键字的网页
filetype:指定访问的文件类型
7.2 Google Hacking 符号使用
(1)精确搜索:给关键词加上双引号实现精确匹配双引号内的字符;
(2)通配符:谷歌的通配符是星号”*”,必须在精确搜索符双引号内部使用。用通配符代替关键词或短语中无法确定的字词;
(3)点号匹配任意字符:点号 “.” 匹配的是匹配某个字符,不是字、短语等内容;
(4)基本搜索符号约束:加号 “+” 用于强制搜索,即必须包含加号后的内容。一般与精确搜索符一起应用。关键词前加 “-“ 减号,要求搜索结果中包含关键词,但不包含减号后的关键词,用关于搜索结果的筛选;
(5)数字范围:用两个点号 “.” 表示一个数字范围。一般应用于日期、货币、尺寸、重量、高度等范围的搜索,如︰手机 2000..3000 元,注意“3000”与“元”之间必须有空格;
(6)布尔逻辑:或符号 “|” 在多个关键字中,只要有一个关键字匹配上即可;与符号 “&” 所有的关键字都匹配上才可以。
7.3 Google Hacking 综合利用
查找后台地址:site:域名 inurl:login|admin/ manage| member|admin_login |login_admin|system |login |user |main |cms
查找文本内容:site:域名 intext:管理|后台|登陆|用户名|密码|验证码|系统|帐户 |admin|login|sys|managetem|password|username
查找可注入点:site:域名 inurl:aspx|jsp|php|asp
查找上传漏洞:site:域名 inurl:file|load|editor|Files
找eweb 编辑器:site:域名 inurl:ewebeditor|editor|uploadfile|eweb|edit
存在的数据库:site:域名 filetype:mdb|asp|#
查看脚本类型:site:域名 filetype:asp|aspx|phpljsp
例 1:intext:login japan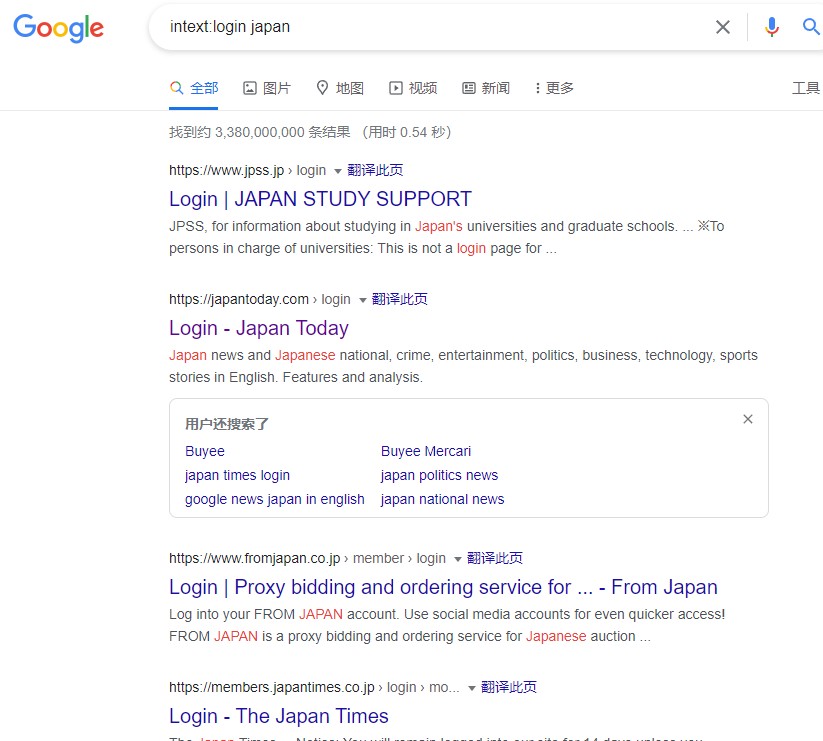
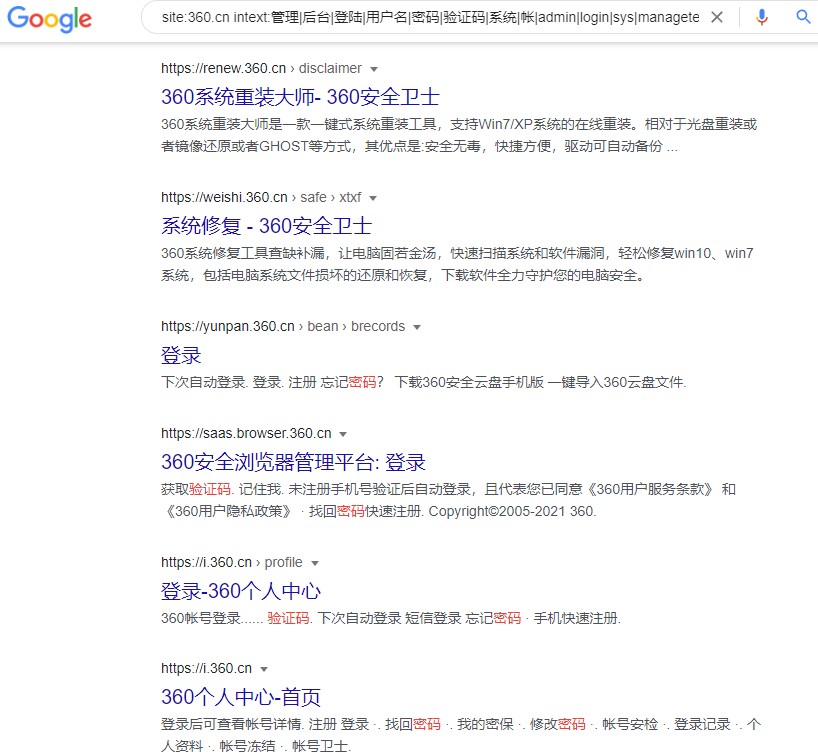
例 2:site:360.cn intext:管理|后台|登陆|用户名|密码|验证码|系统|帐
|admin|login|sys|managetem|password|username
8、指纹识别
8.1 什么是指纹识别
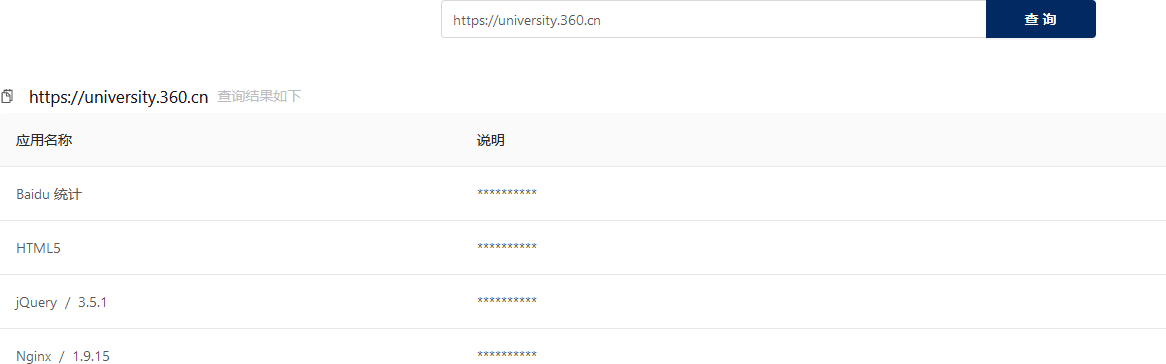 指纹识别是信息收集环节中一个比较重要的环节,通过一些开源的工具、平台或者手工检测目标系统是公开的CMS 程序还是二次开发至关重要,能准确的获取CMS 类型、Web 服务组件类型及版本信息 可以帮助红队评估人员快速有效的去验证已知漏洞。
指纹识别是信息收集环节中一个比较重要的环节,通过一些开源的工具、平台或者手工检测目标系统是公开的CMS 程序还是二次开发至关重要,能准确的获取CMS 类型、Web 服务组件类型及版本信息 可以帮助红队评估人员快速有效的去验证已知漏洞。
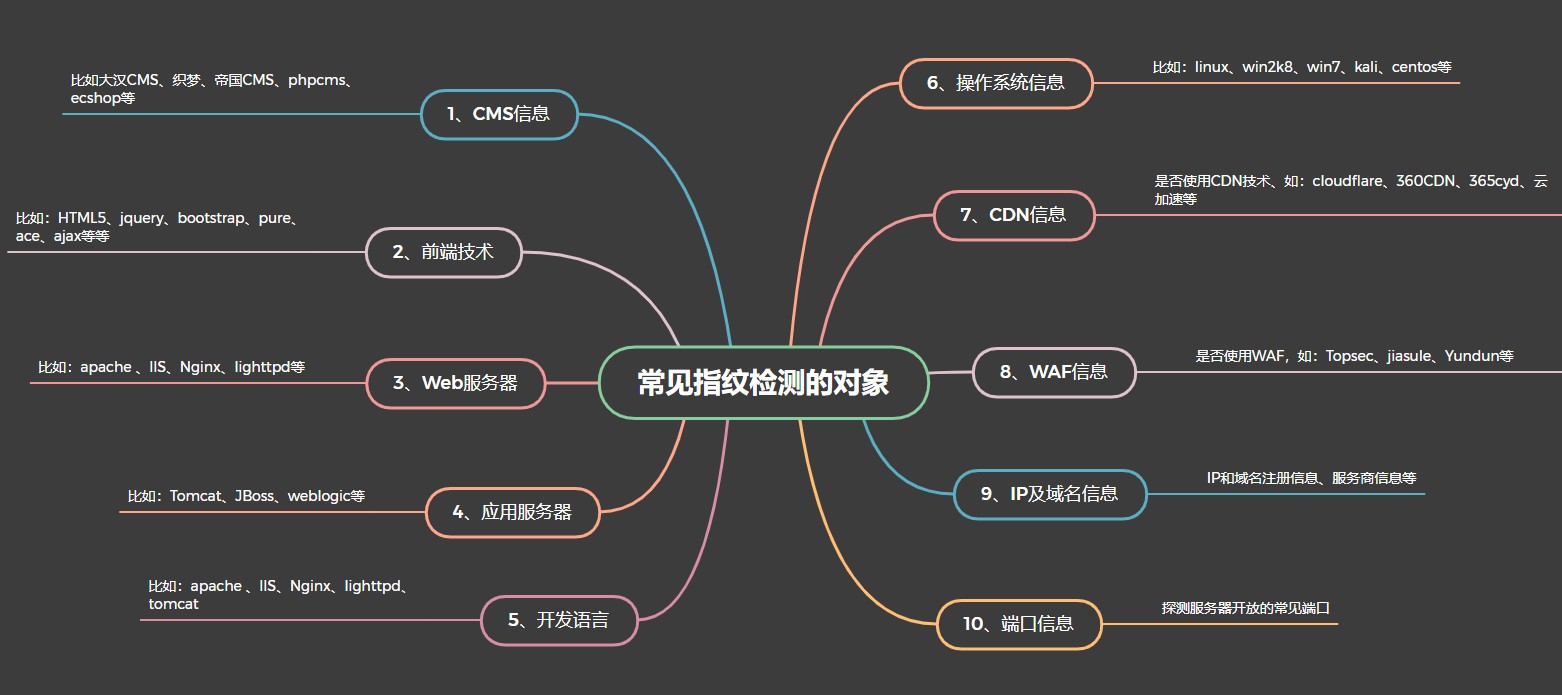
指纹识别常见的检测对象:
- CMS<内容管理系统>信息,常见CMS 有:dede 织梦、worepress、phpcms、thinkphp、ezcms、ecshop、帝国、大汉 CMS、discuz、魅力、海洋 cms、逐浪CMS Zoomla、drupal、EarCMS、思途CMS
- 前端技术:HTML5、jquery、bootstrap、pure、ace、ajax 等等
- 中间件和容器等:apache 、llS、Nginx、lighttpd、tomcat、weblogic、jboss、websphere 等等
- 开发语言:php、java、ruby、go、python、c#、Jsp、asp、aspx 等等
- 操作系统:Windows NT、Linux、类UNIX (MAC OS)
- CDN 信息:是否使用 CDN 技术、如:cloudflare、360CDN、365cyd、云加速等等
- 端口或者服务:有些软件或平台还会探测服务器开放的常见端口
- IP 或者域名信息:IP 和域名注册信息、服务商信息等
- WAF:检测是否有WAF,如:云盾、云锁、安全狗、IPS/IDS 等等
8.2 常见指纹识别方法
1、特定文件的 MD5
一些网站的特定图片文件、js 文件、CSS 等静态文件,如favicon.ico、css、logo.ico、js 等文件一般不会修改,通过爬虫对这些文件进行抓取并比对md5 值,如果和规则库中的md5 一致则说明是同一CMS。这种方式速度比较快,误报率相对低一些,但也不排除有些二次开发的CMS 会修改这些文件。
2、正常页面或错误网页中包含的关键字
先访问首页或特定页面如robots.txt 等,通过正则的方式去匹配某些关键字,如Powered by Discuz、dedecms 等。
或者可以构造错误页面,根据报错信息来判断使用的CMS 或者中间件信息,比较常见的如tomcat的报错页面。
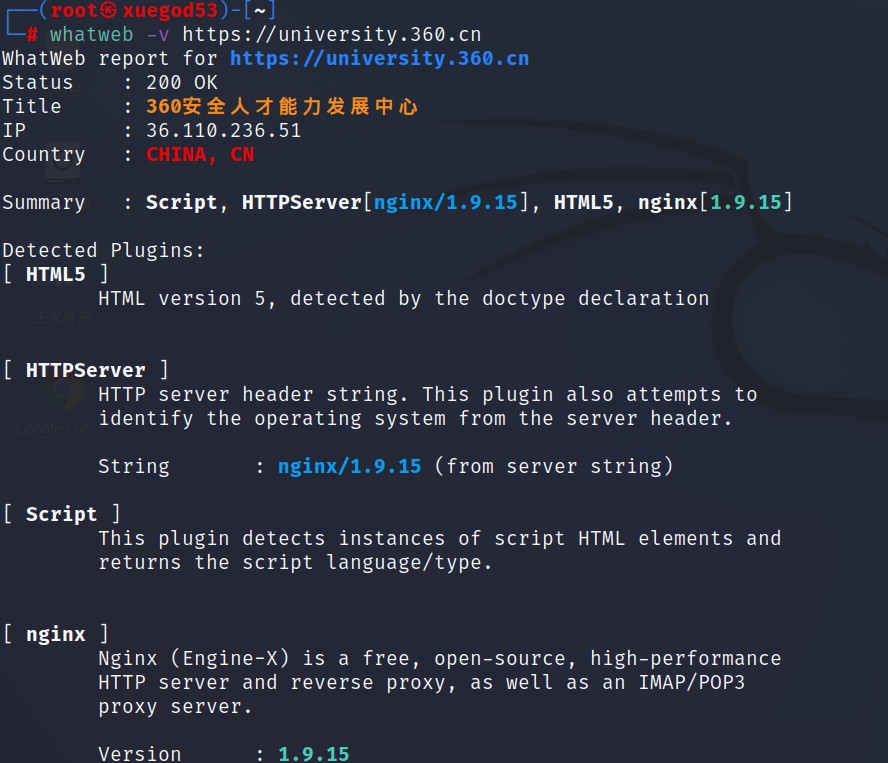
3、请求头信息的关键字匹配
根据网站response 返回头信息进行关键字匹配,whatweb 和Wappalyzer 就是通过banner 信息来快速识别指纹,之前fofa 的web 指纹库很多都是使用的这种方法,效率非常高,基本请求一次就可以,但搜集这些规则可能会耗时很长。而且这些banner 信息有些很容易被改掉。
根据response header 一般有以下几种识别方式:
- 查看http 响应报头的X-Powered-By 字段来识别;
- 根据Cookies 来进行判断,比如一些waf 会在返回头中包含一些信息,如 360wzws、Safedog、yunsuo 等;
- 根据header 中的Server 信息来判断,如DVRDVS-Webs、yunjiasu-nginx、Mod_Security、nginx-wallarm 等;
- 根据 WWW-Authenticate 进行判断,一些路由交换设备可能存在这个字段,如NETCORE、huawei、h3c 等设备。
4、部分URL 中包含的关键字,比如 wp-includes、dede 等URL 关键特征。
通过规则库去探测是否有相应目录,或者根据爬虫结果对链接url 进行分析,或者对robots.txt 文件中目录进行检测等等方式,通过url 地址来判别是否使用了某CMS,比如wordpress 默认存在 wp- includes 和 wp-admin 目录,织梦默认管理后台为dede 目录,solr 平台可能使用/solr 目录, weblogic 可能使用 wls-wsat 目录等。
5、开发语言的识别
web 开发语言一般常见的有 PHP、jsp、aspx、asp 等,常见的识别方式有:
- 通过爬虫获取动态链接进行直接判断是比较简便的方法。
asp 判别规则如下
- 通过X-Powered-By 进行识别
比较常见的有X-Powered-By: ASP.NET 或者X-Powered-By: PHP/7.1.8 3)
- 通过Set-Cookie 进行识别
这种方法比较常见也很快捷,比如Set-Cookie 中包含 PHPSSIONID 说明是php、包含JSESSIONID 说明是java、包含ASP.NET_Sessionld 说明是 aspx 等。
通过第三方在线平台进行指纹识别:
- http://www.yunsee.cn/
- http://finger.tidesec.net/
- http://whatweb.bugscaner.com/look/
- https://fp.shuziguanxing.com/
- http://www.whatweb.net/
- https://whatweb.net/
通过利用指纹识别工具进行指纹识别
- WhatWeb: https://github.com/urbanadventurer/WhatWeb
- Wapplyzer: https://github.com/AliasIO/Wappalyzer
- Whatruns: https://www.whatruns.com/downloads/
- Plecost: https://github.com/iniqua/plecost
- WTF_Scan: https://github.com/dyboy2017/WTF_Scan
- Webfinger: https://github.com/se55i0n/Webfinger
- FingerPrint: https://github.com/tanjiti/FingerPrint
- 御剑 web 指纹识别程序:https://www.webshell.cc/4697.html
- w11scan 分布式 WEB 指纹识别平台: https://github.com/w-digital-scanner/w11scan
- Dayu 指纹识别工具: https://github.com/Ms0x0/Dayu
9、目录、敏感文件探测
9.1 概述
扫描站点的目录,寻找敏感文件,如目录名、探针文件、后台、robots.txt、备份文件等。目录:站点结构、权限控制不严格;
探针文件:服务器配置信息,1.php、phpinfo.php、readme.txt、config.txt 等;
后台:管理整个网站的入口,admin.php、index.php/s=admin、administrator.php 等; robots.txt:一般存放在站点根目录,如果管理员对 robots.txt 配置不合理就会造成信息泄露; 备份文件:数据库备份、网站备份文件等,如 .bak 文件、.zip 文件、.rar 文件等;
敏感JS 文件:网页中可能嵌套的JS 存在敏感信息,如后台的入口、登录评估等;
API:网页中可能存在嵌套的应用程序接口,在信息收集中可以考虑寻找接口; 网页链接:收集页面中包含所有的链接。
9.2 常见利用工具
- https://github.com/maurosoria/dirsearch
- https://github.com/H4ckForJob/dirmap
- https://github.com/lijiejie/BBScan
- https://github.com/7kbstorm/7kbscan-WebPathBrute
- https://sourceforge.net/projects/dirbuster/
- https://github.com/OJ/gobuster
- https://github.com/TuuuNya/webdirscan
- https://github.com/deibit/cansina
- https://github.com/aducode/wwwscan
- 御剑后台扫描工具、AWVS、北极熊扫描器等
1、御剑后台扫描工具
御剑后台扫描珍藏版是TOOLS 大牛的作品,方便查找用户后台登陆地址,同时也为程序开发人员增加了难度,尽量独特的后台目录结构。附带很强大的字典,字典我们也是可以自己修改的,继续增加规则。
特点:
(1)扫描线程自定义:用户可根据自身电脑的配置来设置调节扫描线程
(2)集合DIR 扫描ASP ASPX PHP JSP MDB 数据库包含所有网站脚本路径扫描
(3) 默认探测 200
安装:
御剑不用安装,直接下载下来解压,双击”御剑后台扫描工具.exe”即可正常使用在域名输入框中输入域名,选择扫描参数即可,注意网站后端脚本类型。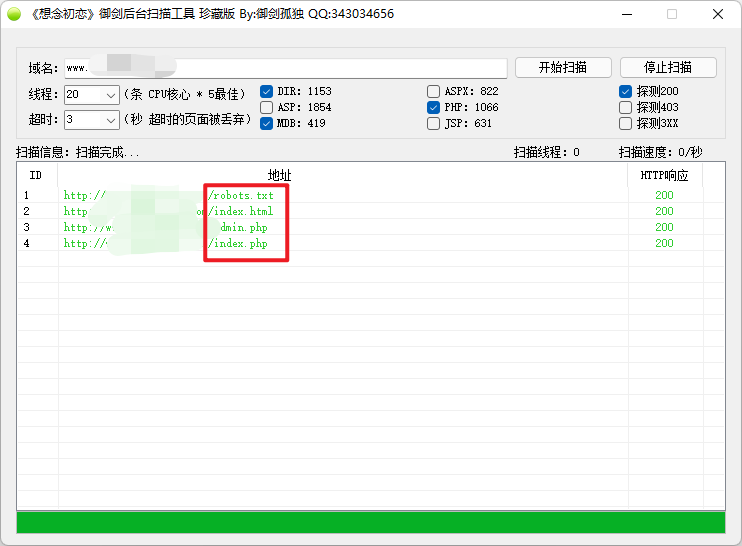
2、Dirbuster
DirBuster 是一个多线程Java 应用程序,旨在强制Web/应用程序服务器上的目录和文件名。它可以选择执行纯暴力,在查询隐藏文件和目录方面非常好用。
安装使用:
(1)安装java,配置JDK 环境变量
(2) 下载安装:https://sourceforge.net/projects/dirbuster/ Kali 自带DirBuster
┌──(root㉿kali)-[~]
└─# dirbuster
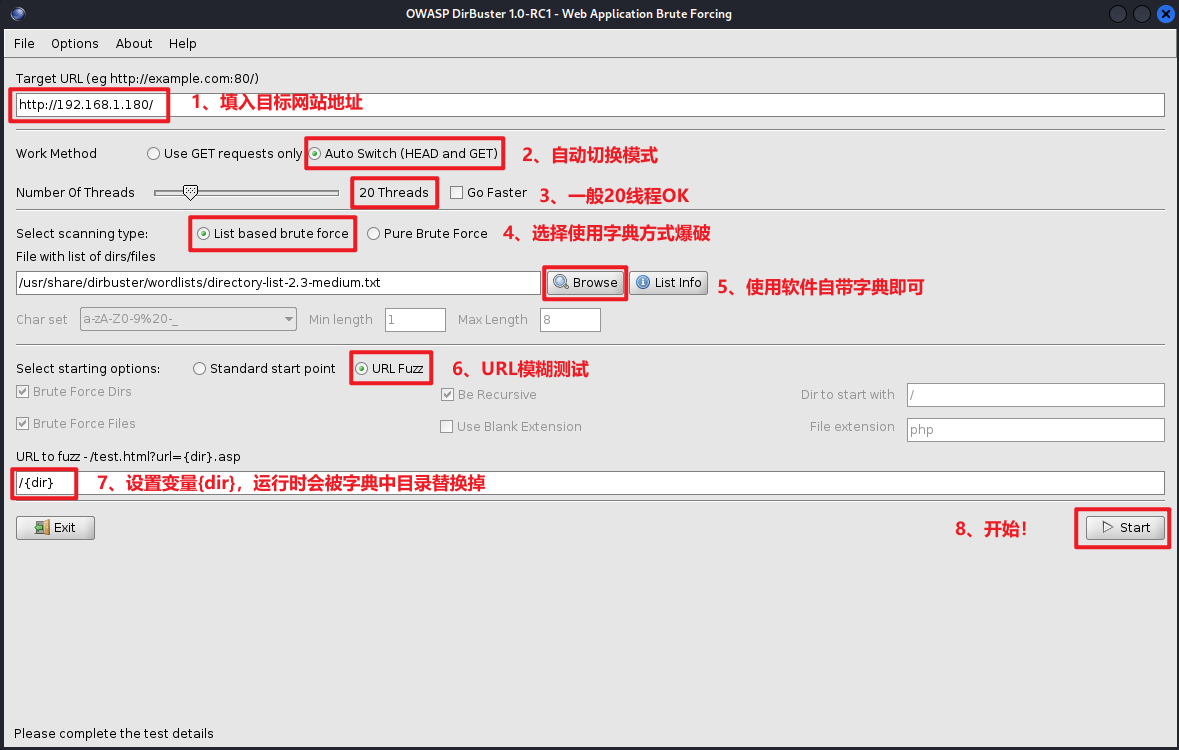
面板参数:
- Target URL:输入要探测网站的地址;
需要注意的是这个地址要加上协议,看网站是http 还是https。
- Work Method:选择工作方式。
一个是get 请求,一个是自动选择。一般选auto switch 的自动选择,它会自行判断是使用head方式或get 方式。
- Number of Thread:是选择扫描线程数,一般为 20,电脑配置好的可根据情况选择。
- select scanning type:选择扫描类型。
list based brute force 是使用字典扫描的意思,勾选上。随后browse 选择字典文件,可用自己的,也可用dirbuster 自己的。
pure brute force 是纯暴力破解的意思。
- select starting options:选项一个是 standard start point(固定标准的名字去搜),一个是URL Fuzz(相当于按关键字模糊搜索),选择URL Fuzz,随后在URL to fuzz 框中输入 /{dir} 即可。
扫描结果说明:
200 OK:文件存在并能够读取。404 File not found:文件不存在。
301 Moved permanently:这是到给定URL 的重定向。
401 Unauthorized:需要权限来访问这个文件。
403 Forbidden:请求有效但是服务器拒绝响应。
3、Dirsearch
基于python 的命令行工具,用于暴力扫描页面结构,包括网站中的目录、备份文件、编辑器、后台等敏感目录。
特点:
- 多线程,使其比任何其他站点扫描仪工具都快;
- 执行递归暴力破解;
- 具有HTTP 代理支持;
- 有效地检测到无效网页;
- 具有用户代理随机化和批处理功能;
- 支持请求延迟;
安装:
下载地址:https://github.com/maurosoria/dirsearch
运行环境:必须安装python3
常见命令和参数:
python dirsearch.py -h 查看帮助菜单
-u 指定需要扫描URL
-e 指定需要扫描的文件名
-x 403,302,301 排除状态码
-w 指定自定义的字典文件路径
-r 递归扫描,非常耗时
-R 递归深度级别
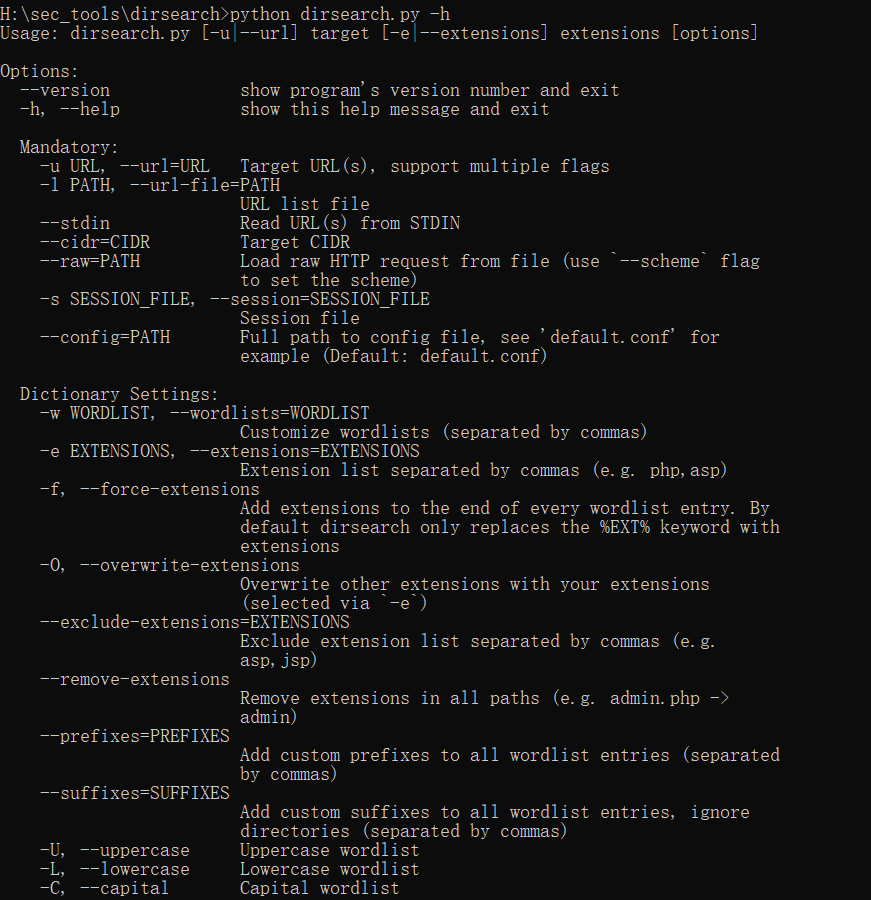
H:\sec_tools\dirsearch>python dirsearch.py -u http://192.168.1.180 -e php -x 403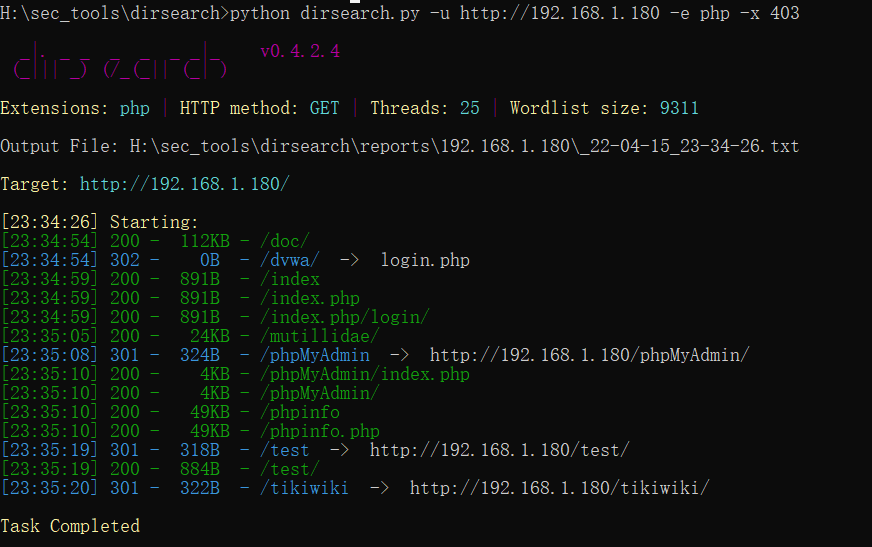
4、LinkFinder
LinkFinder 是一个 Python 脚本,旨在发现lavaScript 文件中的端点及其参数。这样渗透测试人员和Bug 猎手就可以在他们正在测试的网站上收集新的、隐藏的端点。导致新的测试环境,可能包含新的漏洞。
安装:
git clone https://github.com/GerbenJavado/LinkFinder.git
cd LinkFinder
python setup.py install (pip3 install -r requirements.txt)
python linkfinder.py -h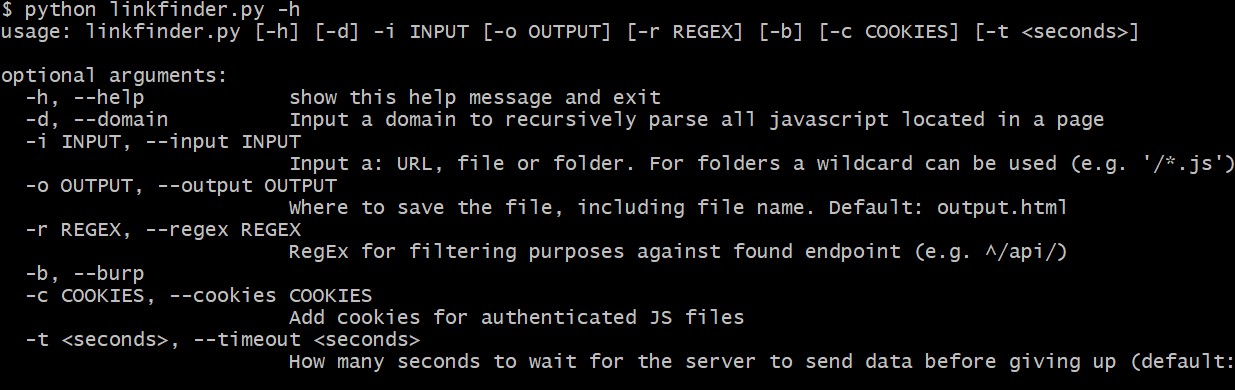
-i —input 输入一个:URL、文件或文件夹。对于文件夹,可以使用通配符(例如’/*.js’)。
-o —output OUTPUT “cli” 打印到 STDOUT,否则保存 HTML 文件默认:
output.html
-r REGEX,—regex REGEX 用于针对找到的端点进行过滤(例如 ^/api/)
-d —domain 在分析整个域时切换使用。枚举所有找到的 JS 文件。
-b —burp 在输入包含多个 JS 文件的 Burp ‘Save selected’ 文件时切换使用
-c COOKIES,—cookies COOKIES 将 cookie 添加到请求中
-h —help 显示帮助信息并退出
H:\sec_tools\LinkFinder>python linkfinder.py -i http://192.168.1.180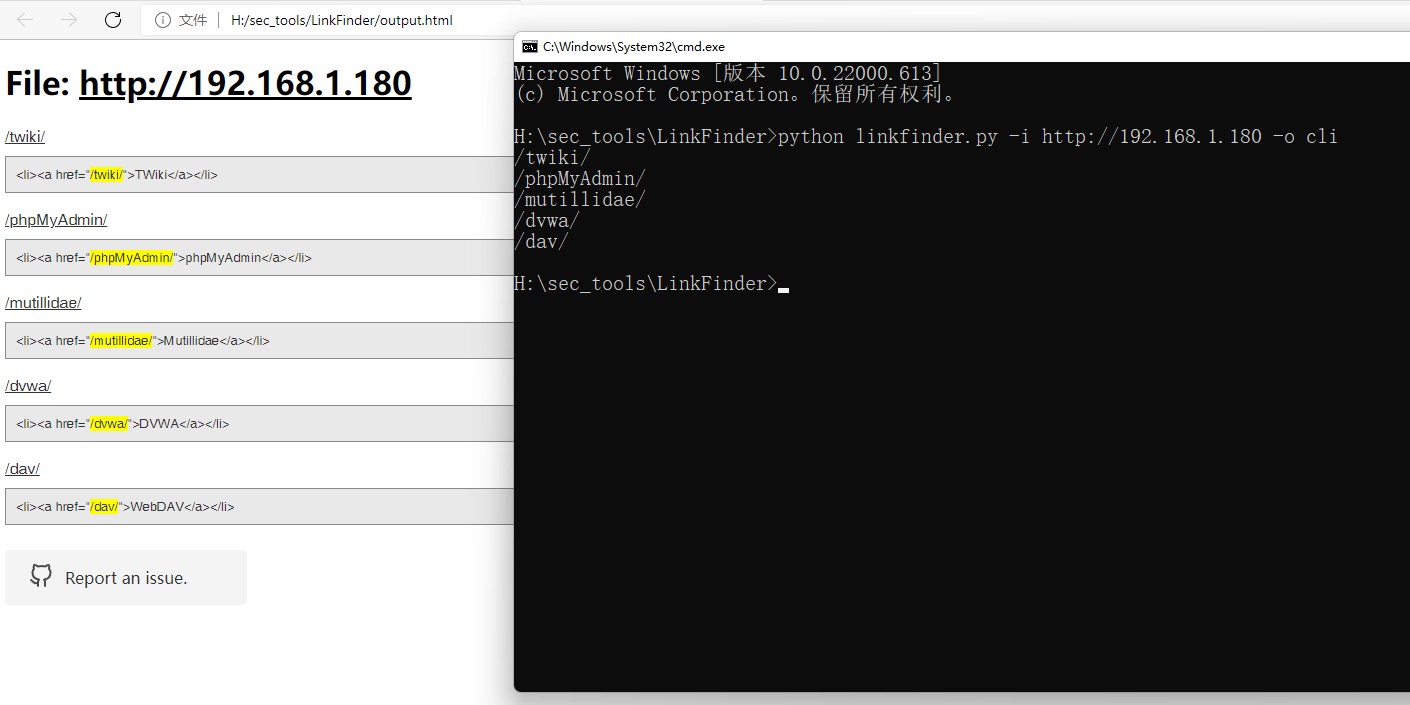
5、Link Grabber
Link Grabber 是一款能够批量提取、筛选、复制网页里各种链接的Chrome 扩展。
安装:
使用Chrome 浏览器访问:
https://chrome.google.com/webstore/category/extensions?hl=zh-CN
搜索”LinkGrabber”,安装即可。
访问待测试页面,点击浏览器中 “Link Grabber”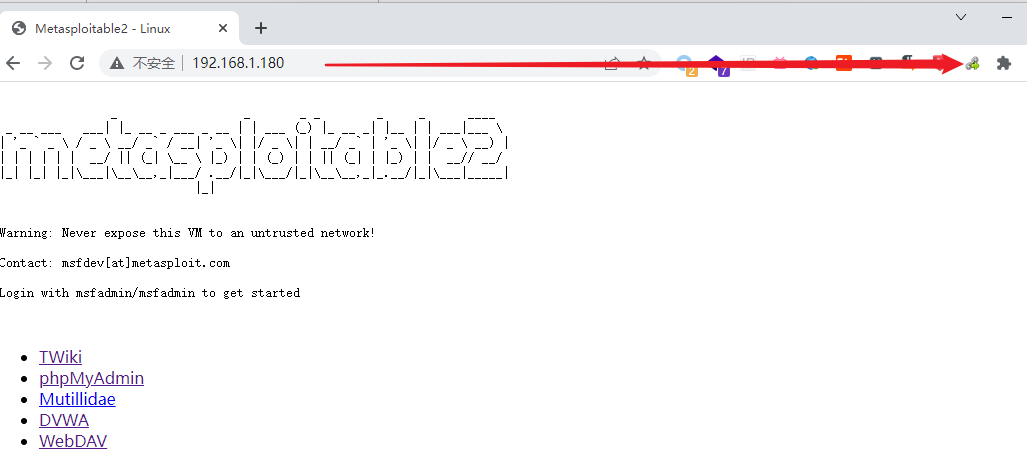
10、WAF 探测
WAF 也即 WEB 应用防火墙,是通过执行一系列针对HTTP/HTTPS 的安全策略来专门为Web 应用提供保护的一款产品。在必要的情况下还是可以对WAF 进行探测,了解WAF 的种类和版本,并尝试使用一些手段绕过WAF 规则。
常用的两种方式:
网站安全狗
UPUPW 安全防护
网防G01
宝塔防火墙
腾讯云
华为云
长亭SafeLine
玄武盾
10.2 WAF 探测
1、Nmap 探测WAF
nmap -p80,443 —script=http-waf-detect target_ip
nmap -p80,443 —script=http-waf-fingerprint target_ip
2、wafw00f 探测WAF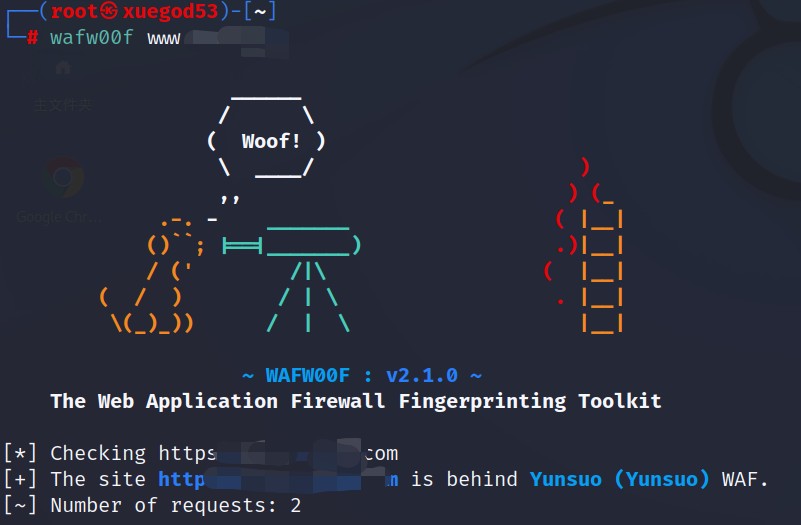
11、其他信息收集
11.1 敏感信息
针对某些安全做得很好的目标,直接通过技术层面是无法完成渗透测试的。在这种情况下,可以利用搜索引擎目标暴露在互联网上的关联信息。
例如:数据库文件、后台登录页面、服务配置信息,甚至是通过 Git 找到站点泄露源代码,以及Redis 等未授权访问、Robots.txt 等敏感信息,从而达到红队评估目的。
在某些情况下,收集到的信息会对后期进行测试起到帮助重要。如果通过收集敏感信息直接获取了目标系统的数据库访问权限,那么渗透测试任务就结束了一大半。因此在进行技术层面情况下的测试之前, 应该先进行更多的信息收集,尤其是针对敏感信息的。
11.2 Github 信息泄露
Github 是一个分布式的版本控制系统,拥有大量的开发者用户。随着越来越多的应用程序转移到云端,Github 已经成为了管理软件开发以及发现已有代码的首选方法。当今大数据时代,大规模数据泄露事件时有发生,但有些人不知道很多敏感信息的泄露其实是我们无意之间造成的。一个很小的疏漏,可能会造成一系列的连锁反应。Github 上敏感信息的泄露,就是一个典型的例子,存在着一些安全隐患。
常 用 工 具 :
https://github.com/FeeiCN/gsil
https://github.com/madneal/gshark
1、gsil
介绍:此工具主要用于 GitHub 敏感信息泄露的监控,可实现邮件实时告警,缺点不是可视化。
所需环境:
Windows10
Python3.9
gsil 项目:https://github.com/FeeiCN/gsil
开启 POP3/SMTP 服务的邮箱
一个github 账号token,获取地址:https://github.com/settings/tokens
Windows 使用 git 可以安装资料中的 Git-2.31.1-64-bit.exe
安装完 git 后,想要把 gsil 安装到哪个目录,就在此目录中单击鼠标右键。
打开git bash
项目安装:
检查 Python 环境
$ python -V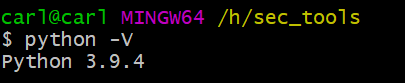
建议在安装之前把pip 升级到最新版,不然有可能报错,命令如下:
$ python -m pip install —upgrade pip
我这里已经是最新版。
安装gsil
$ git clone https://github.com/FeeiCN/gsil.git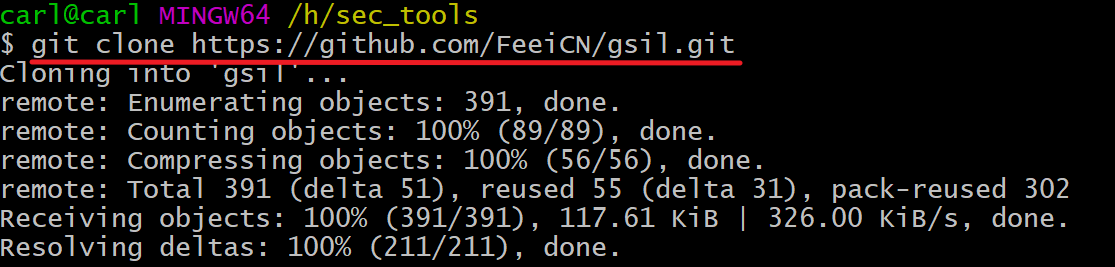
或者使用资料中下载好的gsil.zip,直接解压就可以。
$ cd gsil
$ pip3 install -r requirements.txt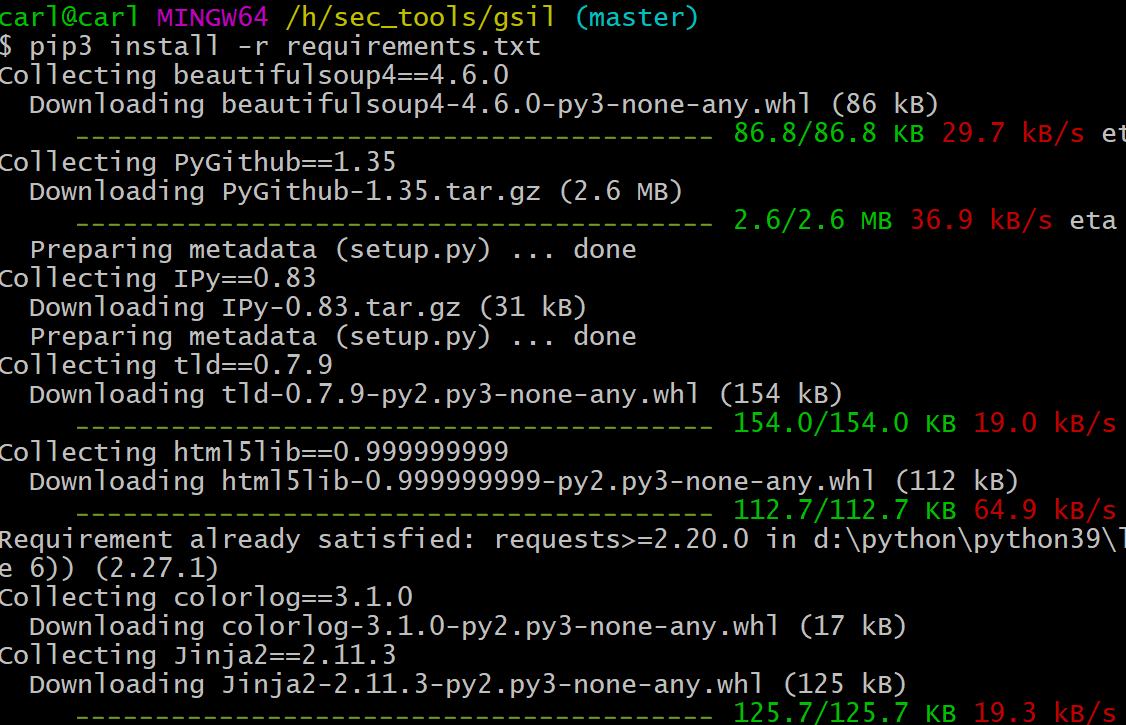
安装完了,进入gsil 目录找到config.gsil.cfg.example 文件,将其复制一份并改名为:config.gsil.cfg
打开此文件,内容如下:
[mail]
host : smtp.exmail.qq.com //这个最后要改成smtp.qq.com
port : 25 //这个端口smtp 服务一般是 465
mails : your_mail //这是你的邮箱地址Ps:多个邮箱用,隔开
from : GSIL
password : your_password //这是生成的授权码
to : feei@feei.cn //这是接受邮件的邮箱地址
cc : feei@feei.cn //这是抄送邮件的邮箱地址
[github]
clone : false //扫描到的漏洞仓库是否立刻Clone 到本地
tokens : your_github_token //这是你github 的token
邮箱服务配置:
这里以 QQ 邮箱为例,找到【设置】点击【账户】

下拉找到POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV 服务一栏,点击开启
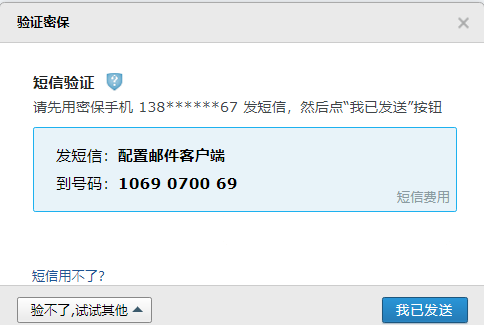
按照提示发送指定短信内容到指定号码后,点击 我已发送。验证成功就可以拿到授权码。
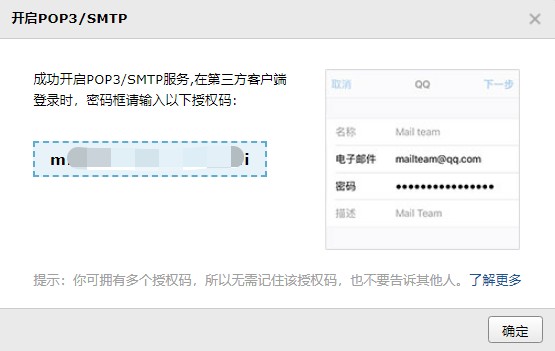
绑定 QQ 安全中心的用户需要输入app 中的令牌。
github 获取token:
进入https://github.com/settings/tokens** **页面点击生成新令牌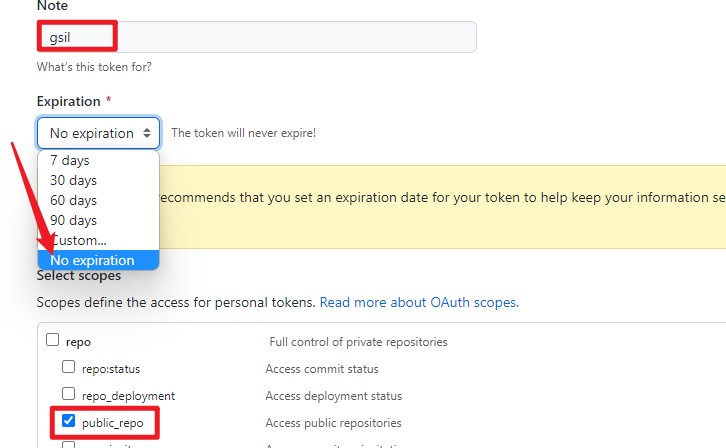
向下拉,点击生成 Token
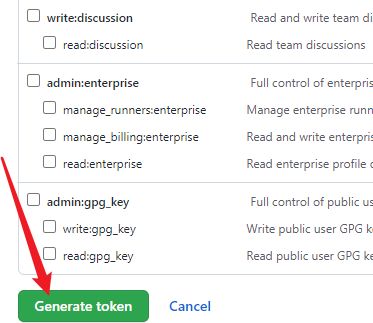
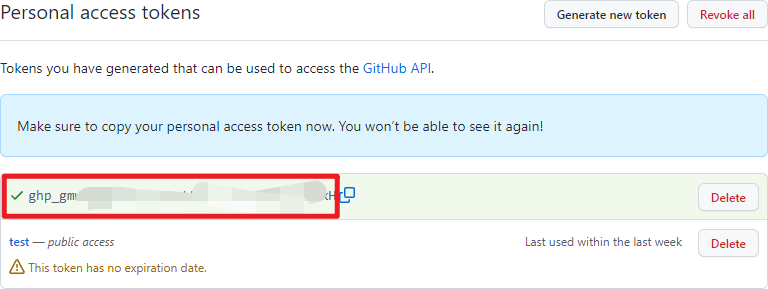
最后将配置文件改成这样就可以了。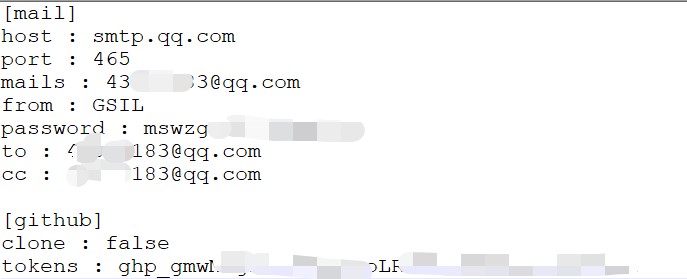
配置搜索规则:
找到 rules.gsil.yaml.example,将文件名修改为:rules.gsil.yaml
修改你想搜索的内容,解释如下:
{
# 一级分类,一般使用公司名,用作开启扫描的第一个参数(python gsil.py test) “test”: {
# 二级分类,一般使用产品线
“mogujie”: {
# 公司内部域名
“\”mogujie.org\””: {
# mode/ext 默认可不填
“mode”: “normal-match”,
“ext”: “php,java,python,go,js,properties”
},
# 公司代码特征
“copyright meili inc”: {},
# 内部主机域名
“yewu1.db.mogujie.host”: {},
# 外部邮箱
“mail.mogujie.com”: {}
},
“meilishuo”: {
“meilishuo.org”: {},
“meilishuo.io”: {}
}
}
}
都配置好以后你可以先检查一下token 的有效性,这样部署就完成了。
$ python gsil.py —verify-tokens
排错:
如出现如下错误提示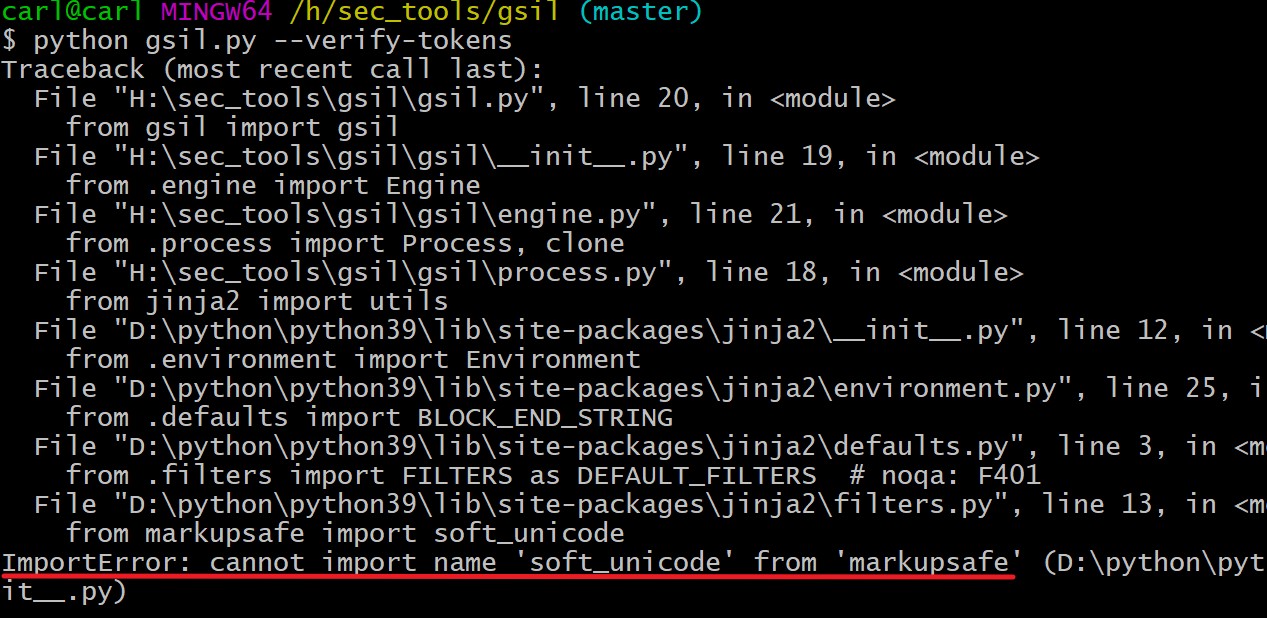
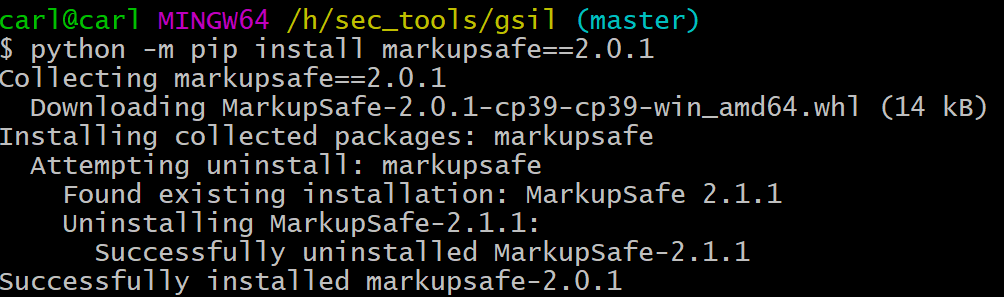
解决方案:
$ python -m pip install markupsafe==2.0.1
再次运行: $ python gsil.py —verify-tokens
$ python gsil.py —verify-tokens
Tokens 验证有效,可以进行敏感信息收集了。
说明:如果遇到其他报错信息,请自行百度解决。
$ python gsil.py test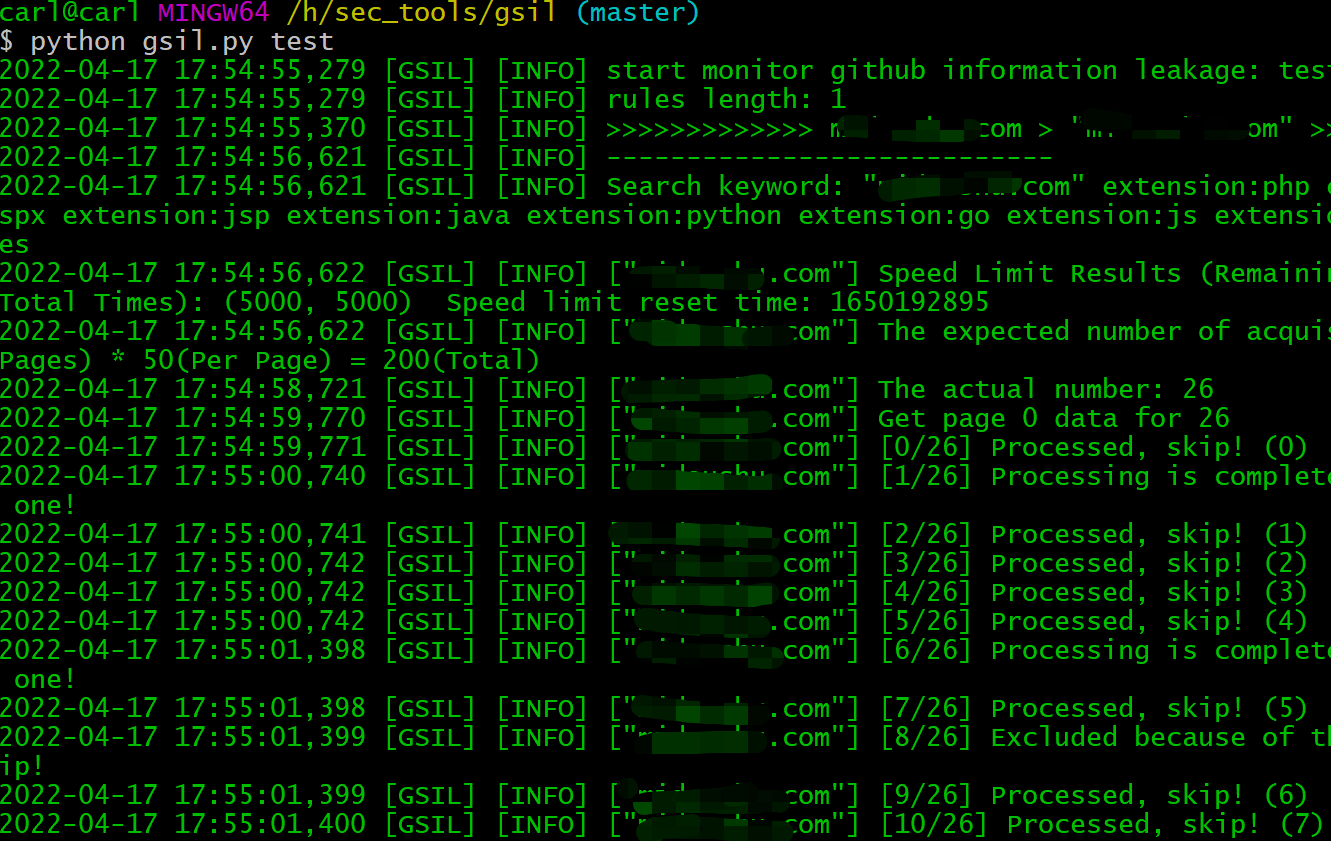
 执行结束后,到邮箱查看结果
执行结束后,到邮箱查看结果
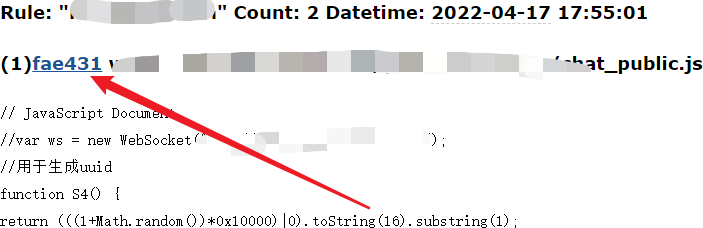
点击 fae431 就可以直接定位到文件位置
2、gshark
介绍:这是个可视化的监测工具,它不仅可以监控github,还可以监控gitlab。所需环境:
go
64 位gcc
Kali
安装golang
┌──(root㉿kali)-[~]
└─# apt update
└─# apt install golang -y
Kali 一般自带gcc,没有的话使用下面命令安装一下。
└─# apt install gcc -y
gshark 安装
└─# git clone https://github.com/madneal/gshark
或者将资料中的gshark.zip 上传到Kali 解压。
设置 go 国内源
└─# go env -w GOPROXY=https://goproxy.cn
启用 go module
└─# go env -w GO111MODULE=on
启动Kali MySQL 服务,并设置密码(如果之前没有设置过)
└─# systemctl start mariadb
└─# mysqladmin -uroot password “123456”
设置MySQL 服务开机自启动
└─# systemctl enable mariadb
服务器端安装
切换到gshark/server 目录
└─# cd gshark/server
┌──(root㉿kali)-[~/gshark/server]
└─# ls
开始构建
└─# go mod tidy
└─# mv config-temp.yaml config.yaml
└─# go build
开启后台web 服务
└─# ./gshark web &
网页端安装
┌──(root㉿kali)-[~/gshark/server]
└─# cd ../web
└─# npm install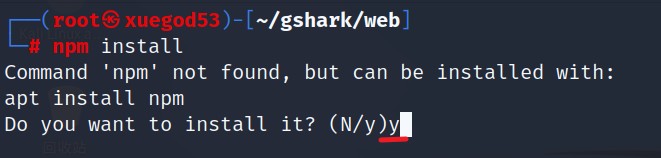
等待安装完,再次运行
└─# npm install
如报错如下: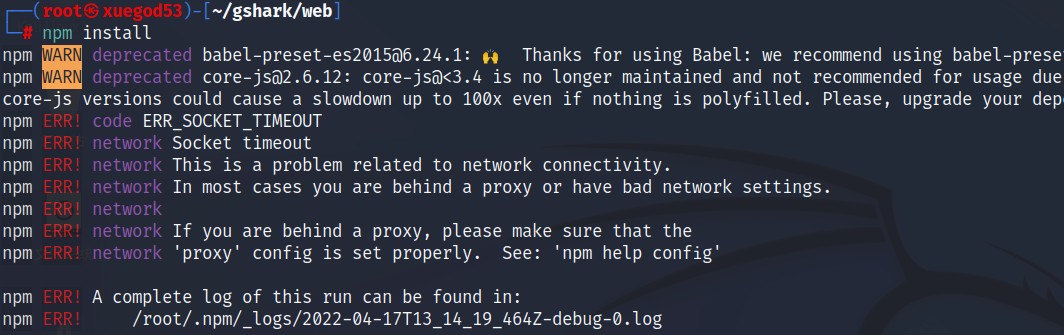
再次运行:
└─# npm install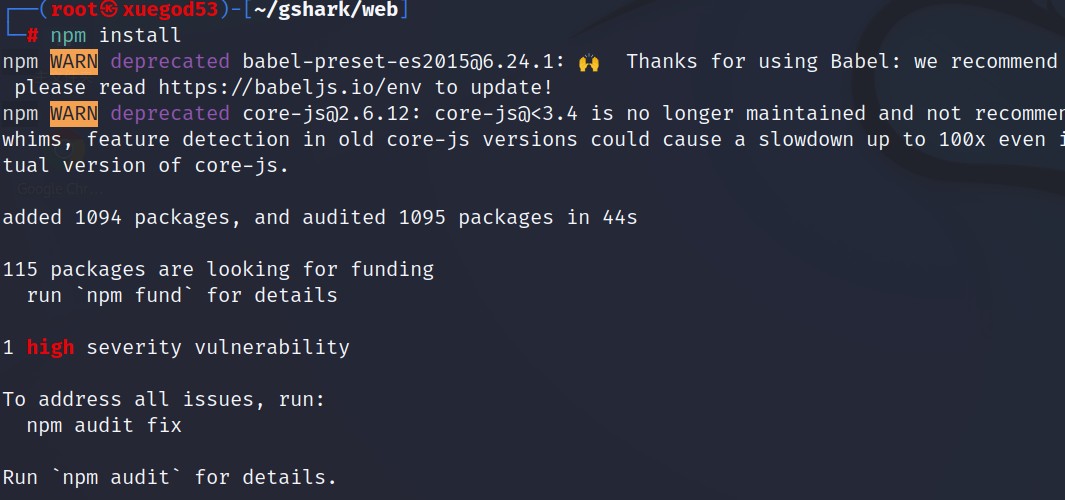
└─# npm audit fix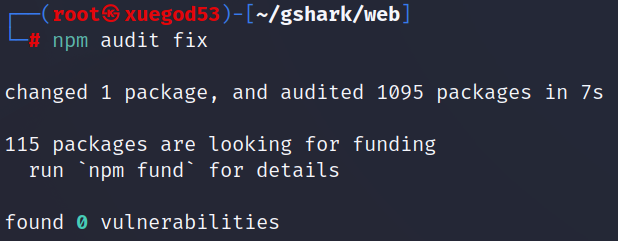
└─# npm run build
└─# npm run serve
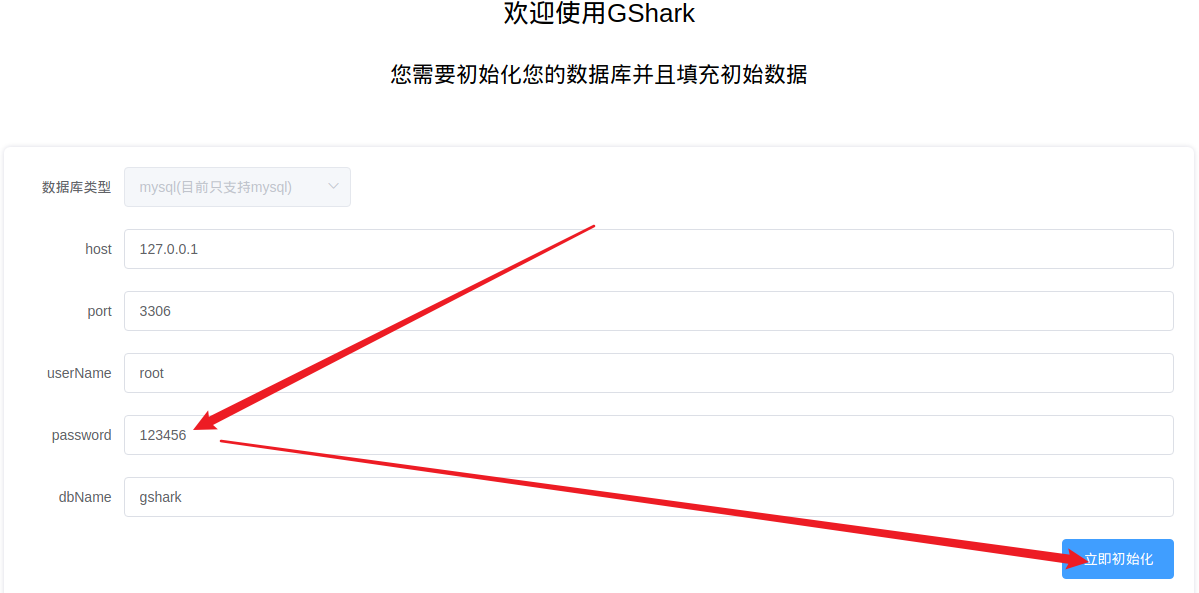
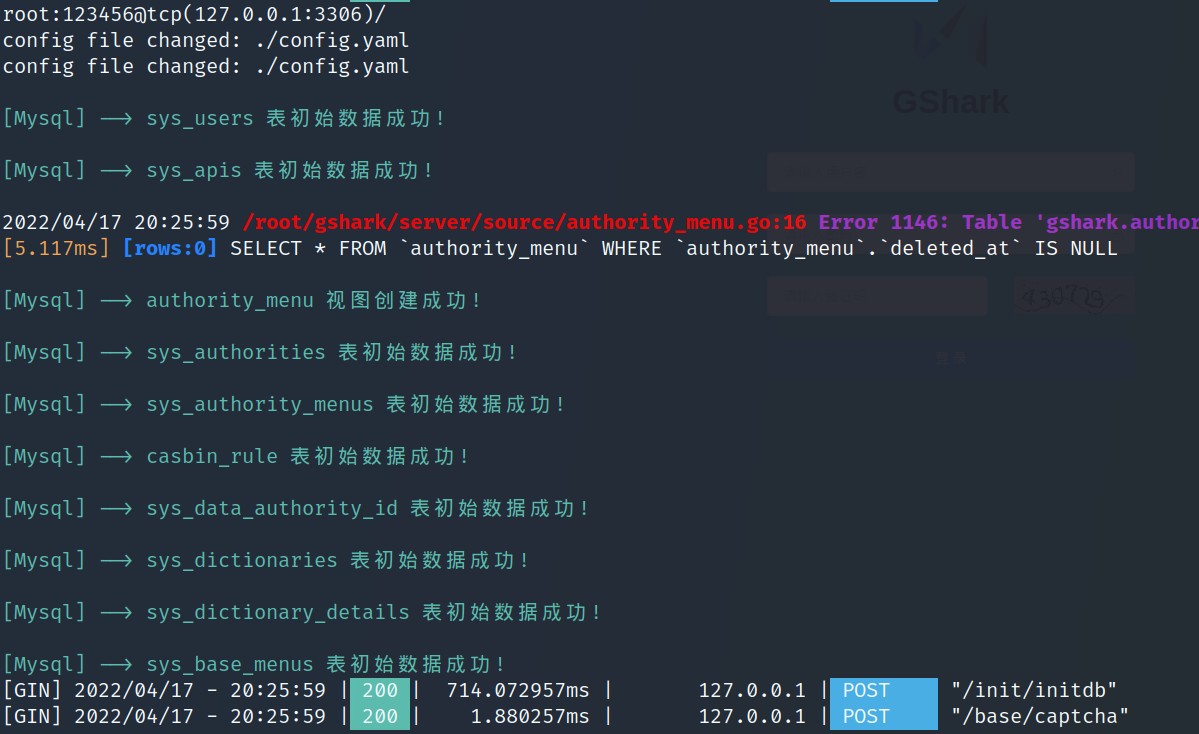
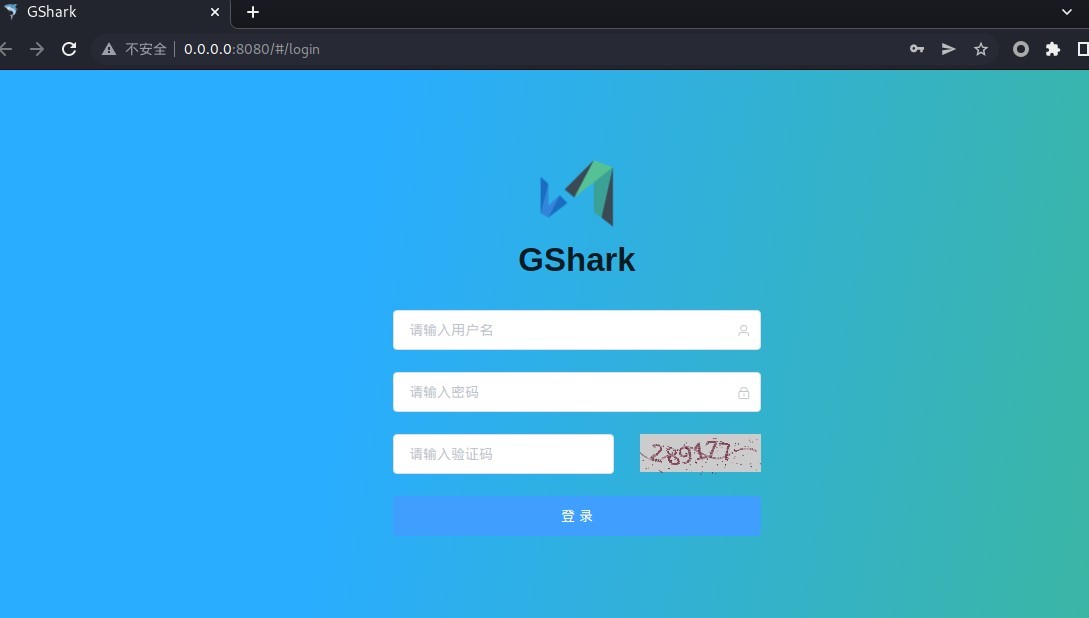
使用默认的账号和密码:gshark/gshark 登录。
添加github 的Token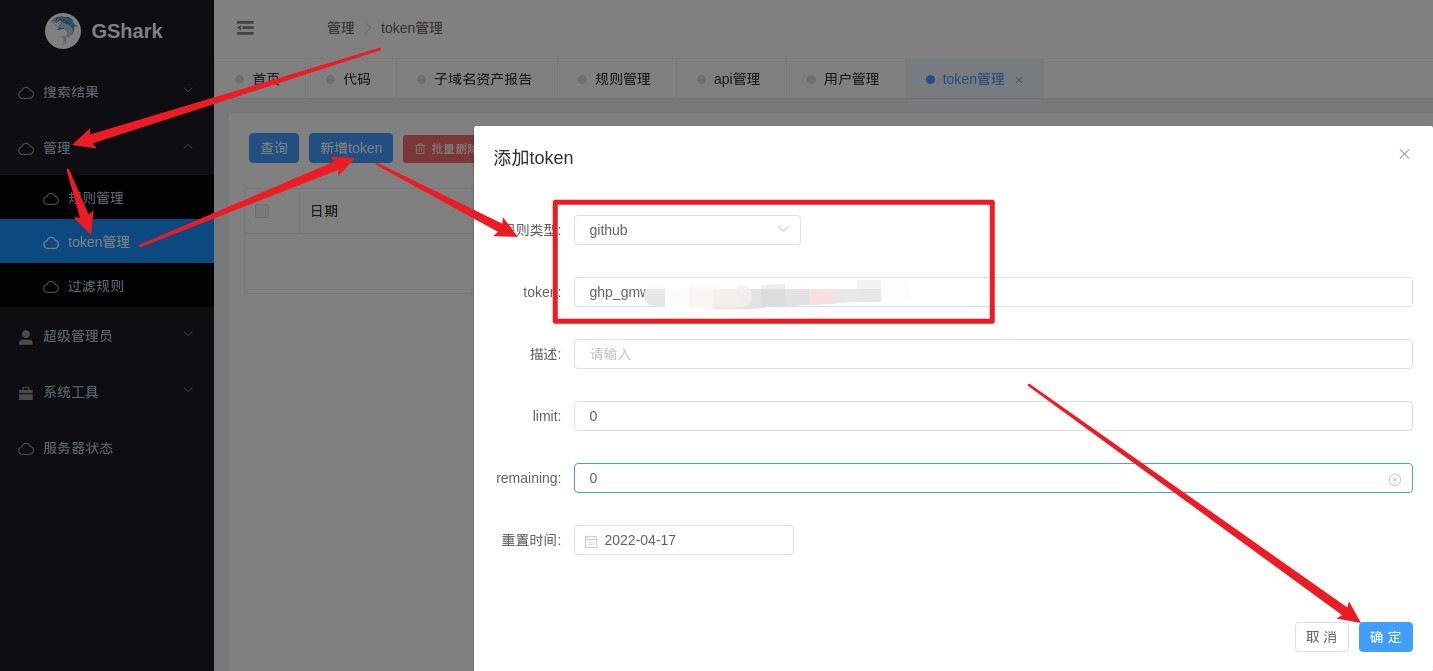
设置规则,想扫那个域名或者关键字填上就行。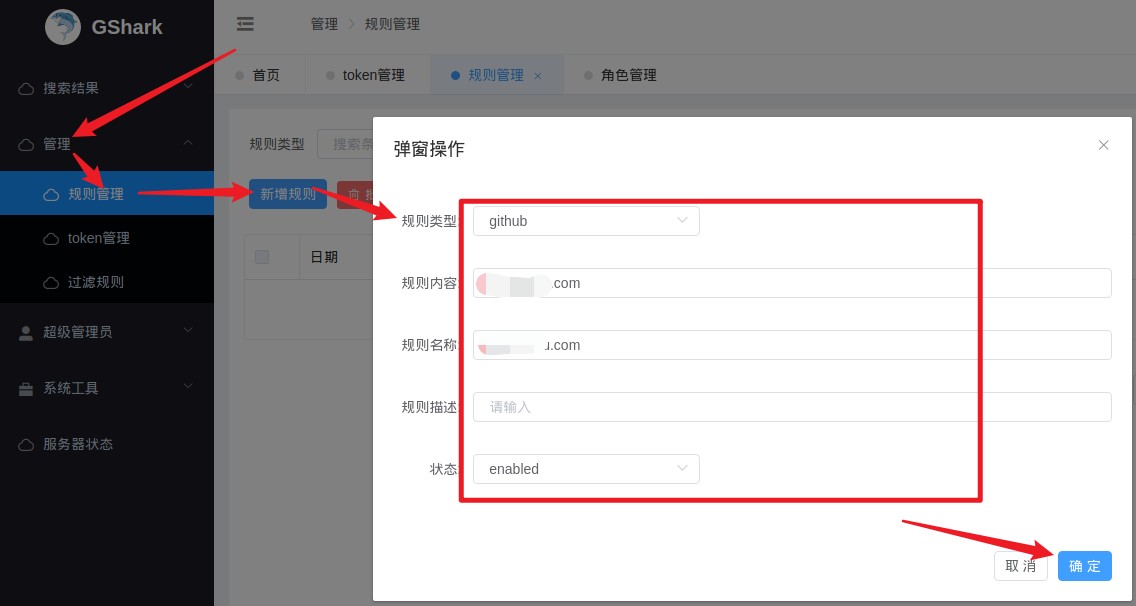
设置过滤规则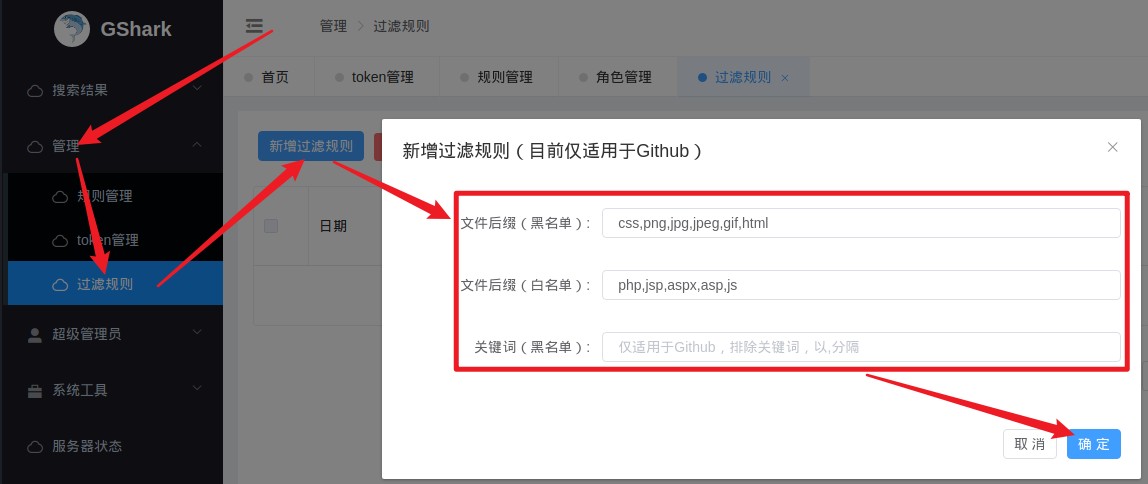
回到终端输入下面命令开始监测
过一段时间源代码扫描报告中就会有一堆结果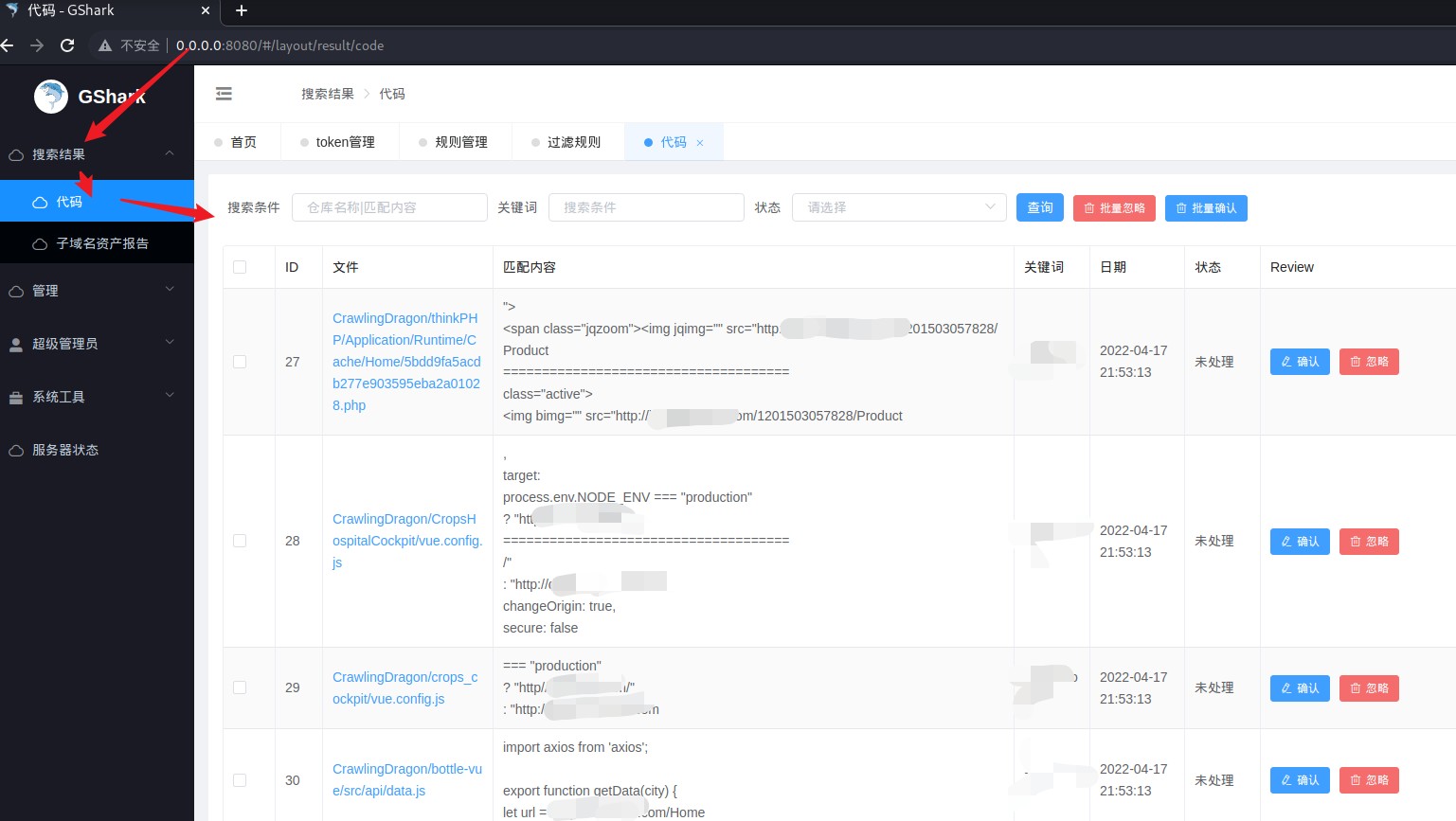
直接点击文件列对应的链接会跳到那个文件。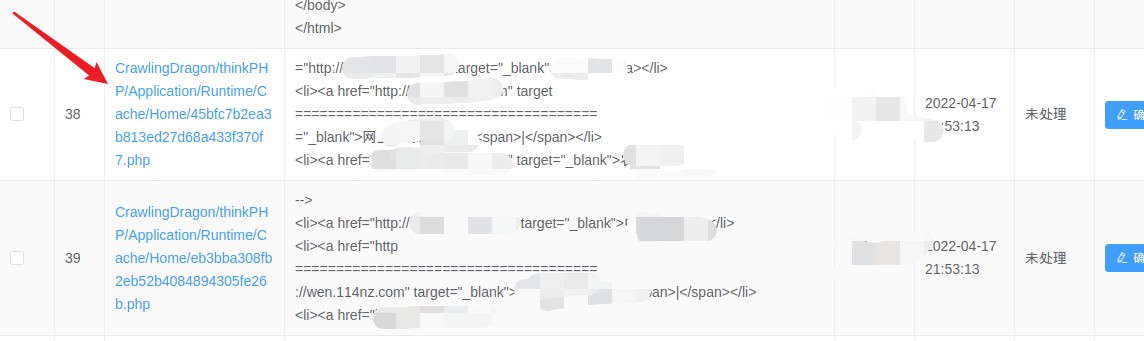
11.3 源码信息收集
- 利用JS 文件信息收集,在JS 文件中搜索关键字API,Swagger UI 等等,尝试寻找API 接口地址。
- 利用 APK、jar 等移动应用提取,通过AndroidKiller、apktool、jd-gui、jadx、jad 等反编译工具。静态分析:IDA Pro 分析dex 文件反汇编生成的Dalvik 字节码,或者使用文本编辑器阅读baksmali 反编译生成的smali 文件。另一种是阅读反汇编生成的Java 源码,可以使用dex2jar 生成jar 文件,然后再用jd-gui 阅读文件的代码。
- 利用在线源码托管平台,常见在线源码托管平台
https://searchcode.com/
https://gitee.com/
https://github.com/
https://coding.net/
https://codechina.csdn.net/explore
https://gitshell.com/
http://www.svnchina.com/
11.4 旁站、C 段
旁站指的是同一服务器上的其他网站,很多时候,有些网站可能不是那么容易入侵。那么,可以查看该网站所在的服务器上是否还有其他网站。如果有其他网站的话,可以先拿下其他网站的webshell,然 后再提权拿到服务器的权限,最后就自然可以拿下该网站了!
对于实战攻防工程师来说,C 段扫描比较有意义。对于单独网站的渗透测试,C 段扫描意义不大。C 段嗅探的意思就是拿下它同一C 段中的其中一台服务器,也就是说是C 段 1-255 中的一台服务器,然后利用工具嗅探拿下该服务器。
利用在线平台对平台组织的网站系统进行旁站和C 段探测。常见在线平台如下:
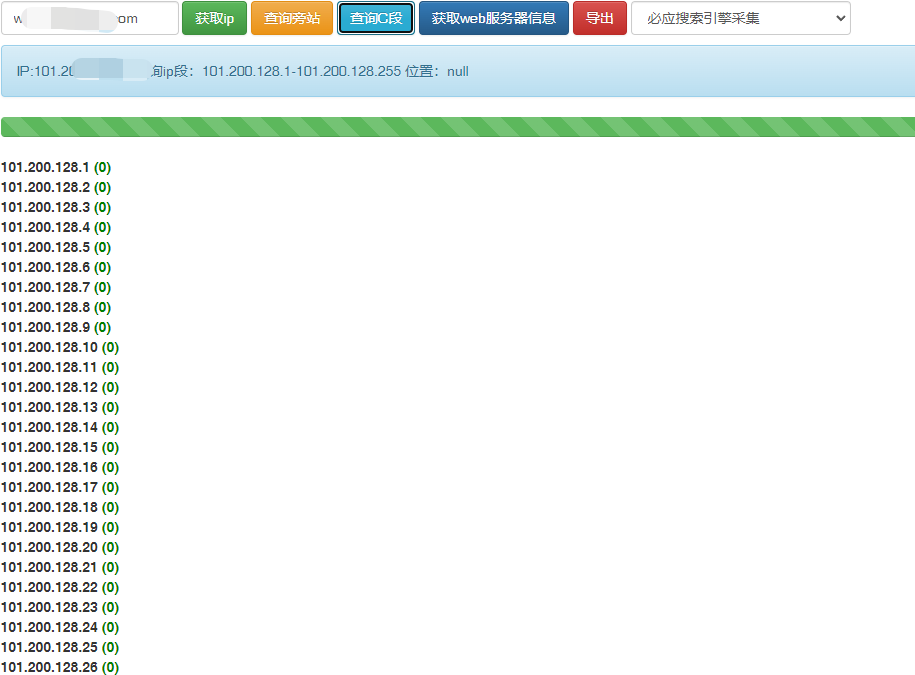
11.5 组织架构
目标组织信息——通过企查查、天眼查、国家企业信用信息公示系统等来对企业信息进行查询,可以查到目标组织的物理地址、逻辑关系网、邮箱、子公司、联系电话等信息。
域名注册信息——Whois 可以查看注册的域名、注册人邮箱、电话、注册商等信息。客服信息—— 销售客服、技术支持售后客服。
招聘信息——官网招聘联系方式、招聘网站联系方式等。
常见在线平台:
11.6 信用信息查询
通过信用信息查询可获取目标组织的相关信息,包含:法定代表人、统一社会信用代码、注册号、经营范围等。
常用在线查询地址:
1、国家企业信用信息公示系统:http://www.gsxt.gov.cn/index.html
2、悉知-全国企业信息查询::http://company.xizhi.com/
3、信用中国-个人信用查询搜索-企业信息查询搜索-统―社会信用代码查询:
https://www.creditchina.gov.cn/
11.7 历史漏洞信息
常用的漏洞公共资源库
1、国内:
国家信息安全漏洞库:http://www.cnnvd.org.cn/
国家信息安全漏洞共享平台: https://www.cnvd.org.cn/
SeeBug:https://www.seebug.org/?ref=www
信息安全漏洞门户VULHUB:http://vulhub.org.cn/viewlglobal
数字观星:https://poc.shuziguanxing.com/#/
NSFOCUS 绿 盟 科 技 :http://www.nsfocus.net/index.php?act=sec_bug
BugScan—漏洞插件社区:http://www.bugscan.net/source/template/vulns/
漏洞列表│教育行业漏洞报告平台:https://src.sjtu.edu.cn/list/
工控系统行业漏洞库平台:http://ivd.winicssec.com/
exp 库-打造中文最大exploit 库:http://www.expku.com/
乌云漏洞库:https://github.com/hanc00l/wooyun_public
2、国外:
Exploit-db:https://www.exploit-db.com/
Sploitus | Exploit & Hacktool Search Engine:https://sploitus.com/
Packetstorm:https://packetstormsecurity.org/
SecurityFocus:https://www.securityfocus.com/bid
Cxsecurity:https://cxsecurity.com/exploit/
rapid7 Vulnerability & Exploit Database:https://www.rapid7.com/db/
Most recent entries - CVE-Search: https://cve.circl.lu/
CVE security vulnerability database.Security vulnerabilities, exploits: https://www.cvedetails.com/
CVE mitre - Search CVE List:https://cve.mitre.org/cve/search_cve_list.html
美国官方工控数据库ICS-CERT Landing | CISA:https://www.us-cert.gov/ics
路由器漏洞搜索Routerpwn: http://www.routerpwn.com/
11.8 社工信息
社工技术在安全领域广泛应用,并成为红队人员的一种辅助手段。在红队人员进行渗透测试前会通过社工手段收集目标组织的信息,所收集到的信息越多攻击测试的面就越广,所能发现的漏洞就越多。当系统足够强大使得你的渗透技术受到限制时,社工手段也不失为一种打开困局的突破口。
社工需要收集的信息有:
- 项目的信息;
- 目标组织的信息;
- 目标组织员工的信息等。
1、项目的信息
一个项目从创建到开发到应用,这中间会产生许多有用的信息,一些信息对于安全人员来说可能是突破某个问题的钥匙。
项目的名称和服务信息的利用:有些软件的服务商会使用他们开发的项目为一些目标组织或者电商提供整套的建站服务,网站和管理后台是他们事先开发好的,并根据客户的需求进行部署。假如某个电商平台我们获知了它的项目名称叫xmall2.0,进而我们可获知xmall 的服务商为A 目标组织,进而我们便有可能获取到该项目的源码。一种方式是冒充客户从A 目标组织获取该xmall2.0 版本的项目,一种是从网上搜索有没有使用者将项目源码泄露。源码都到你手上了,目标在你面前已然变得完全透明,那么接下来的渗透将更加容易。
项目的开发者信息的利用:有的网站你在查看它的源码的时候会发现作者的署名,但是作者的署名会有什么用呢?很多人认为开发者的信息并无用处,但是作为安全人员来说这可是一条渗透的思路。比如我们从一个网站的源码中看到了它的作者是ZhangDeShuai,然后我们可以通过该名字去网上搜到他的一些平台账号,他可能在CSDN、Github 或者博客上发布过一些项目的实例或者技术的框架,这可能就是你所渗透的目标所用到的。开发者往往还有一些不太好的习惯,他们往往将一些重要的信息附上自己的名字,比如有些开发在数据库建admin 表时起名zhangdeshuai_admin。白帽子在 sql 注入后会使用字典猜解表名进而获取表中的数据,那么在爆破字典中加入开发者的名字不失为一种破解的思路。
项目的开发语言、开发框架、时间和版本信息的利用:我们所使用的开发技术都是在不断升级更新 的,在一些老的版本可能会存在一些固有的漏洞。假如我们获知了某个项目使用了php 进行开发,当我们获知了它的开发时间进而便能推测出它大概的php 版本。这就为白帽子提供了一条渗透的思路,通过尝试利用该php 版本存在的固有漏洞便可对该项目进行渗透。
2、目标组织的信息
对渗透目标所属的目标组织来说,目标组织的有些信息也可为我们的渗透提供思路。
目标组织的组织架构、人事信息、产品信息:目标组织的一些公开信息可以从天眼查或者企信宝上看到,一些内部的信息也会因为泄露被获知,但是这些信息能为我们的渗透提供哪些帮助呢?举个例子,比如我们获知了A 目标组织的人事信息,如果该目标组织的内部沟通并不畅通,我们便可冒充A 目标组织某个部门的员工给负责该渗透目标的技术人员打电话,我们可以编一个正当的理由要求该技术人员为我们提供一些便利。再举个例子,比如我们获知了该目标组织的产品信息,我们便可伪装成该产品的重要客户给该目标组织打去电话,表明我们使用该产品时出现了些问题,要求技术人员提供一些信息帮助解决。
目标组织的子域名、子服务器:目标组织子域名或者子服务器的发现能使得攻击面扩大。因为我们所渗透的目标可能会与目标组织的其他域有或多或少的联系,当目标域无从下手时,可以从与该域有关联的其他域另辟蹊径。举个例子,比如我们的渗透目标是http://qq.com,我们通过子域名爆破发现了http://game.qq.com、http://video.qq.com,我们发现了该目标组织还有游戏和视频的业务,可能通过对这两个子域的渗透就能进入该目标组织。
3、人的信息
上面我们提到过,有些人的安全习惯不太好,可能会将一些重要的信息附上自己的名字、生日或者常用昵称,这会为我们的破解提供便利。还有不少目标组织在第三方服务平台或者服务器、域名商处注册账号时会使用技术部门主管的邮箱或者手机号。对渗透目标所属主管的个人信息进行搜集也能为我们实施渗透或者劫持提供思路。
利用在线社工平台进行信息收集:
1、https://www.reg007.com/
2、https://checkusernames.com/
3、https://knowem.com/
4、https://namechk.com/
5、https://www.blackbookonline.info/
6、https://aleph.occrp.org/
7、https://monitor.firefox.com/
8、https://haveibeenpwned.com/
9、https://ghostproject.fr/
11.9 图标和信息特征
favicon.ico 图标——获取目标站点的 favicon.ico 图标的哈希值,然后配合shodan 进行目标站点资产收集,因为每个目标站点的favicon.ico 图标的哈希值可能是固定值,因此可以通过该方法从shodan,fofa 等等去寻找更多资产。示例:“shodan 搜索语句: http.favicon.hash:哈希值”。生成图标哈希值的利用工具:
https://github.com/devanshbatham/FavFreak
非常规操作:
1、如果找到了目标的一处资产,但是对目标其他资产的收集无处下手时,可以查看一下该站点的body 里是否有目标的特征,然后利用网络空间搜索引擎(如fofa 等)对该特征进行搜索,如: body=”XX 公司” 或body=”360” 等。该方式一般适用于特征明显、资产数量较多的目标,并且很多时候效果非常好。
2、当通过上述方式的找到test.com 的特征后,再进行body 的搜索,然后再搜索到test.com 的时候,此时fofa 上显示的ip 大概率为test.com 的真实IP。
11.10 公众号、微信小程序、APP 收集
1、公众号搜集
搜狗:https://weixin.sogou.com/
企查查:https://www.qcc.com/
2、微信小程序收集微信小程序搜索
企查查 https://www.qcc.com/
3、APP 收集
企 查 查 :https://www.qcc.com/
点点:https://app.diandian.com
七麦:https://www.qimai.cn/
七麦还可以切换苹果和安卓,获取下载链接apk 丢进模拟器爱企查:https://aiqicha.baidu.com/

若有收获,就点个赞吧
0 人点赞
