hashmap主要用来处理键值对特征的数据,基于hash表实现map接口,访问速度快,但遍历顺序是不确定的
基本变量
loadFactor //称为负载因子,默认值为0.75threshold //表示所能容纳的键值对的临界值//threshold计算公式为数组长度*负载因子size //HashMap中实际存在的键值对数量modCount //用来记录HashMap内部结构发生变化的次数HashMap的默认容量INITIAL_CAPACITY为 16
HashMap底层实现原理:
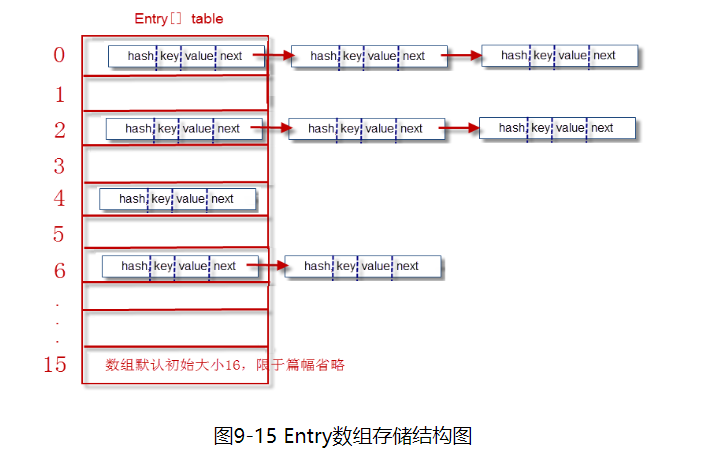
HashMap底层实现采用了哈希表(数组+链表)
存储过程
每个key对象都会产生一个hashcode;不同的散列算法极力解决hash值冲突的问题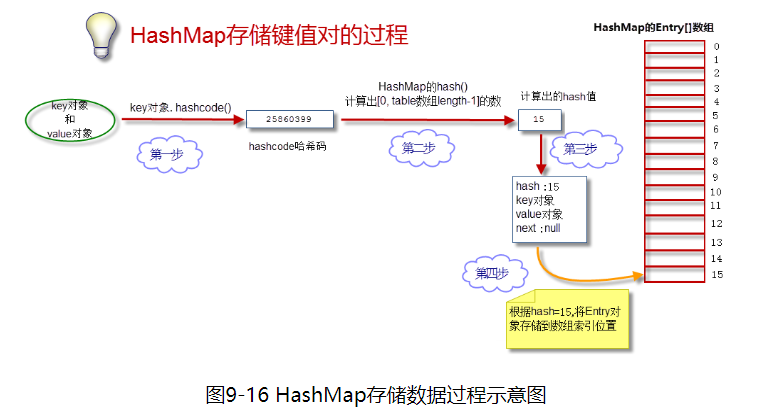
JDK8中,当链表长度大于8时,链表就转换为红黑树,大大提高了查找的效率;链表长度降到6时,转为链表
扩容
HashMap的位桶数组,初始大小为16。实际使用时,大小是可变的。如果位桶数组中的元素达到(数组容量*加载因子), 就重新调整数组大小变为原来2倍大小。
扩容很耗时。扩容的本质是定义新的更大的数组,并将旧数组内容挨个拷贝到新数组中
树化时机
容量大于等于64或者链表长度大于等于8
HashMap非线程安全
1.7
1.7版本使用的是头插法,在扩容的时会把链表逆序插入新的数组中
由于多线程对HashMap进行扩容,某个线程执行过程中,被挂起,其他线程已经完成数据迁移,等CPU资源释放后被挂起的线程重新执行之前的逻辑,数据顺序已经被改变,造成死循环、数据丢失
1.8
由于多线程对HashMap进行put操作,具体原因:假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全

若有收获,就点个赞吧
0 人点赞
