1.opencv 头文件描述

2.点积、叉积
若向量a=(a1,b1,c1),向量b=(a2,b2,c2)
向量a·向量b=a1a2 + b1b2 + c1c2
向量a×向量b=(b1c2-b2c1, c1a2-a1c2, a1b2-a2b1)
https://zhidao.baidu.com/question/11925732.html
3.cv::Rect 矩形相关

3.1 rectangle画矩形
cv::Mat I,B,temp;I = cv::Mat::zeros(300, 400, CV_8UC3);B = I.clone();cv::Rect r1(60,60,200,100);cv::Rect r2(cv::Point(140, 120), cv::Size(200, 100));cv::rectangle(I, r1, cv::Scalar(0,255,0), 2);cv::rectangle(I, r2, cv::Scalar(0,0,255), 2);cv::imshow("rectangle",I);cv::Rect rs(r1);rs += cv::Size(-30, 60);cv::rectangle(B, r1, cv::Scalar(0,255,0), 2);cv::rectangle(B, rs, cv::Scalar(0,0,255), 2);cv::imshow("rectangle2",B);


3.2 cv::RotatedRect 可以旋转矩形
包含一个center(中点)的cv::Point2f变量,一个名为size(矩阵大小)的cv::Size2f变量,以及一个名为angle的浮点数变量表示矩形围绕中心的旋转角度。
cv::Mat I,B,temp;I = cv::Mat(300, 400, CV_8UC3, cv::Scalar(255, 255, 255));cv::Point2f center(200, 150);cv::Size2f size(180, 120);float angle = 30.0;cv::RotatedRect rRect(center, size, angle);cv::Point2f vertices[4];rRect.points(vertices);for (int i=0;i<4; i++){cv::line(I, vertices[i], vertices[(i+1)%4], cv::Scalar(255, 0, 0), 2);}cv::circle(I, center, 2, cv::Scalar(0,0,0), 2);cv::Rect boundingRect = rRect.boundingRect();//外接矩形cv::rectangle(I, boundingRect, cv::Scalar(0,0,255),1);cv::imshow("123",I);

4. RGB颜色空间
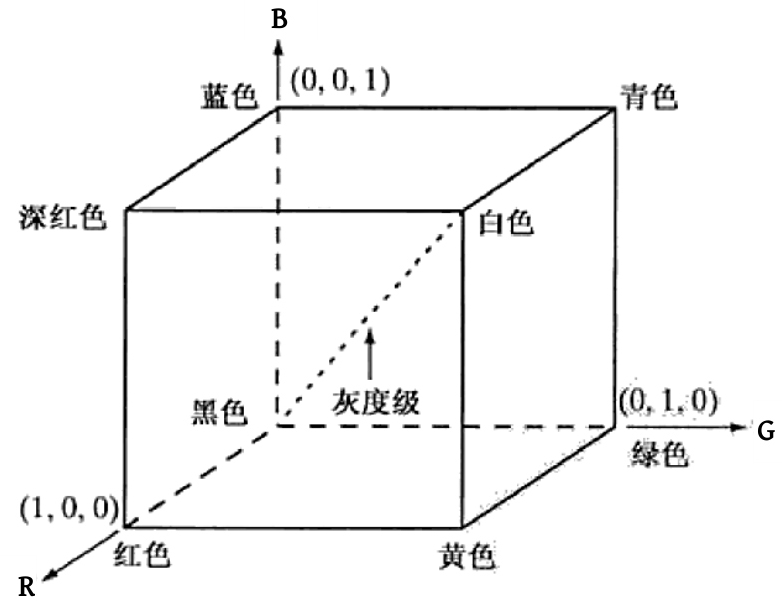
5.机器学习的分类
按照学习形式可以分为监督学习、无监督学习和强化学习等。吧在机器学习任务中用于训练、验证或测试的数据都称为样本,其中,用于训练的样本集称为训练集,用于验证模型好坏的样本集称为验证集,用于测试的样本集简称为测试集。
监督学习使用的是标注过的带有标签的数据进行训练,通常用于回归、分类等。训练集中的每一个样本都由一个输入对象和标签组成。
无监督学习使用无标签的数据进行训练,通常用于异常检测等任务,机器从没有标签的数据中寻找隐藏的模式,发现数据之间内在的特征和相互关系,从而将其划分为不用的类别。
强化学习与监督学习类似,模型在学习过程中以获得对没有学习过的问题做出正确解答的泛化能力为目标。在强化苏学习过程中,算法对预测结果进行自我评估,从而不断改进。
6. K-means聚类
K-means是无监督学习(数据无标签)
K-means实现原理:https://zhuanlan.zhihu.com/p/104557021
以上图为例,分步骤解释:
1. 一组已知数据,我们希望能把他分成K簇;
2. 随机选择K(这里K=2)个聚类的初始中心(以红色、蓝色做区分);
3.簇分配:轮询所有样本数据,计算其到K个中心点的距离,将样本归到距离最小的中心点的聚类,把自己标定成聚类中心点的颜色;
4. 移动聚类中心:找到同一簇(红色或蓝色)所有点的平均位置,把簇中心点移动到这个位置上
5. 重复c) d)的步骤
6. 知道中心点不再变动了(或者变动范围在一个很小值),就认为K均值聚合成功了。
函数:
CV_EXPORTS_W double kmeans( InputArray data, int K, InputOutputArray bestLabels,TermCriteria criteria, int attempts,int flags, OutputArray centers = noArray() );
参数1:输入,points为输入样本矩阵,每行为一个样本。
参数2:输入,clusterCount为类别数。
参数3:输出,labels是一个一维矩阵,其大小和points一样,存储每个输入样本执行k-means后的类标签,值为0到clusterCount-1。
参数4:输入,TermCriteria()为迭代终止条件,含义如下:
◎ TermCriteria::EPS:当迭代达到期望精度时终止,参数为double epsilon=1.0。
◎ TermCriteria::COUNT:当迭代达到最大迭代次数时终止,参数为int max_Count=10。
参数5:输入,attempts为算法使用不同初始类中心坐标尝试执行的次数,attempts=3。
参数6:输入,flag为算法初始化类中心的方法,KMEANS_PP_CENTERS。
参数7:输出,centers中存放的是算法计算后每个类别的中心坐标,后续代码依据centers画圆。
返回值是聚类完成后的类别紧凑性度量值
另外K-means还可以做图片压缩
代码例子:
// k-means.cpp : 定义控制台应用程序的入口点。//#include "stdafx.h"#include "opencv.hpp"#include <iostream>using namespace cv;using namespace std;//#define EXAMPLE1//图片压缩int main(){Mat img = imread("girl.jpg", 1);Mat samples = img.reshape(0, img.cols*img.rows); // 图像转换成sampleCount行*3通道的矩阵printf("image : h = %d, w = %d, c = %d\n", img.rows, img.cols, img.channels());//转换为CV_32FC3浮点型samples.convertTo(samples, CV_32FC3); // or CV_32F works (too)printf("samples: h = %d, w = %d, c = %d\n", samples.rows, samples.cols, samples.channels());//define criteria, number of clusters(K)TermCriteria criteria = TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 10, 1.0);//终止条件int K = 4; // 聚类类别数:4,8,16Mat labels; // 聚类结果索引矩阵Mat centers; // 聚类中心// 执行kmeans()double compactness = kmeans(samples, K, labels, criteria, 3, KMEANS_PP_CENTERS, centers);// 将聚类中心转为int型centers.convertTo(centers, CV_8UC3);// 按照聚类结果标签labels,对samples重新分配BGR值samples.convertTo(samples, CV_8UC3);cout << endl << "--- centers ---" << endl;cout << centers.at<Vec3b>(0, 0) << endl;cout << centers.at<Vec3b>(1, 0) << endl;cout << centers.at<Vec3b>(2, 0) << endl;cout << centers.at<Vec3b>(3, 0) << endl;cout << endl << "--- samples original ---" << endl;cout << samples.at<Vec3b>(1, 0) << endl; // 8U 类型的 RGB 彩色图像使用 <Vec3b>访问Mat像素值cout << samples.at<Vec3b>(100, 0) << endl;cout << samples.at<Vec3b>(1000, 0) << endl;cout << endl << "--- label ---" << endl;cout << labels.at<int>(1) << endl; // 8U 类型的 RGB 彩色图像使用 <Vec3b>访问Mat像素值cout << labels.at<int>(100) << endl;cout << labels.at<int>(1000) << endl;// 按label标签重新为samples赋值,实现色彩压缩for (int i = 0; i < labels.rows; i++){int cluster = labels.at<int>(i);// Vec3b为OpenCV中CV_8UC3类型的RGB彩色图像数据类型samples.at<Vec3b>(i, 0) = centers.at<Vec3b>(cluster, 0);}cout << endl << "--- samples cluttered ---" << endl;cout << samples.at<Vec3b>(1, 0) << endl;cout << samples.at<Vec3b>(100, 0) << endl;cout << samples.at<Vec3b>(1000, 0) << endl;// 4.输出/显示聚类结果// 将samples转回img尺寸Mat img_out = samples.reshape(0, img.rows); // 图像转换成sampleCount行*3通道的矩阵cout << "Compactness: " << compactness << endl;imshow("image", img);imshow("clusters", img_out);// 保存图像stringstream ss;ss << K;string str = ss.str();string image_save_name = str + "_cluter.jpg";imwrite(image_save_name, img_out);waitKey();return 0;}#ifdef EXAMPLE1int main(){//分类坐标点// 1. 初始化参数const int MAX_CLUSTERS = 5; // 最大类别数Scalar colorTab[] ={Scalar(0, 0, 255),Scalar(0,255,0),Scalar(255,100,100),Scalar(255,0,255),Scalar(0,255,255)};Mat img(500, 500, CV_8UC3); // 新建画布img = Scalar::all(255); // 将画布设置为白色RNG rng(12345); //随机数产生器// 主循环for (;;){// 初始化类别数int k, clusterCount = rng.uniform(2, MAX_CLUSTERS + 1); // 在[2, MAX_CLUSTERS + 1)区间,随机生成一个整数// 初始化样本数int i, sampleCount = rng.uniform(1, 1001); // 在[1, 1001)区间,随机生成一个整数Mat points(sampleCount, 1, CV_32FC2); // 输入样本矩阵:sampleCount行*1列,浮点型,2通道Mat labels; // 聚类结果索引矩阵clusterCount = MIN(clusterCount, sampleCount); // 聚类类别数<样本数std::vector<Point2f> centers;cout << points.at<float>(0,0) << endl;cout << points.at<float>(10,0) << endl;cout << "---1---" << endl;// 2. 随机生成输入样本/* generate random sample from multigaussian distribution */for (k = 0; k < clusterCount; k++){Point center;center.x = rng.uniform(0, img.cols);center.y = rng.uniform(0, img.rows);// 对样本points指定行进行赋值Mat pointChunk = points.rowRange(k*sampleCount / clusterCount,k == clusterCount - 1 ? sampleCount :(k + 1)*sampleCount / clusterCount);cout << points.at<float>(0, 0) << endl;cout << points.at<float>(10, 0) << endl;cout << "---2---" << endl;// rng.fill函数,会以center点为中心,产生高斯分布的随机点(位置点),并把位置点保存在矩阵pointChunk中。rng.fill(pointChunk, RNG::NORMAL, Scalar(center.x, center.y), Scalar(img.cols*0.05, img.rows*0.05));}//打乱points中的值,//第二个参数表示随机交换元素的数量的缩放因子,//总的交换次数dst.rows*dst.cols*iterFactor,//第三个参数是个随机发生器,决定选那两个元素交换。cout << points.at<float>(0, 0) << endl;cout << points.at<float>(10, 0) << endl;cout <<"---3---" << endl;randShuffle(points, 1, &rng);cout << points.at<float>(0, 0) << endl;cout << points.at<float>(10, 0) << endl;cout << "---4---" << endl;// 3. 执行k-means()算法// 输入:points为输入样本矩阵,每一行为一个样本// 输入:clusterCount为类别数// 输出:labels是一个一维矩阵,其size和points一样,存储每个输入样本执行kmeans算法后的类标签,值为0到clusterCount-1// 输入:TermCriteria()迭代终止条件:// TermCriteria::COUNT:当迭代达到最大迭代次数时终止,参数为int max_Count=10// TermCriteria::EPS:当迭代达到期望精度时终止,参数为double epsilon=1.0// 输出:centers中存放的是kmeans算法结束后每个类别的中心位置// 返回值:compactness聚类完成后的类别紧凑性度量值double compactness = kmeans(points, clusterCount, labels,TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 10, 1.0),3, KMEANS_PP_CENTERS, centers);// 4.绘制聚类结果for (i = 0; i < sampleCount; i++){int clusterIdx = labels.at<int>(i);Point ipt = points.at<Point2f>(i);circle(img, ipt, 2, colorTab[clusterIdx], FILLED, LINE_AA);}for (i = 0; i < (int)centers.size(); ++i){Point2f c = centers[i];circle(img, c, 40, colorTab[i], 1, LINE_AA);}// 5.输出/显示聚类结果cout << "Compactness: " << compactness << endl;imshow("clusters", img);char key = (char)waitKey();if (key == 27 || key == 'q' || key == 'Q') // 'ESC'break;}return 0;}#endif
7.KNN
https://zhuanlan.zhihu.com/p/85636009
KNN是分类算法中最简单的方法之一。为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的投票法则,将未知样本与K个最邻近样本中所属类别占比较多的归为一类。
理解:
- k=3, 存在两个蓝色,一个绿色,则红星属于蓝色类别;
- k=5, 存在三个绿色,2个蓝色,则红星属于绿色类别;

k 的取值很关键,K值选的太大易引起欠拟合,太小容易过拟合,需交叉验证确定K值。
缺点:1.因为训练样本是存在内存中的,所有需要大量的存储空间,而且计算待测样本和训练数据中所有样本的距离,所以非常耗时。
2.对于随机分布的数据效果不好。
// KNN.cpp : 定义控制台应用程序的入口点。//#include "stdafx.h"#include "opencv.hpp"#include <iostream>using namespace cv;using namespace cv::ml;using namespace std;//#define CLASSIFIER#define REGRESSION// 生成训练集与测试集的函数void generateDataSet(Mat &img, Mat &trainData, Mat &testData, Mat &trainLabel, Mat &testLabel, int train_rows=4);#ifdef CLASSIFIERint main(){// 用于分类// 1.读取原始数据Mat img = imread("digits.png", 1); // 使用图片格式的MNIST数据集(部分)cvtColor(img, img, CV_BGR2GRAY);// 2.制作训练集// 设置训练集、测试集大小int train_sample_count = 4000;int test_sample_count = 1000;int train_rows = 4; // 每类用于训练的行数,4000/10类/100(样本/行)=4Mat trainData, testData; // 申明训练集与测试集Mat trainLabel(train_sample_count, 1, CV_32FC1); // 申明训练集标签Mat testLabel(test_sample_count, 1, CV_32FC1); // 申明测试集标签// 生成训练集、测试集与标签generateDataSet(img, trainData, testData, trainLabel, testLabel/*, train_rows*/);// 3.创建并初始化KNN模型cv::Ptr<cv::ml::KNearest> knn = cv::ml::KNearest::create(); // 创建knn模型int K = 5; // 考察的最邻近样本个数knn->setDefaultK(K);knn->setIsClassifier(true); // 用于分类knn->setAlgorithmType(cv::ml::KNearest::BRUTE_FORCE);// 4.训练printf("开始训练...\n");//printf("trainData : rows, cols = %d, %d\n", trainData.rows, trainData.cols);//printf("trainLabel: rows, cols = %d, %d\n", trainLabel.rows, trainLabel.cols);knn->train(trainData, cv::ml::ROW_SAMPLE, trainLabel);printf("训练完成\n\n");// 5.测试printf("开始测试...\n");Mat result;knn->findNearest(testData, K, result);//printf("test samples = %d\n", testData.rows);//printf("result rows = %d\n", result.rows);// 精度int count = 0;for (int i = 0; i < test_sample_count; i++){int predict = int(result.at<float>(i));int actual = int(testLabel.at<float>(i));if (predict == actual){printf("label: %d, predict: %d\n", actual, predict);count++;}elseprintf("label: %d, predict: %d ×\n", actual, predict);}printf("测试完成\n");// 输出结果double accuracy = double(count) / double(test_sample_count);printf("K = %d\n", K);printf("accuracy = %.4f\n", accuracy);waitKey();return 0;}#endif#ifdef REGRESSIONint main(){// 用于回归// 1.读取原始数据Mat img = imread("digits.png", 1);cvtColor(img, img, CV_BGR2GRAY);// 2.制作训练集// 设置训练集、测试集大小int train_sample_count = 4000;int test_sample_count = 1000;int train_rows = 4; // 每类用于训练的行数,4000/10类/100(样本/行)=4Mat trainData, testData; // 申明训练集与测试集Mat trainLabel(train_sample_count, 1, CV_32FC1); // 申明训练集标签Mat testLabel(test_sample_count, 1, CV_32FC1); // 申明测试集标签// 生成训练集、测试集与标签generateDataSet(img, trainData, testData, trainLabel, testLabel/*, train_rows*/);// 3.创建并初始化KNN模型cv::Ptr<cv::ml::KNearest> knn = cv::ml::KNearest::create(); // 创建knn模型int K = 5; // 考察的最邻近样本个数knn->setDefaultK(K);knn->setIsClassifier(false); // 用于回归knn->setAlgorithmType(cv::ml::KNearest::BRUTE_FORCE);// 4.训练printf("开始训练...\n");//printf("trainData : rows, cols = %d, %d\n", trainData.rows, trainData.cols);//printf("trainLabel: rows, cols = %d, %d\n", trainLabel.rows, trainLabel.cols);knn->train(trainData, cv::ml::ROW_SAMPLE, trainLabel);printf("训练完成\n\n");// 5.测试printf("开始测试...\n");Mat result;knn->findNearest(testData, K, result);//printf("test samples = %d\n", testData.rows);//printf("result rows = %d\n", result.rows);// 精度int t = 0;int f = 0;for (int i = 0; i < test_sample_count; i++){int predict = int(result.at<float>(i));int actual = int(testLabel.at<float>(i));if (predict == actual){printf("label: %d, predict: %d\n", actual, predict);t++;}else{printf("label: %d, predict: %d ×\n", actual, predict);f++;}}printf("测试完成\n");// 输出结果float accuracy = (t * 1.0) / (t + f);printf("K = %d\n", K);printf("accuracy = %.4f\n", accuracy);waitKey();return 0;}#endif/** @生成模型的训练集与测试集参数1:img ,输入,灰度图像,由固定尺寸小图拼接成的大图,不同类别的小图像依次排列参数2:trainData ,输出,训练集,维度为:训练样本数 * 单个样本特征数,CV_32FC3类型参数3:testData ,输出,测试集,维度为:测试样本数 * 单个样本特征数,CV_32FC3类型参数4:trainLabel,输出,训练集标签,维度为:训练样本数 * 1,CV_32FC1类型参数4:testLabel ,输出,测试集标签,维度为:测试样本数 * 1,CV_32FC1类型参数5:train_rows,输入,用于训练的样本所占行数,默认4行用于训练,1行用于测试*/void generateDataSet(Mat &img, Mat &trainData, Mat &testData, Mat &trainLabel, Mat &testLabel, int train_rows){// 初始化图像中切片图与其他参数int width_slice = 20; // 单个数字切片图像的宽度int height_slice = 20; // 单个数字切片图像的高度int row_sample = 100; // 每行样本数100幅小图int col_sample = 50; // 每列样本数50幅小图int row_single_number = 5; // 单个数字占5行int test_rows = row_single_number - train_rows; // 测试样本所占行数Mat trainMat(train_rows * 20 *10, img.cols, CV_8UC1); // 存放所有训练图片trainMat = Scalar::all(0);Mat testMat(test_rows * 20 * 10, img.cols, CV_8UC1); // 存放所有测试图片testMat = Scalar::all(0);// 生成测试、训练大图for (int i = 1; i <= 10 ; i++){Mat tempTrainMat = img.rowRange((i - 1) * row_single_number * 20, (i * row_single_number - 1) * 20).clone();Mat tempTestMat = img.rowRange((i * row_single_number - 1) * 20, (i * row_single_number) * 20).clone();imshow("temptrain", tempTrainMat);imshow("temptest", tempTestMat);//printf("tempTrainMat(w, h) = %d, %d\n", tempTrainMat.cols, tempTrainMat.rows);//printf("tempTestMat (w, h) = %d, %d\n", tempTestMat.cols, tempTestMat.rows);// traincv::Mat roi_train = trainMat(Rect(0, (i - 1) * train_rows * 20, tempTrainMat.cols, tempTrainMat.rows));Mat mask_train(roi_train.rows, roi_train.cols, roi_train.depth(), Scalar(1));// testcv::Mat roi_test = testMat(Rect(0, (i - 1) * test_rows * 20, tempTestMat.cols, tempTestMat.rows));Mat mask_test(roi_test.rows, roi_test.cols, roi_test.depth(), Scalar(1));// 提取的训练测试行分别复制到训练图与测试图中tempTrainMat.copyTo(roi_train, mask_train);tempTestMat.copyTo(roi_test, mask_test);//显示效果图imshow("trainMat", trainMat);imshow("tesetMat", testMat);cv::waitKey(10);}// 存大图imwrite("trainMat.jpg", trainMat);imwrite("testMat.jpg", testMat);// 生成训练、测试数据printf("开始生成训练、测试数据...\n");Rect roi;for (int i = 1; i <= col_sample; i++) // 50行:1-50行数字图像{//printf("第%d行: \n", i);for (int j = 1; j <= row_sample; j++) // 100列:1-100列数字图像{// 第行为训练集Mat temp_single_num; // 读取一个数字图像// 关键步骤:当前切片数字的位置区域roi = Rect((j-1)*width_slice, (i-1)*height_slice, width_slice, height_slice);temp_single_num = img(roi).clone(); // 注意此处需要使用深拷贝.clone(),后面才能改变切片图的形状,否则roi内存区域不连续//imshow("slice", temp_single_num);//waitKey(1);if (i % 5 != 0)//{// 起始行记为1-4,6-9,11-14...46-49行为测试集// 将单个数字切片拉成向量连续放入Mat容器中trainData.push_back(temp_single_num.reshape(0, 1));//}else//{ // 起始行记为1,第5,10,15...50行为测试集testData.push_back(temp_single_num.reshape(0, 1));//}}}trainData.convertTo(trainData, CV_32FC1);testData.convertTo(testData, CV_32FC1);printf("训练、测试数据已生成\n\n");// 生成标签printf("开始生成标签数据...\n");for (int i = 1; i <= 10; i++){// train labelMat tmep_label_train = Mat::ones(train_rows * row_sample, 1, CV_32FC1); // 临时存放当前标签的矩阵tmep_label_train = tmep_label_train * (i - 1); // 标签从0开始Mat temp = trainLabel.rowRange((i - 1)* train_rows * row_sample, i * train_rows * row_sample);tmep_label_train.copyTo(temp); // 将临时标签复制到trainLabel对应区域,因为浅拷贝,改变temp即改变trainLabel// test labelMat tmep_label_test = Mat::ones(test_rows * row_sample, 1, CV_32FC1);tmep_label_test = tmep_label_test * (i - 1);temp = testLabel.rowRange((i - 1)* test_rows * row_sample, i * test_rows * row_sample);tmep_label_test.copyTo(temp);}printf("标签数据已生成\n\n");//printf("trainLabel(1,400,401,800,801,4000) = %f, %f, %f, %f, %f, %f\n", trainLabel.at<float>(0), trainLabel.at<float>(399), trainLabel.at<float>(400), trainLabel.at<float>(799), trainLabel.at<float>(800), trainLabel.at<float>(3999));//printf("testLabel (1,100,101,200,201,1000) = %f, %f, %f, %f, %f, %f\n", testLabel.at<float>(0), testLabel.at<float>(99), testLabel.at<float>(100), testLabel.at<float>(199), testLabel.at<float>(200), testLabel.at<float>(999));//cv::waitKey();}
7.决策树
决策树是属于监督学习,可以做分类也可以做回归。最早出现的是ID3算法,之后进行改进成了C4.5算法。决策树的核心问题是:自顶向下的各个节点应选择何种属性进行切分,才能获得最好的分类。因此,选择最佳切分属性是决策树的关键所在(意思是如何找到一个最佳属性当作根节点)。
详细介绍:https://www.cnblogs.com/molieren/articles/10664954.html
视频介绍:https://www.bilibili.com/video/BV1Ps411V7px?p=5
// Creating and training a decision tree#include "stdafx.h"#include <opencv.hpp>#include <opencv2/ml/ml.hpp>#include <iostream>#define _MUSROOM//#define _BOSTONusing namespace std;using namespace cv;using namespace cv::ml;#ifdef _BOSTONint main(int argc, char *argv[]) {// 1.读取数据// 1.1 读取训练集const char *csv_file_name_train = "../boston-house-prices/housing-train.csv";cv::Ptr<TrainData> dataSetTrain =TrainData::loadFromCSV(csv_file_name_train, // Input file name0, // 从数据文件开头跳过的行数-1, // 样本标签于此列开始,-1时样本标签为最后一列-1 // 样本标签于此列结束,-1时为上一个参数所在列);// 验证数据读取是否正确int n_train_samples = dataSetTrain->getNSamples();if (n_train_samples == 0) {cerr << "读取文件错误: " << csv_file_name_train << endl;exit(-1);}else {cout << "从" << csv_file_name_train << "中,读取了" << n_train_samples << "个训练样本" << endl;}// 1.2 读取测试集const char *csv_file_name_test = "../boston-house-prices/housing-test.csv";cv::Ptr<TrainData> dataSetTest = TrainData::loadFromCSV(csv_file_name_test, 0, -1, -1);int n_test_samples = dataSetTest->getNSamples();if (n_test_samples == 0) {cerr << "读取文件错误: " << csv_file_name_test << endl;exit(-1);}else {cout << "从" << csv_file_name_test << "中,读取了" << n_test_samples << "个测试样本" << endl;}// 2.创建决策树模型cv::Ptr<RTrees> dtree = RTrees::create();// 3.设置模型参数dtree->setMaxDepth(15);//15dtree->setMinSampleCount(2);//2dtree->setRegressionAccuracy(0.01f);dtree->setUseSurrogates(false /* true */);dtree->setCalculateVarImportance(true); // 开启特征重要性计算//dtree->setMaxCategories(15);dtree->setCVFolds(0 /*10*/); //dtree->setUse1SERule(true/*true*/);dtree->setTruncatePrunedTree(true);// 4.训练决策树cout << "start training..." << endl;dtree->train(dataSetTrain);cout << "training success!" << endl;// 输出样本特征属性重要性Mat var_importance = dtree->getVarImportance();if (!var_importance.empty()){double rt_imp_sum = sum(var_importance)[0];printf("var#\timportance (%%):\n");int i, n = (int)var_importance.total();// 返回矩阵的元素总个数for (i = 0; i < n; i++)printf("%-2d\t%-4.1f\n", i, 100.f*var_importance.at<float>(i) / rt_imp_sum);}// 5. 训练集精度cv::Mat train_results;float MSE_train = dtree->calcError(dataSetTrain,false, // use train datatrain_results);cv::Mat expected_responses = dataSetTrain->getResponses();int total_train = 0;float square_error = 0.0;cout << endl << "--- train set --- " << endl;for (int i = 0; i < expected_responses.rows; ++i) {float responses = train_results.at<float>(i, 0);float expected = expected_responses.at<float>(i, 0);square_error += (expected - responses) * (expected - responses);total_train++;//cout << "price: " << expected << ",\tpredict: " << responses << endl;cout << expected << "\t" << responses << endl;}// 计算RMSE指标float RMSE_train = sqrt(square_error / total_train);// 6. 保存模型dtree->save("trained_dtree.xml");// 7. 读取模型dtree->load("trained_dtree.xml");// 8. 测试集精度cv::Mat results_test;float MSE_test = dtree->calcError(dataSetTest,true, // use train data: now it is test data actuallyresults_test);cv::Mat expected_responses_test = dataSetTest->getResponses();//cout << expected_responses_test.size() << endl;int total_test = 0;square_error = 0.0;cout << endl << "--- test set --- " << endl;for (int i = 0; i < expected_responses_test.rows; ++i) {float responses = results_test.at<float>(i, 0);float expected = expected_responses_test.at<float>(i, 0);square_error += (expected - responses) * (expected - responses);total_test++;//cout << "price: " << expected << ",\tpredict: " << responses << endl;cout << expected << "\t" << responses << endl;}// 计算RMSE指标float RMSE_test = sqrt(square_error / total_test);cout << "train data RMSE = " << RMSE_train << " k USD" << endl;cout << "test data RMSE = " << RMSE_test << " k USD" << endl;cout << "train data MSE = " << MSE_train << endl;cout << "test data MSE = " << MSE_test << endl;system("pause");return 0;}#endif#ifdef _MUSROOMint main(int argc, char *argv[]) {// 1.读取数据//const char *csv_file_name = argc >= 2 ? argv[1] : "D:/data/ml-data/mushroom/agaricus-lepiota.data";const char *csv_file_name = argc >= 2 ? argv[1] : "../mushroom/agaricus-lepiota.data";// 1.1 读取CSV数据文件// 函数用法...cv::Ptr<TrainData> dataSet =TrainData::loadFromCSV(csv_file_name, // Input file name0, // 从数据文件开头跳过的行数0, // 样本的标签从此列开始1, // 样本输入特征向量从此列开始"cat[0-22]" // All 23 columns are categorical);// Use defaults for delimeter (',') and missch ('?')使用默认的“,”分割特征// 1.2 验证数据读取是否正确int n_samples = dataSet->getNSamples();if (n_samples == 0) {cerr << "读取文件错误: " << csv_file_name << endl;exit(-1);}else {cout << "从" << csv_file_name << "中,读取了" << n_samples << "个样本" << endl;}// 1.3 划分训练集与测试集dataSet->setTrainTestSplitRatio(0.9, false); //按90%和10%的比例将数据集为训练集和测试集int n_train_samples = dataSet->getNTrainSamples();int n_test_samples = dataSet->getNTestSamples();cout << "Train Samples: " << n_train_samples << endl<< "Test Samples: " << n_test_samples << endl;// 2.创建决策树模型cv::Ptr<RTrees> dtree = RTrees::create();// 3.设置模型参数// 3.1 设置类别重要性数组// Set up priors to penalize "poisonous" 10x as much as "edible"//float _priors[] = { 1.0, 10.0 };//cv::Mat priors(1, 2, CV_32F, _priors);dtree->setMaxDepth(10);//10dtree->setMinSampleCount(10);//10dtree->setRegressionAccuracy(0.01f);dtree->setUseSurrogates(false /* true */);dtree->setMaxCategories(15);dtree->setCVFolds(1 /*10*/); // nonzero causes core dumpdtree->setUse1SERule(false/*true*/);dtree->setTruncatePrunedTree(true);//dtree->setPriors( priors );dtree->setPriors(cv::Mat()); // ignore priors for now...// Now train the model// NB: we are only using the "train" part of the data set// 4.训练决策树cout << "start training..." << endl;dtree->train(dataSet);cout << "training success." << endl;// 5.测试cv::Mat results_train, results_test;float train_error = dtree->calcError(dataSet, false, results_train);// use training datafloat test_error = dtree->calcError(dataSet, true, results_test); // use test datastd::vector<cv::String> names;dataSet->getNames(names);Mat flags = dataSet->getVarSymbolFlags();// 6.统计输出结果cv::Mat expected_responses = dataSet->getTestResponses();int t = 0, f = 0, total = 0;for (int i = 0; i < dataSet->getNTestSamples(); ++i) {float responses = results_test.at<float>(i, 0);float expected = expected_responses.at<float>(i, 0);cv::String r_str = names[(int)responses];cv::String e_str = names[(int)expected];if (responses == expected){t++;cout << "label: " << e_str << ", predict: " << r_str << endl;}else{f++;cout << "label: " << e_str << ", predict: " << r_str << " ×" << endl;}total++;}cout << "Correct answer = " << t << endl;cout << "Incorrect answer = " << f << endl;cout << "Total test sample = " << total << endl;cout << "[Decision Tree] Correct answers : " << (float(t) / total) << ""<< endl;cout << "[Decision Tree] Incorrect answers: " << (float(f) / total) << "" << endl;cout << "[Decision Tree] Error on training data: " << train_error << "%" << endl;cout << "[Decision Tree] Error on test data: " << test_error << "%" << endl;system("pause");return 0;}#endif

若有收获,就点个赞吧
0 人点赞
