W10使用cuda运行YOLOv5方法
https://www.cnblogs.com/20183544-wangzhengshuai/p/14814438.html
https://blog.csdn.net/liaowenfeng/article/details/122249033
如果运行报错
AttributeError: ‘Upsample‘ object has no attribute ‘recompute_scale_factor‘问题解决
原因是torch 版本太高的原因,或者解决办法:https://blog.csdn.net/SSS__jq/article/details/123458804
requirements.txt 文件
一般项目都会指定出项目所包含的库,及库版本。都是在这个文件里面。
命令行执行:
1、首先先确认到指定的python环境。conda activate YOLOV5_python38
2、然后执行 pip install -r requirements.txt
detect参数讲解
—weights
加载默认的权重文件(模型文件),文件一般都是github上的这些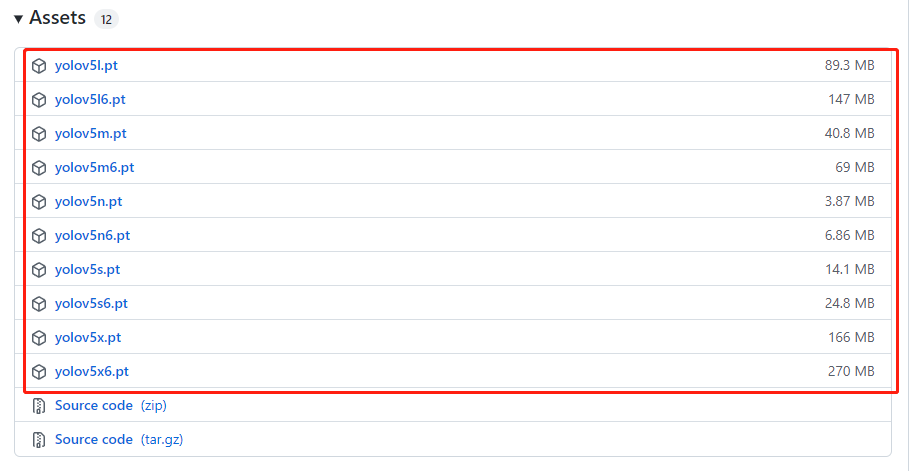
—source
—img-size
是图片在训练或预测过程中,需要把图片resize到指定大小来操作。官方给的权重文件有640和1280两种
—conf-thres
—iou-thres

IOU的计算公式:交集除以并集
例子:
值越大框越多:如当这个值为1时
—device
表示是用CPU还是cuda。默认为空,他会在后台自己检测,优先GPU(前提是cuda环境要安装好)
—view-img
只要指定了这个参数 ,这个就会设置为true,这个参数的意思是在检测过程中显示检测结果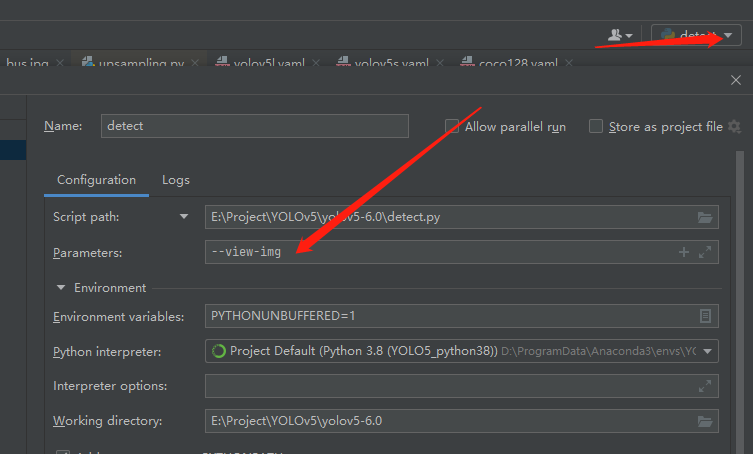
—save-txt
—save-conf
—nosave
—classes
可以指定只识别某种或几种类型
如: —classes 0 只识别类型0的
—angnostic-nms
—augment
—update
—project
—name
—exist-ok
如果没有设置他,就会以文件夹递增式的保存文件。如果设置了这个就只会保存到以—name设置的文件名中
train参数讲解
—weights
可以指定一个训练好的模型(迁移学习,利用训练好的模型,作为参数初始化)。如果空则会参用程序的默认参数去初始化。
—cfg
—data
—hyp
—epochs
—batch-size
把多少个数据打包成一个batch送到网络模型中训练,值越大,训练速度也越快,大小受GPU的限制
—img-size
—rect

—resume
如果需要继续训练模型,就指定之前训练的模型权重文件 default=’last.pt’
—nosave
—notest
—noautoanchor
—evolve
—image-weights
—multi-scale
—single-cls
—adam
—sync-bn
—linear-lr
学习速率

若有收获,就点个赞吧
0 人点赞
