数组
数组是一种连续存储线性结构,元素类型相同,大小相等,数组是多维的,通过使用整型索引值来访问他们的元素,数组尺寸不能改变
数组的优点:
存取速度快
数组的缺点:
事先必须知道数组的长度
插入删除元素很慢
空间通常是有限制的
需要大块连续的内存块
插入删除元素的效率很低
2. 链表
n个节点离散分配,彼此通过指针相连,每个节点只有一个前驱节点,每个节点只有一个后续节点,首节点没有前驱节点,尾节点没有后续节点。
确定一个链表我们只需要头指针,通过头指针就可以把整个链表都能推出来。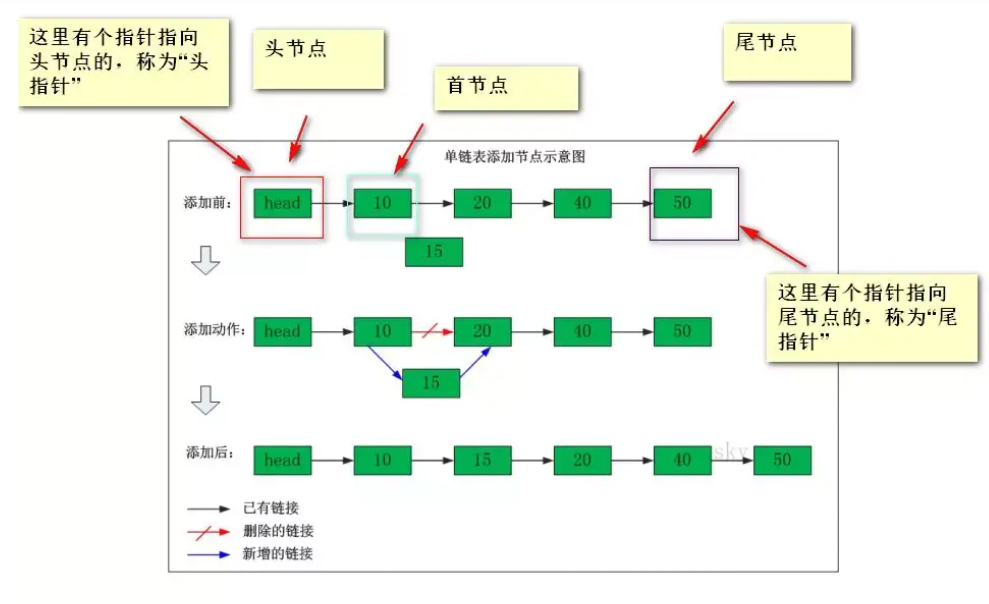
链表优点
空间没有限制
插入删除元素很快
链表缺点
存取速度很慢
链表又细分了3类:
单向链表
一个节点指向下一个节点。
双向链表
一个节点有两个指针域。
循环链表
能通过任何一个节点找到其他所有的节点,将两种(双向/单向)链表的最后一个结点指向第一个结点从而实现循环。
操作链表要时刻记住的是:节点中指针域指向的就是另一个节点!
Java实现链表
首先,我们定义一个类作为节点,节点需要有两个属性:
数据域
指针域
public class Node {//数据域public int data;//指针域,指向下一个节点public Node next;public Node() {}public Node(int data) {this.data = data;}public Node(int data, Node next) {this.data = data;this.next = next;}
如上,一个链表节点对象就创建完成了,但理解链表本身并不难,但做相关的操作却并非易事,其算法包括且不限于:
- 插入节点
遍历
查找
清空
销毁
求长度
排序
删除节点
去重
创建链表&增加节点
创建头节点
Node head = new Node(value);
然后找到尾节点进行插入
/*** 向链表添加数据* @param value 要添加的数据* @param head 头节点*/public static void addData(int value, Node head) {//初始化要加入的节点Node newNode = new Node(value);//临时节点Node temp = head;// 找到尾节点while (temp.next != null) {temp = temp.next;}// 已经包括了头节点.next为null的情况了~temp.next = newNode;}
遍历链表
上面我们已经编写了增加方法,现在遍历一下,从首节点开始,不断往后面找,直到后面的节点没有数据
/**● 遍历链表● @param head 头节点*/public static void traverse(Node head) {//临时节点,从首节点开始Node temp = head.next;while (temp != null) {System.out.println("链表数据:" + temp.data);//继续下一个temp = temp.next;}}
- 栈和队列
参考什么是堆,栈,堆栈,队列
数组和链表都是线性存储结构的基础,栈和队列都是线性存储结构的应用。
栈
我们将栈可以看成一个放光盘的箱子,箱口与略大与光盘。然后
往箱子里面放东西叫做入栈
往箱子里面取东西叫做出栈
箱子的底部叫做栈底
箱子的顶部叫做栈顶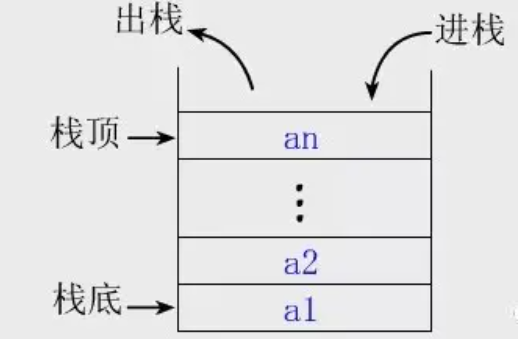
说到栈的特性,有一句经典的言语来概括:先进后出,后进先出。
Java实现栈
使用数组实现的叫静态栈
使用链表实现的叫动态栈
沿用上一章节的链表对象Node,创建一个栈对象(栈顶,栈底):
public class Stack {// 栈顶public Node stackTop;// 栈底public Node stackBottom;public Stack(Node stackTop, Node stackBottom) {this.stackTop = stackTop;this.stackBottom = stackBottom;}public Stack() {}
}
进栈操作
将原本栈顶指向的节点交由新节点来指向,栈顶指向新加入的节点
/**● 进栈● @param stack 栈● @param value 要进栈的元素*/public static void pushStack(Stack stack, int value) {// 封装数据成节点Node newNode = new Node(value);// 栈顶本来指向的节点交由新节点来指向newNode.next = stack.stackTop;// 栈顶指针指向新节点stack.stackTop = newNode;}
遍历栈
只要栈顶元素的指针不指向栈底,那么就一直输出遍历结果
/**● 遍历栈● @param stack*/public static void traverse(Stack stack) {Node stackTop = stack.stackTop;//栈顶元素的指针不指向栈底,那么就一直输出遍历结果while (stackTop != stack.stackBottom) {System.out.println("栈数据:" + stackTop.data);stackTop = stackTop.next;}
出栈操作
在出栈之前看看该栈是否为空,不为空才出栈
将栈顶的元素的指针(指向下一个节点)赋值给栈顶指针(完成出栈)
/**● 出栈(将栈顶的指针指向下一个节点)● @param stack*/public static void popStack(Stack stack) {// 栈不为空才能出栈if (stack.stackTop != stack.stackBottom) {//栈顶元素Node top = stack.stackTop;// 栈顶指针指向下一个节点stack.stackTop = top.next;System.out.println("栈数据:" + top.data);}}
队列
队列非常好理解,我们将队列可以看成我们平时排队打饭。
有新的人加入了 -> 入队
队头的人打饭了 -> 出队
相对于栈而言,队列的特性是:先进先出,后进后出
队列
使用数组实现的叫静态队列
使用链表实现的叫动态队列
这次我就使用数组来实现静态队列。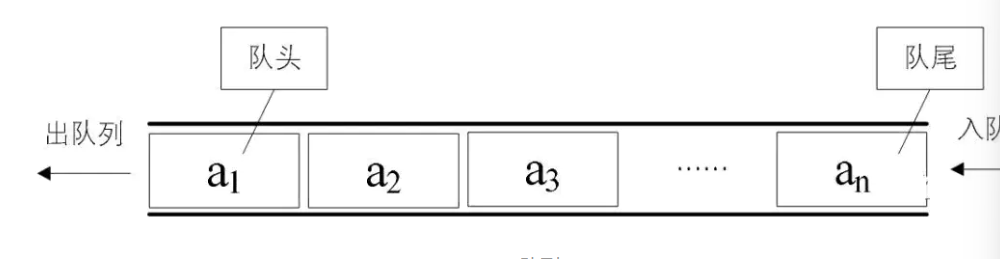
Java实现队列
public class Queue {private Object[] data=null;private int maxSize; //队列容量private int front; //队列头,允许删除private int rear; //队列尾,允许插入//构造函数public Queue(){this(5);}public Queue(int initialSize){if(initialSize >=0){this.maxSize = initialSize;data = new Object[initialSize];front = rear =0;}else{throw new RuntimeException("初始化大小不能小于0:" + initialSize);}}//判空public boolean empty(){return rear==front?true:false;}//入队public boolean add(E e){if(rear== maxSize){throw new RuntimeException("队列已满,无法插入新的元素!");}else{data[rear++]=e;return true;}}//出队public E poll(){if(empty()){throw new RuntimeException("空队列异常!");}else{E value = (E) data[front]; //保留队列的front端的元素的值data[front++] = null; //释放队列的front端的元素return value;}}//队列长度public int length(){return rear-front;}/*** 遍历队列* @param queue**/public static void traverseQueue(Queue queue) {// front的位置int i = queue.front;while (i != queue.rear) {System.out.println("队列值:" + queue.data[i]);//移动fronti = (i + 1) % queue.data.length;}}
}
其他队列算法、循环队列、链表结构的队列实现略,读者朋友可自行练习。
二叉树
树是一种非线性的数据结构,相对于线性的数据结构(链表、数组)而言,树的平均运行时间更短(往往与树相关的排序时间复杂度都不会高),
和现实中的树相比,编程的世界中的树一般是“倒”过来看,这样容易我们分析。
现实中的树是有很多很多个分支的,分支下又有很多很多个分支,如果在程序中实现这个会非常麻烦。因为本来树就是非线性的,而我们计算机的内存是线性存储的,太过复杂的话无法设计出来。
因此,就有了简单又经常用的 -> 二叉树,顾名思义,就是每个分支最多只有两个的树,上图就是二叉树。
一棵树至少会有一个节点(根节点)
树由节点组成,每个节点的数据结构包括一个数据和两个分叉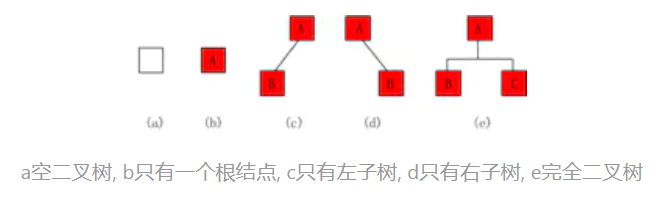
a空二叉树, b只有一个根结点, c只有左子树, d只有右子树, e完全二叉树
Java实现二叉树
首先,使用Java类定义节点
public class TreeNode {// 数据private int value;// 左节点private TreeNode leftNode;// 右节点private TreeNode rightNode;public TreeNode(int value) {this.value = value;}// TODO getter&setter略...
遍历二叉树
二叉树遍历有三种方式:
中序遍历
先访问根节点,然后访问左节点,最后访问右节点(根->左->右)
先序遍历
先访问左节点,然后访问根节点,最后访问右节点(左->根->右)
后序遍历
先访问左节点,然后访问右节点,最后访问根节点(左->右->根)
堆和堆栈
堆内存用来存放由new创建的对象和数组。
在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。
‘堆栈’ 就是 ‘栈’,称呼不同而已。
栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享。
堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
散列表
无论是Set还是Map,我们会发现都会有对应的—>HashSet,HashMap
首先我们也先得回顾一下数据和链表:
链表和数组都可以按照人们的意愿来排列元素的次序,他们可以说是有序的(存储的顺序和取出的顺序是一致的)
这会带来缺点:想要获取某个元素,就要访问所有的元素,直到找到为止,会消耗很多时间。
所以我们需要另外的存储结构:不在意元素顺序,能快速查找元素。其中就有一种常见方式:散列表。
散列表工作原理
散列表为每个对象计算出一个整数,称为散列码。根据这些计算出来的整数(散列码)保存在对应的位置上!即,散列码就是索引。
在Java中,散列表用的是链表数组实现的,每个列表称之为桶。
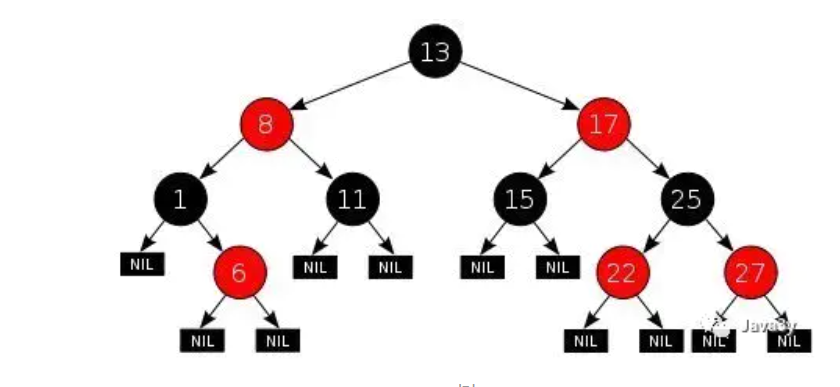
红黑树
是一种平衡二叉树,TreeSet、TreeMap底层都是红黑树来实现的。
二叉查找树也有个例(最坏)的情况(线性):
线性二叉查找树
上面符合二叉树的特性,但是它是线性的,完全没树的用处,树是要“均衡”才能将它的优点展示出来,比如下面这种:
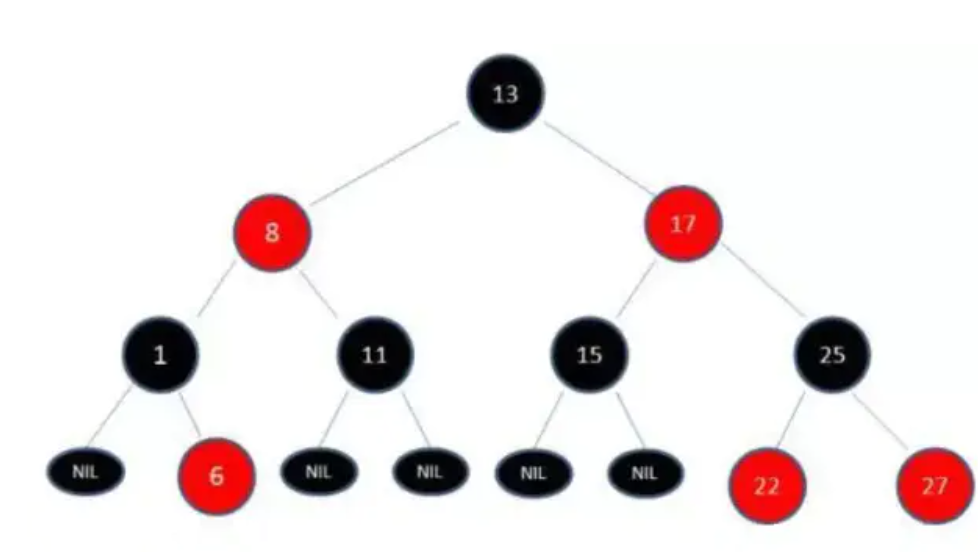
因此,就有了平衡树这么一个概念~红黑树就是一种平衡树,它可以保证二叉树基本符合均衡的金字塔结构。
上图就是一个红黑树,红黑树就字面上的意思,有红色的节点,有黑色的节点。
性质1. 节点是红色或黑色。
性质2. 根节点是黑色。
性质3. 每个叶节点(NIL节点,空节点)是黑色的。
性质4. 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
性质5. 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。

若有收获,就点个赞吧
0 人点赞
