在MySQL中Limit有两种语法:
- limit offset, rows
- limit rows
一般我们在分页查询的时候,rows不会太大,因为rows表示每页要显示的数量(你总不可能每页要显示个几万条吧)。而随着页数的加深,offset就会变大,查询效率随之就变慢了。
为什么当offset很大时,查询效率会变慢呢?
比如当我们用 limit 1000000, 10 的时候,MySQL会先扫描满足条件的1000010行,扔掉前面的1000000行,返回后面的10行。所以offset越大的时候,扫描的行就越多,效率也就越慢了。
我们先准备一张tb_test表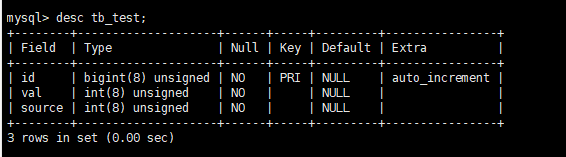
表中有1000+W行数据
mysql> select count(*) from tb_test;+----------+| count(*) |+----------+| 11075415 |+----------+1 row in set (1.15 sec)
我们先试一下 最常规的写法
select * from tb_test where val = 4 limit 100000, 5;
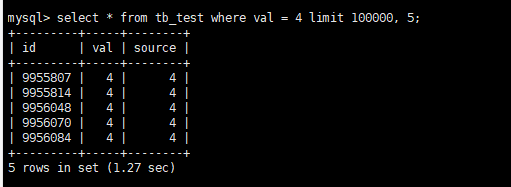
耗时1秒多,然后我们试试两种优化方案。
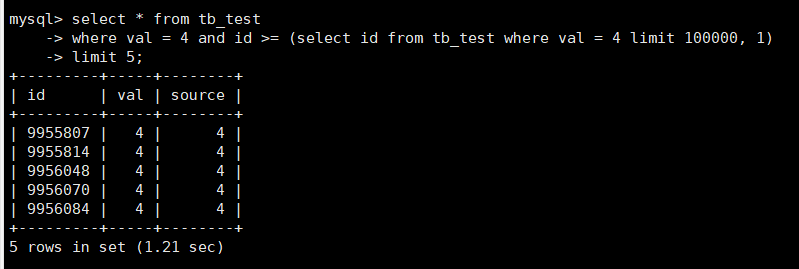
如果主键id是有序的,可以用子查询来优化
select * from tb_testwhere val = 4 and id >= (select id from tb_test where val = 4 limit 100000, 1)limit 5;
如果主键id是无序的,可以用inner join来优化
select t.* from tb_test t inner join (select id from tb_test where val = 4 limit 100000, 5) tmp on t.id = tmp.id;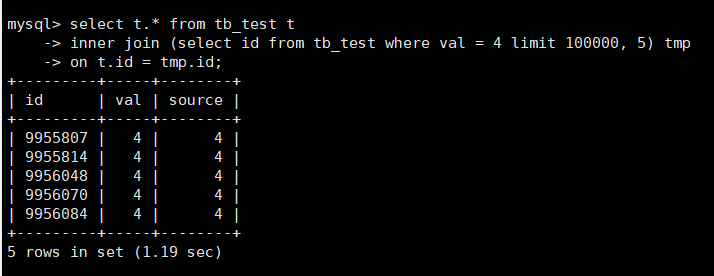
好像优化的SQL查询效率也没提高多少啊???
别急,接下来我们给val字段添加上索引,再来测试一下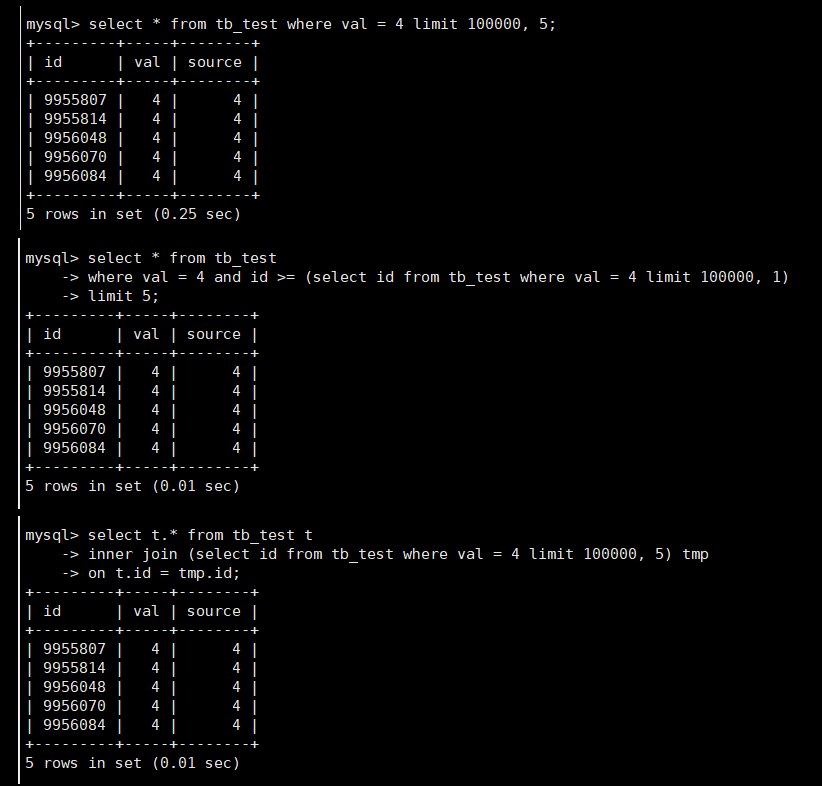
效率差距立马就体现出来了有木有。
所以我们可以得出结论:如果要优化limit查询的话,where条件中的字段一定要有索引。
PS:如果是手机端的话,我们可以让前端每次都把当前页的最大id(或者最小id)传过来,我们的查询中就可以直接使用下面这样的SQL语句
select * from tb_test where id > ? and val = ? limit 5
这种SQL语句在id是有序且不会跳页的业务场景下是非常合适的,但是PC端一般是允许跳页的,就不太合适了

若有收获,就点个赞吧
0 人点赞
