在以前,我想判断符合某个条件的数据是否存在时,都是使用count(*) 查询出记录数量,然后在在业务代码中通过 count > 0 来判断是否存在。但是count(*) 是会统计多行数据的,我们只是希望判断有没有数据,而不需要知道多少条数据,这时候用 count(*) 似乎有点浪费性能。后来在网上看到说用 limit 1 来优化count(*) 的性能,乍一看感觉蛮有道理的,但是!!!实际查询一下就发现不对劲了。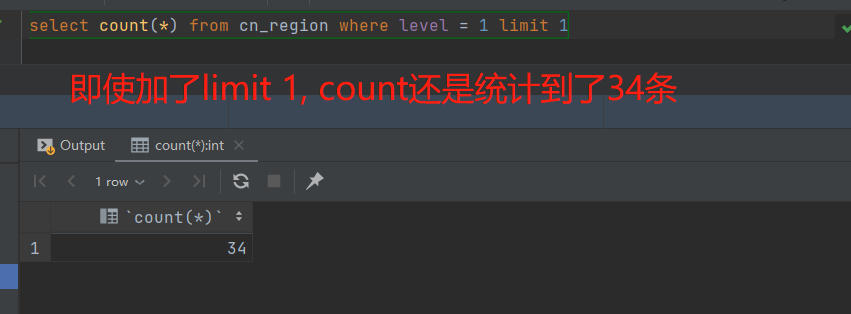
然后我们通过 explain 来看下这条sql的执行情况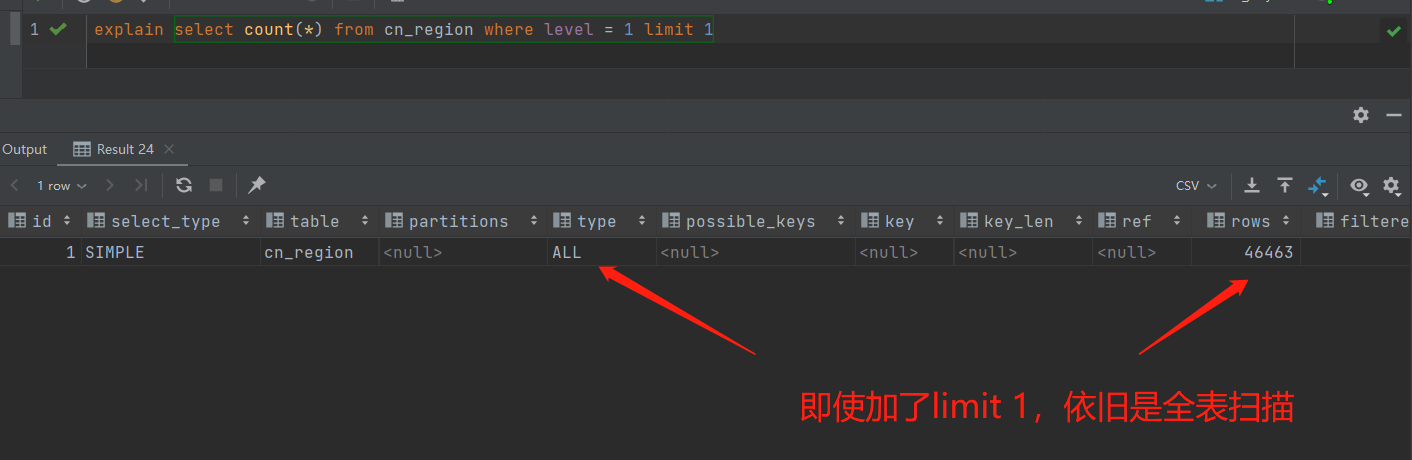
坑爹呢,这limit 1 加了也没用啊!!!
其实稍微分析一下就能明白,limit 1 影响的是返回结果的行数,而 count(*) 返回结果正好就是一行,所以limit 1 其实对于 count(*) 来说是根本没有意义的
如果我们只是想判断记录是否存在的话,其实可以通过
select 1 from table where field = 'xxx' limit 1
然后再业务代码中判断返回值是否为null,如果为null 的话,就说明不存在。

若有收获,就点个赞吧
0 人点赞
