内存回收
内存泄漏是指当一块内存不再被应用程序使用的时候,由于某种原因,这块内存没有返还给操作系统或者内存池的现象。内存泄漏可能会导致应用程序卡顿或者崩溃。
质量低下的程序可能造成内存泄漏,了解 JS 垃圾回收的机制,可以知道哪些情况下会造成内存泄漏,从而避免不良的编程习惯。
垃圾回收
JavaScript 中内存回收是自动的。当对象不被引用或者从根(JavaScript 的根可以理解为全局对象)开始不能被访问到时,就被当作垃圾在某个时间点被回收。JavaScript 运行垃圾回收时,其它程序是暂停执行的。
GC算法
GC 是一种机制,它里面的垃圾回收器完成具体的工作:查找垃圾释放空间、回收空间。算法就是工作时查找和回收所遵循的规则。
引用计数算法
引用计数算法顾名思义就是通过设置对象的引用数来判断其是否垃圾,当对象的引用关系发生改变时,计数器就修改引用的数字,如果引用数变为 0 则立即回收。
优点是在发现垃圾的时候能立即进行回收,最大程度减少程序卡顿。缺点是无法回收循环引用的对象,另外时间开销较大(得给每个对象开一个计数器,当监控到对象引用数变化时需要修改引用计数器的数字)。
// 循环引用function foo () {const obj1 = {}const obj2 = {}obj1.name = obj2obj2.name = obj1}

标记清除算法
分为标记和清除两步,标记就是遍历所有对象标记活动对象,然后再遍历所有对象把非活动对象
(没有标记的对象)清除,回收空间。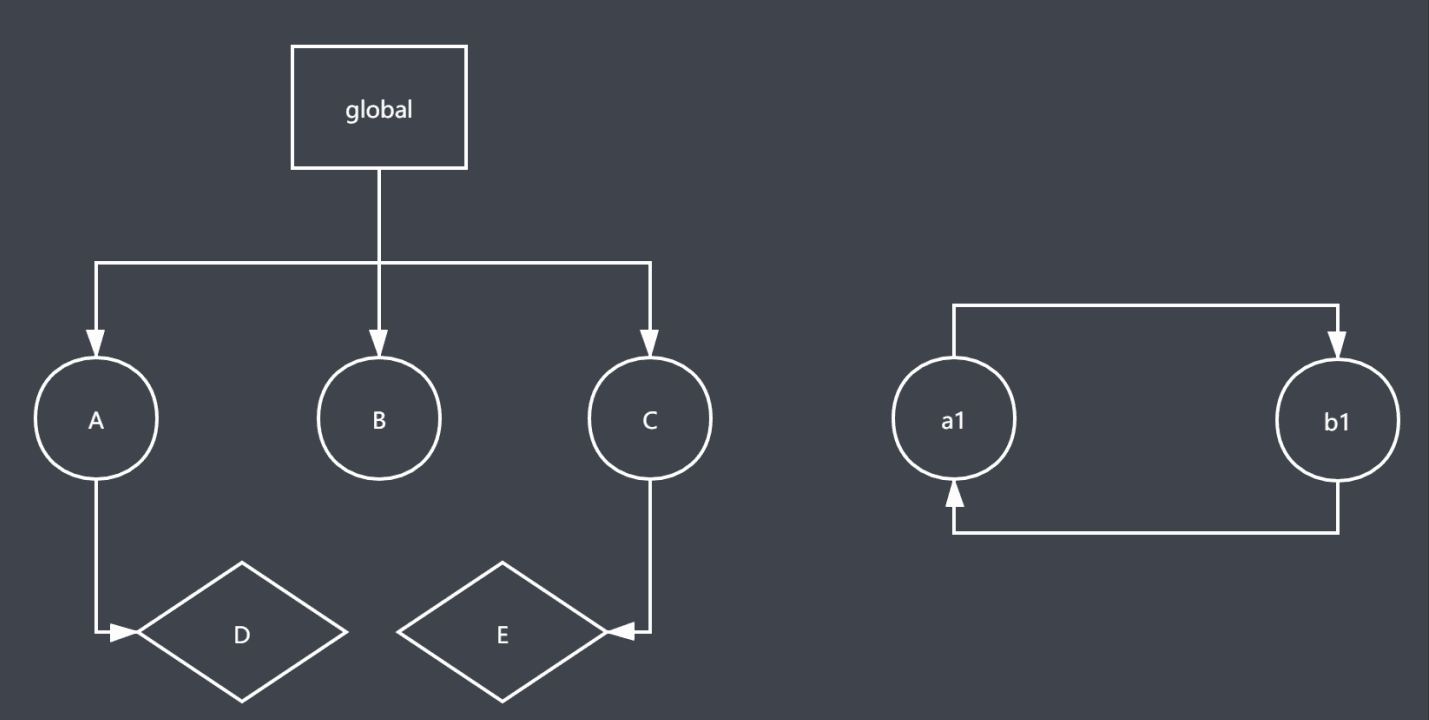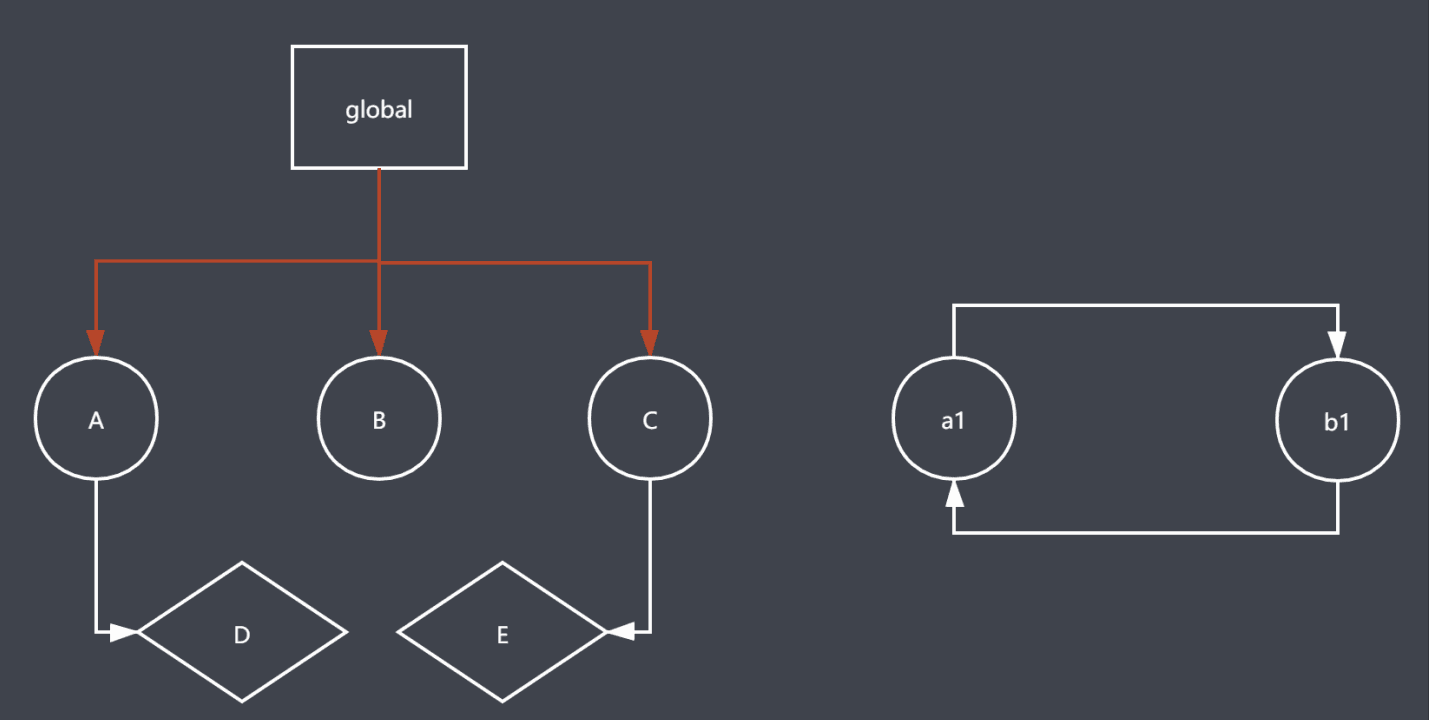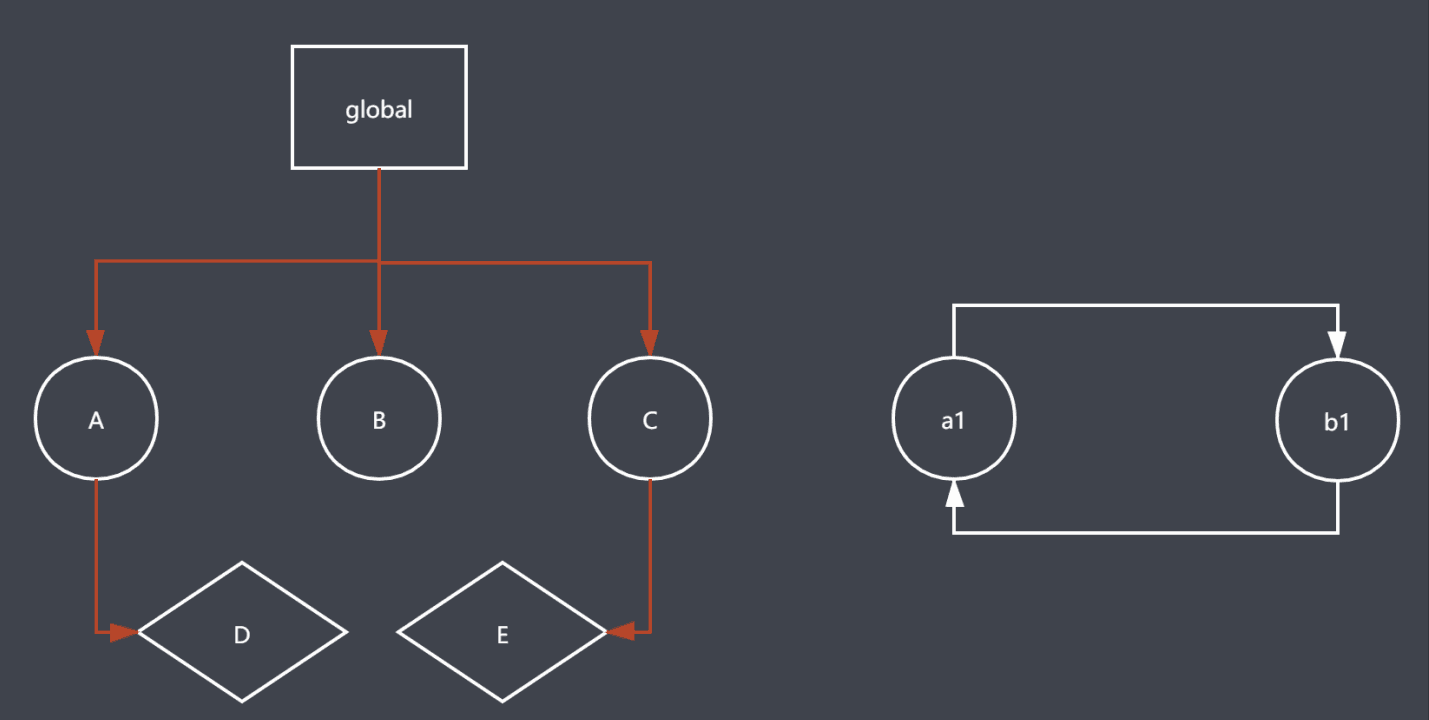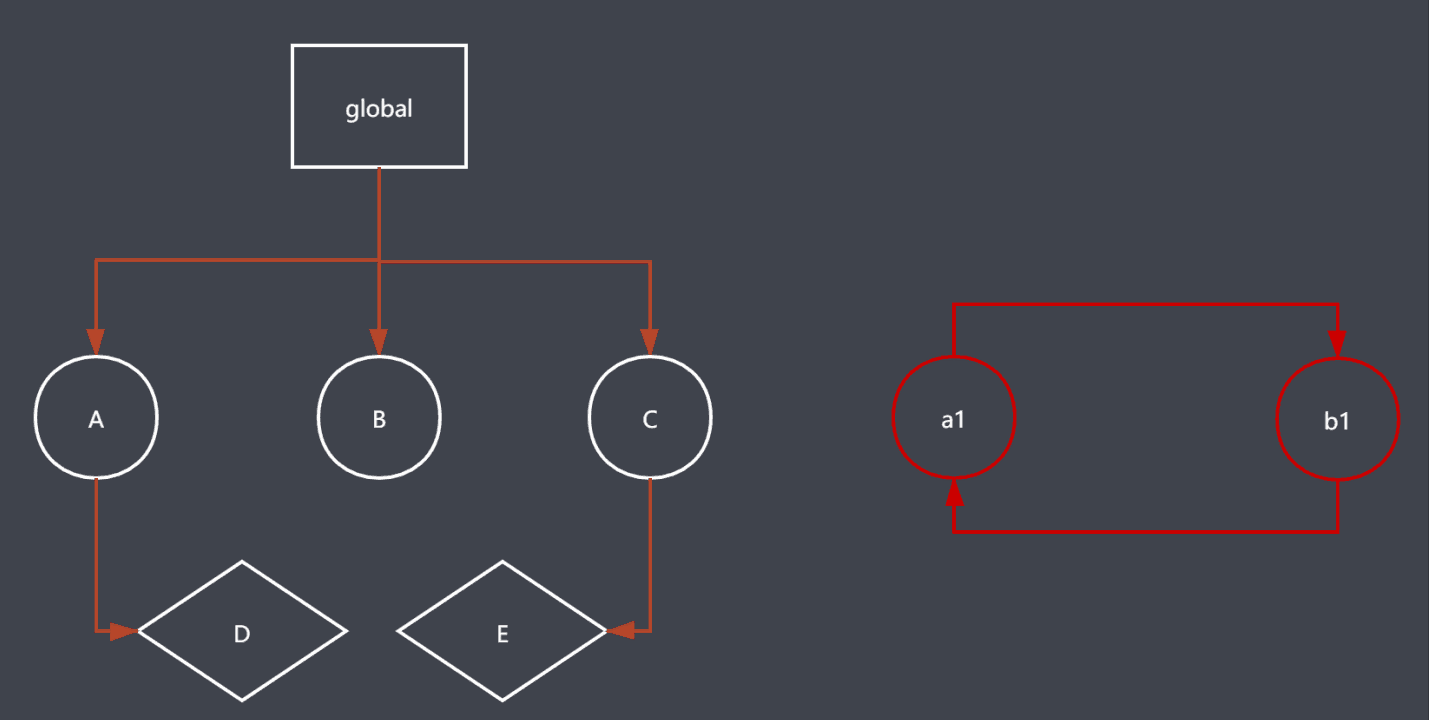
优点是能解决循环引用的问题。
缺点是容易产生碎片化的空间;回收不是立即执行。
标记整理算法
标记整理算法是标记清除算法的增强算法,它同样会标记活动对象,但是清理时先会移动对象在内存上的位置,把活动对象和非活动对象各自放在一片连续的空间。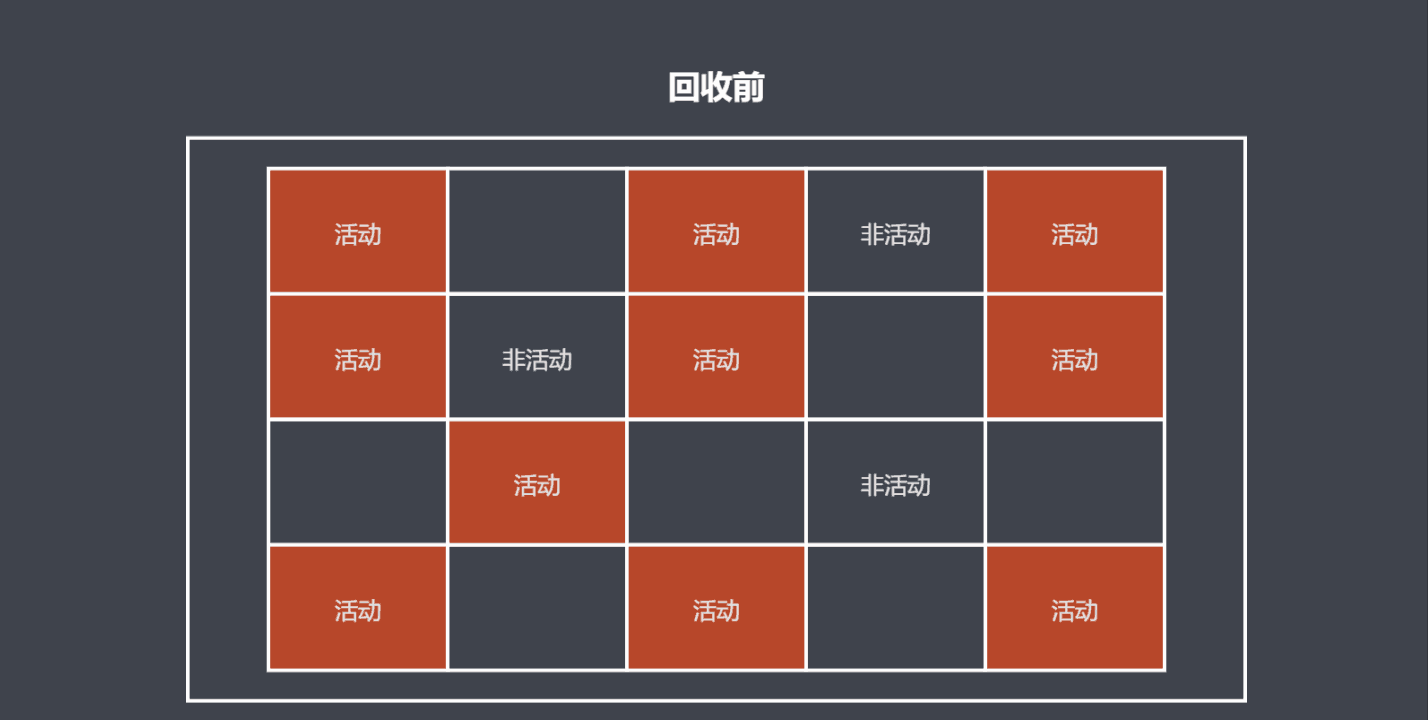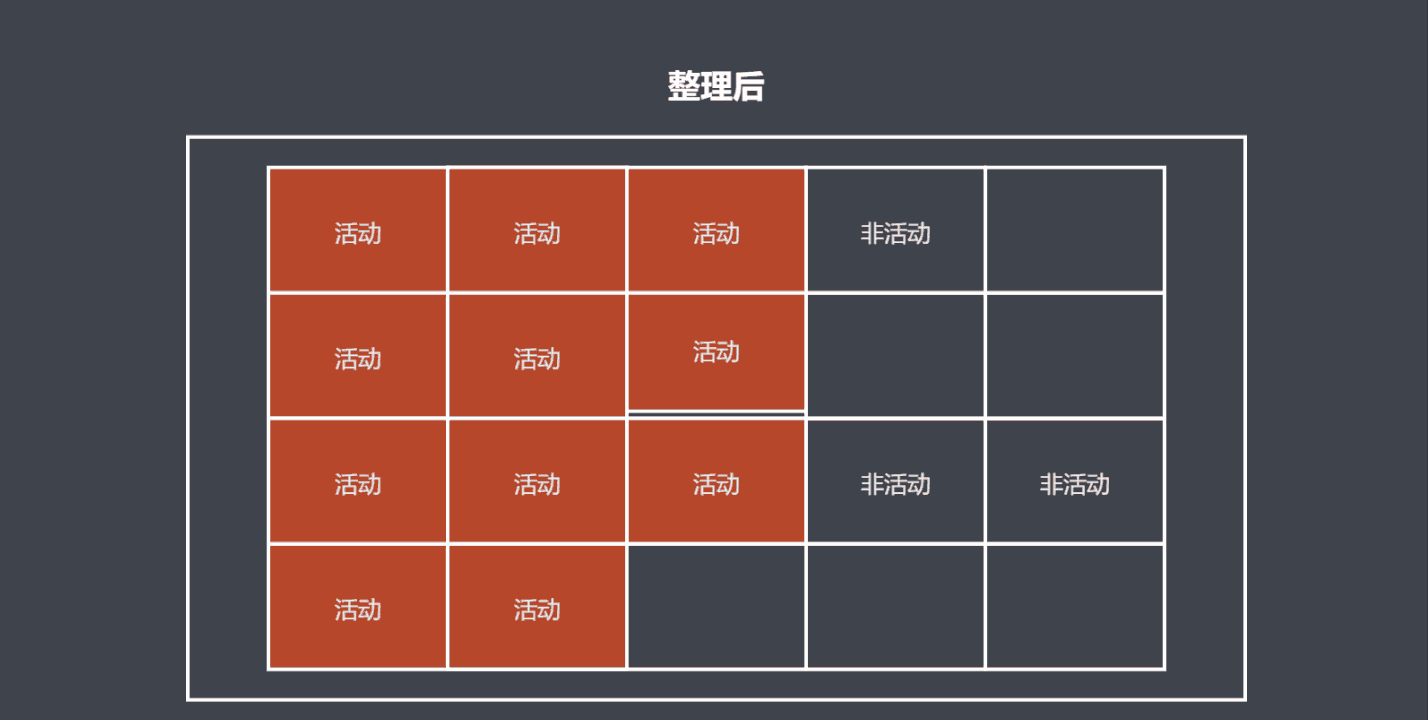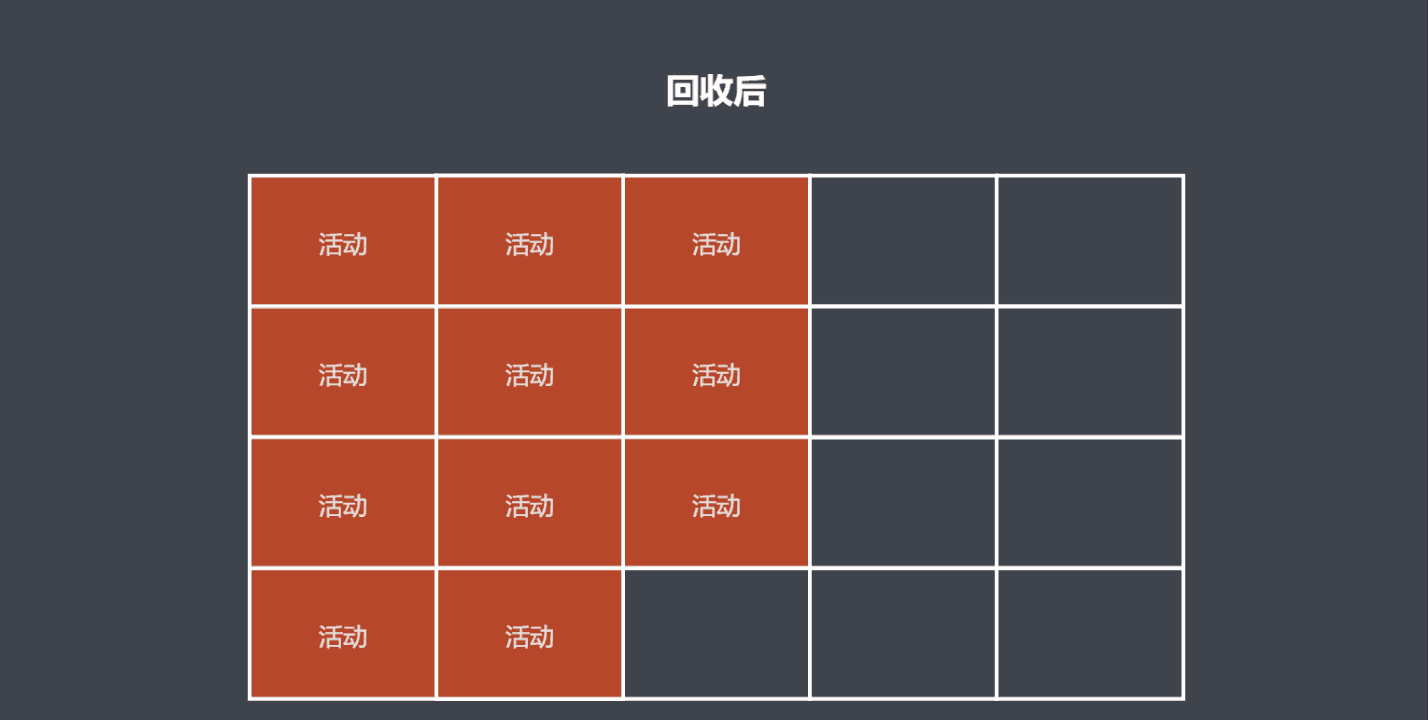
优点是避免了空间碎片化。
缺点是不会立即执行回收,并且由于需要移动对象,回收的效率较慢。
V8 引擎
V8 引擎是一款主流的执行 JavaScript 执行引擎。采用即时编译,设置了内存上限。
垃圾回收策略
V8 垃圾回收采用分代回收的思想,把内存分为新生代和老生代。新生代空间较小,64位系统是 32M,32位系统是 16M,平分给使用空间 From 和空闲空间 To。老生代空间较大,64位系统上限是 1.4G,32位上限是 700M。
常用 GC算法有分代回收、空间复制、标记清除、标记整理、标记增量。
新生代
新生代指的是存活时间较短的对象,比如一个局部作用域的对象。新生代回收用的算法是复制算法 + 标记整理。活动对象存储于 From,标记整理后将活动对象拷贝到 To,From 释放所有空间,变成 To 空间,原来的 To 空间现在变成 From 空间。
拷贝的过程中可能出现晋升,即新生代对象转移至老生代。经过一轮 GC 回收还存活的对象就需要晋升。如果 To 空间占用率达到 25%,就需要将所有活动对象晋升。
新生代区域垃圾回收是使用空间来换取时间。(复制算法,有空闲空间)
老生代
老生代回收主要采用标记清除、标记整理、增量标记算法。首先使用标记清除完成空间回收,虽然会产生碎片化空间,但是整体速度更快。当新生代对象晋升,老生代空间又不足以存放晋升对象时,会标记整理进行空间优化。
增量标记算法是对垃圾回收过程的效率优化。它把一整段的垃圾回收过程拆分成几个步骤,和主程序交叉进行,使得用户在引擎进行垃圾回收的时候也感觉不到主程序暂停或卡顿。
工作流程
此处只讨论 V8引擎在浏览器中的应用。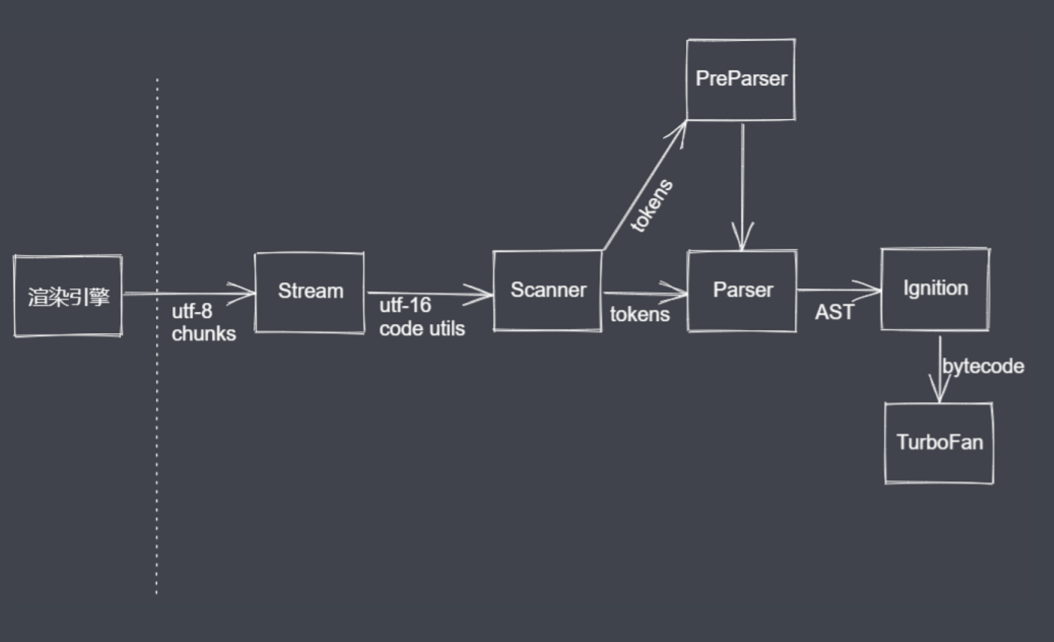
V8引擎是浏览器渲染引擎里,一个用于执行 JS 代码的部分。
Scanner 是扫描器,对 JS 代码进行词法分析,生成 tokens。
const username = "alishi"
上面的 JS 代码经过 Scanner 词法分析后生成的数据大概的结构就是:
[{"type": "Keyword","value": "const"},{"type": "Identifier","value": "username"},{"type": "Punctuator","value": "="},{"type": "String","value": "alishi"}]
Parser 是一个解析器,Scanner 词法分析后的 tokens 传给 Parser,Parser 解析的过程就是一个语法校验、语法分析的过程,解析的结果是语法树 AST(Abstract Syntax Tree)。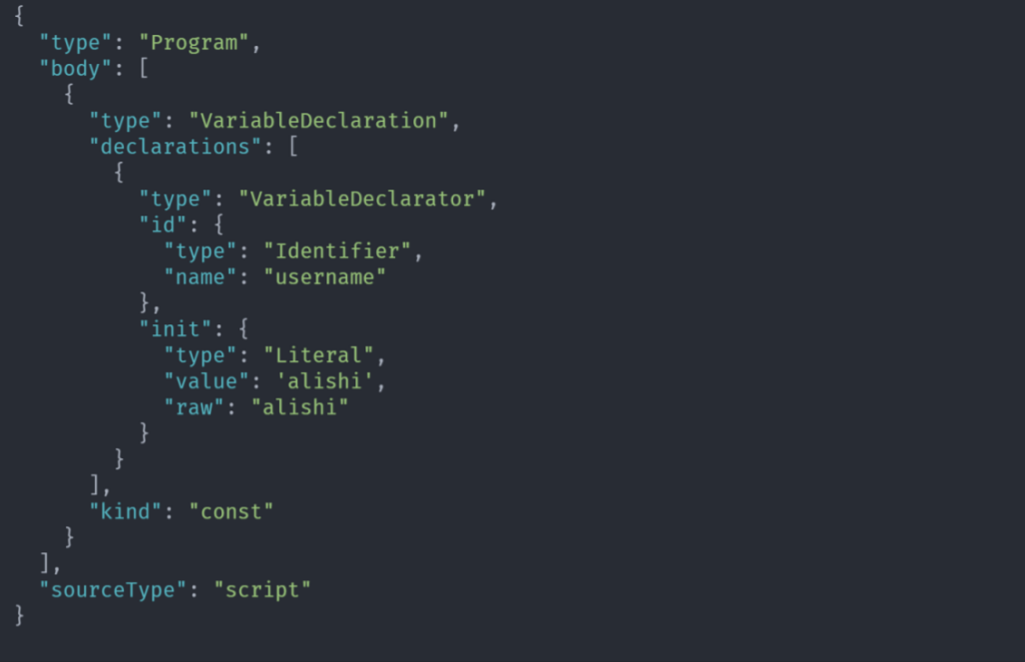
Parser 有两种解析过程,一种是 Parser,即全量解析;另一种是 PreParser,即预解析。
对于未使用的代码采用的是预解析,它不生成 AST,创建无变量引用和声明 scopes,依据规范抛出特定的错误,预解析的速度更快。
对于使用的代码采用全量解析,生成 AST,构建具体 scopes 信息,变量引用,声明等。并且抛出所有语法错误。
// 声明时未调用,被认为是吧不被执行的代码,采用预解析function foo () {console.log('foo')}// 声明时未调用,被认为是吧不被执行的代码,采用预解析function f2 () {console.log('f2')}// 函数立即执行,只进行一次全量解析(function bar() {console.log('bar')})()// 调用 foo,此时对 foo 重新进行一次全量解析foo()
Ignition 是 V8引擎提供的解释器,拿到 Parser 传过来的语法树后它就进行预编译,生成字节码。
TurboFan 是 V8引擎提供的编译器模块,它把字节码转换为汇编代码,之后就可以开始执行代码了,也就是执行堆栈执行过程
堆栈处理
相关概念
- JS 执行环境:就是在哪里运行,浏览器、Node等。
- 执行上下文 EC:有全局执行上下文 EC(G) 和函数执行上下文,还有 eval 上下文(一般不使用)。全局执行上下文只有一个,在 JS 执行过程中,它一直处于执行环境栈栈底;函数执行上下文可以存在无数个,函数被调用时就会创建一个函数执行上下文,被重复调用也会创建新的上下文。
- 执行环境栈 EC Stack(Execution Context Stack):也叫调用栈(Call Stack)、执行上下文栈,执行环境申请的一片内存空间,用于 JS 执行过程所创建的所有上下文,最开始会压入全局执行上下文,之后每次有函数调用都会压入一个新创建的函数执行上下文。
- SCOPE:作用域。
- VO:变量对象,全局变量对象是 VO(G)。
- AO:活动对象。可以看作在私有的上下文中存在的 VO。
- GO:全局对象。它是对象,因此也会有一个内存的空间地址。它在页面开始加载时创建出来,对象有许多属性和 API,VO(G) 中 window 指向这个对象,所以 window 就是全局对象。
- var 声明的全局变量会挂载到 window 对象身上。
基本类型处理
var x = 100var y = xy = 200console.log(x)/*** 01 基本数据类型是按值进行操作* 02 基本数据类型值是存放在 栈区的* 03 无论我们当前看到的栈内存,还是后续引用数据类型会使用的堆内存都属于计算机内存* 04 GO(全局对象)*/
这里的 x,y 都是全局变量。
值得注意的是,在栈中先创建的是值而不是变量。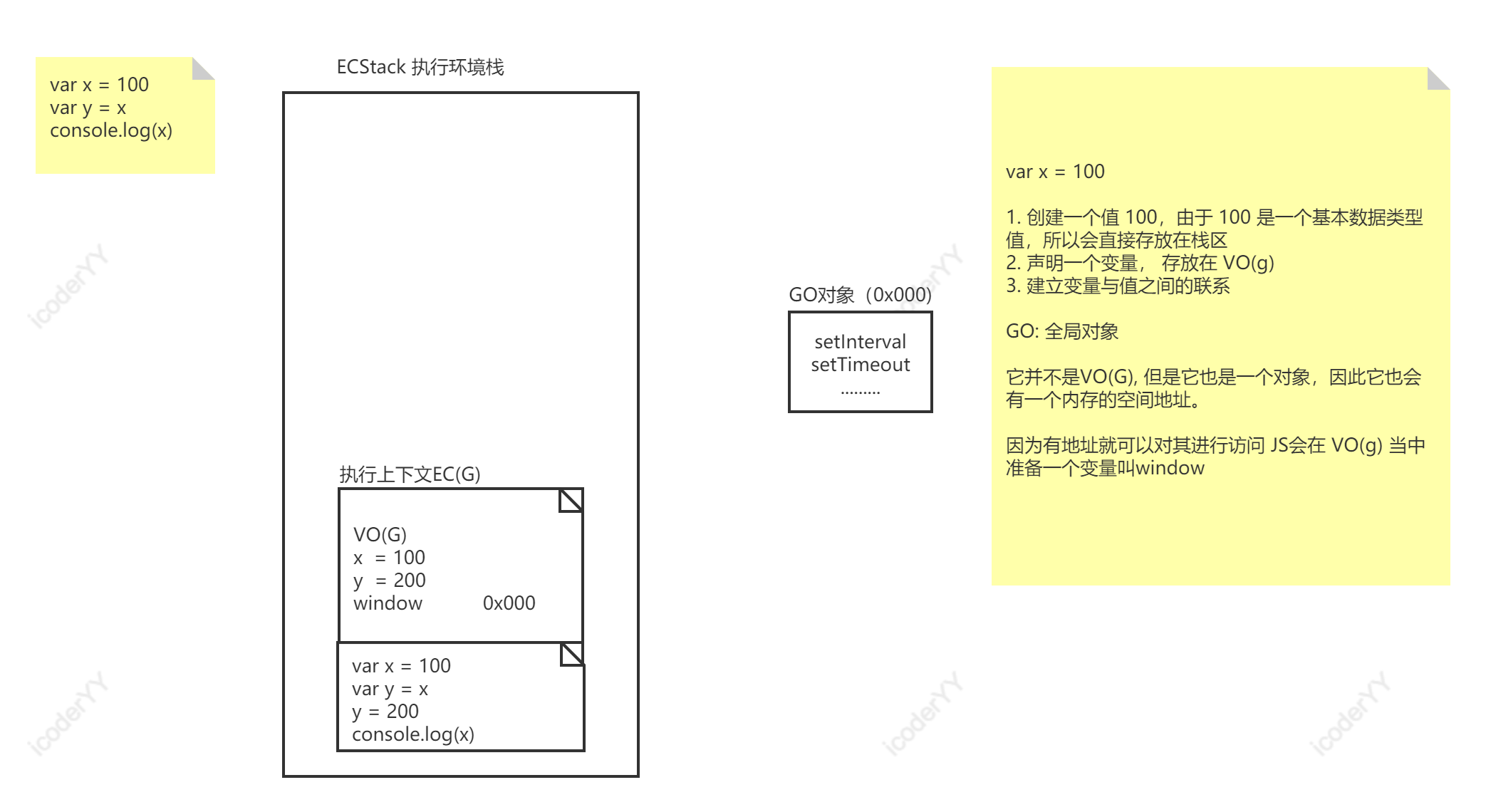
引用类型处理
var a = 1var b = a = 3// 第 2 行等同于 var a = 3; var b = a
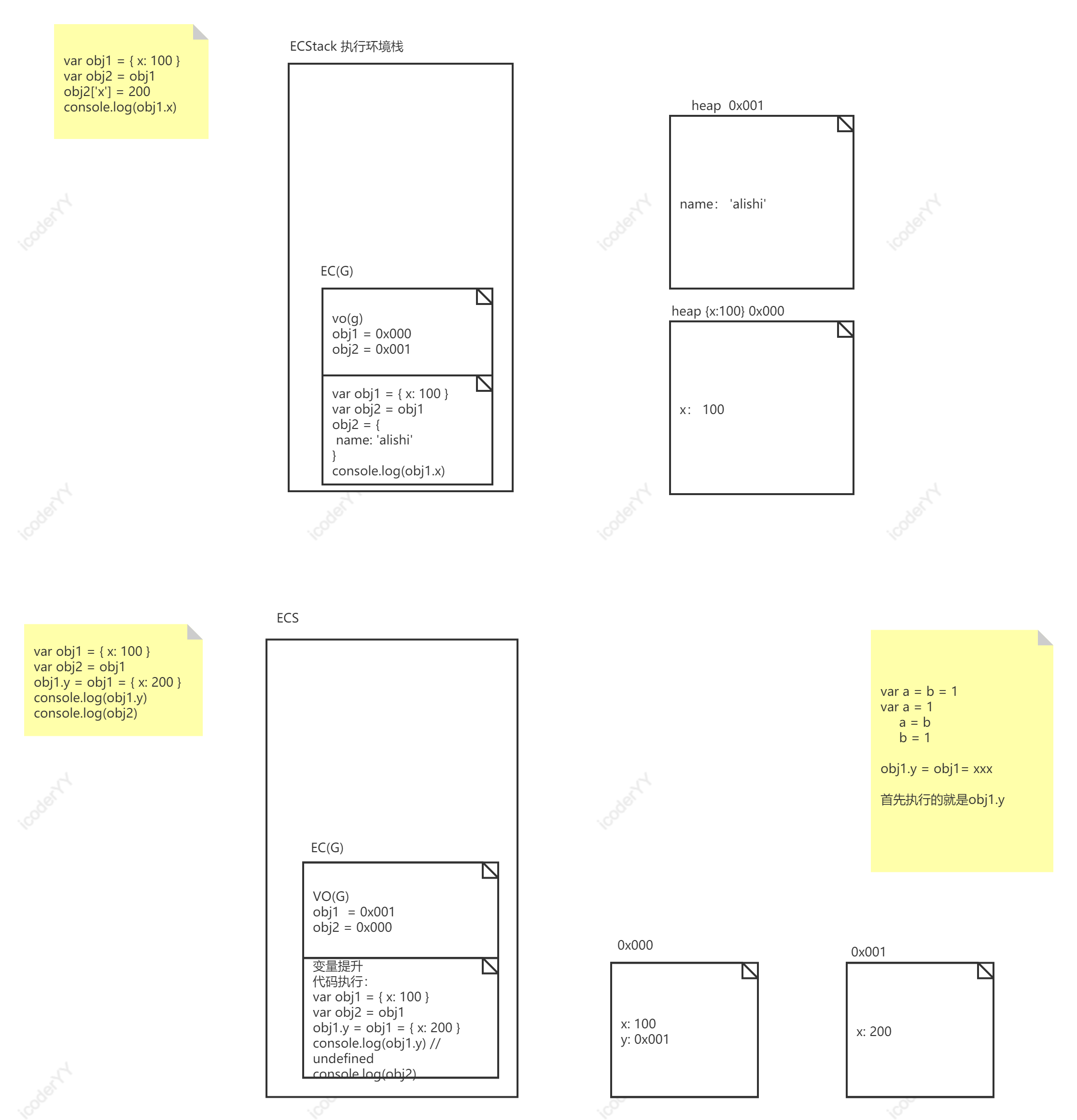
var obj1 = { x: 100 }var obj2 = obj1obj1.y = obj1 = { x: 200 }console.log(obj1.y)console.log(obj2)
连续赋值语句的执行顺序是从右往左,但是:在执行一个赋值操作时,我们首先要取出=左侧的变量,用来确定这次赋值操作最终结果的存放位置。然后运算=右侧的表达式来获取最终的结果,并将结果存放入对应的位置,也就是前边取出的变量所对应的位置。obj1.y = obj1 = {x: 200},这里拆出来先执行的是取出obj1.y的位置,但是obj1 = {x:100},所以会执行 obj1.y = undefined,这时 obj1 存储的地址是 0x000,所以 y 属性就放在这个地址。
然后是在堆中创建对象{x: 200},假设该对象在堆中的地址是 0x001,之后就是从右到左的顺序:obj1 = 0x001,obj1.y = 0x001。
需要注意,连续赋值语句里obj1.y的 y 存储在 0x000。打印 obj1.y,访问到的是 0x001 上的 y 属性,但是这个地址上没有,所以打印出 undefined。
函数处理
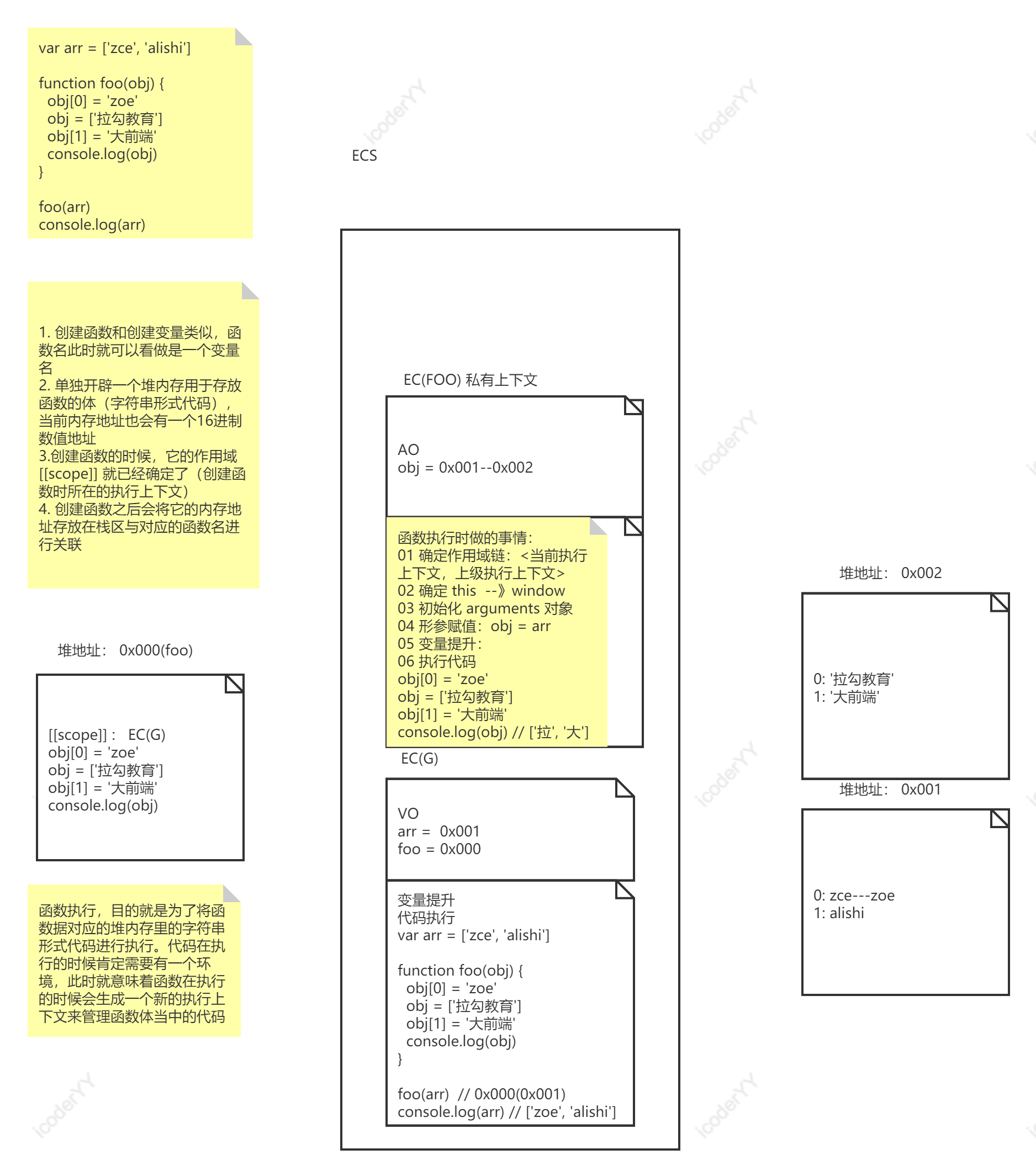
函数创建过程:
- 将函数名存储在栈中,存放在 VO 当中,同时它的值就是函数体存储的堆内存地址。
- 函数本身也是一个对象,创建时会有一个内存地址,空间内存放的就是函数体代码(字符串形式的)。
- 函数创建时,它的作用域已经确定了。
函数执行过程:函数执行时会形成一个全新私有上下文,它里面有一个AO 用于管理这个上下文当中的变量。
- 确定作用域链 <当前执行上下文, 上级作用域所在的执行上下文>
- 确定 this
- 初始化 arguments 对象
- 形参赋值,它就相当于是变量声明,然后将声明的变量放置于 AO
- 变量提升 var 和 function
- 代码执行
var arr = ['zce', 'alishi']function foo(obj) {obj[0] = 'zoe'obj = ['拉勾教育']obj[1] = '大前端'console.log(obj)}foo(arr)console.log(arr)/*** 01 函数创建* -- 可以将函数名称看做是变量,存放在 VO 当中 ,同时它的值就是当前函数对应的内存地址* -- 函数本身也是一个对象,创建时会有一个内存地址,空间内存放的就是函数体代码(字符串形式的)* 02 函数执行* -- 函数执行时会形成一个全新私有上下文,它里面有一个AO 用于管理这个上下文当中的变量* -- 步骤:* 01 作用域链 <当前执行上下文, 上级作用域所在的执行上下文>* 02 确定 this* 03 初始化 arguments (对象)* 04 形参赋值:它就相当于是变量声明,然后将声明的变量放置于 AO* 05 变量提升* 06 代码执行*/
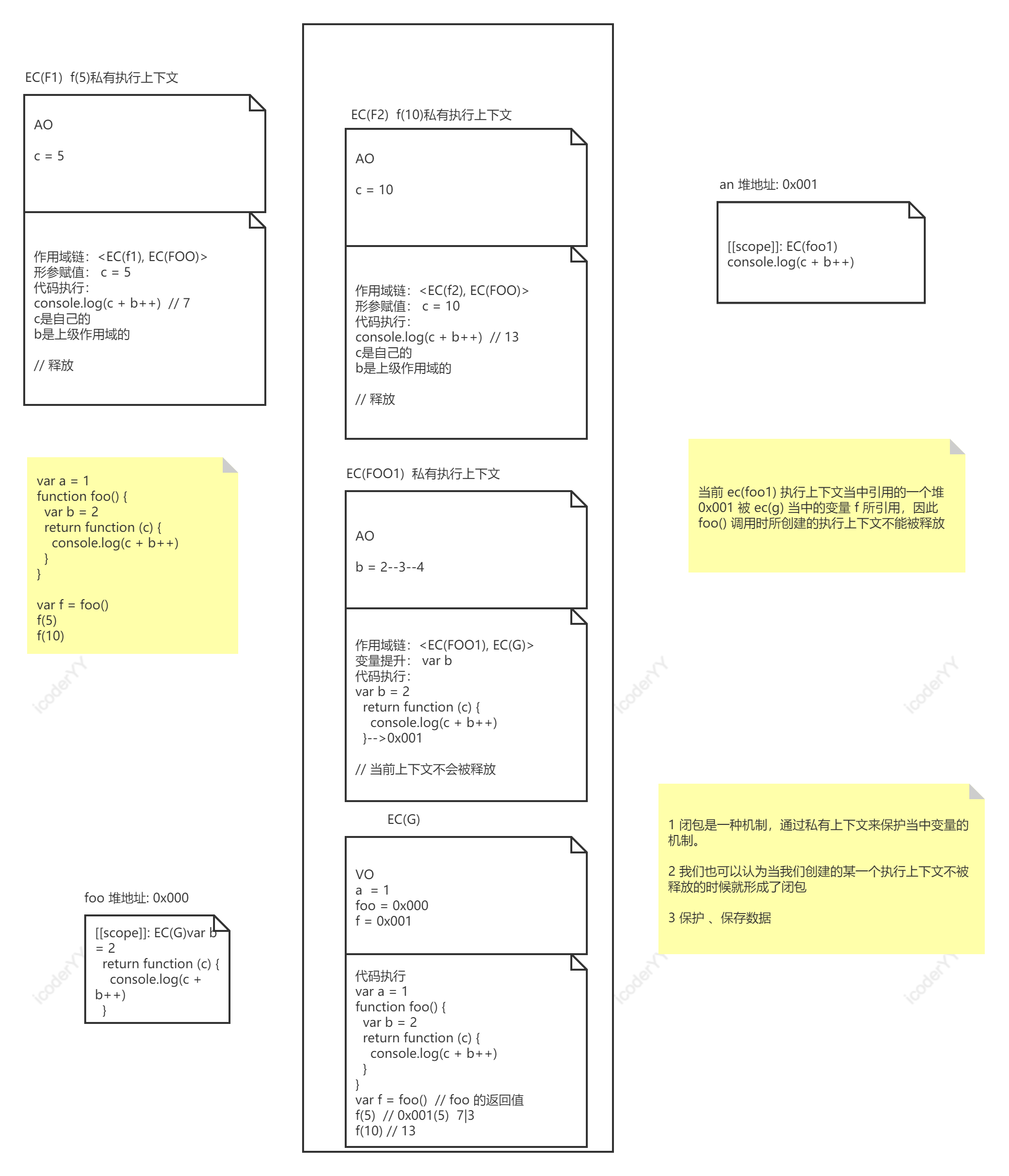
闭包处理
var a = 1function foo() {var b = 2return function (c) {console.log(c + b++)}}var f = foo()f(5)f(10)/*** 01 闭包: 是一种机制:* 保护:当前上下文当中的变量与其它的上下文中变量互不干扰* 保存:当前上下文中的数据(堆内存)被当前上下文以外的上下文中的变量所引用,这个数据就保存下来了* 02 闭包:* 函数调用形成了一个全新的私有上下文,在函数调用之后当前上下文不被释放就是闭包(临时不被释放)*/
垃圾回收
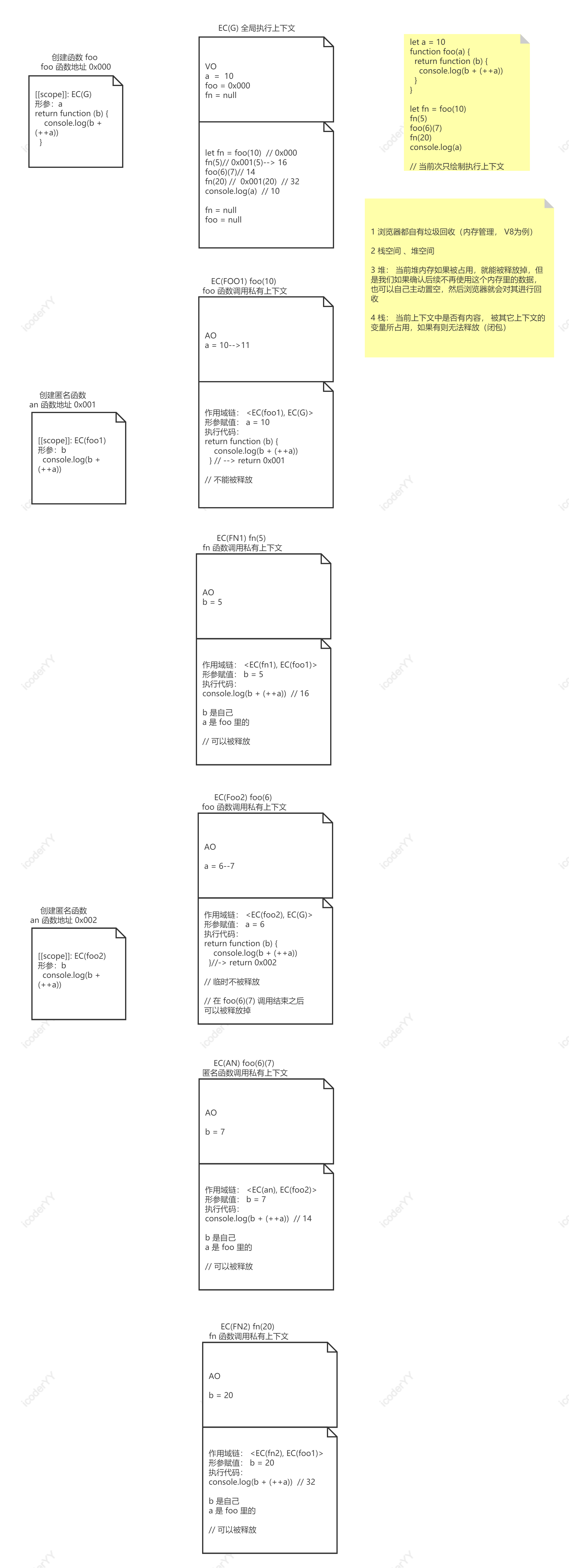
let a = 10function foo(a) {return function (b) {console.log(b + (++a))}}let fn = foo(10)fn(5)foo(6)(7)fn(20)console.log(a)
循环添加事件实现
模拟对 DOM 上的多个按钮循环添加点击事件。
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>循环添加事件</title></head><body><button index='1'>按钮1</button><button index='2'>按钮2</button><button index='3'>按钮3</button><script>var aButtons = document.querySelectorAll('button')// 基础// for (var i = 0; i < aButtons.length; i++) {// aButtons[i].onclick = function () {// console.log(`当前索引值为${i}`)// }// }/*** 闭包* 事件委托*/// for (var i = 0; i < aButtons.length; i++) {// (function (i) {// aButtons[i].onclick = function () {// console.log(`当前索引值为${i}`)// }// })(i)// }// for (var i = 0; i < aButtons.length; i++) {// aButtons[i].onclick = (function (i) {// return function () {// console.log(`当前索引值为${i}`)// }// })(i)// }// for (let i = 0; i < aButtons.length; i++) {// aButtons[i].onclick = function () {// console.log(`当前索引值为${i}`)// }// }/*** 自定义属性*/// for (var i = 0; i < aButtons.length; i++) {// aButtons[i].myIndex = i// aButtons[i].onclick = function () {// console.log(`当前索引值为${this.myIndex}`)// }// }/*** 事件委托*/// document.body.onclick = function (ev) {// var target = ev.target,// targetDom = target.tagName// if (targetDom === 'BUTTON') {// var index = target.getAttribute('index')// console.log(`当前点击的是第 ${index} 个`)// }// }</script></body></html>
性能优化手段
JS 性能测试网站:JSBench.me
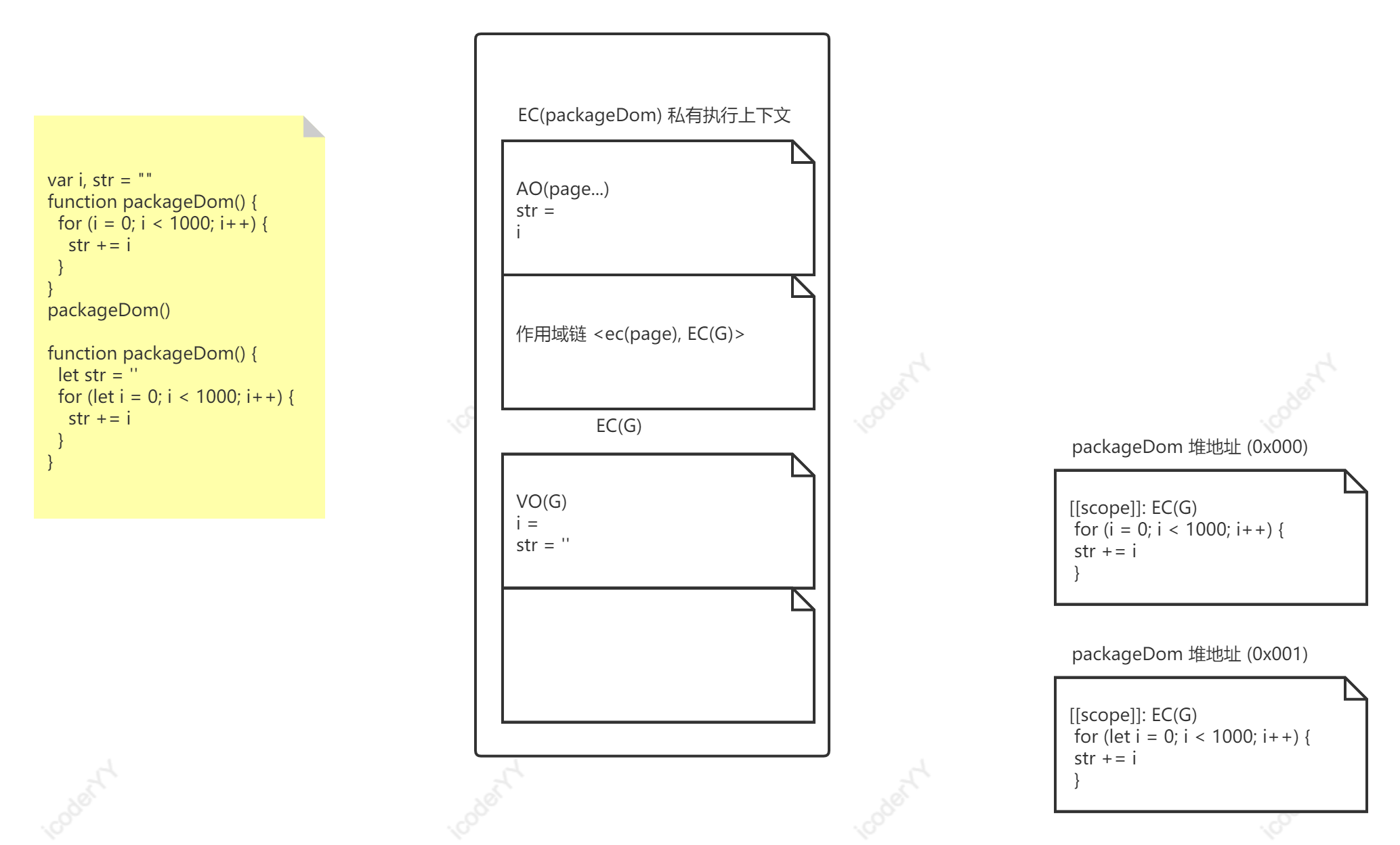
变量局部化
寻找变量的时候,会沿着作用域链逐层往上查找,如果当前作用域没有找到,就往上找,而往上找所花费的时间自然会更多。变量局部化就是把变量定义在当前作用域,避免往上查找。
var i, str = ""function packageDom() {// 往上,即全局作用域找 ifor (i = 0; i < 1000; i++) {// 往上找 strstr += i}}packageDom()// 这个更快function packageDom() {// str 在当前作用域let str = ''// i 也在当前作用域for (let i = 0; i < 1000; i++) {str += i}}packageDom()
缓存数据
假设有一个对象的属性值需要被频繁的使用到,那么可以定义一个变量来保存这个值。
如果不是频繁使用的值,那么就不必定义变量,减少声明和语句的数量也是可以提高速度的。
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>缓存数据</title></head><body><div id="skip" class="skip"></div><script>// 缓存数据:对于需要多次使用的数据进行提前保存,后续进行使用var oBox = document.getElementById('skip')// 假设在当前的函数体当中需要对 className 的值进行多次使用,那么我们就可以将它提前缓存起来function hasClassName(ele, cls) {console.log(ele.className)return ele.className == cls}console.log(hasClassName(oBox, 'skip'))function hasClassName(ele, cls) {var clsName = ele.classNameconsole.log(clsName)return clsName == cls}console.log(hasClassName(oBox, 'skip'))/*01 减少声明和语句数(词法 语法)02 缓存数据(作用域链查找变快)*/</script></body></html>
减少访问层级
像下面的代码,第二个 Person 把 age 的访问封装成一个 get 方法,获取 age 比起第一个多通过一层函数,这样就多了一次进栈出栈的操作,并且在堆中多开了。
// 更快function Person() {this.name = 'zce'this.age = 40}let p1 = new Person()console.log(p1.age)function Person() {this.name = 'zce'this.age = 40this.getAge = function () {return this.age}}let p1 = new Person()console.log(p1.getAge())
防抖与节流
在一些高频率时间触发的场景下我们不希望对应的事件处理函数多次执行,例如鼠标滚动、输入的模糊匹配、轮播图切换、点击操作等。浏览器默认会有监听事件间隔(大约4-6ms),如果检测到多次事件的监听执行,那么就会造成不必要的浪费。
假设页面上有一个按钮,我们可以连续点击。
对于这个高频的操作来说,我们只希望识别一次点击,可以认为是第一次或最后一次,这个就叫做防抖。
对于高频操作,我们可以自己来设置频率,让本来会执行很多次的事件触发,按着我们定义的频率来减少触发的次数。
防抖函数
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>防抖函数实现</title></head><body><button id="btn">点击</button><script>var oBtn = document.getElementById('btn')// oBtn.onclick = function () {// console.log('点击了')// }/*** handle 最终需要执行的事件监听* wait 事件触发之后多久开始执行* immediate 控制执行第一次还是最后一次,false 执行最后一次*/function myDebounce(handle, wait, immediate) {let i = 1;console.info(i + 1)// 参数类型判断及默认值处理if (typeof handle !== 'function') throw new Error('handle must be an function')if (typeof wait === 'undefined') wait = 300if (typeof wait === 'boolean') {immediate = waitwait = 300}if (typeof immediate !== 'boolean') immediate = false// 所谓的防抖效果我们想要实现的就是有一个 ”人“ 可以管理 handle 的执行次数// 如果我们想要执行最后一次,那就意味着无论我们当前点击了多少次,前面的N-1次都无用let timer = nullreturn function proxy(...args) {let self = this,init = immediate && !timerclearTimeout(timer)timer = setTimeout(() => {timer = null!immediate ? handle.call(self, ...args) : null}, wait)// 如果当前传递进来的是 true 就表示我们需要立即执行// 如果想要实现只在第一次执行,那么可以添加上 timer 为 null 做为判断// 因为只要 timer 为 Null 就意味着没有第二次....点击init ? handle.call(self, ...args) : null}}// 定义事件执行函数function btnClick(ev) {console.log('点击了1111', this, ev)}// 当我们执行了按钮点击之后就会执行...返回的 proxyoBtn.onclick = myDebounce(btnClick, 200, false)// oBtn.onclick = btnClick() // this ev</script></body></html>
节流函数
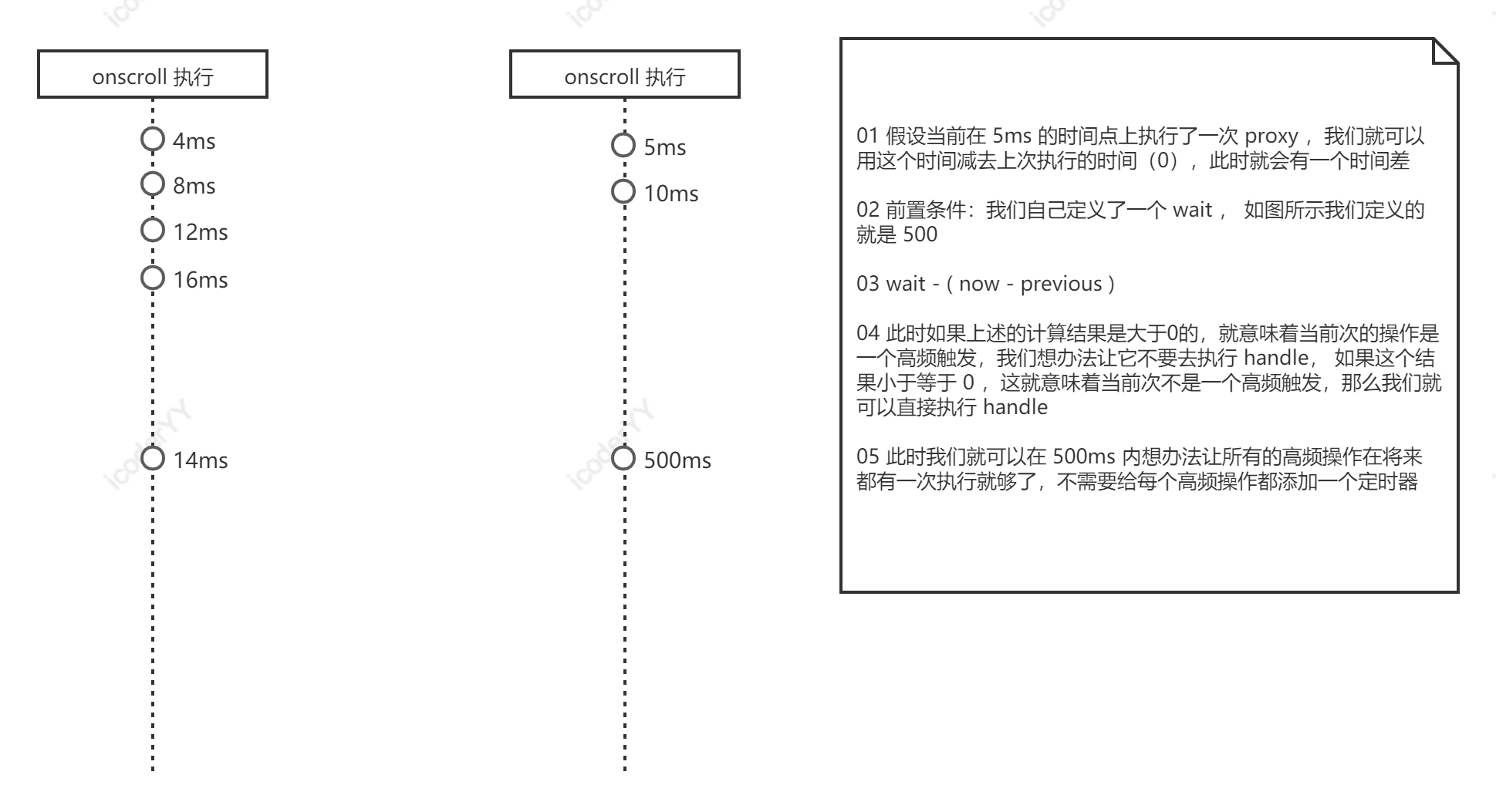
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>节流函数实现</title><style>body {height: 5000px;}</style></head><body><script>// 节流:我们这里的节流指的就是在自定义的一段时间内让事件进行触发function myThrottle(handle, wait) {if (typeof handle !== 'function') throw new Error('handle must be an function')if (typeof wait === 'undefined') wait = 400let previous = 0 // 定义变量记录上一次执行时的时间let timer = null // 用它来管理定时器return function proxy(...args) {let now = new Date() // 定义变量记录当前次执行的时刻时间点let self = thislet interval = wait - (now - previous)if (interval <= 0) {// 此时就说明是一个非高频次操作,可以执行 handleclearTimeout(timer)timer = nullhandle.call(self, ...args)previous = new Date()} else if (!timer) {// 当我们发现当前系统中有一个定时器了,就意味着我们不需要再开启定时器// 此时就说明这次的操作发生在了我们定义的频次时间范围内,那就不应该执行 handle// 这个时候我们就可以自定义一个定时器,让 handle 在 interval 之后去执行timer = setTimeout(() => {clearTimeout(timer) // 这个操作只是将系统中的定时器清除了,但是 timer 中的值还在timer = nullhandle.call(self, ...args)previous = new Date()}, interval)}}}// 定义滚动事件监听function scrollFn() {console.log('滚动了')}// window.onscroll = scrollFnwindow.onscroll = myThrottle(scrollFn, 600)</script></body></html>
减少判断层级
减少循环嵌套。
// 速度较慢function doSomething (part, chapter) {const parts = ['ES2016', '工程化', 'Vue', 'React', 'Node']if (part) {if (parts.includes(part)) {console.log('属于当前课程')if (chapter > 5) {console.log('您需要提供 VIP 身份')}}} else {console.log('请确认模块信息')}}doSomething('ES2016', 6)// 速度较快function doSomething (part, chapter) {const parts = ['ES2016', '工程化', 'Vue', 'React', 'Node']if (!part) {console.log('请确认模块信息')return}if (!parts.includes(part)) returnconsole.log('属于当前课程')if (chapter > 5) {console.log('您需要提供 VIP 身份')}}doSomething('ES2016', 6)
减少循环体活动
循环体内执行的语句越多,整体消耗的时间自然越多。
// 实际上每次循环都要获取数组的长度,如果数组很大,那么速度会慢得比较明显var test = () => {var ivar arr = ['zce', 38, '我为前端而活']for(i=0; i<arr.length; i++) {console.log(arr[i])}}test()// 把数组长度提取出来var test = () => {var ivar arr = ['zce', 38, '我为前端而活']var len = arr.lengthfor(i=0; i<len; i++) {console.log(arr[i])}}test()
字面量与构造式
构造式就是 new 的方式,通过构造函数去创建一个对象、变量、常量。比如创建一个数字变量let num = new Number(4)。
字面量指的是能够使用简单结构和符号创建对象的表达式。比如创建一个数字变量let num = 4。
字面量的优势在于它不用通过构造函数去创建,少做了函数的调用的步骤,少了一次函数执行上下文进出栈。在创建基本数据类型的时候这种性能上的优势会更加明显。
// 字面量快得多var str1 = 'zce说我为前端而活'console.log(str1)var str2 = new String('zce说我为前端而活')console.log(str2)

若有收获,就点个赞吧
0 人点赞
