1. 先删缓存再更新数据库
1.1. 定义
先删除缓存再更新数据库的言下之意是在线程更新数据库前,先把缓存删除,然后在更新数据库。这样做的目的很明显,就是不管数据库更新成功与否,先把缓存删除,然后更新数据库。等下一次请求时因为已经删除了缓存就不会命中缓存,就会从数据库把更新后的数据库信息写入缓存从而达到缓存和数据库一致性的目的。就算数据库更新失败事务回滚,虽然缓存被删除了,但是在下一次请求时会重新从数据库中查询信息写入缓存中。
虽然先删除缓存再更新数据库可以实现一致性,但是在多线程的场景下还是会出现数据不一致的问题。
我们来模拟这个问题的原因:
- 线程T1进行写入操作,删除缓存,此时线程挂起
- 线程T2进行查询操作发现缓存没有命令(因为线程T1已经删除缓存)
- 线程T2就从数据库查询并且得到旧值,并且将旧值写入缓存
- 此时线程T1从挂起状态恢复将数据更新至数据库
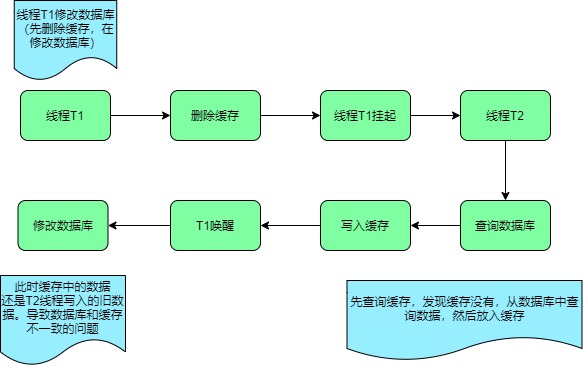
我们分析在多线程并发操作的情况下,会导致数据不一致性的问题。如果不采用缓存过期策略,该数据永远都是脏数据
2.2. 解决
采用延时双删策略+设置缓存过期时间+重试机制
- 先删除缓存
- 在写入数据库
- 休眠等待500毫秒
- 再次删除缓存
设置缓存过期时间的原因?
设置过期的原因是保证缓存最终一致性的的解决方案,既在缓存过期后从数据库查询数据写入缓存达到缓存最终一致性,这种方案的弊端就是在最差的情况下超时时间内的数据可能存在不一致的情况,但是缓存过期后数据会最终一致。
重试机制
引入重试机制的目的是尽最大努力来保证我们每一个步骤都能执行成功,特别在步骤四,如果再次删除缓存失败会导致数据不一致的问题,因为写入数据库后,没有再次删除缓存(此时缓存中可能会存在旧值,因为其他线程在此期间进行了查询操作)。重试机制可以引入消息机制。
休眠时间怎么定义?
休眠时间需要根据业务自行评估,评估查询业务的耗时时间,一般在查询业务耗时的基础上增加几百毫秒即可
休眠时间降低吞吐量怎么办?
可以对二次删除的内容另起一个线程来异步删除,这样就不需要等待修改时间后再返回结果,其目的可以提高吞吐量
如果二次删除缓存失败怎么办?
这是一个好问题,既采用延时双删策略时,在写入数据库成功后,缓存信息删除失败。
2. 异步更新缓存(订阅MySql binlog) + 重试
2.1. 定义
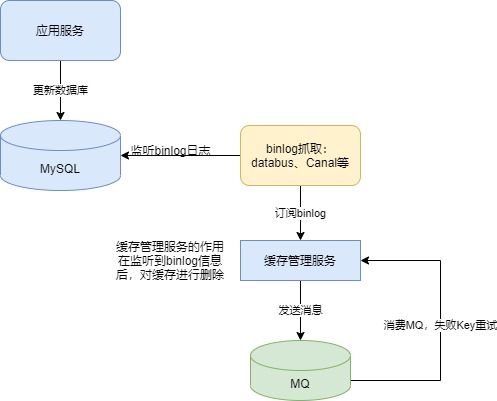
异步更新缓存的优势在于对业务系统零侵入,通过中间件(如阿里的Canal)订阅Mysql的binlog日志,再更新到缓存中,缺点在于引入了中间件增加了运维部署成本
2.2. 解决
异步操作+消息机制
- 开启数据库binlog功能
- 写入数据库
- 订阅binlog日志,分析日志得到数据库写入数据。
- 删除缓存,将写入数据写入缓存。
- 如果缓存删除失败将数据发送消息队列,消息队列消费消息将数据写入缓存
2.3. 存在问题
- 脏数据时间窗口“较大”
这个脏数据的时间窗口较大,是相对同步删除来说。在你收到binlog之前,他中间要经过:binlog从主库同步到从库 —> binlog从库到binlog监听组件(如Canal) —> binlog 从监听组件发送到MQ —> 消费MQ消息这几步动作,这些动作都是有一定耗时的,可能是几十毫秒甚至几百毫秒,所以说它其实整体是有一个脏数据的时间窗口
- 极端场景下存在长期脏数据问题
- binlog 抓取组件宕机导致脏数据。
- 拆库拆表流程中可能存在并发脏数据
- 拆库拆表中可能存在并发脏数据问题的原因
通过一个例子来发现为什么会有并发脏数据的问题
表A正在进行数据库拆分,当前进行到灰度切读流量阶段:部分读新库,部分读老库
数据库拆分大致流程:增量数据同步(双写)、全量数据迁移、数据一致性校验、灰度切读、切读完毕后停写老库
假设新旧库中存在表A,表中存在数据a=1,并发情况下可能有以下流程
| 时序 | 线程1 | 线程2 | 线程3 |
|---|---|---|---|
| 1 | 更新老库数据:a=2 | ||
| 2 | 异步监听binlog删除缓存 | ||
| 3 | 查询新库数据:a=1 | ||
| 4 | 老库数据同步到新库:a=2 | ||
| 5 | 将数据写入缓存:a=1(脏) |
该例子中,灰度切读阶段中,我们还是优先保障老库的流程,因此还是先写老库,由于写新库和写老库之间存在时间间隔,在线程3还没有将数据同步到新库的这个时间间隔内,线程2并发查询到新库的老数据,同时在监听binlog删除缓存流程之后将老数据写入缓存,从而导致脏数据问题,并且脏数据可能会持续很久。
双写的方式有很多种,我们使用的是通过公司的中间件直接将老库数据通过binlog的方式同步到新库,该方案通过监控发现在写压力较大的情况下,延迟可能会达到几秒,因此出现了上述问题。
而如果是使用代码进行同步双写,双写之间的时间间隔会较小,该问题出现的概率会相对低很多,但是还是无法保障绝对不会出现,就像上面提过的,写老库和写新库2个操作之间如果发生了YGC或者FGC,就可能导致这两个操作之间的时间间隔比较大,从而可能发生上面的案例。
还有就是代码双写的方式必须收敛所有的写入口,上文提到过的,通过命令行或者数据库管理平台的方式修改的数据,代码双写也是无法覆盖的,需要执行者在新老库都执行一遍,如果遗漏了新库,则可能导致数据问题。
2.4. 总结
虽然异步更新引入了中间件和消息机制,增加了运维成本。但是可以保证缓存和数据库一致性的可靠性,对业务系统代码零侵入。
双删策略的特点是实现简单,对业务系统的侵入性很大。在实际架构中采用哪种方式需要开发人员根据自己的业务复杂度,容忍度来采用哪种方式。
该方案在大多数场景下没有太大问题,业务比较小的场景可以使用,或者在其基础上进行适当补充。
3. 最终方案
3.1. 定义
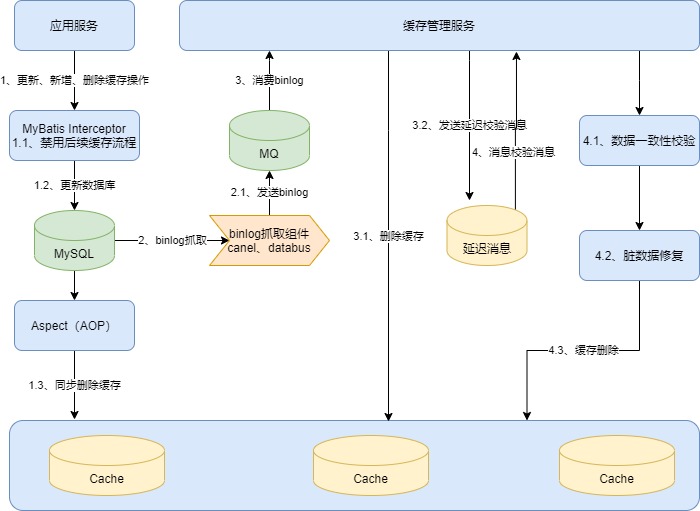
缓存三重删除 + 数据一致性校验 + 更新流程禁用缓存 + 强制读Redis主节点
3.2. 解决方案
第一步:更新数据库后同步删除缓存
第二步:监听数据库的binlog异步删除缓存:带重试,保障一定会最终删除成功
第三步:缓存数据带过期时间,过期后自动删除,越近更新的数据过期时间越短
- 主要解决进一步防止并发下的脏数据问题
- 解决一些由于未知原因,导致需要更换缓存结构的问题
第四步:监听数据库的binlog延迟N秒后进行数据一致性校验
- 解决一些极端场景下的脏数据问题
第五步:存在数据库更新的链路禁用对应缓存
- 防止并发下短期内的脏数据影响到更新流程
第六步:强制读Redis主节点
第七步:查询异步数据一致性校验、灰度放量
- 更新数据库后同步删除缓存
这个同步删除缓存其实是为了解决监听binlog的时间窗口比较大的问题,更新完数据之后,马上进行一次同步删除,不一致的时间窗口非常小
- 监听数据库的binlog 异步删除缓存
该步骤是整个方案的核心,因为binlog理论上是绝对不会丢失的,他步像同步删除存在无法收敛入口的问题。因此,我们会保障该步骤一定能删除成功,如果出现失败,则通过MQ不断重试。
- 缓存数据带过期时间,过期后自动删除、越近更新的数据过期时间越短
该策略的设计初衷是因为我们前面讲的并发问题其实都是在存在并发更新跟一些并发查询的场景下出现的,因此最近刚刚更新过的数据,他出现不一致的概率相对于那种很久没更新过的数据来说会大很多
例如最近一个小时内更新的数据,我可能给他设计的过期时间很短,当然这个过期时间很多是相对于其他数据而言,绝对时间还是比较长的,例如我们使用的是一个小时。
这边是因为我们整体的请求量和数据量太大,如果使用的过期时间太短,会导致写缓存流量特别大,导致缓存集群压力很大。
因此,如果使用该策略,建议过期时间一开始可以设置大一点,然后逐渐往下调,同时观察缓存集群的压力情况。
该方案可以进一步保证我们数据的一个最终一致性。
同时带过期时间可以解决另一个问题,如果你在缓存上线后发现缓存数据结构设计不合理,你想把该缓存替换掉。如果该缓存有过期时间,你不需要处理存量数据,让他到期自动删除就行了。如果该缓存没有过期时间,则你需要将存量数据进行删除,不然可能会占用大量空间。
- 监听数据库的binlog延迟N秒后进行数据一致性校验
这个操作也是非常关键,通过监听binlog可能会产生脏数据,并且脏数据都是在更新操作之后的很短时间内触发的。因此我们对每一个更新操作,都在延迟一段时间后去校验其缓存数据是否正确,如果不正确,则进行修复,这样就保障了绝大多数并发导致的脏数据问题。
至于延迟多久,我个人建议是延迟几分钟,不能延迟太短,否则起不到兜底的效果
- 存在数据库更新的链路禁用对应缓存
在数据库更新的场景里面,我们可能会有一些查询操作。例如我更新完这个数据之后,我马上又查了一下。这个时候其实如果你去走缓存,很有可能是会存在脏数据。因为他更新完之后,马上读取这个间隔是非常短的。你的缓存其实可能还没有删除完,或者存在短期内的不一致,我们还没有修复。
但是这种更新场景他对数据的一致性要求一般是比较高的。因为更新完之后,他要拿这个查询出来的数据去做一些其他操作。例如记录数据变更的操作日志。
我把一个数据从a=1改成a=2,我在更新之前,我先查出来a=1,更新完之后我立马就去查出来a=2,这个时候我就记录一条操作日志,内容是a从1变成2。
这种情况下,如果你在更新完之后的这个查询去走缓存,就有很大的概率查到a=1,这时候你的操作日志就变成a从1变成1,导致操作日志是错的。
所以说这种更新后的查询,我们一般会让他不走缓存,因为他这个时效性就是太快了,缓存流程可能还没处理完成。
这个方案点其实是借鉴了MySQL事务的设计思想,MySQL中,事务对于自己更新过的内容都是实时可见的。因此,我们这边也做了一个类似的设计。
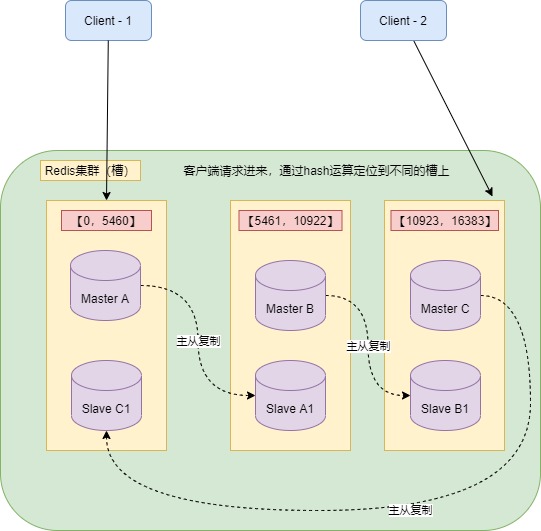
- 强制读Redis 主节点
Redis跟MySQL一样,也会有主从副本,也会有主从延迟。当你将数据写入Redis后,马上去查Redis,可能由于查询从副本,导致读取到的是老数据,因此我们可以通过直接强制读主节点来解决这个问题,进一步增加数据的准确性。
Redis 不像 MySQL 有主节点压力过大的问题,Redis 是分布式的,可以将16384个槽分摊到多个分片上,每个分片的主节点部署在不同的机器上,这样强制读主时,流量也会分摊到多个机器上,不会存在MySQL的单节点压力过大问题。
- 查询异步数据一致性校验、灰度放量
这一步是缓存功能使用前的一些保障措施,保障缓存数据是准确的。
对于查询异步数据一致性校验,我们一般在查询完数据库之后,通过线程池异步的再查询一次缓存,然后把这个缓存的数据跟刚才数据库查出来的数据进行比较,然后将结果进行打点统计。
然后查看数据一致性校验的一致率有多少,如果不一致的概率超过了1%,那可能说明我们的流程还是有问题,我们需要分析不一致的例子,找出原因,进行优化。
如果不一致的概率低于0.01%,那说明整个流程可能基本上已经没啥问题了。这边理论上一定会存在一些不一致的数据,因为我们查询数据库和缓存之间还是有一定的时间间隔的,可能是1毫秒这样,在高并发下,可能这个间隔之间数据已经被修改过了,所以你拿到的缓存数据和数据库数据可能其实不是一个版本,这种情况下的不一致是正常的。
对于灰度放量,其实就是保护我们自己的一个措施。因为缓存流程毕竟还没经过线上的验证,我们一下全切到缓存,如果万一有问题,那可能就导致大量问题,从而可能导致线上事故。
如果我们一开始只是使用几个门店来进行灰度,如果有问题,影响其实很小,可能是一个简单的事件,对我们基本没影响。
在有类似比较大的改造时,通过灰度放量的方式来逐渐上线,是一种比较安全的措施,也是比较规范的措施。
3.3. 总结
该方案的链路确实比较长,但是高并发下确实会有很多问题,因此我们需要有很多措施去保障。当然,这个方案也不是一下子就是这样的,也是通过不断的实践和采坑才逐渐演进而来的。目前该方案在我们线上环境使用了挺长一段时间了,基本没有什么问题,整体还是比较完善的。

若有收获,就点个赞吧
0 人点赞
