前言
Elasticsearch里插入一条记录,其实就是直接PUT一个json的对象,这个对象有多个fields.那么在插入这些数据到Elasticsearch的同时,Elasticsearch还默默的为这些字段建立索引—倒排索引,因为Elasticsearch最核心功能是搜索。
1. 结构

2. 说明
假设有这么几条数据
| ID | Name | Age | Sex |
|---|---|---|---|
| 1 | Kate | 24 | Female |
| 2 | John | 24 | Male |
| 3 | Bill | 29 | Male |
ID是Elasticsearch自建的文档id—docId,那么Elasticsearch建立的索引如下:
Name:
| Term | Posting List |
|---|---|
| Kate | 1 |
| John | 2 |
| Bill | 3 |
Age:
| Term | Posting List |
|---|---|
| 24 | [1,2] |
| 29 | 3 |
Sex:
| Term | Posting List |
|---|---|
| Female | 1 |
| Male | [2,3] |
Posting List
Elasticsearch分别为每个field都建立了一个倒排索引,Kate, John, 24, Female这些叫term,而[1,2]就是Posting List。Posting list就是一个int的数组,存储了所有符合某个term的文档id。
通过posting list这种索引方式似乎可以很快进行查找,比如要找age=24的同学,则id是1,2的同学。但是,如果这里有上千万的记录呢?如果是想通过name来查找呢?
Term Dictionary
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。与传统数据库通过B-Tree的方式类似, 但为啥比B-Tree的查询快呢?
Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树:
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。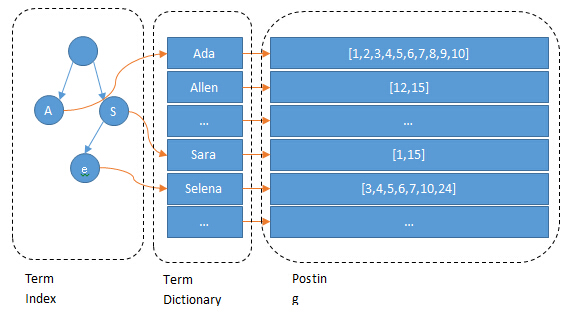
所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
3. 压缩技术
FST — 对于Term Index的有效压缩
假设我们现在要将mop, moth, pop, star, stop and top(term index里的term前缀)映射到序号:0,1,2,3,4,5(term dictionary的block位置)。最简单的做法就是定义个Map
FST 是将项(字节序列)映射到任意输出的有限状态机。
⭕️表示一种状态
—>表示状态的变化过程,上面的字母/数字表示状态变化和权重
将单词分成单个字母通过⭕️和—>表示出来,0权重不显示。如果⭕️后面出现分支,就标记权重,最后整条路径上的权重加起来就是这个单词对应的序号。
FST以字节的方式存储所有的term,这种压缩方式可以有效的缩减存储空间,使得term index足以放进内存,但这种方式也会导致查找时需要更多的CPU资源。
增量编码压缩+按字节存储 — 对于Posting List的有效压缩
增量压缩

图27-5a显示了一个音频信号段,数字化到8位,每一个样本介于-127到127之间。图27-5b显示了该信号的增量编码版本。其主要特点是,增量编码信号的幅值比原始信号低。
原理就是通过增量,将原来的大数变成小数仅存储增量值.
按字节存储—Roaring bitmaps

若有收获,就点个赞吧
0 人点赞
