表的约束
概念 : 对表中的数据进行限定 , 从而保证数据的正确性,有效性和完整性.
- 没有约束的时候 添加的数据可以任意 这样就不太合适
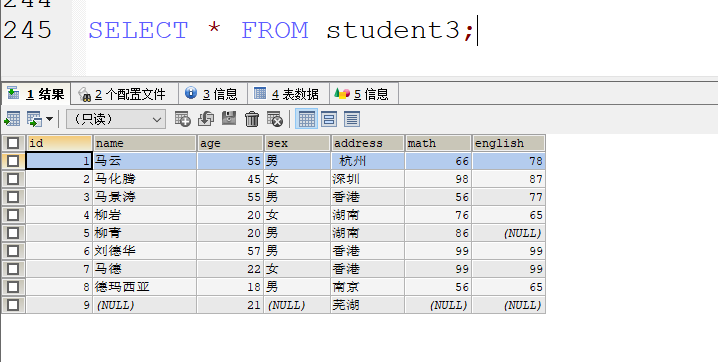
- 没有约束的时候 添加的数据可以任意 这样就不太合适
分类:
- 主键约束 : primary key
- 非空约束 : not null
- 唯一约束 : unique
- 外键约束 : foreign key
- 主键约束
注意
- 含义: 非空且唯一
- 一张表中只可以有一个字段为主键
- 主键就是表中记录的唯一标识
创建表的时候添加约束
- 主键的唯一性
- 主键的非空性
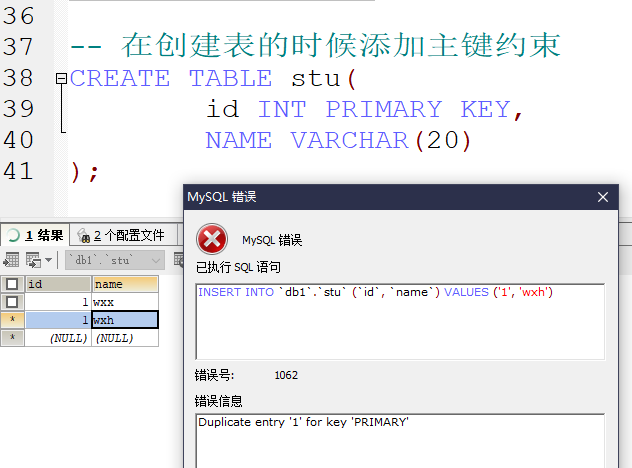
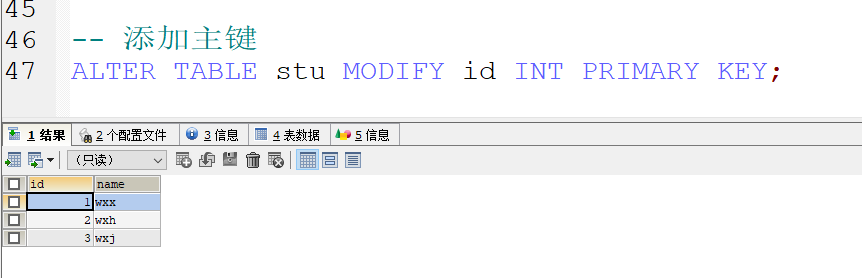
在表创建完成后进行主键约束的添加以及修改
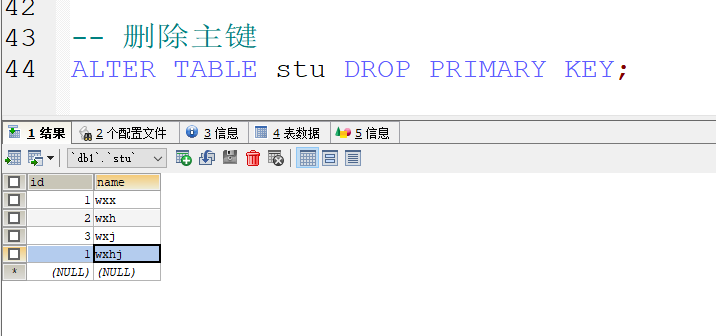
- 删除主键 因为主键在表中的唯一性 所以不需要指定字段
- 当然 指定字段也是可以的
- 添加主键
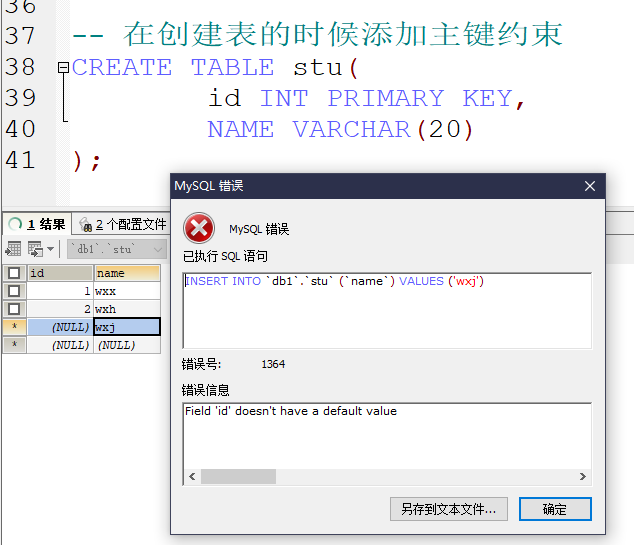
自动增长
如果某一列是数值类型的,使用auto-increment 可以完成值的自动增长
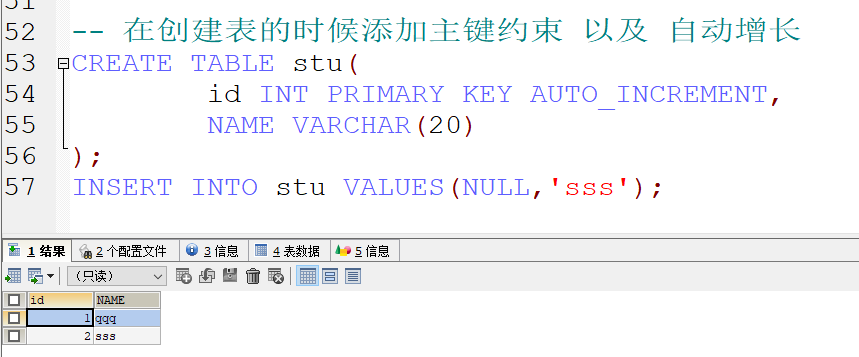
创建表的时候添加
```
- 注意: 自动增长的时候 标号只跟上一条数据有关
 ```
```
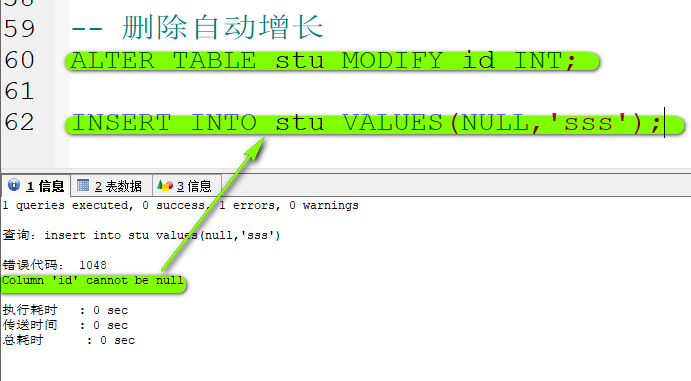
- 删除自动增长
这样并不会删除主键
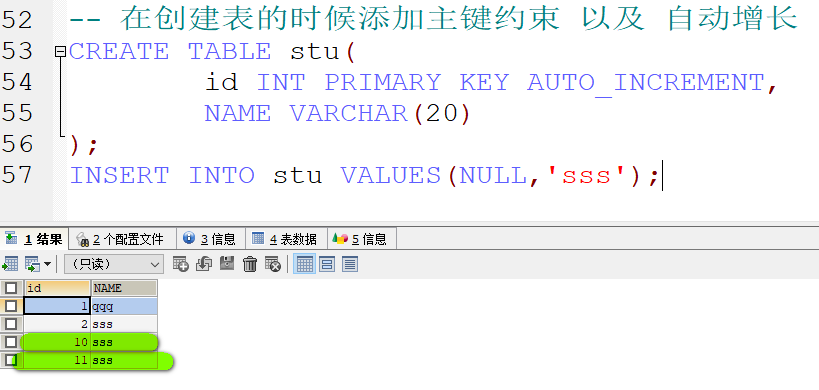
- 添加自动增长
>
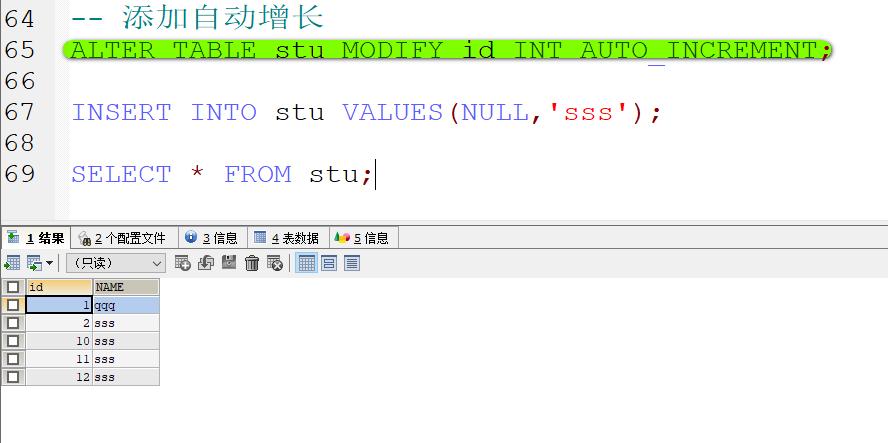
- 注意 大多数情况下 自动增长都是和主键一起使用的
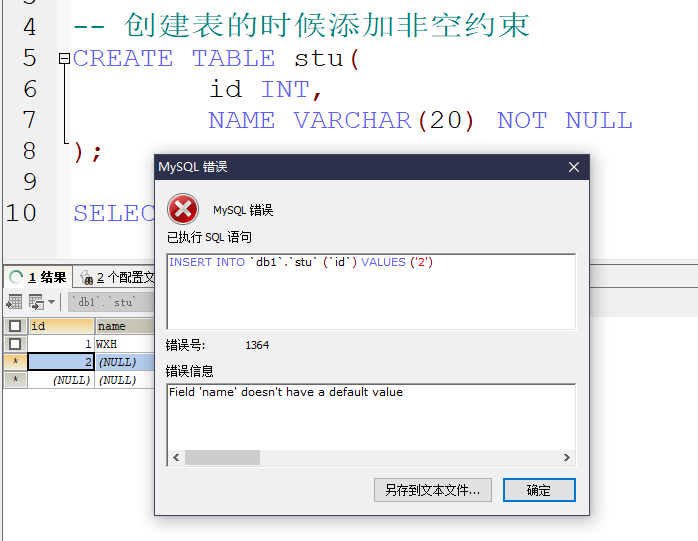
- 非空约束 : not null ,值不能为null
创建表的时候添加约束
在表创建完成后进行非空约束的添加以及修改

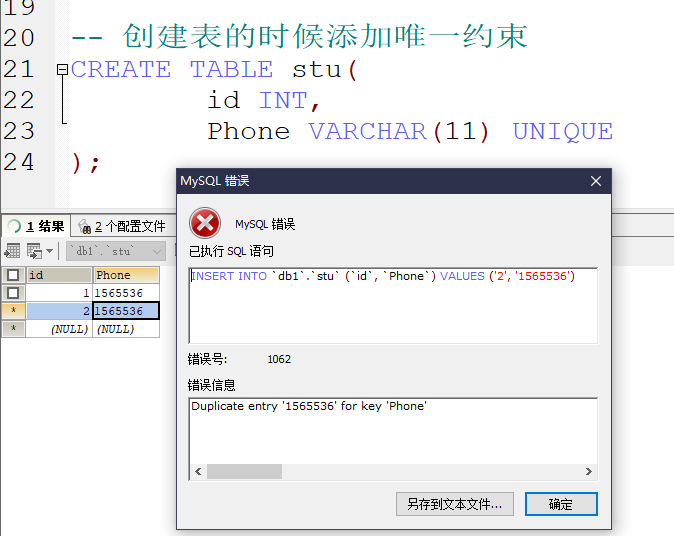
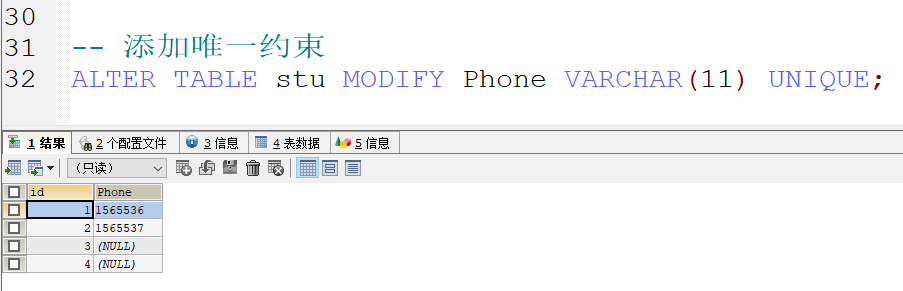
- 唯一约束 : unique , 值不能重复
创建表的时候添加唯一约束
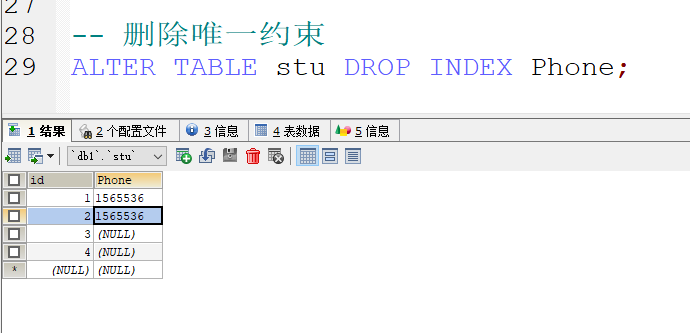
在表创建完成后对唯一约束进行添加以及删除
删除唯一约束 DROP INDEX
添加唯一约束
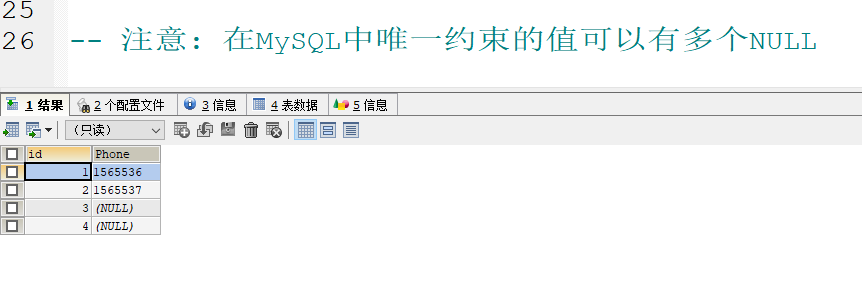
- 注意:
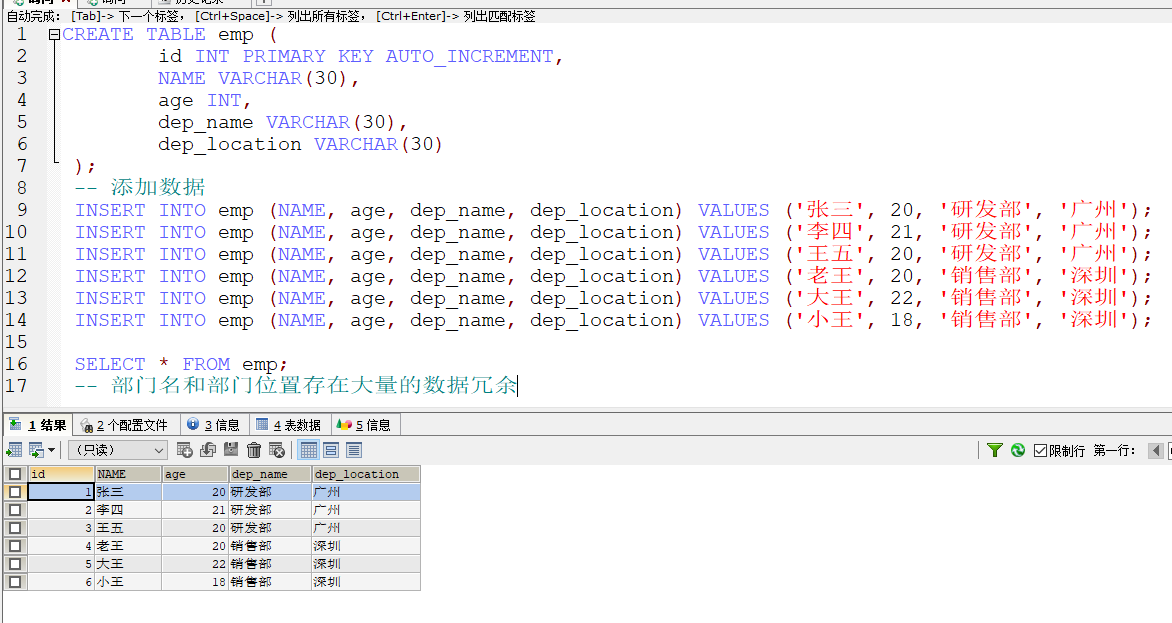
外键约束 : foreign key —->让表与表产生关系,从而保证数据的正确性
问题: 下面的数据中存在大量的数据冗余问题
问题解决: 将表中的信息拆分成两张表
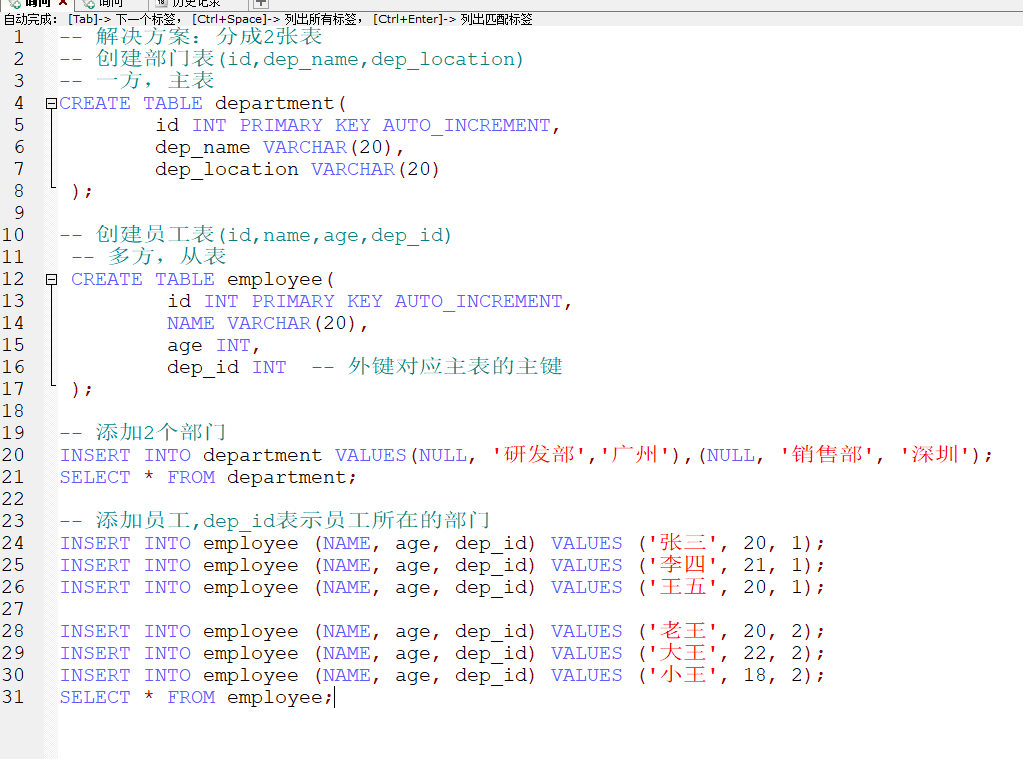
这样表的结构就变成了这样的: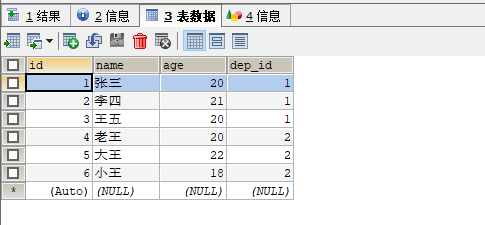
这样就将之前的部门的名称修改成了部门的编号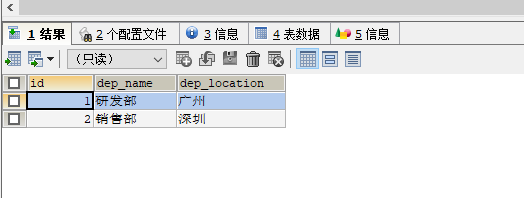
其实数据还是存在问题的
- 当我们将部门表中的某一行删除的时候,在员工表中还存在着部分编号的引用
- 现实中的逻辑是 当部门没有人的时候才可以将部门表中的部门信息删除
- 为了解决上述问题,就可以使用外键约束,将员工表中的部门编号去关联部门表中的主键id
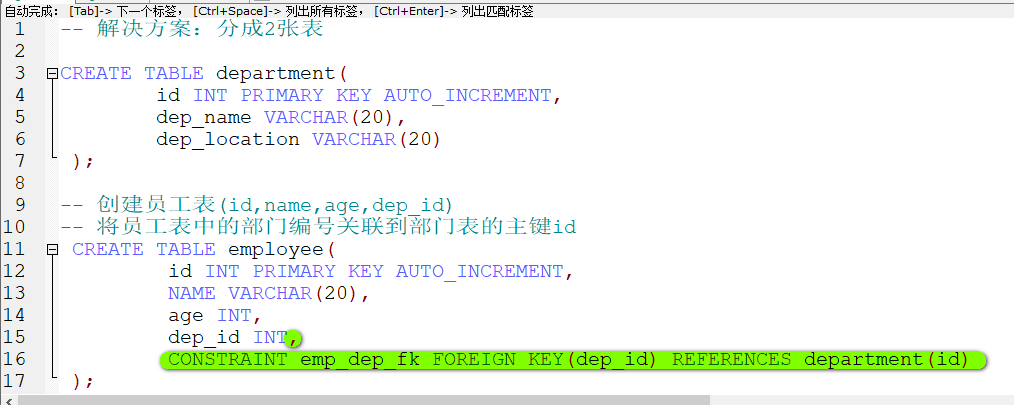
在创建表的时候添加外键
create table 表名(
………..
外键列
constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列的名称)
);
此时去删除部门表的某一行就会出错 因为和主表有外键约束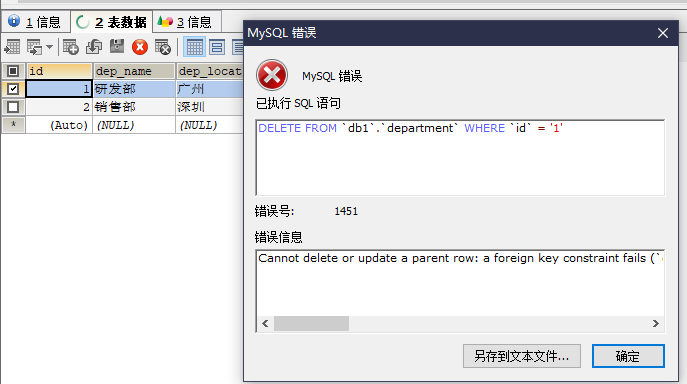
另外 当你去员工表中添加一行 部门编号在部门表中不存在的时候 也会报错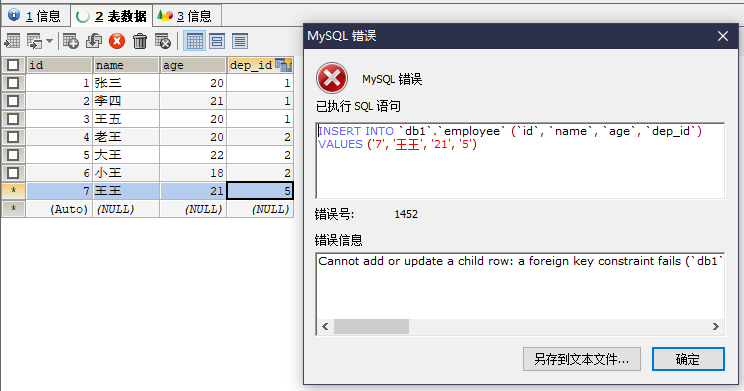
这样就保证了数据的正确性
- constraint 约束,约束条件
- references 参考,参照,引用 在这里翻译为”关联”我觉得更为合适
在表创建完成后进行外键的删除以及添加
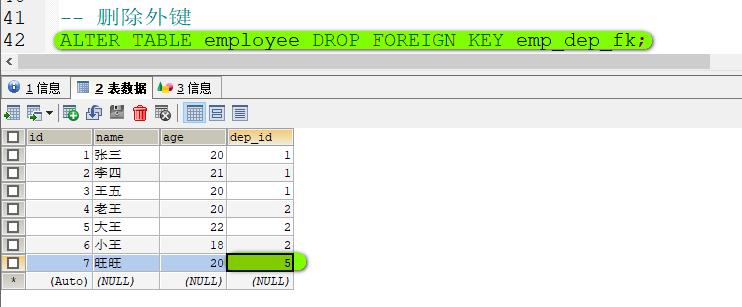
删除外键
语法: ALTER TABLE 表名 DROP FOREIGN KEY 外键名;在表创建完成之后添加外键
语法:ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键列名称) REFERENCES 主表名称(主表列名称);
级联操作
当我们需要将部门表中的部门编号修改的时候
- 首先 将员工表中的这个部门的员工的所在部门编号修改为NULL
- 然后 将部门表中的这个部门修改成相应的编号
- 最后 将员工表中的部门NULL 修改成对应的操作
级联更新操作就是 当我们修改部门表中的部门编号的时候, 员工表中的部门编号会相应的自动修改
级联删除操作 当我们删除部门表中的某一行的时候 那么 在员工表中部门编号为此部门编号的行 都会被删除
弊端 : 删除的时候风险比较大 因为关联的数据都会被删除
实际开发中 级联的使用比较谨慎!!



数据库的设计
多表之间的关系
- 分类:
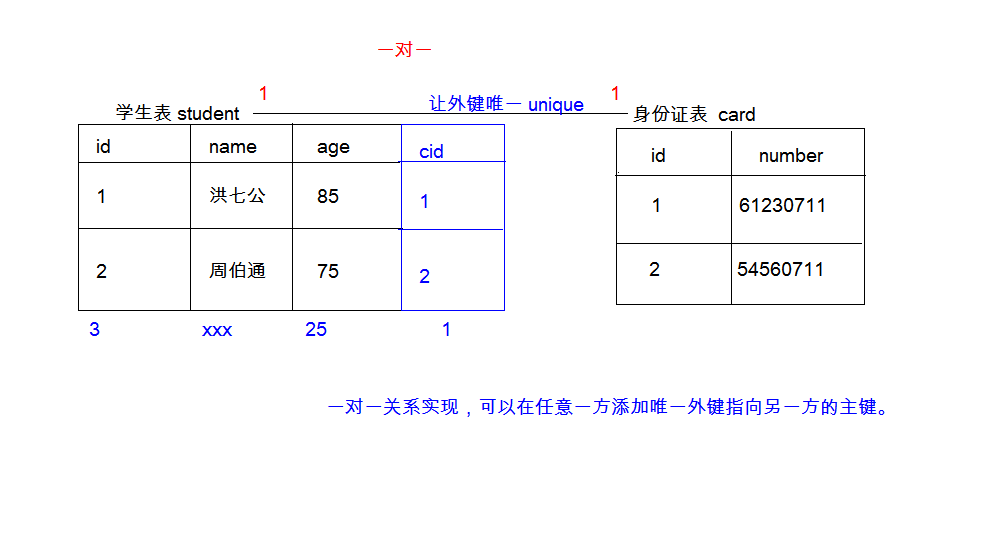
一对一
人和身份证
分析:一个人只有一个身份证,一个身份证只对应一个人
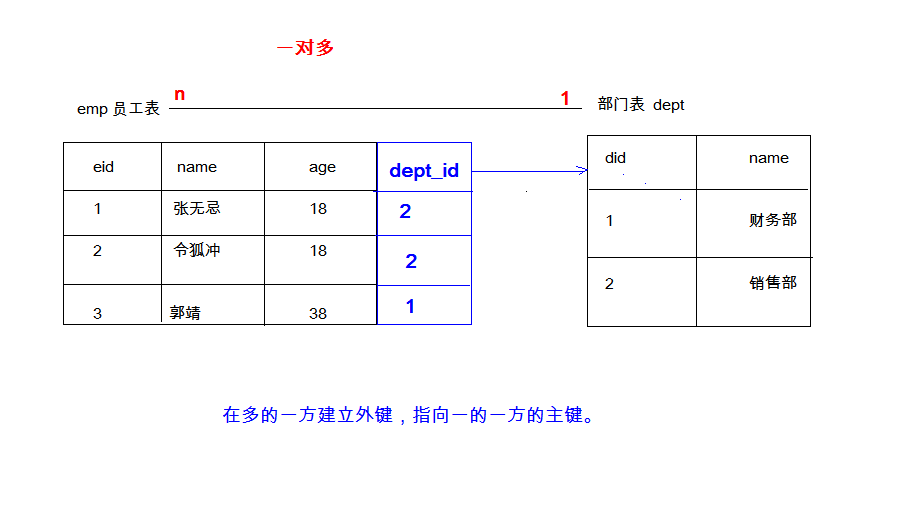
一对多(多对一)
部门和员工
分析:一个部门有多个员工,一个员工只属于一个部门
多对多
学生和课程
一个学生可以选择很多课程,一个课程可以被多个学生选择
实现关系:
一对一
任意一方 添加 唯一外键, 指向另一方的 主键
一对一的关系合成一张表岂不是更实在.
2.
一对多(多对一)
-
在 多 的一方建立外键,指向 1 的一方的主键
3.
多对多
-
借助 中间表 来实现,中间表 至少 包含两个字段 ,这两个字段作为中间表的外键,分别指向两张表的主键
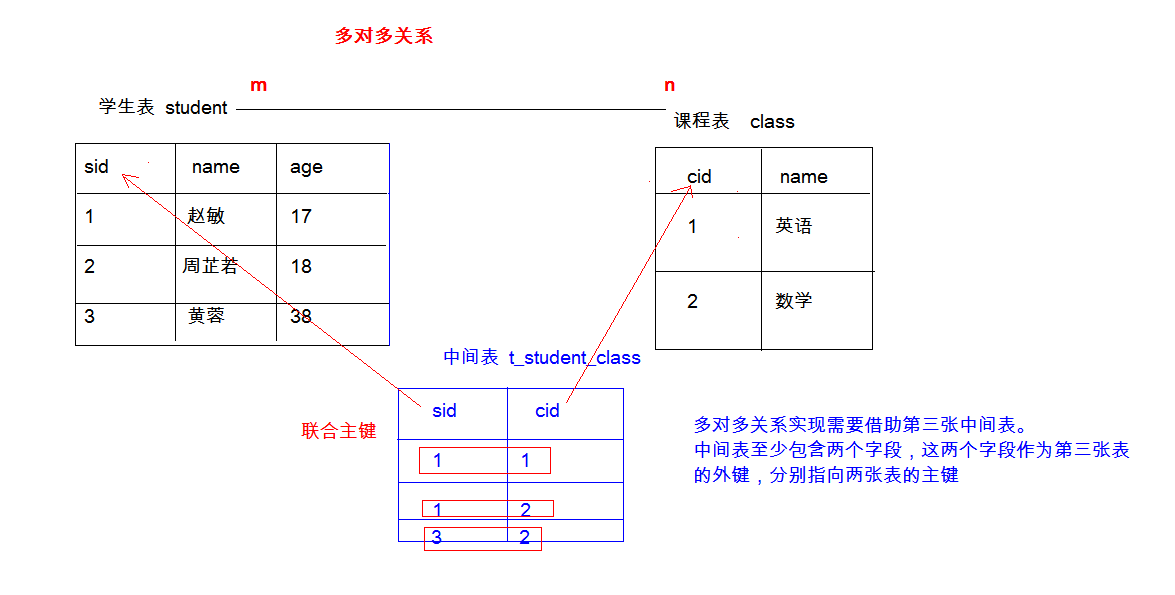
4.
案例分析
-
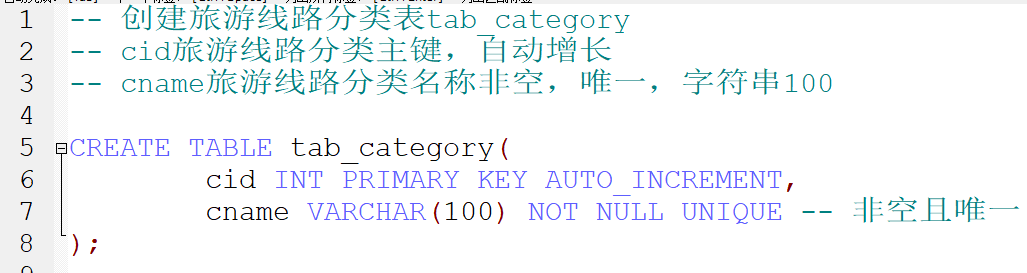
tab_category
-
tab_route

-
tab_user

-
tab_favorite
中间表中的两个字段成为联合主键(中间表的) 然后将这个联合主键作为两个主表的外键

-
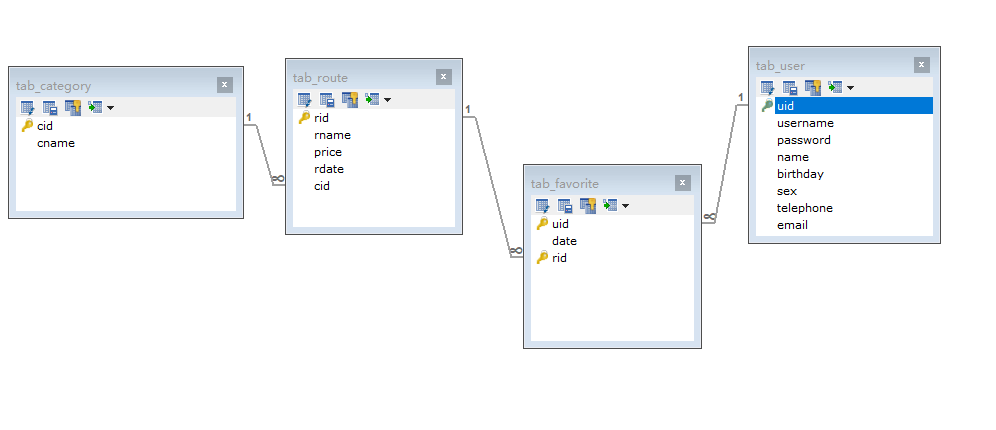
架构图
可以清晰的看出一对多(多对一)的tab_category和tab_route
以及借助中间表(tab_favorite)来实现的多对多的关系tab_route和tab_user
数据库设计的范式
概念 : 在设计数据库时,需要遵循的一些规范, 要遵循后面的范式, 要求必须遵循前面的所有范式, 设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小
第一范式(1NF) : 每一列都是不可分割的原子数据项
也就是说不能存在这样的表 系这一列还可以分割成两个原子项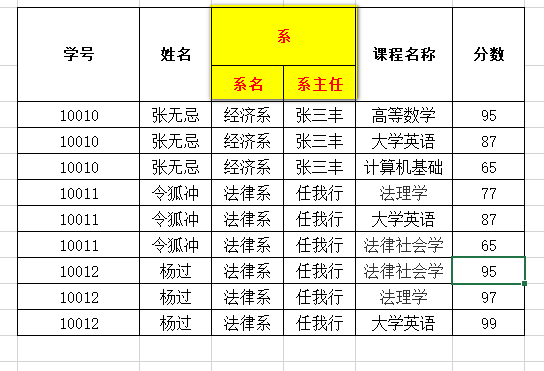
修改后 就变成了原子列
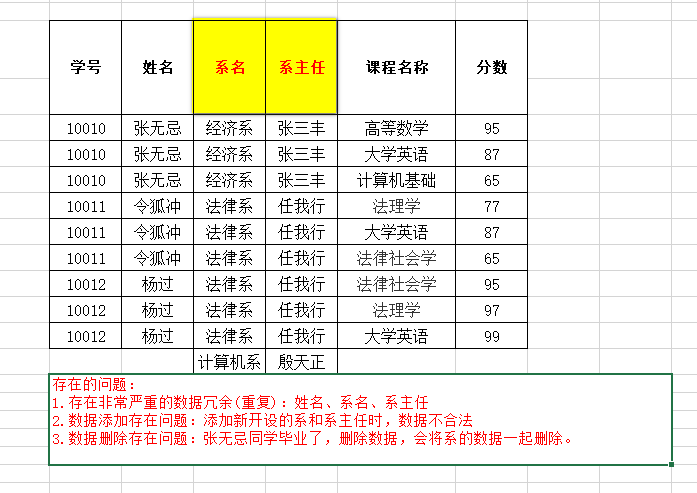
- 第二范式(2NF) : 在1NF的基础上,非码属性必须完全依赖于码(在1NF基础上消除非主属性对主码的部分函数依赖)
几个概念:
可将 —> 读作 “确定”
- 函数依赖:A—>B,如果通过A属性(属性组)的值,可以确定唯一B属性的值。则称B依赖于A
- 例如:学号—>姓名。 (学号,课程名称) —> 分数
- 完全函数依赖:A—>B, 如果A是一个属性组,则B属性值得确定需要依赖于A属性组中所有的属性值
- 例如:(学号,课程名称) —> 分数
- 部分函数依赖:A—>B, 如果A是一个属性组,则B属性值的确定只需要依赖于A属性组中某一些值即可。
- 例如:(学号,课程名称) — > 姓名
- 这里只需要学号就可以确定姓名的
- 传递函数依赖:A—>B, B — >C . 如果通过A属性(属性组)的值,可以确定唯一B属性的值,在通过B属性(属性组)的值可以确定唯一C属性的值,则称 C 传递函数依赖于A
- 例如:学号—>系名,系名—>系主任
- 系主任传递依赖于学号
码:如果在一张表中,一个属性或属性组,被其他所有属性所完全依赖,则称这个属性(属性组)为该表的码
- 通俗的来书就是,通过这个属性或属性组 , 可以确定其他所有的属性
例如:该表中码为:属性组 (学号,课程名称)
- 主属性:码属性组中的所有属性
- 非主属性:除了码属性组的属性
- 第二范式就是在第一范式基础上 消除非主属性对主码的部分函数依赖
- 在表中 码是(学号,课程名称)
- 分数完全依赖于码
- 姓名,系名,系主任 部分函数依赖于码 也就是部分依赖
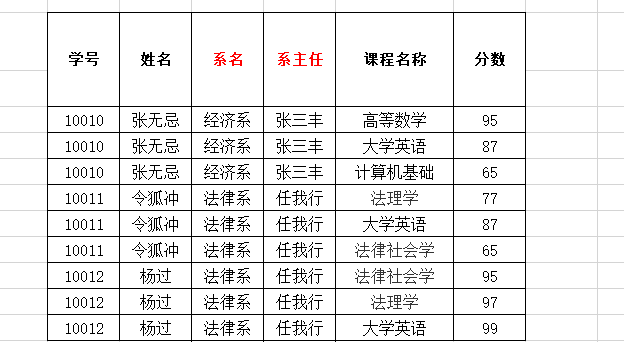
消除部分依赖:将表进行拆分
可见 在选课表中 分数完全依赖与码(学号,课程名称)
在学生表中 姓名,系名,系主任完全函数依赖于码 (学号)
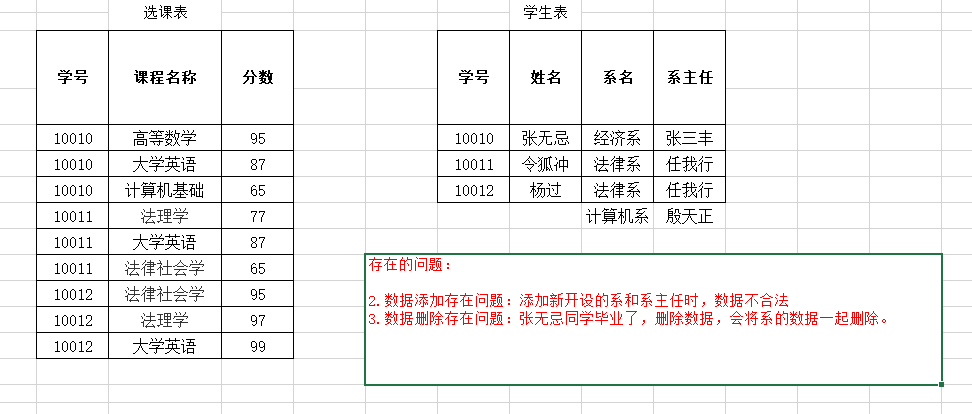
- 第三范式(3NF) : 在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
在上面的表中, 存在 学号—>系名,系名—>系主任 的传递函数依赖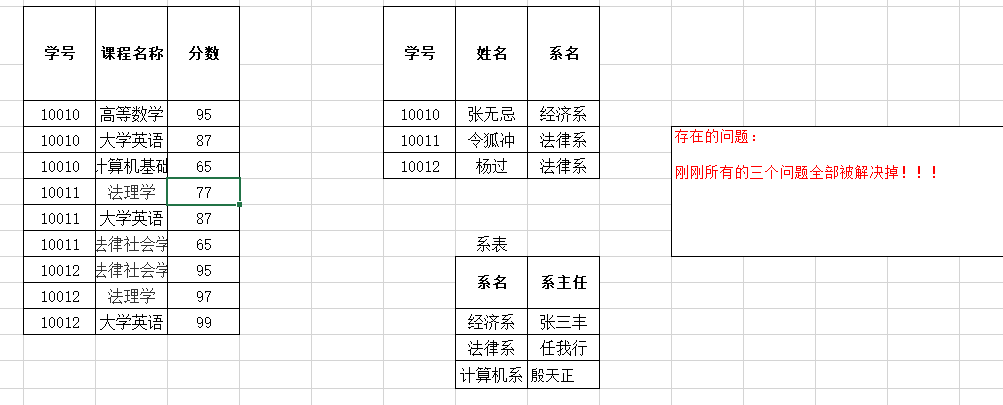
数据库的备份和还原
命令行的方式
语法
- 备份: mysqldump -u用户名 -p密码 数据库名称 > 保存的路径
还原:
- 登录数据库
- 创建数据库
- 使用数据库
- 执行文件 source 文件路径
- 图形化工具
多表查询
笛卡尔积
有两个集合A, B ,取这两个集合的所有的组成情况
总的组成情况的个数= A集合的元素个数 * B集合的元素个数
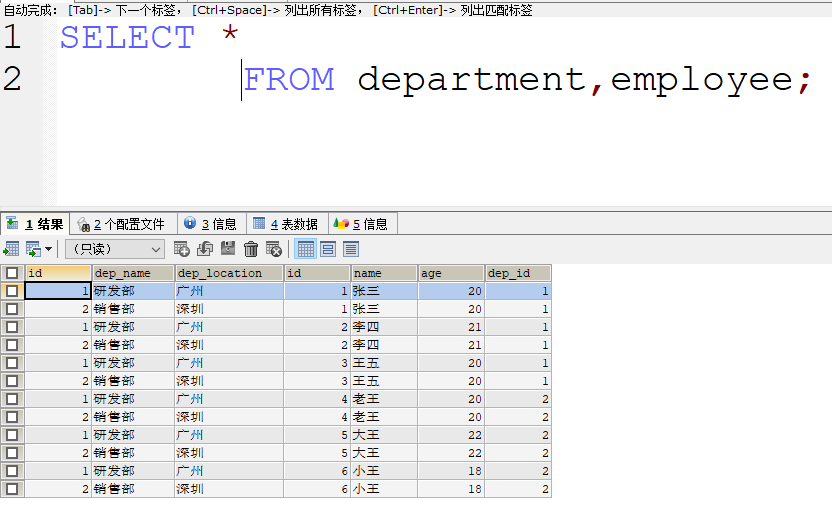
- 要完成多表查询 , 需要消除无用的数据 这就需要用到下列的三种方式
多表查询的分类
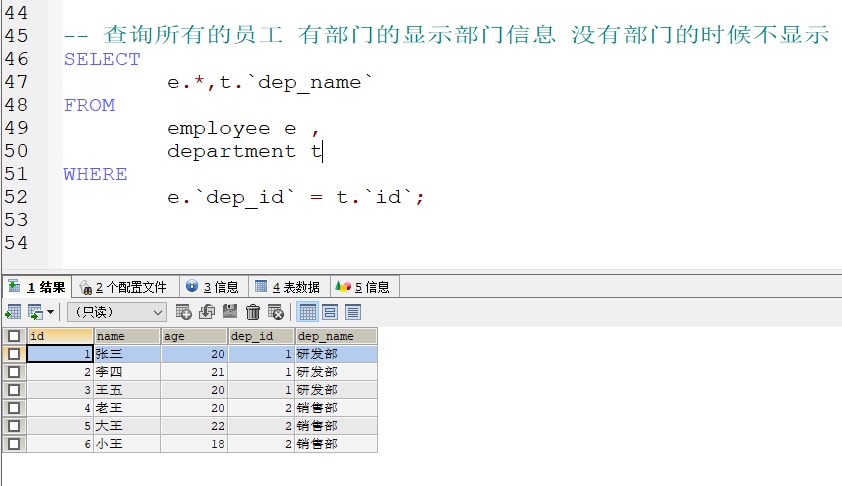
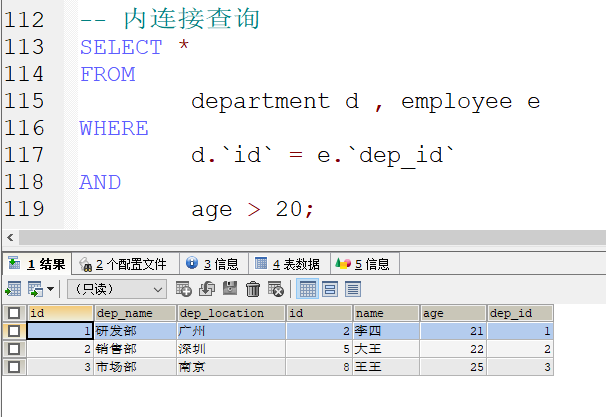
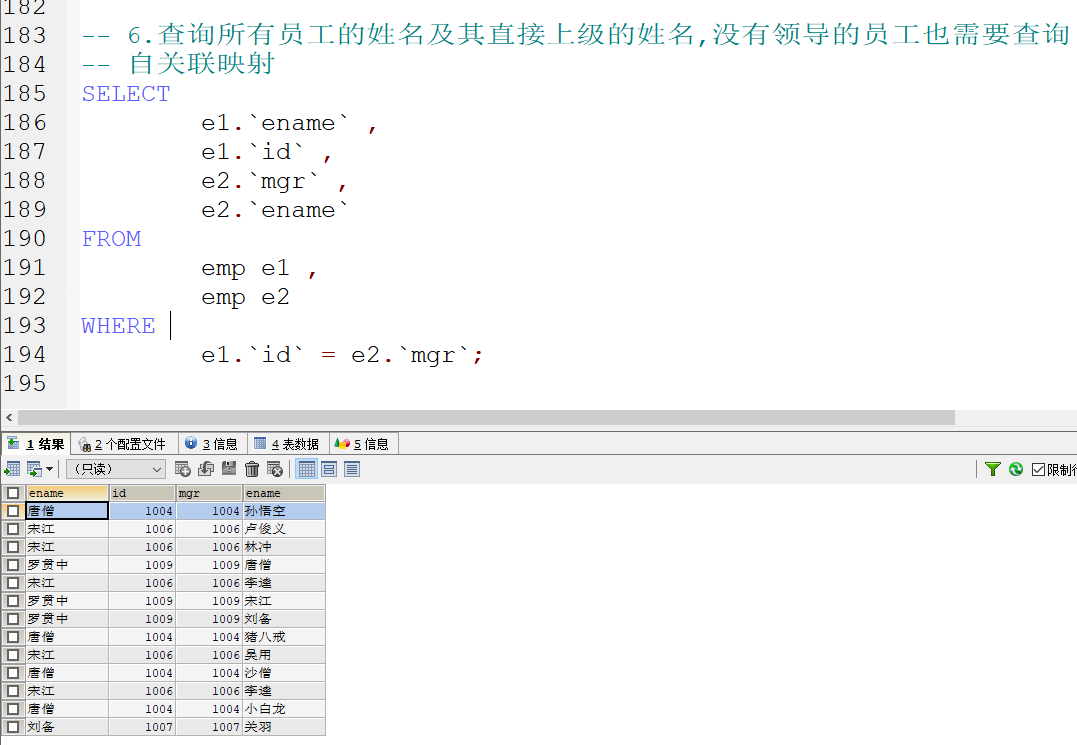
内连接查询 :
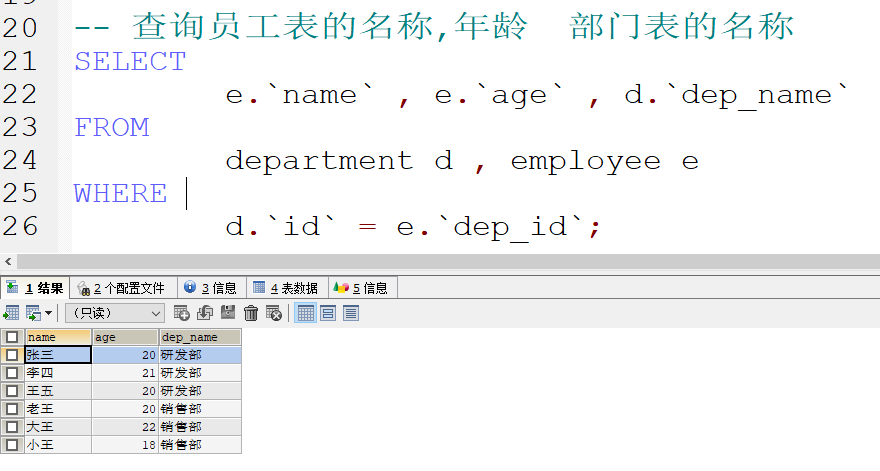
- 隐式内连接 : 使用where条件消除无用的数据
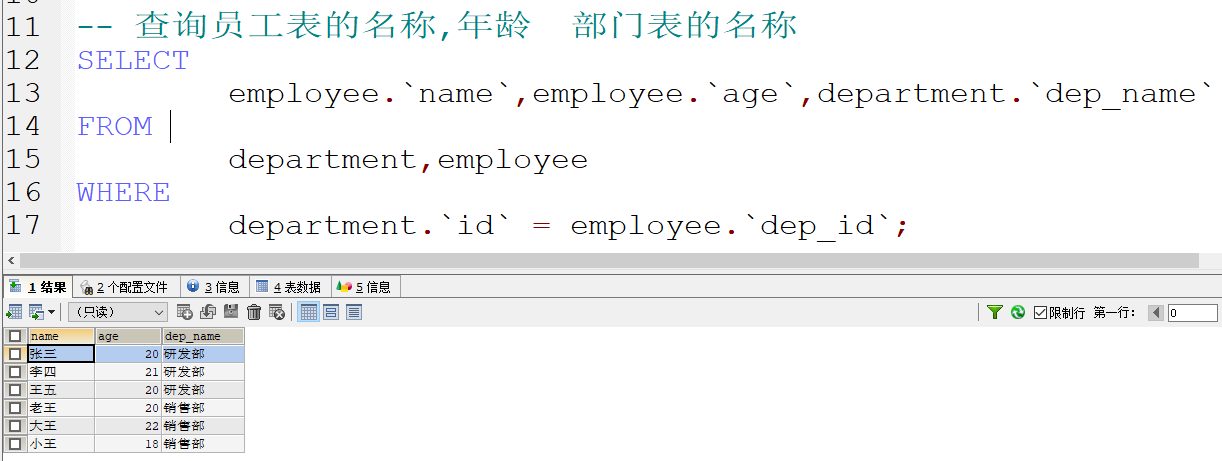
- 隐式内连接 : 使用where条件消除无用的数据
这样的话 当名称太长的时候 我们可以起别名来代替
开发规范: 进行相应的备注 以便查阅

2.
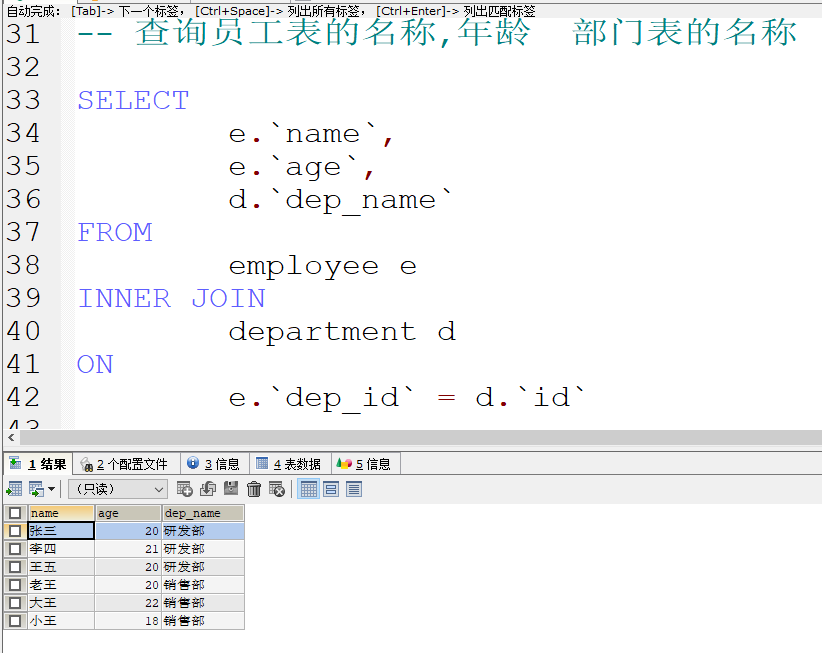
显示内连接
-
语法:
1. SELECT 查询字段 FROM 表1 INNER JOIN 表2 ON 连接条件;- INNER可省略2. SELECT 查询字段 FROM 表1 JOIN 表2 ON 连接条件;
3.
内连接查询的逻辑
1. 从哪些表中查询数据2. 查询的条件是什么3. 查询哪些字段
外连接查询 :
- 此时新加入的员工 还没有分配部门的时候
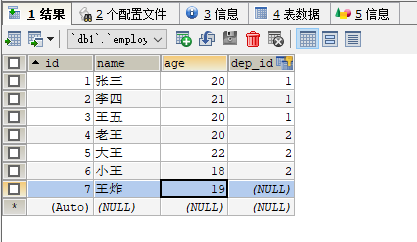
- 此时新加入的员工 还没有分配部门的时候
-
这样并没有完成需求
1.
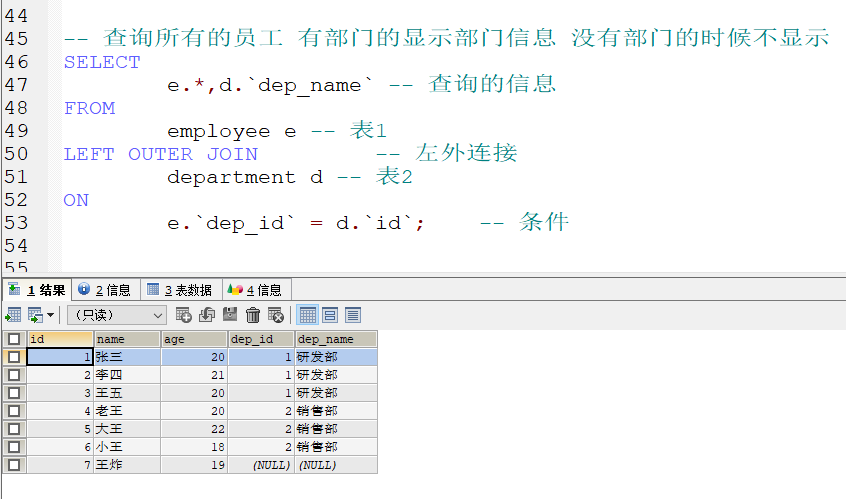
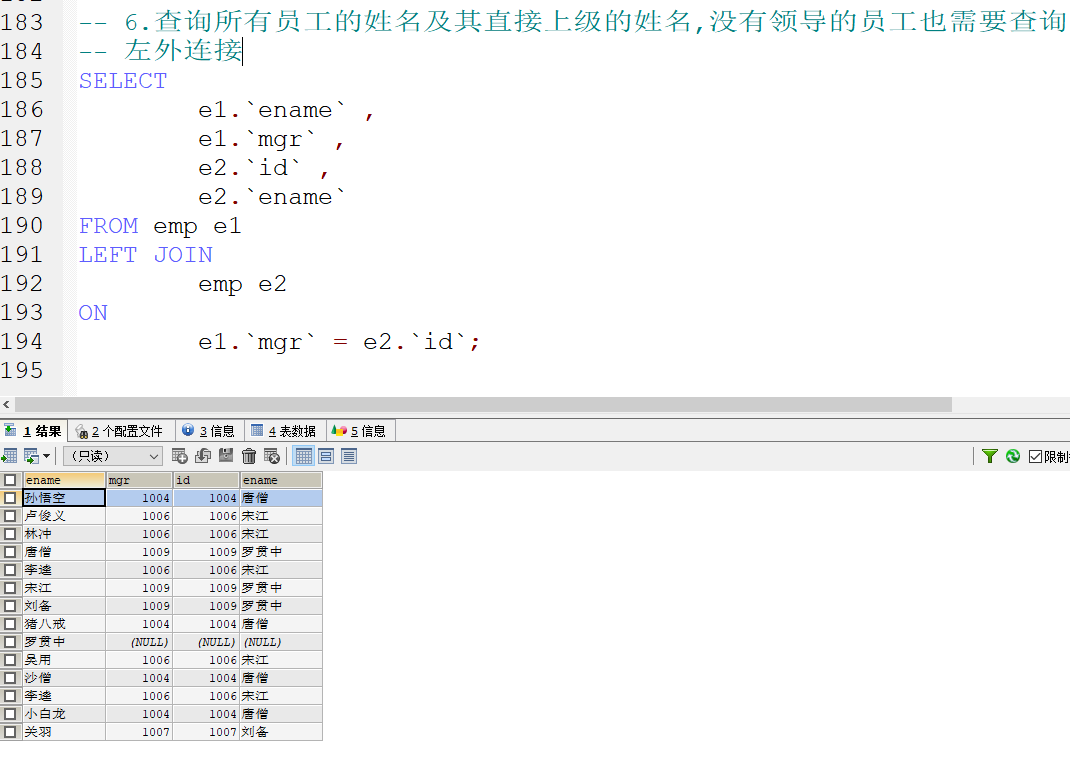
左外连接
语法: SELECT 查询内容 FROM 表1 LEFT [OUTER] JOIN 表2 ON 连接条件;
完成需求:
-
结果显示关键词left左边表中的所有数据,右边表数据数据少了补NULL值,数据多了不显示
-
注: OUTER可省略
2.
右外连接
语法: SELECT 查询内容 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 连接条件;
完成需求:
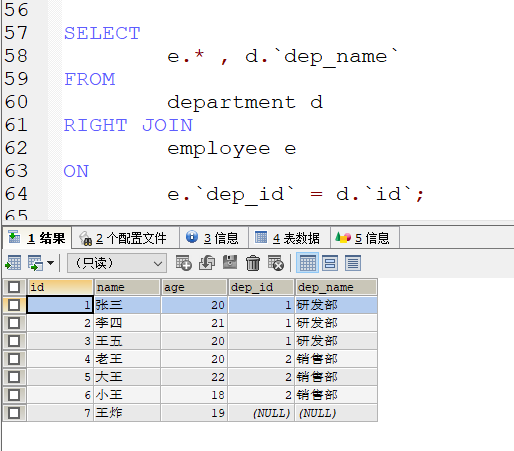
- 右连接是以右边为参照,左边少了补NULL,多了删除
子查询
- 概念 : 查询中嵌套查询 , 称为 嵌套的查询为子查询
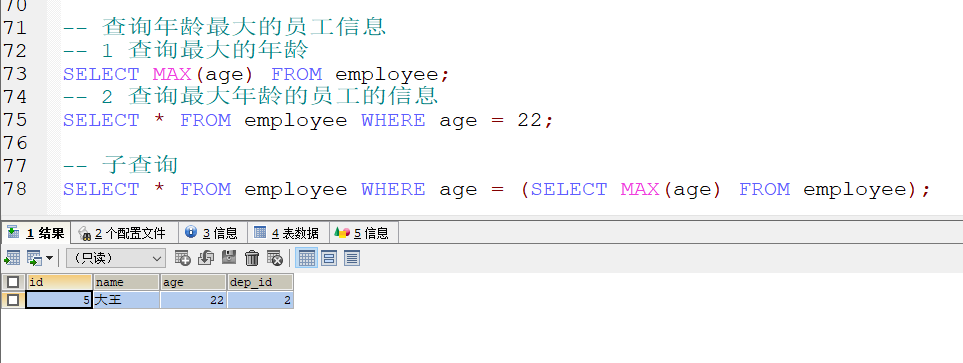
- 概念 : 查询中嵌套查询 , 称为 嵌套的查询为子查询
-
子查询的不同情况
1.
子查询的结果单行单列
-
子查询可以作为条件 使用运算符去判断
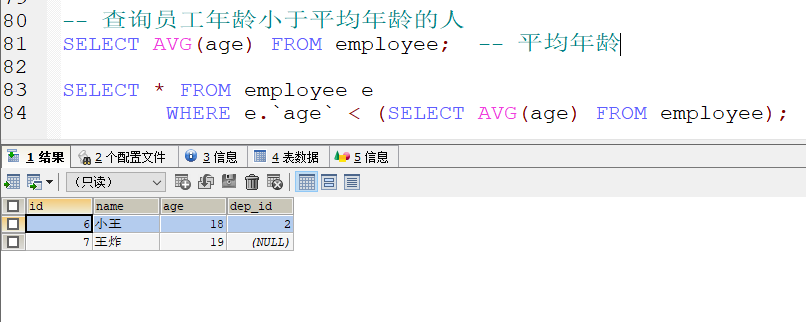
2.
子查询的结果多行单列
-
使用IN来进行判断
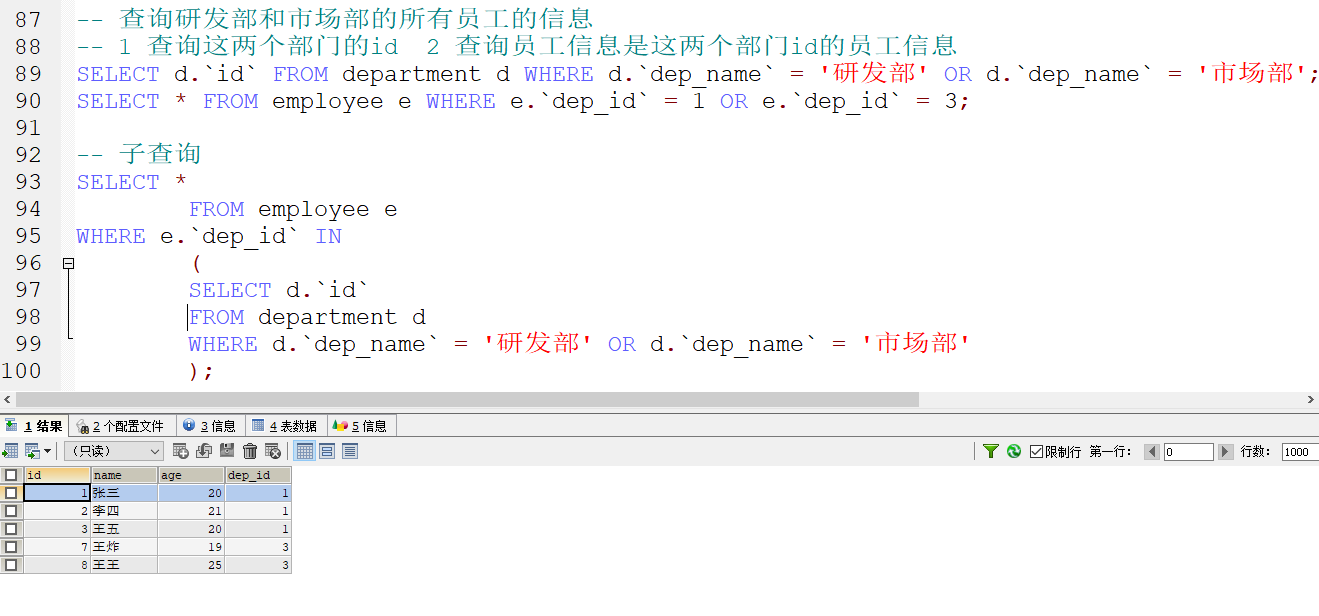
3.
子查询的结果多行多列
-
子查询作为一张虚拟表进行表的查询
-
还可以用内连接进行查询
4.
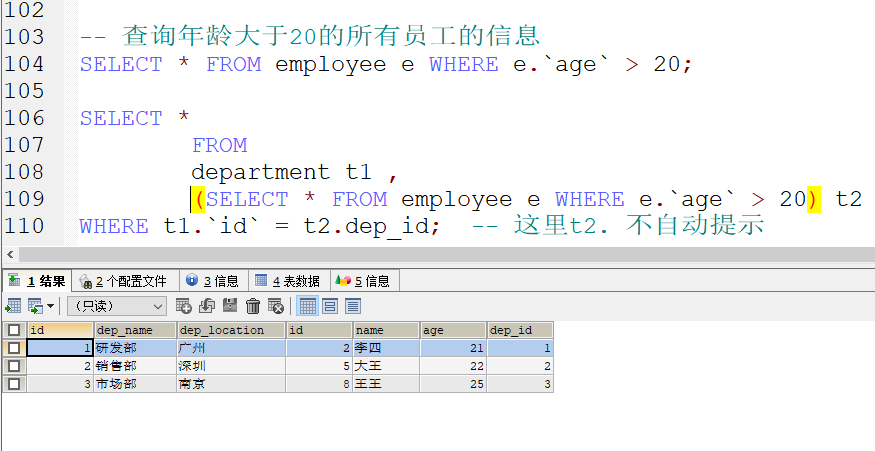
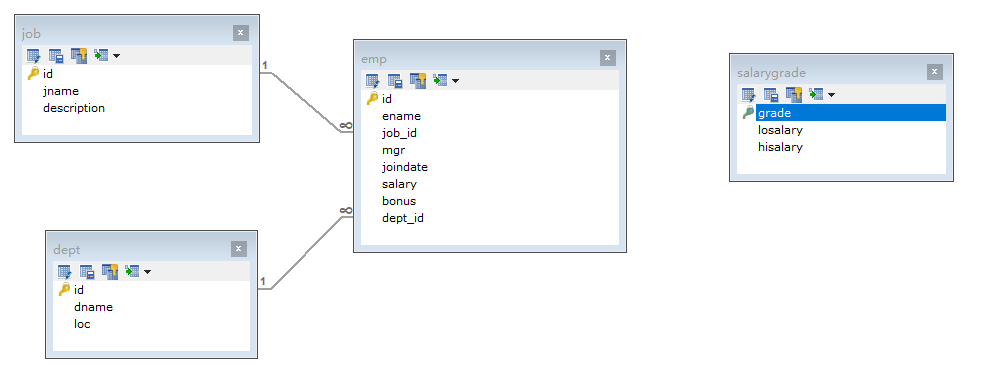
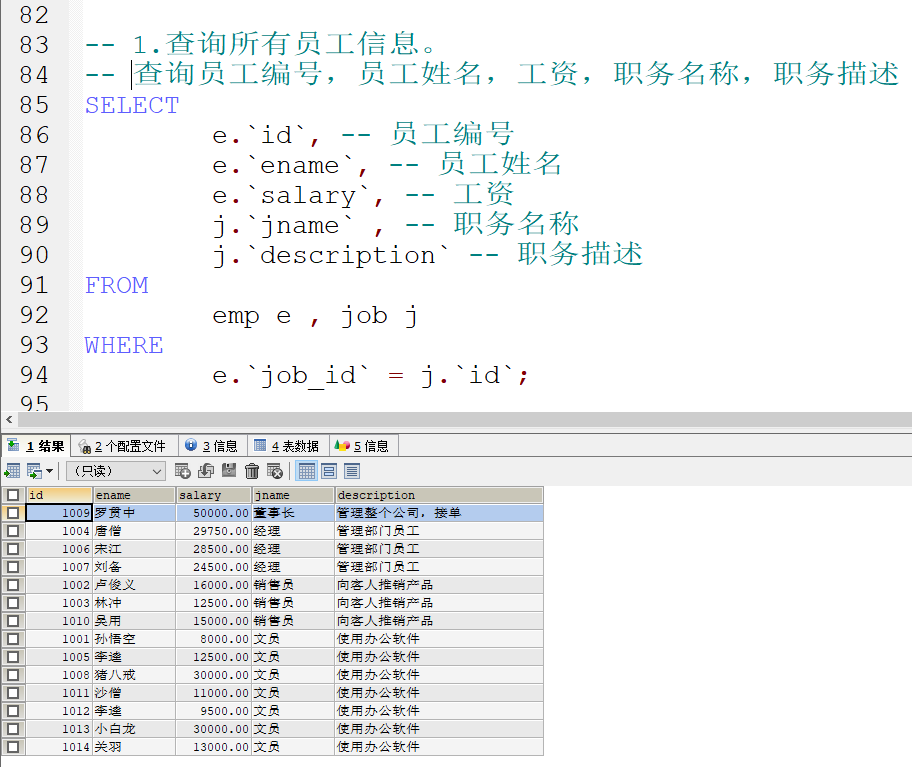
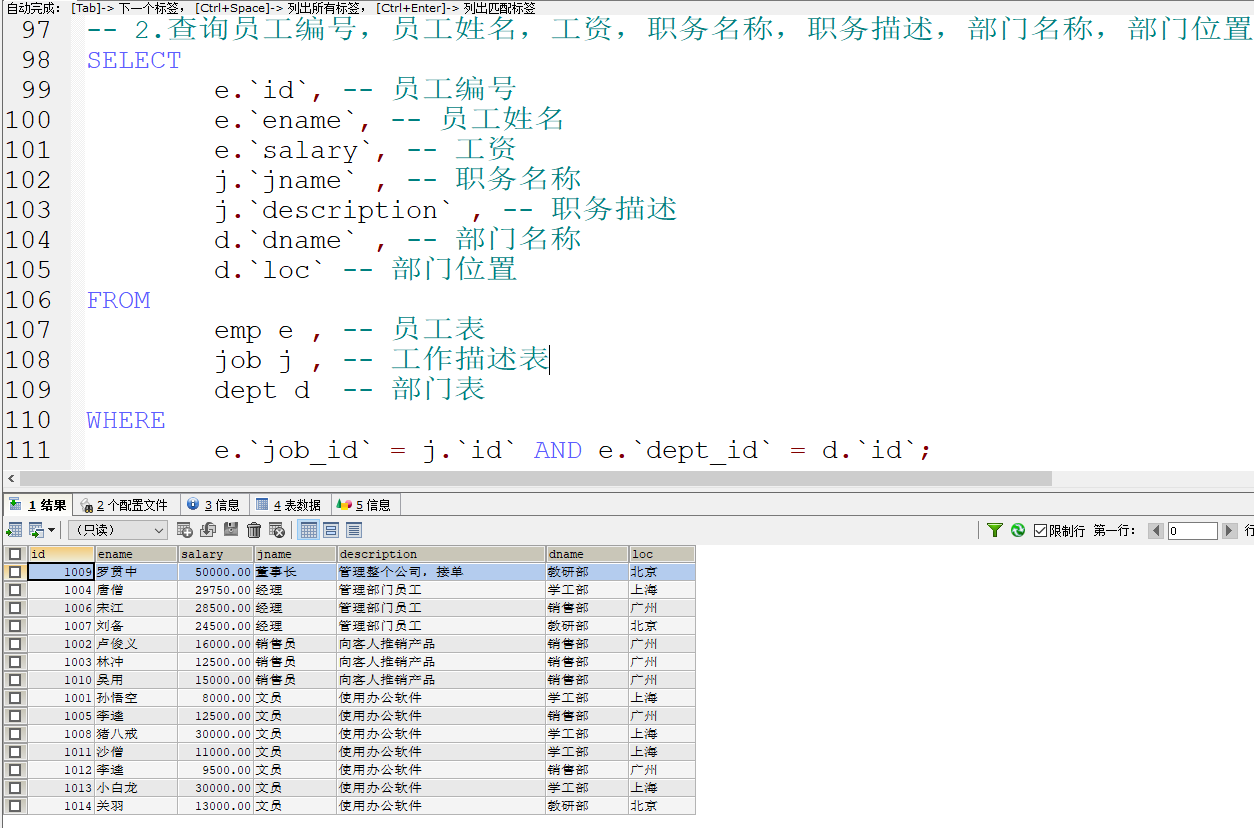
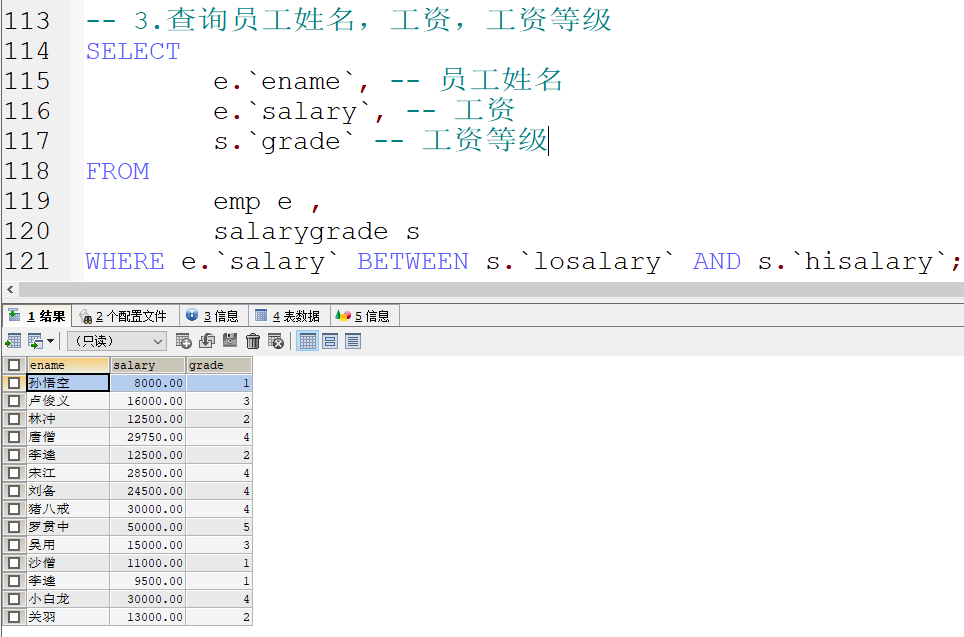
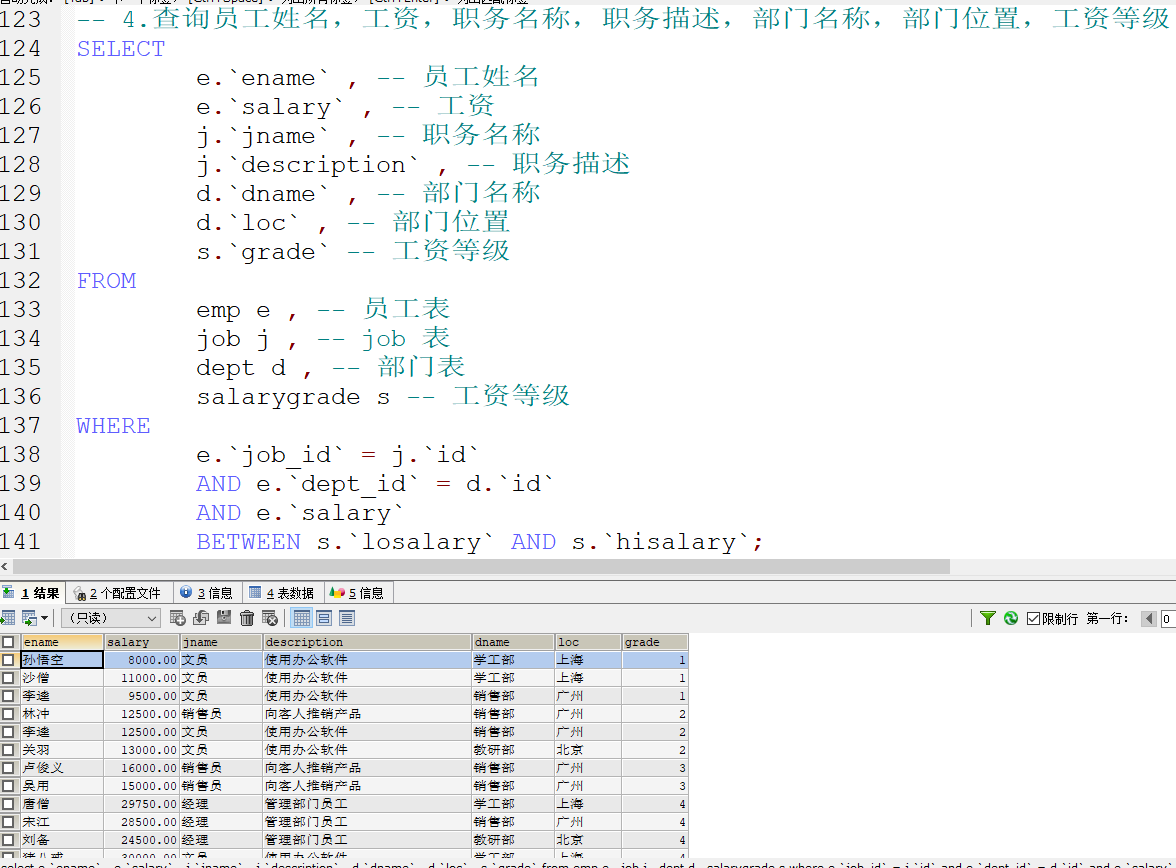
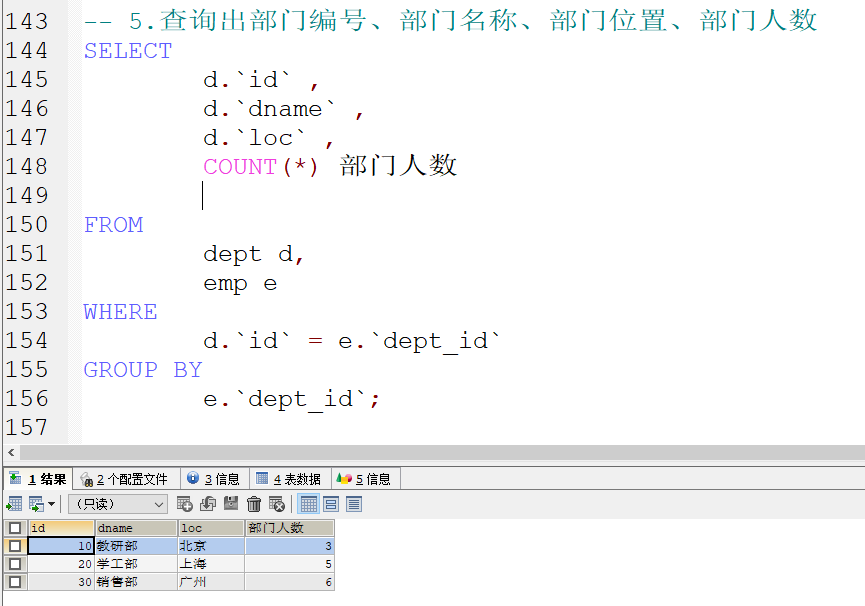
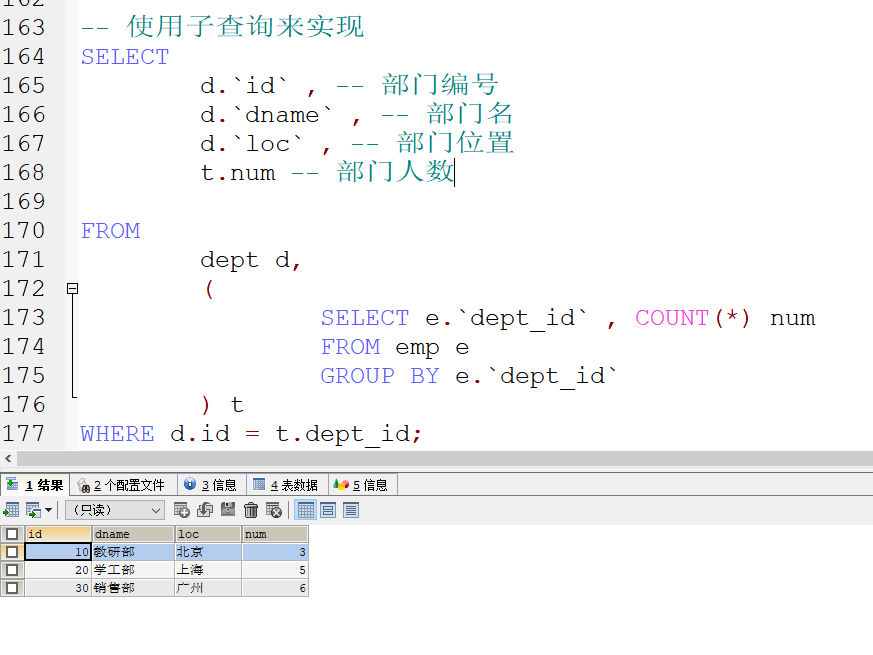
多表查询练习
表结构
完成需求 :
将工资范围作为条件 使用BETWEEN…AND
- 使用子查询来实现
查询所有的数据
使用左外连接
事务
事务的基本介绍
- 概念 : 如果一个包含多个步骤的业务操作 , 被事务管理 , 那么这些操作就变成了一个整体 , 要么同时成功,要么同时失败.

- 概念 : 如果一个包含多个步骤的业务操作 , 被事务管理 , 那么这些操作就变成了一个整体 , 要么同时成功,要么同时失败.
操作
- 开启事务 : start transaction;
- 回滚 : rollback;
提交 : commit;

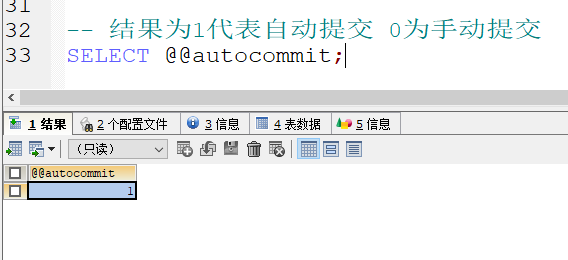
MySQL数据库中的事务默认自动提交
- 一条DML语句自动提交一次事务
- 开启事务的话,需要手动提交事务. 不提交的话 数据只是在临时状态
- Oracle数据库默认手动提交
修改事务的默认提交方式
查看事务的提交方式
修改默认的事务提交方式
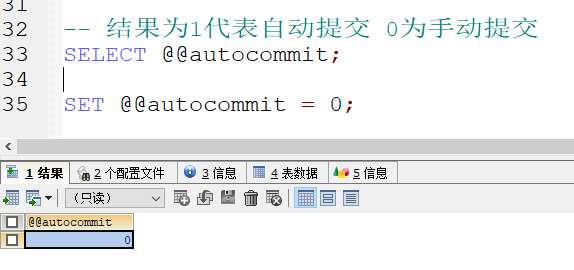
设置成手动提交之后 如果数据修改了 而没有commit的话 数据只是在临时状态 ,表中的数据并未改变
事务的四大特征(重点)
- 原子性(Atomicity) : 被事务管理的SQL语句成为不可分割的最小操作单位, 要么同时成功,要么同时失败
- 持久性(Consistency) : 当事务提交或回滚之后,数据库会持久化地保存数据
- 隔离性(Isolation) : 多个事务之间相互独立
- 一致性(Durability) : 事务操作前后,数据总量不变
事务的隔离级别
概念 : 多个事务之间是隔离的,相互独立的. 但是如果多个事务操作同一批数据,则会引发一些问题,设置不同的隔离级别就可以解决这些问题
存在的问题
- 脏读 : 一个事务读取到另一个事务中的没有提交的数据
不可重复读(虚读) : 在同一个事务中,两次读取到的数据不一样
- 比如说一个操作中,事务未提交之前查询结果与提交之后的查询结果不一样,但是进行查询的语句是一样的
幻读 : 一个事务操作(DML)数据表中所有的数据 , 另一个事务添加了一条数据,则第一个事务查询不到自己的修改
- 与多线程加锁相似 ,将表加锁
隔离级别:
read uncommitted : 读未提交
- 产生的问题 : 脏读、不可重复读、幻读
read committed : 读已提交————->(Oracle默认)
- 产生的问题 :不可重复读、幻读
repeatable read : 可重复读————-> (MySQL默认)
- 产生的问题 :幻读
serializable : 串行化
- 解决所有的问题
注意 : 隔离级别从小到大 安全性越来越高, 但是同时 效率越来越低
数据库隔离级别的查询与设置
- — 查询事务隔离级别
SELECT @@tx_isolation;
— 设置事务的隔离级别
SET GLOBAL TRANSACTION ISOLATION LEVEL 隔离级别;
- — 查询事务隔离级别
DCL
DCL :管理用户,授权
管理用户
- 添加用户

- 添加用户
2.
删除用户

3.
修改用户密码


4.
查询用户
-
注意 : 用户的数据存储在mysql数据库中的user 表中
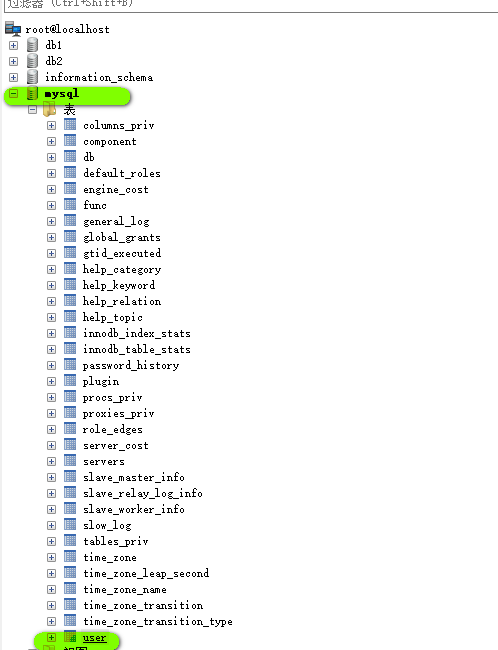
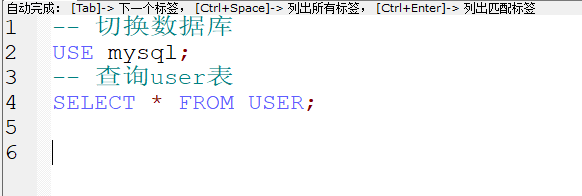
% 通配符 : 表示可以在任意主机使用用户登录数据库
权限管理
- 查询权限
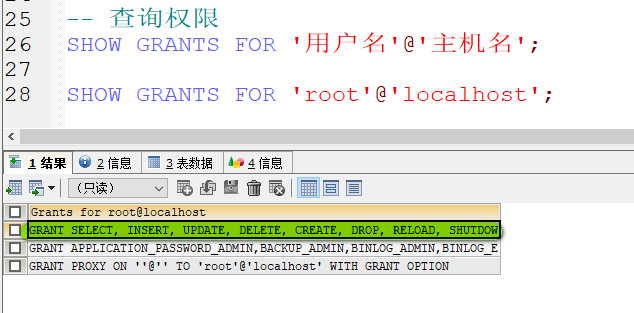
- 查询权限
2.
授予权限

3.
撤销权限

- DBA : 数据库管理员

若有收获,就点个赞吧
0 人点赞
