基础集成
引入项目依赖,下面只引入关键依赖。
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.4.1</version><relativePath/><!-- lookup parent from repository --></parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency></dependencies>
不同的版本有不同的依赖,请选择自己需要的版本,下图是具体的信息。
| Spring Data Release Train | Spring Data Elasticsearch | Elasticsearch | Spring Boot |
|---|---|---|---|
| 2020.0.01 | 4.1.x1 | 7.9.3 | 2.4.x1 |
| Neumann | 4.0.x | 7.6.2 | 2.3.x |
| Moore | 3.2.x | 6.8.12 | 2.2.x |
| Lovelace | 3.1.x | 6.2.2 | 2.1.x |
| Kay2 | 3.0.x2 | 5.5.0 | 2.0.x2 |
| Ingalls2 | 2.1.x2 | 2.4.0 | 1.5.x2 |
对应文档:https://docs.spring.io/spring-data/elasticsearch/docs/current/reference/html/
在当前的 SpringBoot 2.4 + 版本,已经不再使用 TransportClient 和 ElasticsearchTemplate ,而是推荐使用:ElasticsearchRestTemplate ,同时此时不需要手动引入关键类,只需要在 application.peroperties中配置如下信息即可。
spring.elasticsearch.rest.uris=http://localhost:9200
使用的时候,通过 Autowired 注入ElasticsearchRestTemplate 即可。
假如有一个实体类,我们定义如下:
@Setting(settingPath = "es/es-setting.json")@Document(indexName = "book")public class Book {@Idprivate String id;@Field(type = FieldType.Text, searchAnalyzer = "ik_smart", analyzer = "ue-ngram")private String author;@Field(type = FieldType.Text, searchAnalyzer = "ik_smart", analyzer = "ik_max_word")private String name;@Field(type = FieldType.Date, format = DateFormat.date)private LocalDate publishDate;@Field(type = FieldType.Date, format = DateFormat.date_time)private LocalDateTime publishDateTime;//get set toString 省略}
@Setting表示的是ES的配置信息,包括自定义的索引器、分片等信息。不知道如何定义的可以参考文章:自定义分词器案例@Documen中 indexName 是索引的名称@Filed中的信息重点讲解searchAnalyzer和analyzersearchAnalyzer表示的是查询时候该单词如何分词analyzer表示的是索引(保存)的时候如何分词
@Filed中的type表示的是该字段类型,重点强调下时间类型内置 通用的 CRUD 进行简单的基础操作
- 通过方法命名的形式让框架自动生成操作代码:参考链接
当然我个人认为其存在几个缺点
- 通过方法命名进行扩展的做法可能导致部分情况方法名太长了
不太符合中文分词的搜索,比如你要查包含不能
Contains,而应该使用Eqauls【后面会谈到】内置 API
关键接口是:CrudRepository和PagingAndSortingRepositoryCrudRepository集成了基本的 CRUD,如下图所示
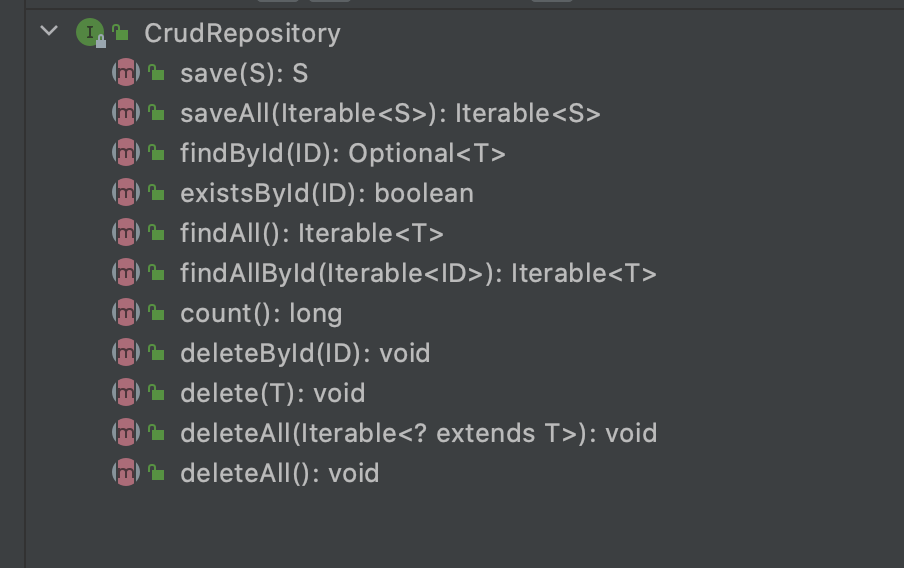
PagingAndSortingRepository在CrudRepository的基础上定义了 分页和排序 操作。
使用的时候,可以直接使用带分页的PagingAndSortingRepository
public interface BookEsMapper extends PagingAndSortingRepository<Book, String> {}
比如定义了上述接口,并且在配置类获取启动类上添加了注解@EnableElasticsearchRepositories(basePackages = "club.hicode.dockerhi")
那么就可以使用了,下面给出一个插入的代码
@Testpublic void testBookSave() {Book book = new Book();book.setName("Kotlin开发手册");book.setAuthor("文在寅");book.setId("012");book.setPublishDate(LocalDate.now());book.setPublishDateTime(LocalDateTime.now());Book result = bookEsMapper.save(book);System.out.println(result);}@Testpublic void testBaseApi() {Optional<Book> optBook = bookEsMapper.findById("012");optBook.ifPresent(System.out::println);Iterable<Book> all = bookEsMapper.findAll();all.forEach(System.out::println);bookEsMapper.deleteById("012");System.out.println("删除 ok");}
执行成功后,通过 DevTools 的指令 GET /book 可以查看到如下信息
{"book" : {"aliases" : { },"mappings" : {"properties" : {"_class" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"author" : {"type" : "text","analyzer" : "ue-ngram"},"id" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"name" : {"type" : "text","analyzer" : "ik_max_word","search_analyzer" : "ik_smart"},"publishDate" : {"type" : "date","format" : "date"},"publishDateTime" : {"type" : "date","format" : "date_time"}}},"settings" : {"index" : {"routing" : {"allocation" : {"include" : {"_tier_preference" : "data_content"}}},"number_of_shards" : "1","provided_name" : "book","creation_date" : "1611655951204","analysis" : {"filter" : {"my_pinyin" : {"keep_joined_full_pinyin" : "true","lowercase" : "true","none_chinese_pinyin_tokenize" : "false","keep_original" : "true","keep_none_chinese_together" : "true","keep_first_letter" : "true","trim_whitespace" : "true","type" : "pinyin","keep_none_chinese" : "true","keep_full_pinyin" : "false"}},"char_filter" : {"ue_char_filter" : {"type" : "mapping","mappings" : ["- => ,","— => ,"]}},"analyzer" : {"ue_ik_pinyin_analyzer" : {"filter" : ["my_pinyin"],"char_filter" : ["html_strip","ue_char_filter"],"type" : "custom","tokenizer" : "ik_max_word"},"ue-ngram" : {"type" : "custom","char_filter" : ["html_strip","ue_char_filter"],"tokenizer" : "ngram_tokenizer"}},"tokenizer" : {"ngram_tokenizer" : {"token_chars" : ["letter","digit"],"min_gram" : "2","type" : "ngram","max_gram" : "3"}}},"number_of_replicas" : "1","uuid" : "ipVtuyH6Qsy422WWQ39gQw","version" : {"created" : "7100199"}}}}}
描述下 settings 的内容就是上文代码中@Setting(settingPath = "es/es-setting.json")设置中的内容。
扩展 API
下面给出实例代码
public interface BookEsMapper extends PagingAndSortingRepository<Book, String> {List<Book> findByAuthorContains(String author);List<Book> findByAuthorEquals(String author);List<Book> findByNameContaining(String name);List<Book> findByNameEquals(String name);}
当我们调用这些代码的时候,为了更方便的进行调试和展示 Query语句,建议在配置文件application.properties添加
logging.level.tracer=TRACE
个人不建议使用 在中文语义下使用 JPA 进行Text的查询,因为这其实挺让人迷糊的,我在学习的时候踩了不少坑。
举个例子:Book类中定义了 name字段的索引分词是 ik_max_word,检索分词用的是 ik_smart。
对于kotlin 开发手册,索引的时候分词为:kotlin/开发/手册
但是如果使用findByNameContaining("发手")的时候,虽然在语义上是发手是包含于开发手册,但是因为分词的缘故,检索不到。
综上,个人建议 JPA检索上的使用更应该是基于 Term的查询和英文检索。新增、修改、删除是没有问题的。
总结
本文主要是 2 个点:
- 实体类构建:关键注解、Setting 设置
- JPA的基本 API和简单 API,更重要的是用于检索的时候,因为 API语义问题,可能给初学者造成误解。

若有收获,就点个赞吧
0 人点赞
