垂直拆分按业务拆分,比如库 third_party 存放三方相关表,库 device 存放设备相关表。水平拆分则是按数据拆分,比如 sporthealth_0.t_sport_record_0。本文阐述水平拆分的两个思路,并提供一个可扩展的分片方案。
数据的存储方式
堆组织表
Oracle 的 create table 默认创建堆表。由于默认没有索引,堆表的写操作效率很高,代价是条件查询需要全表扫描,因此适合写多读少场景。
如果预期读操作也不少,就需要 create index 另外维护索引,但既然用上索引了,不如考虑使用索引组织表。
索引组织表
索引组织表的数据和主键索引是一块维护的,主要有 B树(MongoDB)、B+树(MySQL)、B*树 三种实现。
B-tree
平衡N叉搜索树,有以下特性:
- N叉,相较于 BST 的深度更小。可以减少磁盘IO 次数,适合外部存储
- 搜索树,root 大于 left node ,小于 right node。保证了搜索 avg case 为 O(logN)
- 平衡,leaf node 的深度最大相差 1。保证了搜索 worst case 为 O(logN)
所有 node 均存储数据。保证了搜索 best case 为 O(1)
B+ tree
改自 B-tree,有以下特性:
数据只存储在 leaf node,其它 node 只存储索引。这就有可能把索引完全加载进内存,适合外部存储。
- leaf node 之间通过 pointer 相连。方便全表扫描,因为关系型数据经常要做 join,此外 range search 也称为可能。
文档数据库 MongoDB 的格式存储是 BSON ,用一个 List 就可以表达 1 to N 关系。这意味着只要根据唯一索引找到文档,就可以得到全部信息,不需要 join(遍历),并且搜索越快越好,明显 B树更合适。
B* tree
单表能存多少行
MySQL 官方文档说明 InnoDB 单表最大支持 64TB,《阿里巴巴 Java 开发手册》提出单表行数超过 500 万行或者单表容量超过 2GB 推荐进行分库分表,生产环境中随手记用户表 5000 万行也问题不大。
理论上,只要内存足够大,索引就可以完全进入 buffer pool,即使单表数据量再大,根据 B+ 树的原理,最多一次磁盘IO 就可以找到数据了。实际上,内存是有限的,所以希望 B+ 树的深度尽量小,以减少磁盘IO 次数。
innodb page
HDD磁盘最小的管理单位扇区 Sector 大小是512Bytes,但 Linux一次I/O是8个扇区即 4096Bytes,所以可以发现 Linux 空文件也有 4KB 大小。
执行 show variables 发现 innodb_page_size=16kb,页 = 页头(120B) + 行数据(15232B) + 页目录(1024B) + 页尾(8B)。对于非叶子节点,行数据 = 主键 bigint(8B)+ 页号 FIL_PAGE_OFFSET(4B) = 12Bytes。
那么,一个非叶子节点可以存 15232B / 12B ≈ 1269 个索引,换言之,这棵m叉树的 fanout 是 1269,非常高。
估算公式
有了对 innodb page 的大致认识就可以开始估算了,下面引入3个变量 x,y,z。
总行数 = (x ^ (z-1)) * y
假设一行数据=1024KB,由于 page 的行数据大小为 15232B,那么 y=15232/1024 ≈ 15 行数据。
已知 x=1269, y=15,那么:
对于两层B+树,z=2,则总行数 = (1280 ^ (2-1)) 15 ≈ 2w
对于三层B+树,z=3,则总行数 = (1280 ^ (3-1)) 15 ≈ 2.5kw
水平拆分方案
选择分片键,要从两方面考虑:热点、扩容。热点的意思是对订单的操作集中到1个表中,其他表的操作很少,扩容是指预估不足的情况下,需要重新设置路由。
常见的分片键有日期、订单号、用户标识。以订单号为例,先预估未来几年的订单量为 4000万,每张表存 1000万,我们可以设计4张表进行存储。
hash 取模方案
对指定的路由key(如:id)对分表总数进行取模,上图中,id=12的订单,对4进行取模,也就是会得到0,那此订单会放到0表中。id=13的订单,取模得到为1,就会放到1表中。
- 优点:
订单数据可以均匀的放到那4张表中,这样此订单进行操作时,就不会有热点问题。
订单有个特点就是时间属性,一般用户操作订单数据,都会集中到这段时间产生的订单。如果这段时间产生的订单 都在同一张订单表中,那就会形成热点,那张表的压力会比较大。
- 缺点:
将来的数据迁移和扩容,会很难。
如:业务发展很好,订单量很大,超出了4000万的量,那我们就需要增加分表数。如果我们增加4个表
一旦我们增加了分表的总数,取模的基数就会变成8,以前id=12的订单按照此方案就会到4表中查询,但之前的此订单时在0表的,这样就导致了数据查不到。就是因为取模的基数产生了变化。
range 范围方案
range方案也就是以范围进行拆分数据。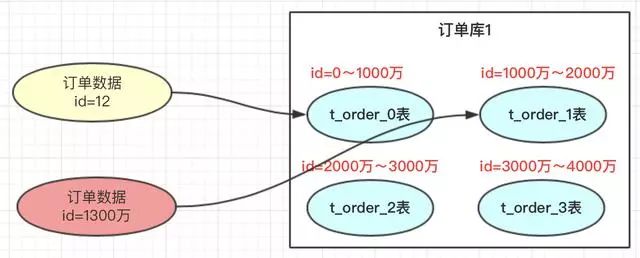
range方案比较简单,就是把一定范围内的订单,存放到一个表中;如上图id=12放到0表中,id=1300万的放到1表中。设计这个方案时就是前期把表的范围设计好。通过id进行路由存放。
- 优点
即时再增加4张表,之前的4张表的范围不需要改变,id=12的还是在0表,id=1300万的还是在1表,新增的4张表他们的范围肯定是 大于 4000万之后的范围划分的。
- 缺点
有热点问题,我们想一下,因为id的值会一直递增变大,那这段时间的订单是不是会一直在某一张表中,如id=1000万 ~ id=2000万之间,这段时间产生的订单是不是都会集中到此张表中,这个就导致1表过热,压力过大,而其他的表没有什么压力。
hybrid 混合方案
预期订单id 范围 [0, 4000w],假设有3个DB,并且 DB_0 的硬盘空间更大。
现定义一个概念 group,这组里面包含了一些分库以及分表,如下图: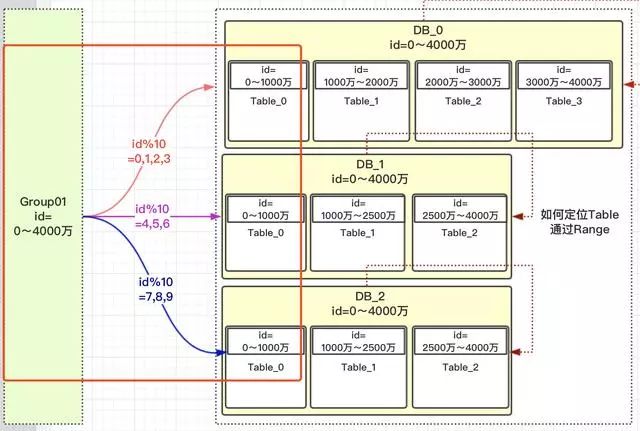
如何路由
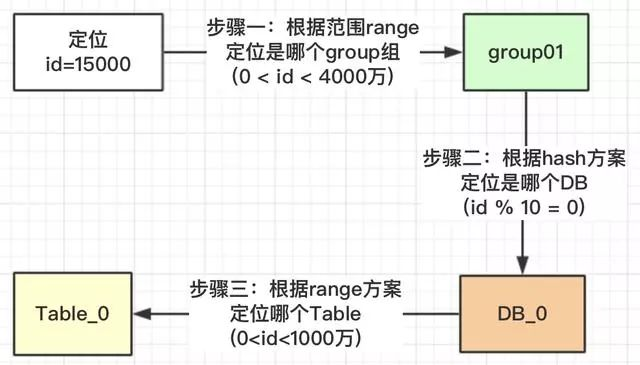
热点问题
由于使用了 hash 方案对 10 取模,范围 [0, 1000w] 的 id 都均匀的分配到 DB_0、DB_1、DB_2 三个数据库中的 Table_0表中,解决了热点问题。
对10进行取模,如果值为 [0,1,2,3] 就路由到 DB_0,[4,5,6] 路由到 DB_1,[7,8,9] 路由到 DB_2。这样的设计可以把多一点的数据放到 DB_0 中,因为它的存储更大。
上面一大段的介绍,就解决了热点的问题,以及可以按照服务器指标,设计数据量的分配。
扩容问题
需要扩容的时候,再设计一个group02组,并定义好此group的数据范围即可。
因为是新增的一个group01组,所以就没有什么数据迁移概念,完全是新增的group组,而且这个group组照样就防止了热点,也就是【4000万,5500万】的数据,都均匀分配到三个DB的table_0表中,【5500万~7000万】数据均匀分配到table_1表中。
思路确定了,通过 3张表建立 group,DB,table 之间的关系。为了避免影响性能,三张关联表可以缓存到本地,一旦需要扩容,通过分布式配置中心 Heracles 增加 group02 的关联关系,无需重启。

参考文献

若有收获,就点个赞吧
0 人点赞
