MongoDB 扩容增加分片的时候,需要保证数据在分片中均衡,其通过 sharding cluster 实现。
要说明mongo的分片原理,我们需要先了解下mongo的分片集群的组件和他们之间的关系。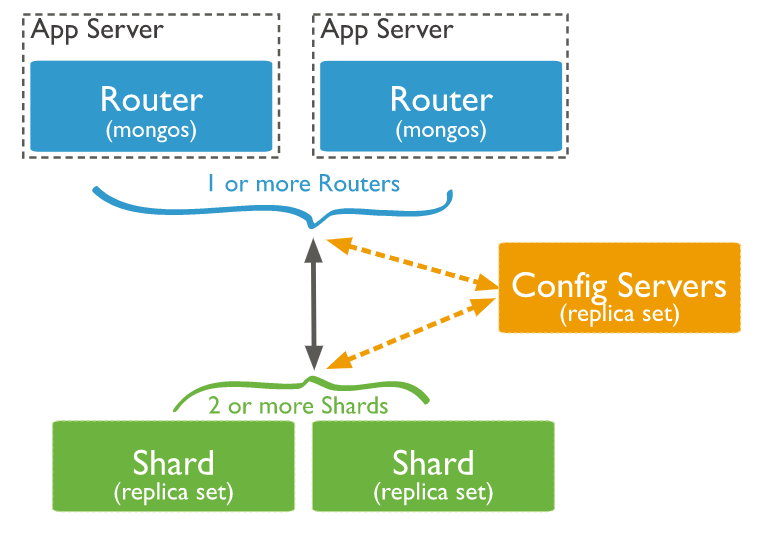
分片
MongoDB分片集群将数据分布在一个或多个分片上。每个分片部署成一个MongoDB副本集,该副本集保存了集群整体数据的一部分。因为每个分片都是一个副本集,所以他们拥有自己的复制机制,能够自动进行故障转移。你可以直接连接单个分片,就像连接单独的副本集一样。但是,如果连接的副本集是分片集群的一部分,那么只能看到部分数据。这也是mongo官方说的:您必须连接到mongos路由器才能与分片集群中的任何集合进行交互。客户端永远不要直接连到单个分片来执行读或写操作。
mongos路由器
如果每个分片都包含部分集群数据,那么还需要一个接口连接整个集群。这就是mongos。mongos进程是一个路由器,将所有的读写请求指引到合适的分片上。如此一来,mongos为客户端提供了一个合理的系统视图。
mongos进程是轻量级且非持久化的。部署多个mongos路由器可支持高可用性和可伸缩性。一种常见的模式是mongos在每个应用程序服务器上放置一个 。 这种模式下路由器可以减少应用程序和路由器之间的网络延迟。或者,您可以将mongos路由器放置在专用主机上。大型部署一般会采用这种方式,因为它使客户端应用程序服务器的数量与mongos实例的数量脱钩 。这样可以更好地控制mongod实例服务的连接数。应用程序连接本地的mongos,而mongos管理了指向单独分片的连接。
配置服务器
上面我们说了mongs进程是非持久化的,如果mongs重启,那之前的路由信息和其他集群信息就全部消失了,所以这种情况下必须要有地方能持久化集群的公认状态;这就是配置服务器的工作,其中持久化了分片集群的元数据,该数据包括:每个数据库,集合和特定范围数据的位置;一份变更记录,保存了数据在分片之间进行迁移的历史信息。配置服务器中保存的元数据是某些特定功能和集群维护时的重中之重。举例来说,每次有mongos进程启动,它都会从配置服务器中获取一份元数据的副本。没有这些数据,就无法获得一致的分片集群视图。该数据的重要性对配置服务器的设计和部署也有影响。
如上面结构图中所示,有三个配置服务器,但它们并不是以副本集的形式部署的。它们比异步复制要求更严格;mongos进程向配置服务器写入时,会使用两阶段提交。这能保证配置服务器之间的一致性。在各种生产环境的分片部署中,必须运行三个配置服务器,这些服务器都必须部署在独立的机器上以实现冗余。
下图是我们生产的mongo集群的配置,有4个分片。ps:
Mongodb复制集(replica set)由一组Mongod实例(进程)组成,包含一个Primary节点和多个Secondary节点,Mongodb Driver(客户端)的所有数据都写入Primary,Secondary通过oplog来同步Primary的数据,保证主从节点数据的一致性;复制集在完成主从复制的基础上,通过心跳机制,一旦Primary节点出现宕机,则触发选举一个新的主节点,剩下的secondary节点指向新的Primary,时间应该在10-30s内完成感知Primary节点故障,实现高可用数据库集群。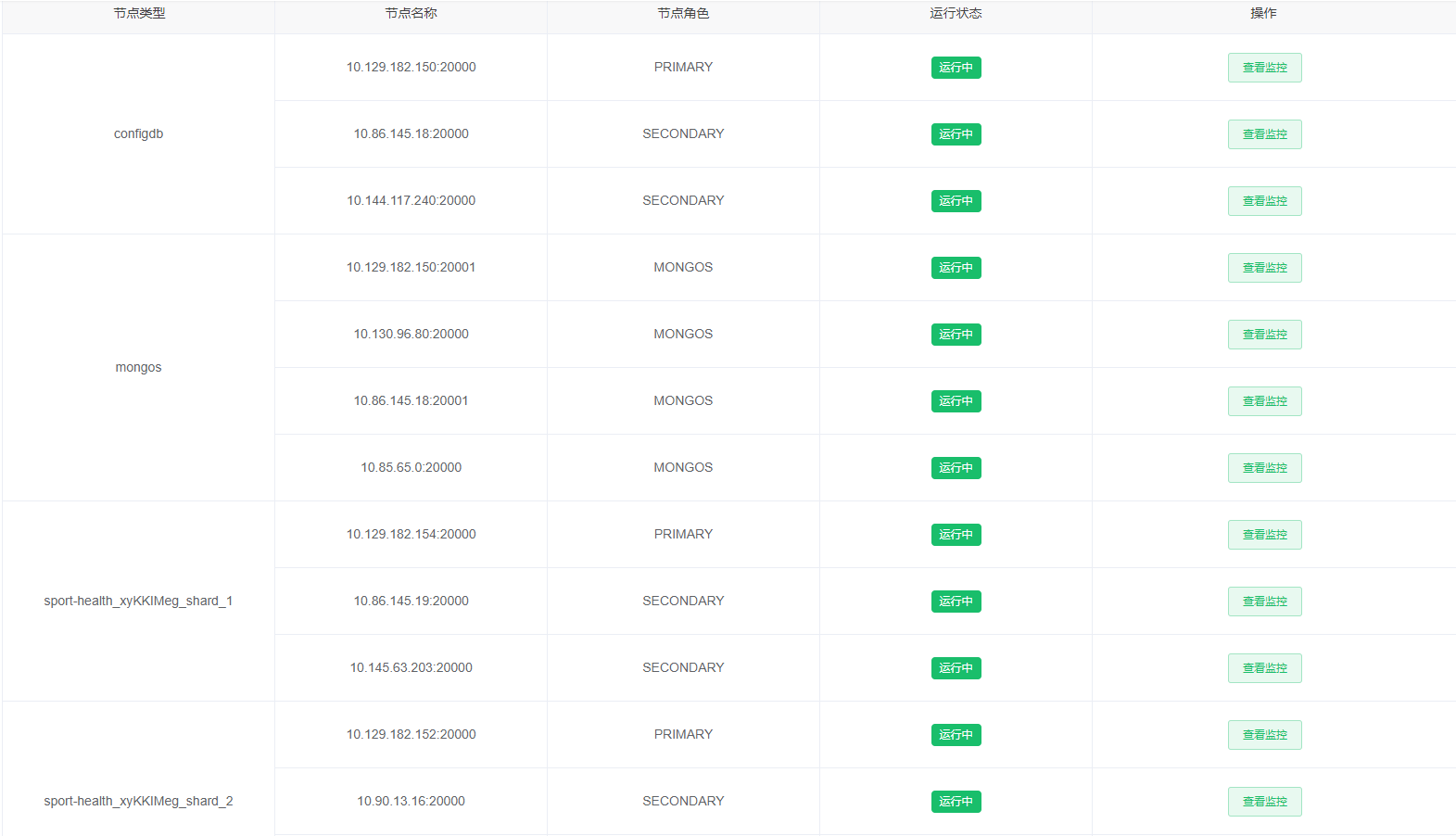
说完了mongdb的分片组件,我们说说mongdb的分片键。分片键是用于确定集合文档在集群的分片之间的分布的。MongoDB使用所谓的分片键让每个文档在这些范围里找到自己的位置。在对该集合进行分片时,必须将其中的一个或多个字段申明为分片键。mongodb目前主要有两种数据分片的策略。范围分片(Range based sharding)和hash分片(Hash based sharding)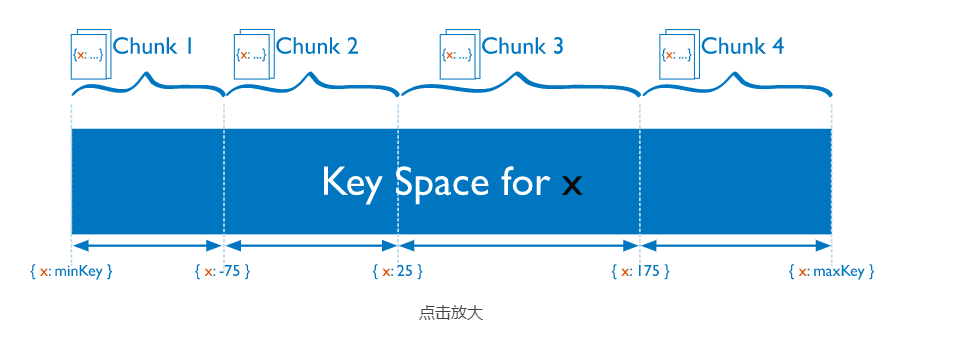
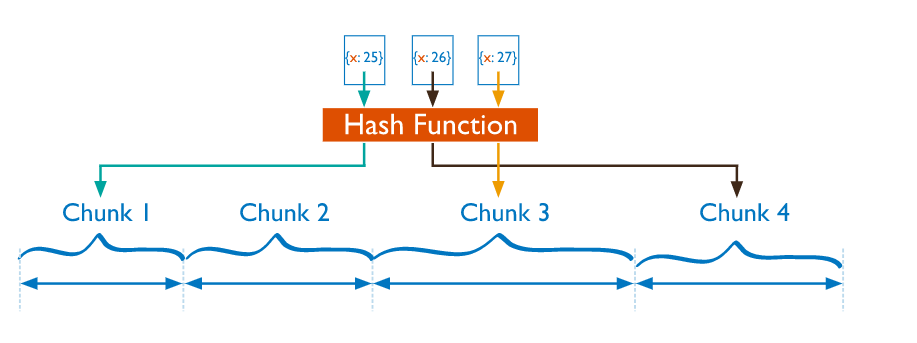
从上面的图可以看到,分片键是和chunk直接关联的。那chunk是什么东西呢?它是位于一个分片中的一段连续的分片键范围。举例来说,可以假设docs集合分布在两个分片A和B上,它被分成下表所示的多个块。每个块的范围都由起始值和终止值来标识。我们已A B两个分片为例.
| 初始值 | 终止值 | 分片 |
|---|---|---|
| -∞ | 10000 | A |
| 10001 | 20000 | B |
| 30001 | 40000 | A |
| 20001 | 30000 | B |
| 30001 | +∞ | A |
从上面的表我们可以看到很奇怪的现象,每个块虽然都是一段连续范围内的数据,但是这些块可以出现在任意分片上。块是逻辑概念而非物理概念,这一点很重要。了解了这两点,我们就能知道高效分片的秘密了。
拆分与迁移
分片机制的重点是块的拆分(spliting)与迁移(migration)
首先,考虑一下块拆分的思想。在初始化分片集群时,只存在一个块,这个块的范围涵盖了整个分片集合。那该如何发展到有多个块的分片集群呢?答案就是块大小达到某个阈值是就会对块进行拆分。默认的块的最大块尺寸时64MB或者100000个文档,先达到哪个标准就以哪个标准为准。在向新的分片集群添加数据时,原始的块最终会达到某个阈值,触发块的拆分。这是一个简单的操作,基本就是把原来的范围一分为二,这样就有两个块,每个块都有相同数量的文档。
请注意,块的拆分是个逻辑操作。当MongoDB进行块拆分时,它只是修改块的元数据就能让一个块变为两个。因此,拆分一个块并不影响分片集合里文档的物理顺序。也就是说拆分既简单又快捷。
你可以回想一下,设计分片系统时最大的一个困难就是保证数据始终均匀分布。MongoDB的分片集群是通过在分片中移动块来实现均衡的。我们称之为迁移,这是一个真实的物理操作。
迁移是由名为均衡器(balancer)的软件进程管理的,它的任务就是确保数据在各个分片中保持均匀变化。通过追踪各分片上块的数量,就能实现这个功能。虽然均衡的触发会随总数据量的不同而变化,但是通常来说,当集群中拥有块最多的分片与拥有块最少的分片的块数相差大于8时,均衡器就会发起一次均衡处理。在均衡过程中,块会从块较多的分片迁移到块较少非分片上,直到两个分片的块数大致相等为止。具体阈值如下:
总的来说:块是逻辑的,是一个键的范围集合,集合中的ID就落在这个范围中。如果超过块的范围就分出来另一个块。加入分片的时候会触发均衡器将原来属于其他分片的块迁移到新加入的块中。同时修改配置服务器中块属于的位置。

若有收获,就点个赞吧
0 人点赞
