chromedriver下载地址
http://npm.taobao.org/mirrors/chromedriver/
一、浏览器基本操作
1.1 、 启动
| 方法 | 作用 |
|---|---|
| Chrome() | 启动浏览器,不同浏览器方法名不一样 |
| get() | 打开某个网页,网页地址以参数传入方法 |
| quit() | 关闭浏览器 |
不同浏览器启动方法
# Firefox 火狐浏览器
driver = webdriver.Firefox()
# 谷歌浏览器 #
driver = webdriver.Chrome()
# ie 浏览器
driver = webdriver.Ie()
# Edge 浏览器
driver = webdriver.Edge()
# Opera 浏览器
driver = webdriver.Opera()
# PhantomJS浏览器
driver = webdriver.PhantomJS()
from selenium import webdriver
# 指定驱动位置
path = "D:\\chromedriver.exe"
# 启动浏览器
driver = webdriver.Chrome(executable_path=path)
# 打开一个网页 如:百度
driver.get("http://www.baidu.com/")
# 关闭浏览器
driver.quit()
第三方库webdriver_manager,管理webdriver
# 第三方库管理webdriver
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
1.2、 浏览器窗口的操作
| 方法 | 作用 |
|---|---|
| maximize_window() | 窗口最大化 |
| minimize_window() | 窗口最小化 |
| fullscreen_window() | 全屏化窗口 |
| set_window_size(width,height) | 设置浏览器大小 |
| set_window_position(x,y) | 指定浏览器位置 |
# 窗口最大化
driver.maximize_window()
# 等待3秒
sleep(3)
# 窗口最小化 等于看不见
driver.minimize_window()
sleep(3)
# 窗口全屏化
driver.fullscreen_window()
sleep(3)
# 设置窗口大小 宽度,高度
driver.set_window_size(300,200)
sleep(3)
# 指定窗口位置 宽度,高度 以左上角 为坐标
driver.set_window_position(100,150)
sleep(3)
1.3 、网页基本操作
| 方法 | 作用 |
|---|---|
| forward() | 前进 |
| back() | 后退 |
| refresh() | 刷新 |
| closs() | 关闭 |
from selenium import webdriver
from time import sleep
options = webdriver.ChromeOptions()
# 指定驱动
driver_path = "D:\\drivers\\chromedriver.exe"
driver = webdriver.Chrome(driver_path,options=options)
# 先打开百度网页
driver.get("http://www.baidu.com")
# 等待五秒
sleep(3)
# 在打开东方财富网
driver.get("https://www.eastmoney.com/")
# 然后 后退 到百度
driver.back()
# 等待3秒
sleep(3)
# 在刷新一下
driver.refresh()
# 给1秒的缓冲
sleep(1)
# 在前进到 东方财富网
driver.forward()
#关闭网页
driver.close()
二、元素定位
我们对网页的各种操作,其实都是对前端元素的操作,那你想实现自动化操作,首要就是查找你要操作的元素,只有匹配到元素才能实现后续的操作。
selenium 元素定位有八种方式
| 方法 | 作用 |
|---|---|
| find_element_by_id() | 根据id属性定位 |
| find_element_by_name() | 根据name属性定位元素 |
| find_element_by_link_text() | 根据超链接的文字信息 |
| find_element_by_partial_link_text() | 根据超链接的部分文字信息 |
| find_element_by_tag_name() | 根据tag名称 |
| find_element_by_class_name() | 根据class名称 |
| find_element_by_xpath() | 根据xpath表达式 |
| find_element_by_css_selector() | 根据css选择器 |
注:
find_element_by_xx
如果没有匹配到元素,则执行报错
如果匹配到一个元素,则返回元素
如果匹配到多个元素,则返回元素
find_elements_by_xx
如果没有匹配到元素,则返回空列表
如果匹配到一个元素,则返回包含一个元素的列表
如果匹配到多个元素,则返回包含多个元素的列表
2.1、 id定位
id 属性在html文件里具有唯一性,是我们优先使用的一种方法
from seleniumimport webdriver
d= webdriver.Chrome()
d.get('https://www.baidu.com')
d.find_element_by_id("kw").send_keys("hello")
2.2 、name 定位
from seleniumimport webdriver
d= webdriver.Chrome()
d.get('https://www.baidu.com')
d.find_element_by_name("wd").send_keys("hello")
2.3、 class 定位
from seleniumimport webdriver
d= webdriver.Chrome()
d.get('https://www.baidu.com')
d.find_element_by_class_name('s_ipt').send_keys('hello')
# 复合class 如:class="bg s_ipt_wr quickdelete-wrap" ,有多个calss属性由空格隔开,我们只能取其中一个
d.find_element_by_class_name('s_ipt_wr')
2.4、 tag 定位
我们就知道HTML是通过tag来定义功能的,比如input是输入,table是表格,等等…。每个元素其实就是一个tag,一个tag往往用来定义一类功能,我们查看百度首页的html代码,可以看到有很多重复的div,input,a等tag, 多个tag的时候 我们要用find_elements_by_tag_name() 他返回的是一个列表 ,我们要对这个列表选索引值进行操作 在我们工作中较少用这种定义方法,仅了解就行。
from selenium import webdriver
d = webdriver.Chrome("D:\\chromedriver.exe")
d.get("http://www.baidu.com")
d.find_element_by_tag_name("area").click()
2.5、link_text
link_text 是我们定位一个超链接最常用的,我们的元素值就是这个超链接的文本 ,精确匹配
from seleniumimport webdriver
import time # 调了一个时间模块
d= webdriver.Chrome()
d.get('https://www.baidu.com')
d.find_element_by_link_text('新闻').click()
time.sleep(5) # 让等待5秒
d.quit()
2.6、 partial_link_text
partial_link_text 也用来定位超链接 ,只不过他与link_text 精确匹配不同 他是 一个模糊匹配
from selenium import webdriver
from time import sleep
options = webdriver.ChromeOptions()
# 指定驱动
driver_path = "D:\\drivers\\chromedriver.exe"
driver = webdriver.Chrome(driver_path,options=options)
# 先打开百度网页
driver.get("http://www.baidu.com")
driver.find_element_by_id("kw").send_keys("selenium")
sleep(1)
driver.find_element_by_id("su").click()
sleep(3)
# 模糊查找 selenium中文网 并点击一下
driver.find_element_by_partial_link_text("selenium中文网").click()
sleep(5)
driver.quit()
2.7、 xpath 定位,路径表达式定位
前面介绍的几种定位方法都是在理想状态下,有一定使用范围的,那就是:在当前页面中,每个元素都有一个唯一的id或name或class或超链接文本的属性,那么我们就可以通过这个唯一的属性值来定位他们。但是在实际工作中并非有这么美好,有时候我们要定位的元素并没有id,name,class属性,或者多个元素的这些属性值都相同,又或者刷新页面,这些属性值都会变化。那么这个时候我们就只能通过xpath或者CSS来定位了。
2.7.1 路径
绝对路径:从根节点开始,到目标位置
xpathstr =”/html/body/div[1]/div[1]/div/form/span[1]/input”
d.find_element_by_xpath(xpathstr)
特点:路径唯一,但是通常比较深,容易受页面改动影响
相对路径:从任意位置,或当前位置开始
xpathstr =”//input[@id=’kw’]”
d.find_element_by_xpath(xpathstr)
特点:书写形式灵活多样,推荐使用
2.7.2 相对匹配方式
下面是相对路径几种方式介绍
根据标签类型定位
xpathstr =”//input” 这样写是匹配input类型的所有元素
根据顺序定位:
xpathstr =”//input[2]” 有层级中的第二个input元素
xpathstr =”//div[last()-1] 查找页面上各个层级中倒数第二个div元素
根据元素属性定位:
xpathstr =”//input[@value]” input类型的标签,并且有value属性的元素
xpathstr =”//input[@value = ‘kw’]” input类型value值为kw 的元素
使用运算符:
xpathstr =”//input[@value=’kw’ and @ id=’ad’] input类型value属性值为kw 并且id属性为 ad的元素
xpathstr =”//input[@maxlength <256]” maxlength值小于256的input元素
层级与属性结合定位
xpathstr = “//form/input” form元素下的input子元素
xpathstr = “//div[@class]/a[3]” div的第三个a标签元素,div具有class属性
使用通配符
xpathstr = “//tools/“ 选出所有的tools下的所有的子元素
xpathstr = “//[@*=”s_tab”]” 任意类型,任意属性值为’s_tab’的元素
模糊匹配
xpathstr = “//a[contains(@href,’logout’)]” 使用contains函数进行部分匹配
xpathstr = “//a[contains(text(),退出)]” 超链接文本内容包括”退出字符”
xpath更多可以参考:https://www.w3school.com.cn/xpath/index.asp
from selenium import webdriver
import time
d= webdriver.Chrome()
d.get('https://www.baidu.com')
# 定位搜索框,然后输入hello
d.find_element_by_xpath('//*[@id="kw"]').send_keys('hello')
time.sleep(5)
d.quit()
2.8、 css_selector 定位
css定位相对比xpath要简洁些,定位速度也要快些,selenium也比较推荐这种方式,但是学习起来会比较难理解,因为他有太多的样式,这里介绍一下比较简单常用的几种方式
| 选择器 | 例子 | 描述 |
|---|---|---|
| #id | #firstname | 选择 id=”firstname” 的元素。 |
| .class | .intro | 选择 class=”intro” 的所有元素。 |
| element>element | div > p | 选择父元素是 的所有 元素。 |
| [attribute=value] | [target=_blank] | 选择带有 target=”_blank” 属性的所有元素。 |
更多可参考:https://www.w3school.com.cn/cssref/css_selectors.asp
from selenium import webdriver
import time
d = webdriver.Chrome()
d.get('https://www.baidu.com')
# 加断言,若在直接就下一步 不会有什么反应,如果不在 就会报错
assert '百度' in d.title
# 先清除一下搜索框
d.find_element_by_css_selector('#kw').clear()
d.find_element_by_css_selector('#kw').send_keys('hello')
time.sleep(5)
d.quit()
在介绍两种现在比较推荐的方法
from selenium import webdriver
from selenium.webdriver.common.by import By
d = webdriver.Chrome("D:\\chromedriver.exe")
d.get("http://www.baidu.com")
d.find_element(By.ID,"kw").send_keys("selenium")
d.find_elements(By.NAME,"wd")[0].send_keys("selenium")
三、切换窗口
# 获取当前窗口
driver.current_window_handle
# 获取所有窗口,返回的是一个数组,可以通过下标切换窗口
driver.window_handles
# 窗口切换
driver.switch_to.window(目标窗口)
四、切换iframe
# 因为文章内容在另外一个iframe嵌套的html里面,所以需要切换iframe后对其操作
# 第一步
# 获取iframe元素
desc_iframe = driver.find_element(By.TAG_NAME, "iframe")
# 第二步,获取后切换到目标iframe
driver.switch_to.frame(desc_iframe)
driver.find_element(By.ID, "tinymce").send_keys("你好1")
# 第三步,因为发布按钮不在frame里面,要退回父frame中才可以继续操作
driver.switch_to.parent_frame()
五、pytest运行测试用例
模块名必须是test开头
方法名必须是test开头
(特殊情况可以自己指定)
5.1 使用pytest运行需要安装第三方pytest库
pip install pytest
5.2 命令行方式,执行测试用例
pytest之命令行方式运行
pytest 运行所有用例
pytest 包路径 -- 指定包运行
pytest 路径/模块名 -- 指定模块运行
pytest 路径/模块名::方法名 -- 指定模块中的方法运行
六、 allure-pytest报告
6.1 安装allure-pytest插件
pip install allure-pytest
6.2 安装allure工具,并配置环境变量
https://github.com/allure-framework/allure2/releases?q=2.9&expanded=true allure工具的下载地址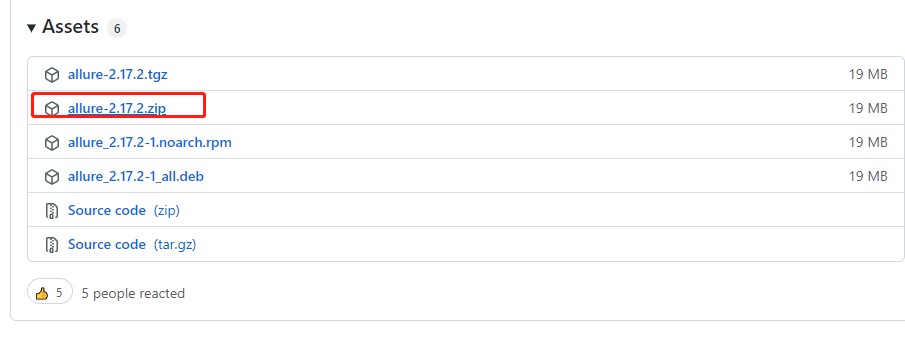
第一步:我的电脑--属性--高级系统设置--环境变量
第二步:path中添加allure的执行路径
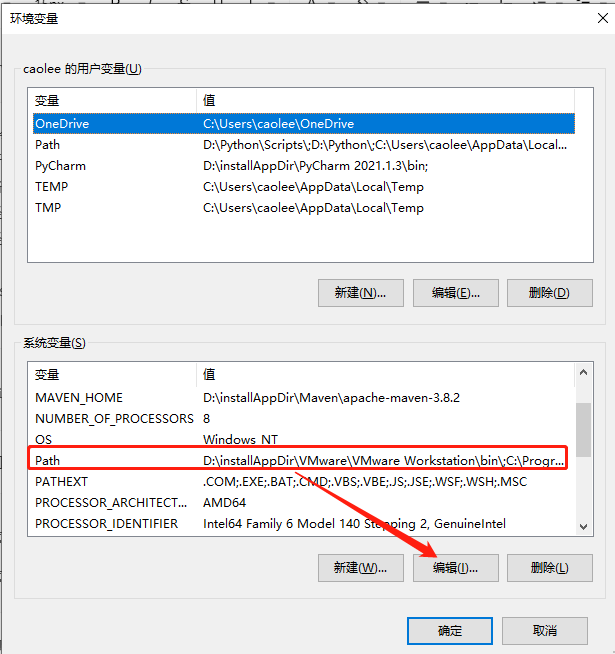
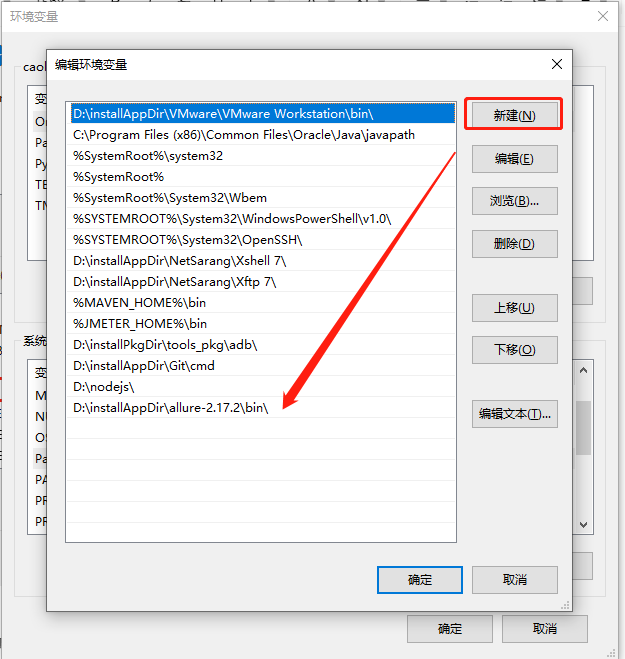
5.3使用pytest运行测试用例,并指定生成报告的路径
pytest --alluredir=report --clean-alluredir
--alluredir=报告存放的位置
--clean-alluredir 每次运行都清除之前生成的文件
5.4 allure serve report 生成HTML格式的报告
要在项目根路径下执行该命令
D:\MyWorkStation\PythonProject\selenium_learning>allure serve report

若有收获,就点个赞吧
0 人点赞
