什么是spark
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。Spark中最基本的数据抽象称RDD,叫做弹性分布式数据集。
宽依赖于窄依赖
窄依赖
窄依赖表示每个父RDD的Partition最多被一个子RDD的一个Partition使用。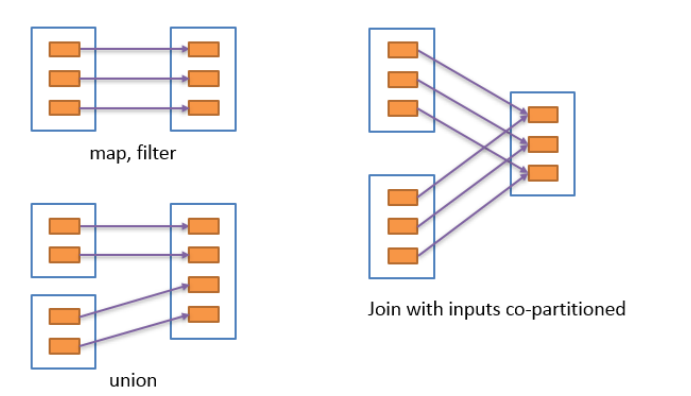
宽依赖
宽依赖表示同一个父RDD的Partition被多个子RDD的Partition依赖,会引起shuffle。
Spark Job的划分
Spark Job由多个stages组成,这些stages就是实现最终的RDD所需的数据转换的步骤,一个宽依赖划分一个stage,每个stage由多个tasks组成,这些tasks就表示每个并行计算,并且会在多个执行器上执行。
Stage任务划分
DAG(有向无环图)
原始的RDD经过一系列的转换形成了DAG,根据R DD之间的依赖关系的不同将DAG划分成不同的stage,对于窄依赖partition的转换处理在Stage中完成,对于宽依赖,由于shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
RDD任务切分中间分为:Application、Job、Stage和Task
(1)Application:初始化一个SparkContext即生成一个Application;
(2)Job:一个Action算子就会生成一个Job;
(3)Stage:Stage等于宽依赖的个数加1;
(4)Task:一个Stage阶段中,最后一个RDD的分区个数就是Task的个数。
注意:Application->Job->Stage->Task每一层都是1对n的关系。
RDD编程-转换算子- Value
RDD编程-转换算子- KeyValue
RDD持久化
RDD Cache缓存
RDD通过Cache或者Persist方法将前面的计算结果缓存,默认情况下会把数据以序列化的形式缓存在JVM的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
代码实现
object cache01 {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3. 创建一个RDD,读取指定位置文件:hello atguigu atguiguval lineRdd: RDD[String] = sc.textFile("input1")//3.1.业务逻辑val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))val wordToOneRdd: RDD[(String, Int)] = wordRdd.map {word => {println("************")(word, 1)}}//3.5 cache操作会增加血缘关系,不改变原有的血缘关系println(wordToOneRdd.toDebugString)//3.4 数据缓存。wordToOneRdd.cache()//3.6 可以更改存储级别// wordToOneRdd.persist(StorageLevel.MEMORY_AND_DISK_2)//3.2 触发执行逻辑wordToOneRdd.collect()println("-----------------")println(wordToOneRdd.toDebugString)//3.3 再次触发执行逻辑wordToOneRdd.collect()//4.关闭连接sc.stop()}}
注意:默认的存储级别都是仅在内存存储一份。在存储级别的末尾加上“_2”表示持久化的数据存为两份。
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
自带缓存算子
object cache02 {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3. 创建一个RDD,读取指定位置文件:hello atguigu atguiguval lineRdd: RDD[String] = sc.textFile("input1")//3.1.业务逻辑val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))val wordToOneRdd: RDD[(String, Int)] = wordRdd.map {word => {println("************")(word, 1)}}// 采用reduceByKey,自带缓存val wordByKeyRDD: RDD[(String, Int)] = wordToOneRdd.reduceByKey(_+_)//3.5 cache操作会增加血缘关系,不改变原有的血缘关系println(wordByKeyRDD.toDebugString)//3.4 数据缓存。//wordByKeyRDD.cache()//3.2 触发执行逻辑wordByKeyRDD.collect()println("-----------------")println(wordByKeyRDD.toDebugString)//3.3 再次触发执行逻辑wordByKeyRDD.collect()//4.关闭连接sc.stop()}}
RDD CheckPoint检查点
- 检查点:是通过将RDD中间结果写入磁盘。
- 为什么要做检查点?
由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。
- 检查点存储路径:Checkpoint的数据通常是存储在HDFS等容错、高可用的文件系统
- 检查点数据存储格式为:二进制的文件
- 检查点切断血缘:在Checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移除。
- 检查点触发时间:对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。但是检查点为了数据安全,会从血缘关系的最开始执行一遍

设置检查点步骤
- 设置检查点数据存储路径:sc.setCheckpointDir(“./checkpoint1”)
调用检查点方法:wordToOneRdd.checkpoint()
代码
object checkpoint01 {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)// 需要设置路径,否则抛异常:Checkpoint directory has not been set in the SparkContextsc.setCheckpointDir("./checkpoint1")//3. 创建一个RDD,读取指定位置文件:hello atguigu atguiguval lineRdd: RDD[String] = sc.textFile("input1")//3.1.业务逻辑val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {word => {(word, System.currentTimeMillis())}}//3.5 增加缓存,避免再重新跑一个job做checkpoint// wordToOneRdd.cache()//3.4 数据检查点:针对wordToOneRdd做检查点计算wordToOneRdd.checkpoint()//3.2 触发执行逻辑wordToOneRdd.collect().foreach(println)// 会立即启动一个新的job来专门的做checkpoint运算//3.3 再次触发执行逻辑wordToOneRdd.collect().foreach(println)wordToOneRdd.collect().foreach(println)Thread.sleep(10000000)//4.关闭连接sc.stop()}}
只增加checkpoint,没有增加Cache缓存打印
第1个job执行完,触发了checkpoint,第2个job运行checkpoint,并把数据存储在检查点上。第3、4个job,数据从检查点上直接读取。
- 增加checkpoint,也增加Cache缓存打印
第1个job执行完,数据就保存到Cache里面了,第2个job运行checkpoint,直接读取Cache里面的数据,并把数据存储在检查点上。第3、4个job,数据从检查点上直接读取。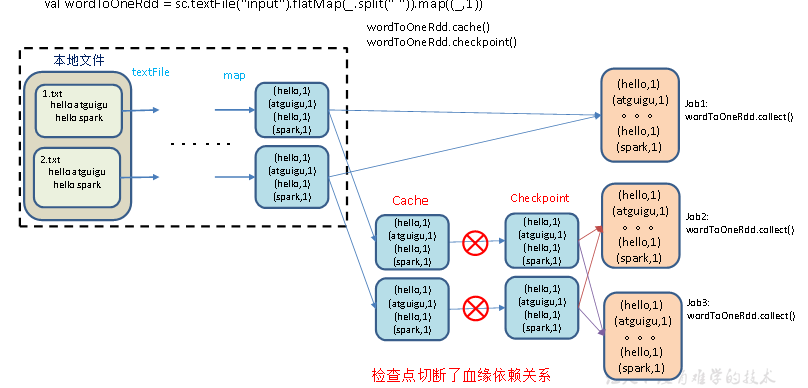
缓存和检查点区别
- Cache缓存只是将数据保存起来,不切断血缘依赖。Checkpoint检查点切断血缘依赖。
- Cache缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint的数据通常存储在HDFS等容错、高可用的文件系统,可靠性高。
- 建议对checkpoint()的RDD使用Cache缓存,这样checkpoint的job只需从Cache缓存中读取数据即可,否则需要再从头计算一次RDD。
如果使用完了缓存,可以通过unpersist()方法释放缓存
检查点存储到HDFS集群
如果检查点数据存储到HDFS集群,要注意配置访问集群的用户名。否则会报访问权限异常。
代码
object checkpoint02 {def main(args: Array[String]): Unit = {// 设置访问HDFS集群的用户名System.setProperty("HADOOP_USER_NAME","atguigu")//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)// 需要设置路径.需要提前在HDFS集群上创建/checkpoint路径sc.setCheckpointDir("hdfs://hadoop102:9000/checkpoint")//3. 创建一个RDD,读取指定位置文件:hello atguigu atguiguval lineRdd: RDD[String] = sc.textFile("input1")//3.1.业务逻辑val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {word => {(word, System.currentTimeMillis())}}//3.4 增加缓存,避免再重新跑一个job做checkpointwordToOneRdd.cache()//3.3 数据检查点:针对wordToOneRdd做检查点计算wordToOneRdd.checkpoint()//3.2 触发执行逻辑wordToOneRdd.collect().foreach(println)//4.关闭连接sc.stop()}}
数据读取与保存
Spark的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统。
文件格式分为:Text文件、Json文件、Csv文件、Sequence文件以及Object文件;
文件系统分为:本地文件系统、HDFS以及数据库。Text文件
数据读取:textFile(String)
-
代码
object Operate_Text {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[1]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3.1 读取输入文件val inputRDD: RDD[String] = sc.textFile("input/1.txt")//3.2 保存数据inputRDD.saveAsTextFile("output")//4.关闭连接sc.stop()}}
JSON 文件
如果JSON文件中每一行就是一个JSON记录,那么可以通过将JSON文件当做文本文件来读取,然后利用相关的JSON库对每一条数据进行JSON解析。
代码
object Operate_Json {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[1]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3.1 读取Json输入文件val jsonRDD: RDD[String] = sc.textFile("input/user.json")//3.2 导入解析Json所需的包并解析Jsonimport scala.util.parsing.json.JSONval resultRDD: RDD[Option[Any]] = jsonRDD.map(JSON.parseFull)//3.3 打印结果resultRDD.collect().foreach(println)//4.关闭连接sc.stop()}}
注意:使用RDD读取JSON文件处理很复杂,同时SparkSQL集成了很好的处理JSON文件的方式,所以应用中多是采用SparkSQL处理JSON文件。
Sequence文件
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)。在SparkContext中,可以调用sequenceFilekeyClass, valueClass。
代码
object Operate_Sequence {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[1]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3.1 创建rddval dataRDD: RDD[(Int, Int)] = sc.makeRDD(Array((1,2),(3,4),(5,6)))//3.2 保存数据为SequenceFiledataRDD.saveAsSequenceFile("output")//3.3 读取SequenceFile文件sc.sequenceFile[Int,Int]("output").collect().foreach(println)//4.关闭连接sc.stop()}}
Object对象文件
对象文件是将对象序列化后保存的文件,采用Java的序列化机制。可以通过objectFilek,v函数接收一个路径,读取对象文件,返回对应的RDD,也可以通过调用saveAsObjectFile()实现对对象文件的输出。因为是序列化所以要指定类型。
代码
object Operate_Object {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[1]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3.1 创建RDDval dataRDD: RDD[Int] = sc.makeRDD(Array(1,2,3,4))//3.2 保存数据dataRDD.saveAsObjectFile("output")//3.3 读取数据sc.objectFile[(Int)]("output").collect().foreach(println)//4.关闭连接sc.stop()}}
文件系统类数据读取与保存
HDFS
Spark的整个生态系统与Hadoop是完全兼容的,所以对于Hadoop所支持的文件类型或者数据库类型,Spark也同样支持。另外,由于Hadoop的API有新旧两个版本,所以Spark为了能够兼容Hadoop所有的版本,也提供了两套创建操作接口。对于外部存储创建操作而言,hadoopRDD和newHadoopRDD是最为抽象的两个函数接口
MYSQL
支持通过Java JDBC访问关系型数据库。需要通过JdbcRDD进行,示例如下:
添加依赖
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.27</version></dependency>
从Mysql读取数据 ```scala package com.save.mysql
import java.sql.DriverManager import org.apache.spark.rdd.JdbcRDD import org.apache.spark.{SparkConf, SparkContext}
object MysqlRDD {
def main(args: Array[String]): Unit = {
//1.创建spark配置信息 val sparkConf: SparkConf = new SparkConf().setMaster(“local[*]”).setAppName(“JdbcRDD”)
//2.创建SparkContext val sc = new SparkContext(sparkConf)
//3.定义连接mysql的参数 val driver = “com.mysql.jdbc.Driver” val url = “jdbc:mysql://hadoop102:3306/rdd” val userName = “root” val passWd = “000000”
//创建JdbcRDD
val rdd = new JdbcRDD(sc, () => {
Class.forName(driver)
DriverManager.getConnection(url, userName, passWd)
},
“select * from rddtable where id>=? and id<=?;”,
1,
10,
1,
r => (r.getInt(1), r.getString(2))
)
//打印最后结果 println(rdd.count()) rdd.foreach(println)
sc.stop() } }
3. 往Mysql写入数据
```scala
def main(args: Array[String]) {
package com.atguigu.spark.day06
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Author: Felix
* Date: 2020/1/8
* Desc: Spark操作MySQL数据库
*/
object Spark02_MySQL {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//数据库连接4要素
val driver = "com.mysql.jdbc.Driver"
val url = "jdbc:mysql://hadoop202:3306/test"
val userName = "root"
val passWd = "123456"
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("qiaofeng",18),("duanyu",20),("xuzhu",21)))
/*
//在循环中创建对象,效率低
rdd.foreach{
case (name,age)=>{
//注册驱动
Class.forName(driver)
//获取连接
val conn: Connection = DriverManager.getConnection(url,userName,passWd)
//执行的sql
var sql:String = "insert into user(name,age) values(?,?)"
//获取数据库操作对象
val ps: PreparedStatement = conn.prepareStatement(sql)
//给参数赋值
ps.setString(1,name)
ps.setInt(2,age)
//执行sql语句
ps.executeUpdate()
//释放资源
ps.close()
conn.close()
}
}*/
/*
//注册驱动
Class.forName(driver)
//获取连接
val conn: Connection = DriverManager.getConnection(url,userName,passWd)
//执行的sql
var sql:String = "insert into user(name,age) values(?,?)"
//获取数据库操作对象
val ps: PreparedStatement = conn.prepareStatement(sql)
rdd.foreach{
case (name,age)=>{
//给参数赋值
ps.setString(1,name)
ps.setInt(2,age)
//执行sql语句
ps.executeUpdate()
}
}
//释放资源
ps.close()
conn.close()*/
rdd.foreachPartition{
datas=>{
//注册驱动
Class.forName(driver)
//获取连接
val conn: Connection = DriverManager.getConnection(url,userName,passWd)
//执行的sql
var sql:String = "insert into user(name,age) values(?,?)"
//获取数据库操作对象
val ps: PreparedStatement = conn.prepareStatement(sql)
datas.foreach{
case (name,age)=>{
//给参数赋值
ps.setString(1,name)
ps.setInt(2,age)
//执行sql语句
ps.executeUpdate()
}
}
//释放资源
ps.close()
conn.close()
}
}
// 关闭连接
sc.stop()
}
}
累加器
累加器:分布式共享只写变量。(Task和Task之间不能读数据)
累加器用来对信息进行聚合,通常在向Spark传递函数时,比如使用map()函数或者用 filter()传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。如果我们想实现所有分片处理时更新共享变量的功能,那么累加器可以实现我们想要的效果。
系统累加器
代码:
object accumulator01 {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[1]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3.创建RDD
val dataRDD: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("a", 2), ("a", 3), ("a", 4)))
//3.1 打印单词出现的次数(a,10) 代码执行了shuffle
dataRDD.reduceByKey(_ + _).collect().foreach(println)
//3.2 如果不用shuffle,怎么处理呢?
var sum = 0
// 打印是在Executor端
dataRDD.foreach {
case (a, count) => {
sum = sum + count
println("sum=" + sum)
}
}
// 打印是在Driver端
println(("a", sum))
//3.3 使用累加器实现数据的聚合功能
// Spark自带常用的累加器
//3.3.1 声明累加器
val sum1: LongAccumulator = sc.longAccumulator("sum1")
dataRDD.foreach{
case (a, count)=>{
//3.3.2 使用累加器
sum1.add(count)
}
}
//3.3.3 获取累加器
println(sum1.value)
//4.关闭连接
sc.stop()
}
}
通过在驱动器中调用SparkContext.accumulator(initialValue)方法,创建出存有初始值的累加器。返回值为org.apache.spark.Accumulator[T]对象,其中T是初始值initialValue的类型。Spark闭包里的执行器代码可以使用累加器的+=方法(在Java中是 add)增加累加器的值。驱动器程序可以调用累加器的value属性(在Java中使用value()或setValue())来访问累加器的值。
注意:
- 工作节点上的任务不能相互访问累加器的值。从这些任务的角度来看,累加器是一个只写变量。
对于要在行动操作中使用的累加器,Spark只会把每个任务对各累加器的修改应用一次。因此,如果想要一个无论在失败还是重复计算时都绝对可靠的累加器,我们必须把它放在foreach()这样的行动操作中。转化操作中累加器可能会发生不止一次更新。
自定义累加器
自定义累加器类型的功能在1.X版本中就已经提供了,但是使用起来比较麻烦,在2.0版本后,累加器的易用性有了较大的改进,而且官方还提供了一个新的抽象类:AccumulatorV2来提供更加友好的自定义类型累加器的实现方式。
自定义累加器步骤继承AccumulatorV2,设定输入、输出泛型
- 重写方法
代码
object accumulator_define {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3. 创建RDD
val rdd: RDD[String] = sc.makeRDD(List("Hello", "Hello", "Hello", "Hello", "Hello", "Spark", "Spark"))
//3.1 创建累加器
val accumulator1: MyAccumulator = new MyAccumulator()
//3.2 注册累加器
sc.register(accumulator1,"wordcount")
//3.3 使用累加器
rdd.foreach(
word =>{
accumulator1.add(word)
}
)
//3.4 获取累加器的累加结果
println(accumulator1.value)
//4.关闭连接
sc.stop()
}
}
// 声明累加器
// 1.继承AccumulatorV2,设定输入、输出泛型
// 2.重新方法
class MyAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]] {
// 定义输出数据集合
var map = mutable.Map[String, Long]()
// 是否为初始化状态,如果集合数据为空,即为初始化状态
override def isZero: Boolean = map.isEmpty
// 复制累加器
override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = {
new MyAccumulator()
}
// 重置累加器
override def reset(): Unit = map.clear()
// 增加数据
override def add(v: String): Unit = {
// 业务逻辑
if (v.startsWith("H")) {
map(v) = map.getOrElse(v, 0L) + 1L
}
}
// 合并累加器
override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = {
var map1 = map
var map2 = other.value
map = map1.foldLeft(map2)(
(map,kv)=>{
map(kv._1) = map.getOrElse(kv._1, 0L) + kv._2
map
}
)
}
// 累加器的值,其实就是累加器的返回结果
override def value: mutable.Map[String, Long] = map
}
广播变量
广播变量:分布式共享只读变量。
在多个并行操作中(Executor)使用同一个变量,Spark默认会为每个任务(Task)分别发送,这样如果共享比较大的对象,会占用很大工作节点的内存。
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,甚至是机器学习算法中的一个很大的特征向量,广播变量用起来都很顺手。
使用广播变量步骤:
- 通过对一个类型T的对象调用SparkContext.broadcast创建出一个Broadcast[T]对象,任何可序列化的类型都可以这么实现。
- 通过value属性访问该对象的值(在Java中为value()方法)。
- 变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)。
代码
object broadcast {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3.创建RDD
//val rdd1: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
//val rdd2: RDD[(String, Int)] = sc.makeRDD(List(("a", 4), ("b", 5), ("c", 6)))
//3.1 采用RDD的方式实现 rdd1 join rdd2,用到Shuffle,性能比较低
//rdd1.join(rdd2).collect().foreach(println)
//3.2 采用集合的方式,实现rdd1和list的join
val rdd1: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val list: List[(String, Int)] = List(("a", 4), ("b", 5), ("c", 6))
// 声明广播变量
val broadcastList: Broadcast[List[(String, Int)]] = sc.broadcast(list)
val resultRDD: RDD[(String, (Int, Int))] = rdd1.map {
case (k1, v1) => {
var v2: Int = 0
// 使用广播变量
//for ((k3, v3) <- list.value) {
for ((k3, v3) <- broadcastList.value) {
if (k1 == k3) {
v2 = v3
}
}
(k1, (v1, v2))
}
}
resultRDD.foreach(println)
//4.关闭连接
sc.stop()
}
}

若有收获,就点个赞吧
0 人点赞
