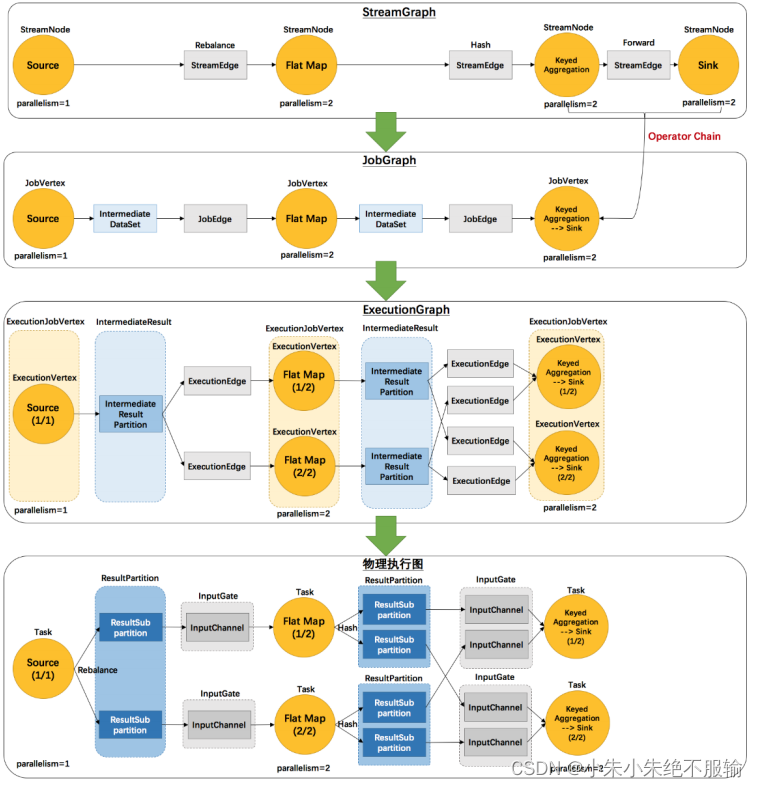
- 流图StreamGraph在CliFrontend(客户端)生成,根据代码中的算子顺序,挨个添加到流图的结构中去。并且把代码中不是对数据做转换的算子变成一些边,比如keyby变成了Hash边,封装了两个东西,一个流节点,一个流的边,并且把它们前后出入关系串起来。
- 作业图JobGraph也是在客户端生成,相比于流图做了几件事情:
- 1)如果可以优化成操作链的,就把它们串到一起
- 2)相关节点和边的转换,StreamNode转为JobVertex,StreamEdge转化为JobEdge,同时多生成了某个顶点的中间数据集IntermediateDataSet,之后把这些数据集,顶点,边根据前后关系遍历串联起来。
- 执行图ExecutionGraph是在JobMaster生成,创建的时候同时创建了一个调度器,调度器里面会把作业图转化为执行图。
- 1)首先把JobVertex转化为ExecutionJobVertex,执行作业顶点根据并行度又细分成ExecutionVertex,一个并行实例一个ExecutionVertex
- 2)把中间数据集IntermediateDataSet转换为中间结果IntermediateResult,同时根据走向划分为多个中间结果分区IntermediateResultParition,
- 3)再根据中间结果与执行作业顶点的关系创建执行边ExecutionEdge
- 调度器有了执行图开始调度,把task根据执行图部署到相应的工作节点上去,通过RPC远程调用网关部署。转发到TaskExecutor开始真正的执行。物理执行图没有一个明确的执行类。
1. Graph的概念
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
- StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph:StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraph:JobManager 根据 JobGraph 生成 ExecutionGraph。ExecutionGraph 是JobGraph 的并行化版本,是调度层最核心的数据结构。
- 物理执行图: JobManager 根 据 ExecutionGraph 对 Job 进 行 调 度 后 , 在 各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
名词解释:
1)StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图。
(1)StreamNode:用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。
(2)StreamEdge:表示连接两个 StreamNode 的边。
2)JobGraph:StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。
(1)JobVertex:经过优化后符合条件的多个 StreamNode 可能会 chain 在一起生成一个 JobVertex,即一个 JobVertex 包含一个或多个 operator,JobVertex 的输入是 JobEdge,输出是IntermediateDataSet。
(2)IntermediateDataSet:表示 JobVertex 的输出,即经过 operator 处理产生的数据集。producer 是 JobVertex,consumer 是 JobEdge。
(3)JobEdge:代表了 job graph 中的一条数据传输通道。source 是 IntermediateDataSet,target 是 JobVertex。即数据通过 JobEdge 由 IntermediateDataSet 传递给目标 JobVertex。
3)ExecutionGraph:JobManager 根据 JobGraph 生成 ExecutionGraph。ExecutionGraph是 JobGraph 的并行化版本,是调度层最核心的数据结构。
(1) ExecutionJobVertex : 和 JobGraph中的 JobVertex一一对 应 。 每一个ExecutionJobVertex 都有和并发度一样多的 ExecutionVertex。
(2)ExecutionVertex:表示 ExecutionJobVertex 的其中一个并发子任务,输入是ExecutionEdge,输出是 IntermediateResultPartition。
(3)IntermediateResult:和 JobGraph 中的 IntermediateDataSet 一一对应。一个 IntermediateResult 包含多个 IntermediateResultPartition,其个数等于该 operator 的并发度。
(4)IntermediateResultPartition:表示 ExecutionVertex 的一个输出分区,producer 是ExecutionVertex,consumer 是若干个 ExecutionEdge。
(5)ExecutionEdge:表示 ExecutionVertex 的输入,source 是 IntermediateResultPartition,target 是 ExecutionVertex。source 和 target 都只能是一个。
(6)Execution:是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个 ExecutionAttemptID。一个 Execution 通过ExecutionAttemptID 来唯一标识。JM 和 TM 之间关于 task 的部署和 task status 的更新都是通过 ExecutionAttemptID 来确定消息接受者。
从这些基本概念中,也可以看出以下几点:
- 由于每个 JobVertex 可能有多个 IntermediateDataSet,所以每个 ExecutionJobVertex 可能有多个 IntermediateResult,因此,每个 ExecutionVertex 也可能会包含多个IntermediateResultPartition;
- ExecutionEdge 这里主要的作⼀是把 ExecutionVertex 和 IntermediateResultPartition连接起来,表示它们之间的连接关系。
4)物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
(1)Task:Execution 被调度后在分配的 TaskManager 中启动对应的 Task。Task 包裹了具有用户执行逻辑的 operator。
(2)ResultPartition:代表由一个 Task 的生成的数据,和 ExecutionGraph 中的IntermediateResultPartition 一一对应。
(3)ResultSubpartition:是 ResultPartition 的一个子分区。每个 ResultPartition 包含多个ResultSubpartition,其数目要由下游消费 Task 数和 DistributionPattern 来决定。
(4)InputGate:代表 Task 的输入封装,和 JobGraph 中 JobEdge 一一对应。每个 InputGate消费了一个或多个的 ResultPartition。
(5)InputChannel:每个 InputGate 会包含一个以上的 InputChannel,和 ExecutionGraph中的 ExecutionEdge 一一对应,也和 ResultSubpartition 一对一地相连,即一个 InputChannel接收一个 ResultSubpartition 的输出。
2. StreamGraph 在 Client 生成
调用用户代码中的 StreamExecutionEnvironment.execute()-> execute(getJobName())-> execute(getStreamGraph(jobName))-> getStreamGraph(jobName, true)StreamExecutionEnvironment.java
首先进入 generate()方法
可以看一下这些跳转到的源码。
主要内容就是:
map 转换将用户自定义的函数 MapFunction 包装到 StreamMap 这个 Operator 中,再将 StreamMap 包装到 OneInputTransformation,最后该 transformation 存 到 env 中,当调用 env.execute 时,遍历其中的 transformation 集合构造出 StreamGraph。其分层实现如下图所示:
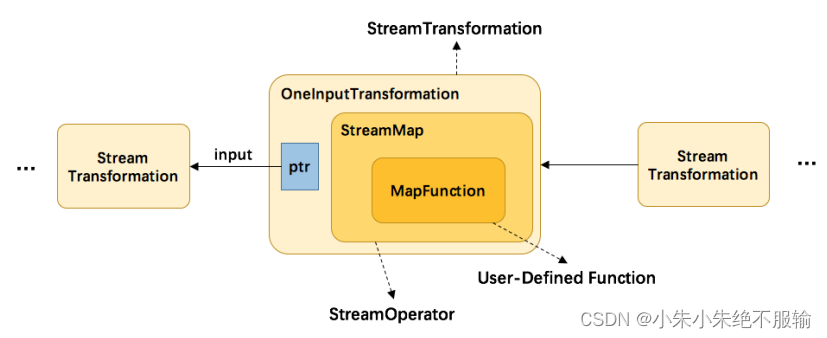 接着分析StreamGraph 生成的源码:
接着分析StreamGraph 生成的源码:
StreamExecutionEnvironment.java -> generator() -> transform()
该函数首先会对该 transform 的上游 transform 进行递归转换,确保上游的都已经完成了转化。然后通过 transform 构造出 StreamNode,最后与上游的 transform 进行连接,构造出 StreamNode。
3. JobGraph 在 Client 生成
StreamGraph 转变成 JobGraph 也是在 Client 完成,主要作了三件事:
- StreamNode 转成 JobVertex。
- StreamEdge 转成 JobEdge。
- JobEdge 和 JobVertex 之间创建 IntermediateDataSet 来连接。
核心逻辑:根据 StreamGraph,生成 JobGraph:
4. ExecutionGraph 在 JobManager 生成
client 生成 JobGraph 之后,就通过 submitJob 提交给 JobManager,JobManager 会根据JobGraph 生成对应的ExecutionGraph。
ExecutionGraph 是 Flink 作业调度时使用到的核⼀数据结构,它包含每一个并行的 task、每⼀个 intermediate stream 以及它们之间的关系。
5. 物理执行图(Task 的调度和执行)
调度的源码分析:从JobMaster.java开始
6. 调度
调度器是 Flink 作业执行的核心组件,管理作业执行的所有相关过程,包括 JobGraph 到 ExecutionGraph 的转换、作业生命周期管理(作业的发布、取消、停止)、作业的 Task 生命周期管理(Task 的发布、取消、停止)、资源申请与释放、作业和 Task 的 Failover 等。
调度有几个重要的组件:
- 调度器:SchedulerNG 及其子类、实现类
- 调度策略:SchedulingStrategy 及其实现类
- 调度模式:ScheduleMode 包含流和批的调度,有各自不同的调度模式
6.1 调度器
调度器作用:
1)作业的生命周期管理,如作业的发布、挂起、取消
2)作业执行资源的申请、分配、释放
3)作业的状态管理,作业发布过程中的状态变化和作业异常时的 FailOver 等
4)作业的信息提供,对外提供作业的详细信息
6.2 调度模式
ScheduleMode 决定如何启动 ExecutionGraph 中的 Task。Flink 提供 3 中调度模式:
1)Eager 调度
适用于流计算。一次性申请需要的所有资源,如果资源不足,则作业启动失败。
2)分阶段调度
LAZY_FROM_SOURCES 适用于批处理。从 SourceTask 开始分阶段调度,申请资源的时候,一次性申请本阶段所需要的所有资源。上游 Task 执行完毕后开始调度执行下游的 Task,读取上游的数据,执行本阶段的计算任务,执行完毕之后,调度后一个阶段的 Task,依次进行调度,直到作业完成。
3)分阶段 Slot 重用调度
LAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUEST 适用于批处理。与分阶段调度基本一样,区别在于该模式下使用批处理资源申请模式,可以在资源不足的情况下执行作业,但是需要确保在本阶段的作业执行中没有 Shuffle 行为。
目前视线中的 Eager 模式和 LAZY_FROM_SOURCES 模式的资源申请逻辑一样,
LAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUEST 是单独的资源申请逻辑。
6.3 调度策略
调度策略有三种实现:
- EagerSchedulingStrategy:适用于流计算,同时调度所有的 task
- LazyFromSourcesSchedulingStrategy:适用于批处理,当输入数据准备好时(上游处理完)进行 vertices调度。
- PipelinedRegionSchedulingStrategy:以流水线的局部为粒度进行调度
PipelinedRegionSchedulingStrategy 是 1.11 加入的,从 1.12 开始,将以 pipelined region 为单位进行调度。pipelined region 是一组流水线连接的任务。这意味着,对于包含多个 region 的流作业,在开始部署任务之前,它不再等待所有任务获取 slot。取而代之的是,一旦任何region 获得了足够的任务 slot 就可以部署它。对于批处理作业,将不会为任务分配 slot,也不会单独部署任务。取而代之的是,一旦某个 region 获得了足够的 slot,则该任务将与所有其他任务一起部署在同一区域中。

若有收获,就点个赞吧
0 人点赞
