- 1. 提交流程">1. 提交流程
- 2. 源码分析">2. 源码分析
- 1.1 提交命令
- 1.2 Main 方法执行
- 1.3 通过 run 方法解析输入参数
- 1.4 执行 this.executeProgram 进入到用户自定义类中
- 1.5 生成 StreamGraph
- 1.6 生成JobGraph">
 1.6 生成JobGraph
1.6 生成JobGraph - 1.7 创建并启动 yarn 客户端
- 1.8 部署集群,上传 jar 包和配置文件到 HDFS
- 1.9 封装 AM 参数和命令,生成 ClusterClientJobClient
- 1.10 提交任务信息
- 2 启动 ApplicationMaster
- 3.1 ApplicationMaster 创建 Dispatcher、ResourceManager
- 3.2 Dispatcher 启动 JobManager
- 7 TaskManager 启动
- 8 向 ResourceManager 注册 slot
- 9 ResourceManager 分配 Slot
- 10 TaskManager 提供 Slot
- 11 提交 Task 任务
- 3. 源码提交流程总结">3. 源码提交流程总结
1. 提交流程
流程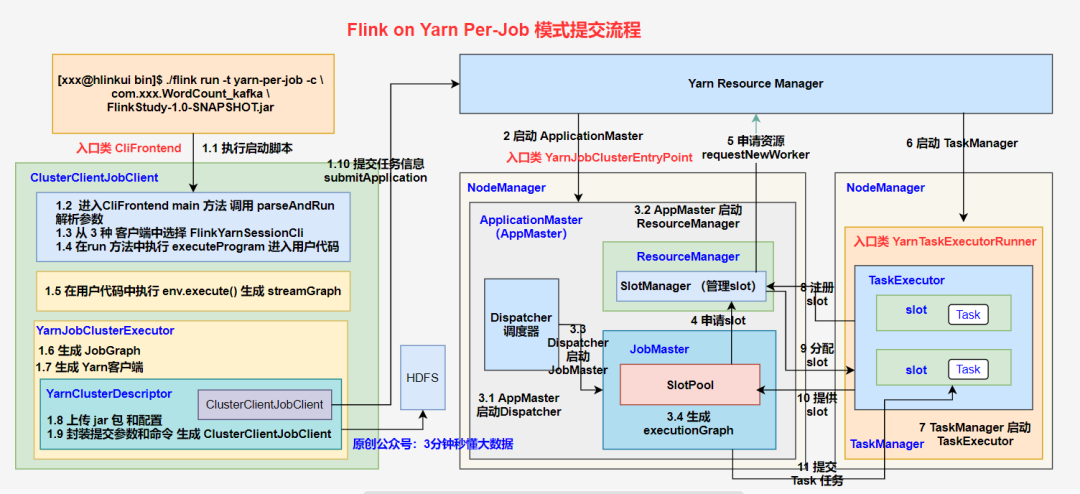
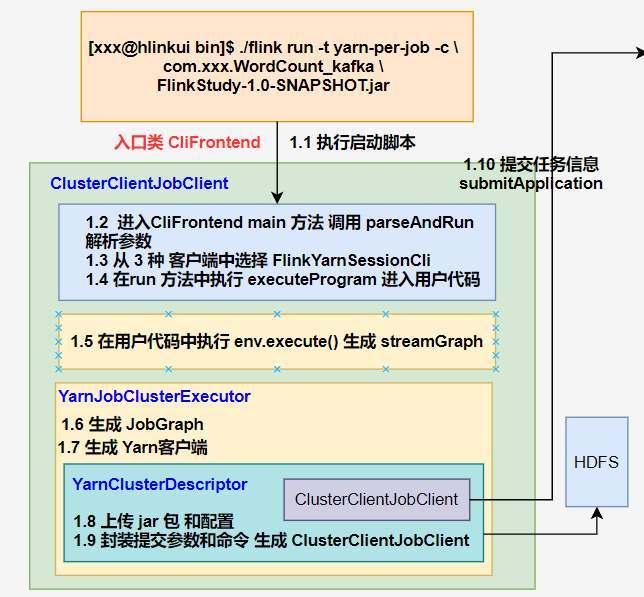
1、客户端(入口类 CliFrontend)
⭐1.1 执行启动脚本,进入 CliFrontend 类的 main 方法中,获取 flink conf 目录配置的路径,然后对其进行加载,同时依次添加 3 种客户端类型,并创建 CliFrontend 对象;
⭐1.2 在 main 中执行 parseAndRun 对提交的命令行参数进行解析;
⭐1.3 在解析命令时,根据提交的 run 模式选择对于的run方法,在run方法中选择 FlinkYarnSessionCli 作为客户端;
⭐1.4 在 run 方法中调用 executeProgram 进入用户自定义代码
⭐1.5 在用户自定义代码中执行 execute(),通过 getStreamGraph() 方法生成 streamGraph;
⭐1.6 选择 YarnJobClusterExecutor 作为 pipelineExecutor,并生成 jobGraph;
⭐1.7 创建并启动 yarn 客户端,获取集群配置参数
⭐1.8 部署集群,将应用配置(Flink-conf.yaml、logback.xml、log4j.properties)和相关文件(Flink Jar、配置类文件、用户 Jar 文件、JobGraph 对象等)上传至分布式存储 HDFS 中。
⭐1.9 封装 ApplicationMaster 参数和命令,生出 ClusterClientJobClient
⭐1.10 ClusterClientJobClient 向 Yarn ResourceManager 提交任务信息
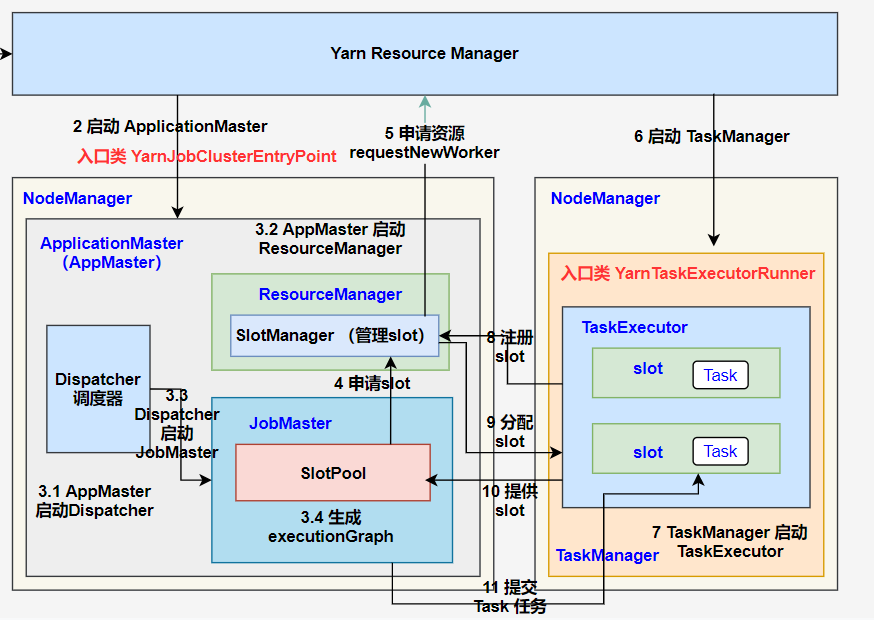
2、启动 ApplicationMaster
⭐2 Yarn ResourceManager 收到提交的任务信息后,将分配 Container 资源,并通知对应的 NodeManager 启动一个 ApplicationMaster (每提交一个 Flink job 就会启动一个 ApplicationMaster)
3、作业提交
⭐3.1 ApplicationMaster 启动 Dispatcher 和 ResourceManager ;
⭐3.2 Dispatcher 启动 JobMaster (该步和 Session 不同,Jabmaster 是由 Dispatcher 拉起,而不是 Client 传过来的)。
JobMaster 负责作业调度,管理作业和 Task 的生命周期,构建 ExecutionGraph( JobGraph 的并行化版本,调度层最核心的数据结构。
4、作业调度执行
⭐4 JobMaster 向 ResourceManager 申请 Slot 资源,开始调度 ExecutionGraph。
⭐5 ResourceManager 将资源请求加入等待队列,通过心跳向 YarnResourceManager 申请新的 Container 来启动 TaskManager 进程。
⭐6 YarnResourceManager 启动,然后从 HDFS 加载 Jar 文件等所需相关资源,在容器中启动 TaskManager。
⭐7 TaskManager 在内部启动 TaskExecutor。
⭐8 TaskManager 启动后,向 ResourceManager 注册,并把自己的 Slot 资源情况汇报给 ResourceManager。
⭐9 ResourceManager 从等待队列取出 Slot 请求,向 TaskManager 确认资源可用情况,并告知 TaskManager 将 Slot 分配给哪个 JobMaster。
⭐10 TaskManager 向 JobMaster 回复自己的一个 Slot 属于你这个任务,JobMaser 会将 Slot 缓存到 SlotPool。
⭐11 JobMaster 调度 Task 到 TaskMnager 的 Slot 上执行。
2. 源码分析
包括三个部分:
- CliFrontend 客户端
- YarnJobClusterEntryPoint:AM 执行的入口类
- YarnTaskExecutorRunner:Yarn 模式下的 TaskManager 的入口类
1.1 提交命令
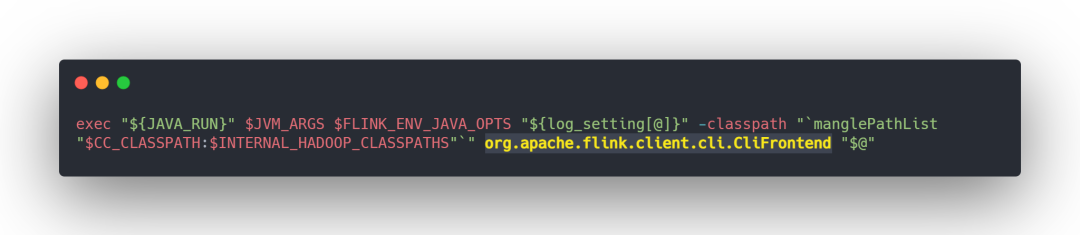
通过 flink on yarn per-job 模式提交,查看 flink 脚本可以看到,程序被提交后,会寻找 CliFrontend 类。
1.2 Main 方法执行
在 CliFrontend.main 方法中,会执行如下操作:
1 获取 flink conf 目录配置的路径; 2 根据 conf 目录加载配置; 3 根据三种方式 GenericCLI、flinkYarnSessionCLI、DefaultCLI按照顺序依次封装成命令行接口。 4 创建 CLiFrontend 客户端; 5 对 flink run 提交的命令行进行解析。(除过 flink 为脚本,run 及 后面的命令全部需要解析判断 ) 具体如下源码:
具体如下源码:
 1.2.1 获取 flink conf 目录配置的路径;
⭐ CliFrontend.java
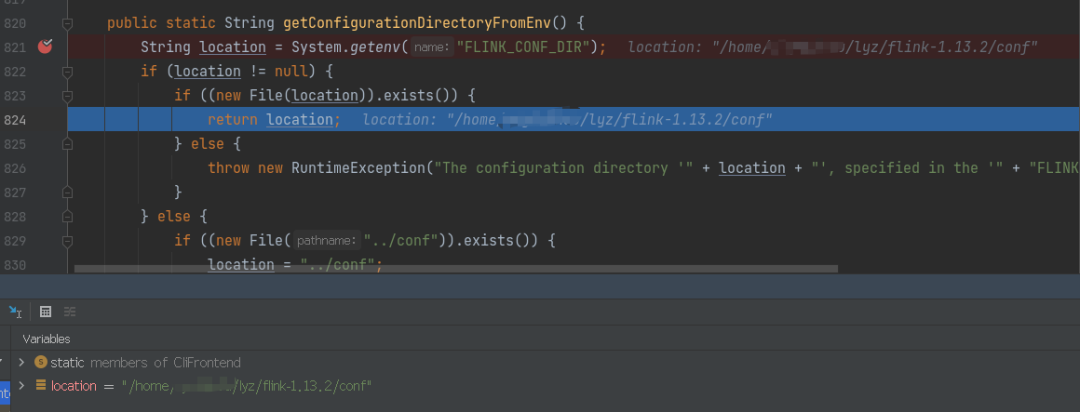
通过 getConfigurationDirectoryFromEnv 方法可以看到,这一步主要是用来获取 flink conf 的目录配置文件路径
1.2.1 获取 flink conf 目录配置的路径;
⭐ CliFrontend.java
通过 getConfigurationDirectoryFromEnv 方法可以看到,这一步主要是用来获取 flink conf 的目录配置文件路径
 1.2.2 根据 conf 目录加载配置;
⭐ GlobalConfiguration.java
在 loadConfiguration 方法中,加载之前获取的 conf 路径配置
1.2.2 根据 conf 目录加载配置;
⭐ GlobalConfiguration.java
在 loadConfiguration 方法中,加载之前获取的 conf 路径配置
 1.2.3 选择创建的客户端类型;
⭐ CliFrontend.java
进入 loadCustomCommandLines 方法中,可以看到 这里依次添加了 GenericCLi、FlinkYarnSessionCli 和 DefaultCLi 三种命令行客户端(后面根据 isActive()按顺序选择):
1.2.3 选择创建的客户端类型;
⭐ CliFrontend.java
进入 loadCustomCommandLines 方法中,可以看到 这里依次添加了 GenericCLi、FlinkYarnSessionCli 和 DefaultCLi 三种命令行客户端(后面根据 isActive()按顺序选择):
 1.2.4 创建 CliFrontend 客户端
⭐ CliFrontend.java
1.2.4 创建 CliFrontend 客户端
⭐ CliFrontend.java
 1.2.5 调用 parseAndRun 解析参数
第五步:cli.parseAndRun(args) 为主要执行方法,我们进入该方法中进行查看:
⭐ CliFrontend.java
在 parseAndRun 方法中,主要是对之前提交的命令进行解析分析,我们以提交的命令行进行分析
flink run -t yarn-per-job -c xxx xxx.jar
1.2.5 调用 parseAndRun 解析参数
第五步:cli.parseAndRun(args) 为主要执行方法,我们进入该方法中进行查看:
⭐ CliFrontend.java
在 parseAndRun 方法中,主要是对之前提交的命令进行解析分析,我们以提交的命令行进行分析
flink run -t yarn-per-job -c xxx xxx.jar其中 flink 为脚本,不算命令,从 run 开始,所以下图源码中的String action = args[0] 得到的第一个参数就是 run。说明提交方式为 run。
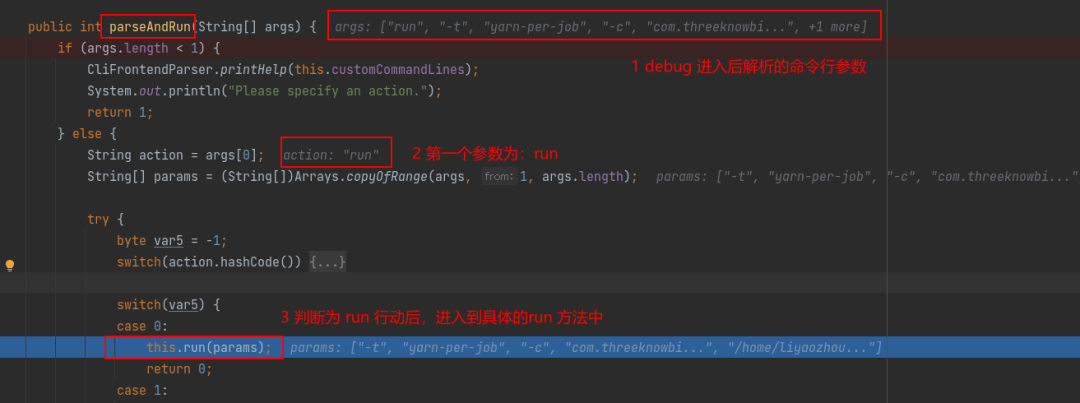
然后根据 run 动作解析输入参数
1.3 通过 run 方法解析输入参数
⭐run 在 CliFrontend.java 类中
在 run 方法中主要执行以下五步操作:
- 使用 CliFrontendParser.getRunCommandOptions()获取默认的运行参数
- 使用 this.getCommandLine 根据用户指定的配置项进行解析,然后包装成commandLine
- 根据提交的命令选择对应的客户端
- 获取有效的配置信息
- 执行 executeProgram 进入用户自定义类中

我们主要分析一下 this.executeProgram
1.4 执行 this.executeProgram 进入到用户自定义类中
⭐executeProgram() 在 CliFrontend.java 类中
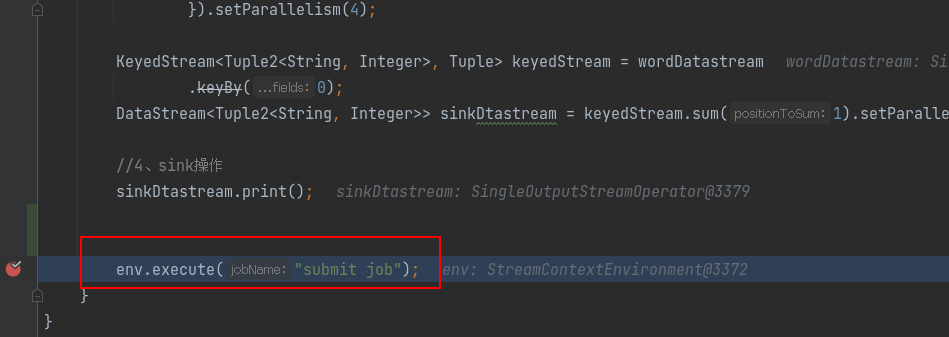
通过调用 this.executeProgram 方法进入到用户定义的程序主类中,首先创建 StreamExecutionEnvironment 环境,然后接收自定义的 source,本文代码使用 kafka 作为 source 源,通过 transformation 对算子进行转换,最后执行 sink 操作,当提交集群时,需要执行 execute()
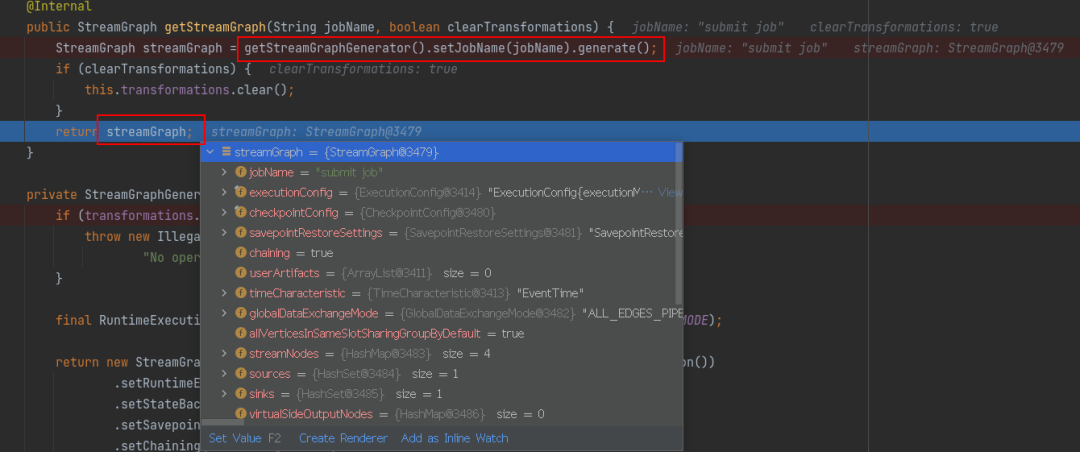
1.5 生成 StreamGraph
⭐StreamGraph 在 StreamExecutionEnvironment.java 类生成
通过查看 execute() 方法,发现通过输入形参 jobMame 最终返回一个 JobExecutionResult,继续深入查看 getStreamGraph()方法

在 getStreamGraph 中,通过加载全局配置和转换操作来取得流图生成器,最后生成 StreamGraph
1.6 生成JobGraph
1.6.1 选择 pipelineExecutor
⭐pipelineExecutor 在 StreamExecutionEnvironment.java 类生成
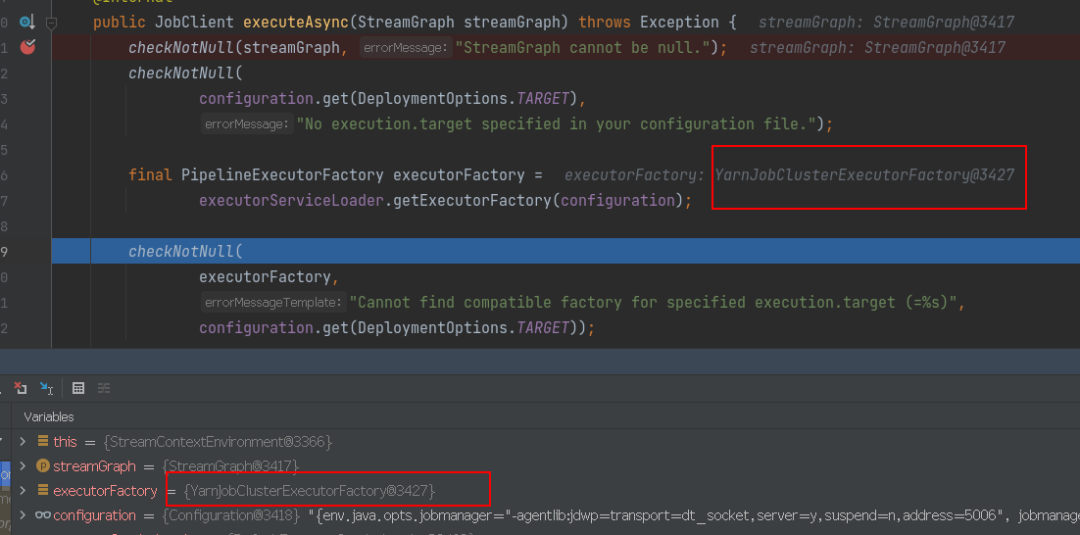
通过 getExecutorFactory(configuration) 选择 YarnJobClusterExecutorFactory 作为工厂类,选择 YarnJobClusterExecutor 作为 pipelineExecutor,
1.6.2 生成 jobGraph
⭐jobGraph 在 AbstractJobClusterExecutor.java 类生成
当 pipelineExecutor 生选择之后,executorFactory 会调用 getExecutor(configuration) 获取之前的配置,然后执行 execute(streamGraph, configuration, userClassloader) 生成 jobClientFuture,在这其中会生成 JobGraph,如下图所示

进入 getJobGraph()方法

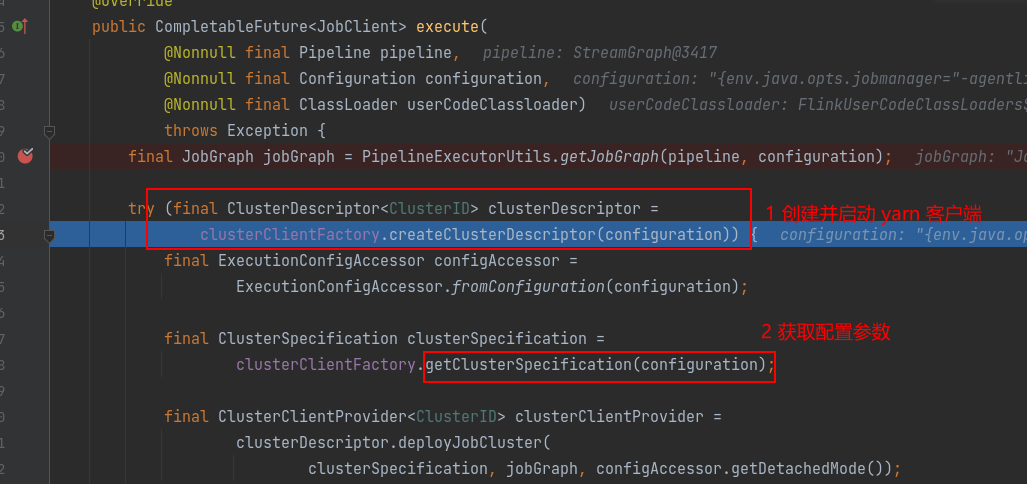
1.7 创建并启动 yarn 客户端
⭐YarnClusterDescriptor 在 AbstractJobClusterExecutor.java 类生成
jobGraph 生成后,会进行如下操作:
- 会创建并启动 yarn 客户端;
- 获取集群配置参数;
1.8 部署集群,上传 jar 包和配置文件到 HDFS
⭐ 集群部署在 YarnJobCluster.java类中

进入到 deployJobCluster()方法中,会获取 YarnJobClusterEntrypoint,启动 ApplicationMaster 的入口
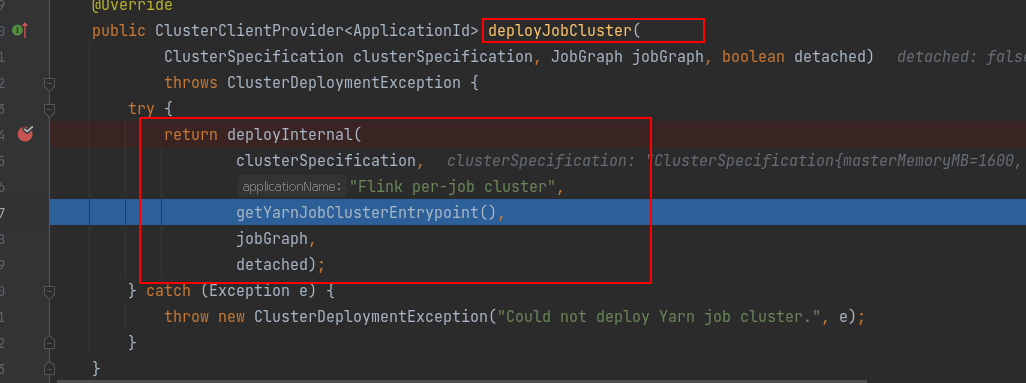
ApplicationMaster 入口启动后,然后将 jar 包和配置文件上传到 HDFS 中。
1.9 封装 AM 参数和命令,生成 ClusterClientJobClient
⭐ YarnClusterDescriptor.java
在 YarnClusterDescriptor 类的 setupApplicationMasterContainer() 方法中会创建 AM 的容器启动上下文,然后封装 AM 参数和命令,生成 ClusterClientJobClient
1.10 提交任务信息
ClusterClientJobClient 生成后,会 进入到 YarnClientImpl 实现类中提交 jobGraph,提交方法为 submitApplication,具体执行流程图如下:

继续深入 执行 rmClient.submitApplication方法,在ApplicationClientProtocolPBClientImpl.java 类的 submitApplication 方法中会获取到http 报文,然后将获取到的报文发送到服务器,并将返回的结果构成 response

最后将应用请求提交到 Yarn 上的 RMAppManager 去提交任务。
2 启动 ApplicationMaster
在 1.8 部署集群的时候,已经启动了 ApplicationMaster。
3.1 ApplicationMaster 创建 Dispatcher、ResourceManager
后面会保证大家更详细的看清楚 JobManager 和 TaskManager的执行过程,我将源码的代码复制出来,添加注释,帮助大家更好理解。
Per-job 模式的 AM container 加载运行入口是 YarnJobClusterEntryPoint 中的 main() 方法,具体如下:


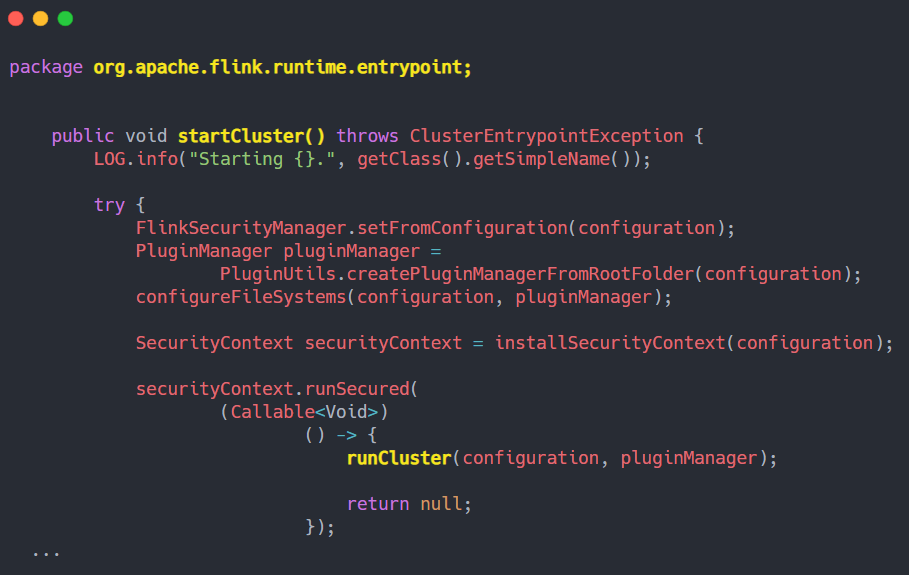
我们进入 runCluster 方法中,
1 、创建 dispatcher、ResourceManager 对象的工厂类。其中包含从本地重新创建 JobGraph 的过程。
2、通过工厂类创建 dispatcher、ResourceManager 对象,Entry 启动 RpcService、HAService、BlobServer、HeartbeatServices、MetricRegistry、ExecutionGraphStore 等

我们调用 create()方法,该方法会执行以下操作:
1、创建接收前端 Rest 请求的节点
2、创建 ResourceManager对象,返回是 new YarnResourceManager
3、创建 dispatcherRunner 对象并启动
4、启动 ResourceManager

3.2 Dispatcher 启动 JobManager
⭐ Dispatcher.java ### 3.3 ResourceManager 启动 SlotManager
⭐ ResourceManager.java
### 3.3 ResourceManager 启动 SlotManager
⭐ ResourceManager.java
 3.3.1 创建 Yarn 的 RM 和 NM 客户端
⭐ ActiveResourceManager.java
3.3.1 创建 Yarn 的 RM 和 NM 客户端
⭐ ActiveResourceManager.java
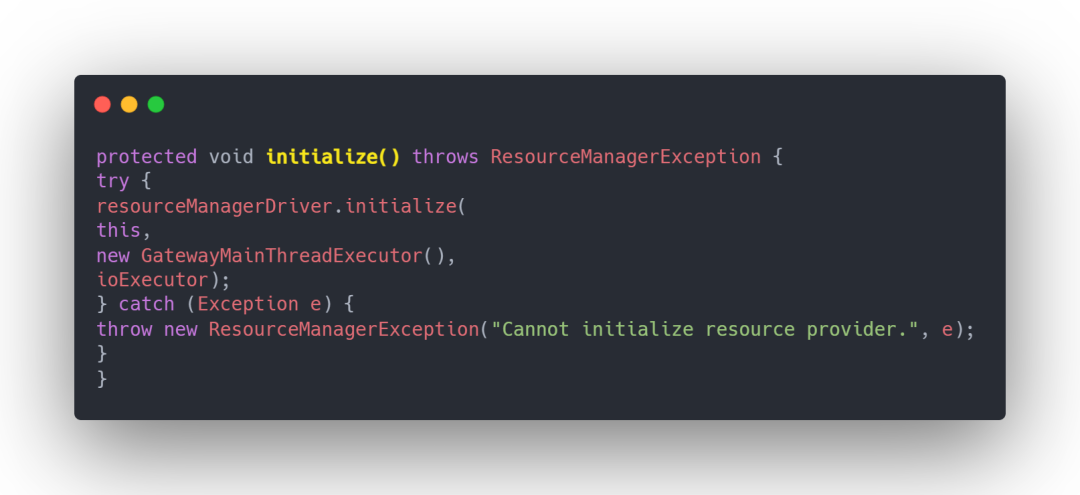 ⭐ YarnResourceManagerDriver.java
在 YarnResourceManagerDriver 里面创建和启动 yarn 的 resourcemanager 客户端,创建和启动 yarn 的 nodemanager 客户端
⭐ YarnResourceManagerDriver.java
在 YarnResourceManagerDriver 里面创建和启动 yarn 的 resourcemanager 客户端,创建和启动 yarn 的 nodemanager 客户端
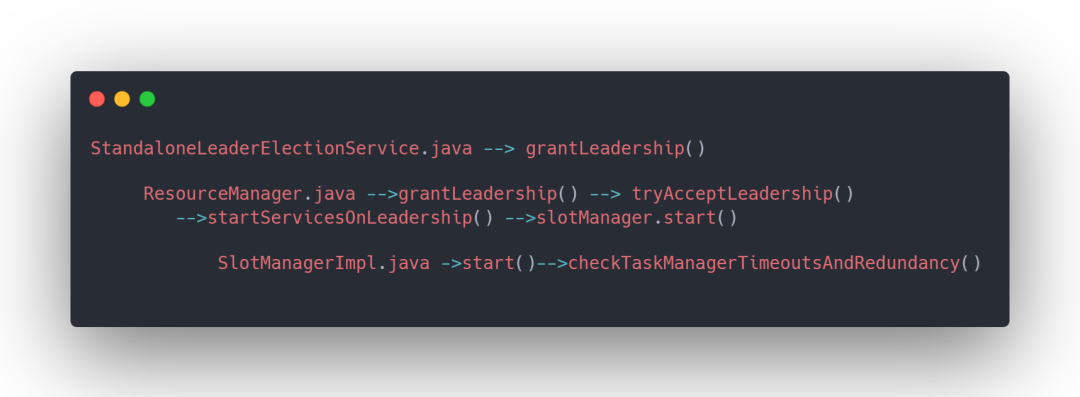
 3.3.2 启动 SlotManager
如下为类之间的方法调用,最后在 checkTaskManagerTimeoutsAndRedundancy 方法中 进行判断:
如果没有 job 在运行,释放 taskmanager,保证随时有足够的 taskmanager
3.3.2 启动 SlotManager
如下为类之间的方法调用,最后在 checkTaskManagerTimeoutsAndRedundancy 方法中 进行判断:
如果没有 job 在运行,释放 taskmanager,保证随时有足够的 taskmanager
 ### 4 JobMaster 向 ResourceManager 申请资源
JobMaster 向 ResourceManager 申请 Slot 资源,开始调度 ExecutionGraph。
### 4 JobMaster 向 ResourceManager 申请资源
JobMaster 向 ResourceManager 申请 Slot 资源,开始调度 ExecutionGraph。### 5 ResourceManager 申请资源 ⭐ ResourceManager.java
 ### 6 TaskManager 启动
⭐ 入口类为 YarnTaskExecutorRunner
### 6 TaskManager 启动
⭐ 入口类为 YarnTaskExecutorRunner

进入到 runTaskManagerSecurely()方法中

7 TaskManager 启动
⭐ TaskExecutor.java
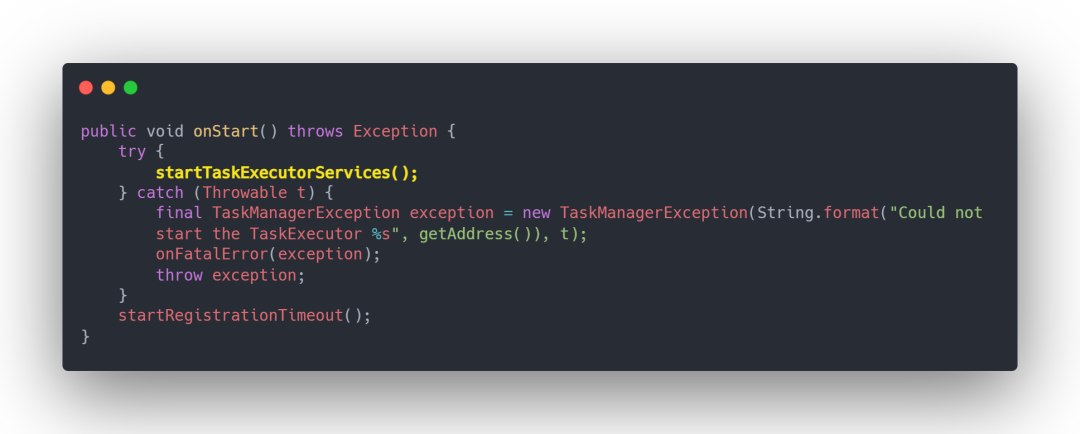
8 向 ResourceManager 注册 slot
⭐ TaskExecutor.java

9 ResourceManager 分配 Slot
⭐ SlotManagerImpl.java
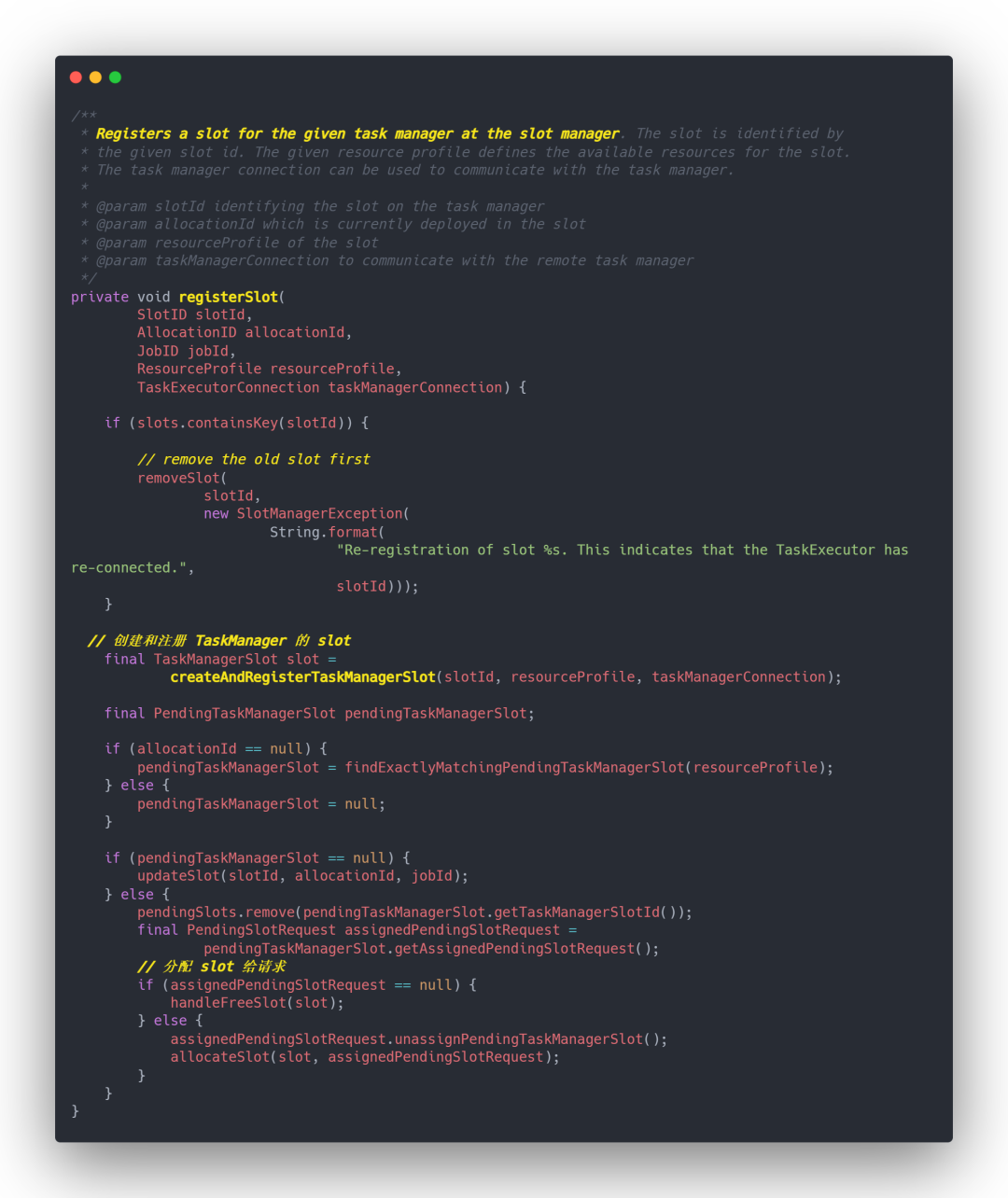
10 TaskManager 提供 Slot
⭐ TaskExecutor.java

11 提交 Task 任务
JobMaster 调度 Task 到 TaskMnager 的 Slot 上执行
3. 源码提交流程总结
1、客户端(入口类 CliFrontend)
⭐1.1 执行启动脚本,进入 CliFrontend 类的 main 方法中,获取 flink conf 目录配置的路径,然后对其进行加载,同时依次添加 3 种客户端类型,并创建 CliFrontend 对象;
⭐1.2 在 main 中执行 parseAndRun 对提交的命令行参数进行解析;
⭐1.3 在解析命令时,根据提交的 run 模式选择对于的run方法,在run方法中选择 FlinkYarnSessionCli 作为客户端;
⭐1.4 在 run 方法中调用 executeProgram 进入用户自定义代码
⭐1.5 在用户自定义代码中执行 execute(),通过 getStreamGraph() 方法生成 streamGraph;
⭐1.6 选择 YarnJobClusterExecutor 作为 pipelineExecutor,并生成 jobGraph;
⭐1.7 创建并启动 yarn 客户端,获取集群配置参数
⭐1.8 部署集群,将应用配置(Flink-conf.yaml、logback.xml、log4j.properties)和相关文件(Flink Jar、配置类文件、用户 Jar 文件、JobGraph 对象等)上传至分布式存储 HDFS 中。
⭐1.9 封装 ApplicationMaster 参数和命令,生出 ClusterClientJobClient
⭐1.10 ClusterClientJobClient 向 Yarn ResourceManager 提交任务信息
2、启动 ApplicationMaster
⭐2 Yarn ResourceManager 收到提交的任务信息后,将分配 Container 资源,并通知对应的 NodeManager 启动一个 ApplicationMaster (每提交一个 Flink job 就会启动一个 ApplicationMaster)
3、作业提交
⭐3.1 ApplicationMaster 启动 Dispatcher 和 ResourceManager ;
⭐3.2 Dispatcher 启动 JobMaster (该步和 Session 不同,Jabmaster 是由 Dispatcher 拉起,而不是 Client 传过来的)。
JobMaster 负责作业调度,管理作业和 Task 的生命周期,构建 ExecutionGraph( JobGraph 的并行化版本,调度层最核心的数据结构。
4、作业调度执行
⭐4 JobMaster 向 ResourceManager 申请 Slot 资源,开始调度 ExecutionGraph。
⭐5 ResourceManager 将资源请求加入等待队列,通过心跳向 YarnResourceManager 申请新的 Container 来启动 TaskManager 进程。
⭐6 YarnResourceManager 启动,然后从 HDFS 加载 Jar 文件等所需相关资源,在容器中启动 TaskManager。
⭐7 TaskManager 在内部启动 TaskExecutor。
⭐8 TaskManager 启动后,向 ResourceManager 注册,并把自己的 Slot 资源情况汇报给 ResourceManager。
⭐9 ResourceManager 从等待队列取出 Slot 请求,向 TaskManager 确认资源可用情况,并告知 TaskManager 将 Slot 分配给哪个 JobMaster。
⭐10 TaskManager 向 JobMaster 回复自己的一个 Slot 属于你这个任务,JobMaser 会将 Slot 缓存到 SlotPool。
⭐11 JobMaster 调度 Task 到 TaskMnager 的 Slot 上执行。

若有收获,就点个赞吧
0 人点赞
