1. SparkSQL执行
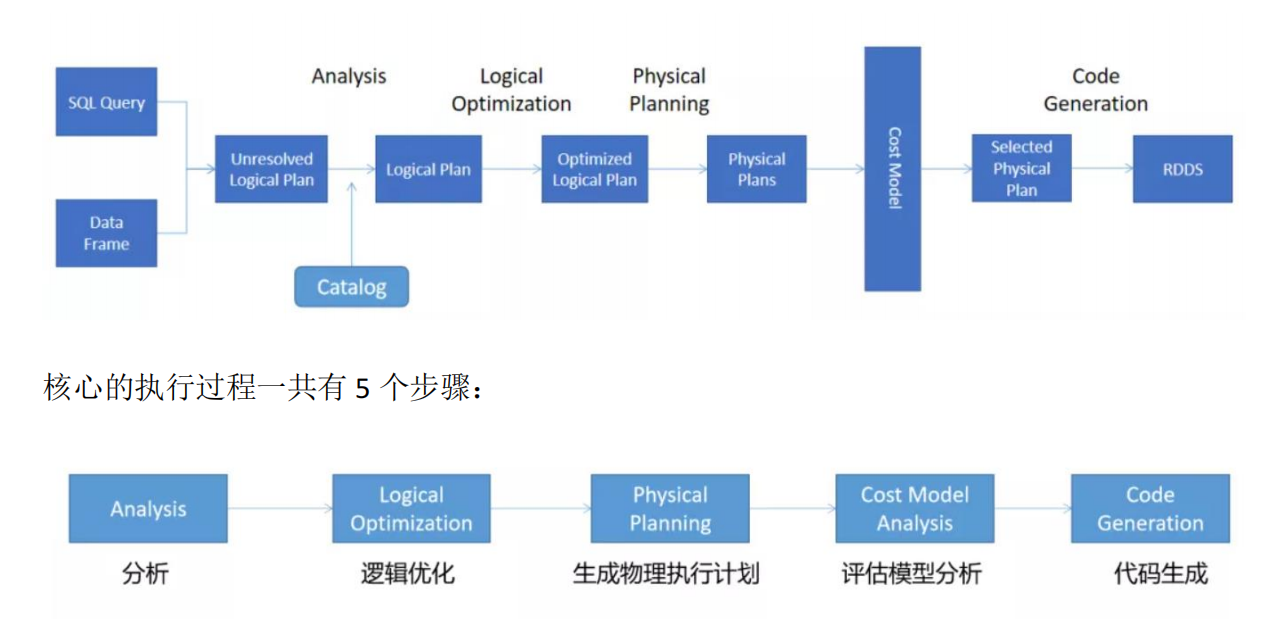 ➢ Unresolved 逻辑执行计划:== Parsed Logical Plan ==
➢ Unresolved 逻辑执行计划:== Parsed Logical Plan ==
Parser 组件检查 SQL 语法上是否有问题,然后生成 Unresolved(未决断)的逻辑计划,
不检查表名、不检查列名。
➢ Resolved 逻辑执行计划:== Analyzed Logical Plan ==
通过访问 Spark 中的 Catalog 存储库来解析验证语义、列名、类型、表名等。
➢ 优化后的逻辑执行计划:== Optimized Logical Plan ==
Catalyst 优化器根据各种规则进行优化。
➢ 物理执行计划:== Physical Plan ==
- HashAggregate 运算符表示数据聚合,一般 HashAggregate 是成对出现,第一个 HashAggregate 是将执行节点本地的数据进行局部聚合,另一个 HashAggregate 是将各个分区的数据进一步进行聚合计算。
- Exchange 运算符其实就是 shuffle,表示需要在集群上移动数据。很多时候 HashAggregate 会以Exchange 分隔开来。
- Project 运算符是 SQL 中的投影操作,就是选择列(例如:select name, age…)。
- BroadcastHashJoin 运算符表示通过基于广播方式进行 HashJoin。
- LocalTableScan 运算符就是全表扫描本地的表。
从 3.0 开始,explain 方法有一个新的参数 mode,该参数可以指定执行计划展示格式:
➢ explain(mode=”simple”):只展示物理执行计划。
➢ explain(mode=”extended”):展示物理执行计划和逻辑执行计划。
➢ explain(mode=”codegen”) :展示要 Codegen 生成的可执行 Java 代码。
➢ explain(mode=”cost”):展示优化后的逻辑执行计划以及相关的统计。
➢ explain(mode=”formatted”):以分隔的方式输出,它会输出更易读的物理执行计划,并展示每个节点的详细信息
2. 资源调优
2.1 资源规划
资源设定上限估算:
1、总体原则
以单台服务器 128G 内存,32 线程为例。
先设定单个 Executor 核数,根据 Yarn 配置得出每个节点最多的 Executor 数量,每个节点的 yarn 内存/每个节点数量=单个节点的数量
总的 executor 数=单节点数量节点数。
2、具体提交参数
1)executor-cores
每个 executor 的最大核数。根据经验实践,设定在 3~6 之间比较合理。
2)num-executors
该参数值=每个节点的 executor 数 work 节点数
每个 node 的 executor 数 = 单节点 yarn 总核数 / 每个 executor 的最大 cpu 核数
考虑到系统基础服务和 HDFS 等组件的余量,yarn.nodemanager.resource.cpu-vcores 配置为:28,参数 executor-cores 的值为:4,那么每个 node 的 executor 数 = 28/4 = 7,假设集群节点为 10,那么 num-executors = 7 10 = 70
3)executor-memory
该参数值=yarn-nodemanager.resource.memory-mb / 每个节点的 executor 数量
如果 yarn 的参数配置为 100G,那么每个 Executor 大概就是 100G/7≈14G,同时要注意yarn 配置中每个容器允许的最大内存是否匹配。
内存估算: ➢ 估算 Other 内存 = 自定义数据结构每个 Executor 核数
➢ 估算 Other 内存 = 自定义数据结构每个 Executor 核数
➢ 估算 Storage 内存 = 广播变量 + cache/Executor 数量
➢ 估算 Executor 内存 = 每个 Executor 核数 * (数据集大小/并行度)
2.2 持久化和序列化
kryo+序列化缓存
使用 kryo 序列化并且使用 rdd 序列化缓存级别。使用 kryo 序列化需要修改 spark 的序列化模式,并且需要进程注册类操作。
根据官网的描述,那么可以推断出,如果 yarn 内存资源充足情况下,使用默认级别 MEMORY_ONLY 是对 CPU 的支持最好的。但是序列化缓存可以让体积更小,那么当 yarn 内存资源不充足情况下可以考虑使用 MEMORY_ONLY_SER 配合 kryo 使用序列化缓存。
DataSet 可以直接使用 cache。
从性能上来讲,DataSet,DataFrame 大于 RDD,建议开发中使用 DataSet、DataFrame。
2.3 CPU 优化
CPU低效原因
1)并行度
➢ spark.default.parallelism
设置 RDD 的默认并行度,没有设置时,由 join、reduceByKey 和 parallelize 等转换决定。
➢ spark.sql.shuffle.partitions
适用 SparkSQL 时,Shuffle Reduce 阶段默认的并行度,默认 200。此参数只能控制 Spark sql、DataFrame、DataSet 分区个数。不能控制 RDD 分区个数
2)并发度:同时执行的 task 数
CPU 低效原因
1)并行度较低、数据分片较大容易导致 CPU 线程挂起
2)并行度过高、数据过于分散会让调度开销更多
Executor 接收到 TaskDescription之后,首先需要对TaskDescription 反序列化才能读取任务信息,然后将任务代码再反序列化得到可执行代码,最后再结合其他任务信息创建 TaskRunner。当数据过于分散,分布式任务数量会大幅增加,但每个任务需要处理的数据量却少之又少,就CPU消耗来说,相比花在数据处理上的比例,任务调度上的开销几乎与之分庭抗礼。显然,在这种情况下,CPU的有效利用率也是极低的。
合理利用 CPU 资源
每个并行度的数据量(总数据量/并行度) 在(Executor 内存/core 数/2, Executor 内存 /core 数)区间
去向 yarn 申请的 executor vcore 资源个数为 12 个(num-executors*executor-cores),如果不修改spark sql 分区个数,那么就会像上图所展示存在 cpu 空转的情况。这个时候需要合理控制 shuffle 分区个数。如果想要让任务运行的最快当然是一个 task 对应一个 vcore,但是一般不会这样设置,为了合理利用资源,一般会将并行度(task 数)设置成并发度(vcore 数)的 2 倍到 3 倍。
修改参数 spark.sql.shuffle.partitions(默认 200), 根据我们当前任务的提交参数有 12 个 vcore,将此参数设置为 24 或 36 为最优效果
3. SparkSQL 语法优化
4. 数据倾斜
绝大多数 task 任务运行速度很快,但是就是有那么几个 task 任务运行极其缓慢,慢慢的可能就接着报内存溢出的问题。
数据倾斜一般是发生在 shuffle 类的算子,比如 distinct、groupByKey、reduceByKey、 aggregateByKey、join、cogroup 等,涉及到数据重分区,如果其中某一个 key 数量特别大, 就发生了数据倾斜。
数据倾斜大 key 定位
从所有 key 中,把其中每一个 key 随机取出来一部分,然后进行一个百分比的推算,这是用局部取推算整体,虽然有点不准确,但是在整体概率上来说,我们只需要大概就可以定位那个最多的 key 了
单表数据倾斜优化
为了减少 shuffle 数据量以及 reduce 端的压力,通常 Spark SQL 在 map 端会做一个 partial aggregate(通常叫做预聚合或者偏聚合),即在 shuffle 前将同一分区内所属同 key 的记录先进行一个预结算,再将结果进行 shuffle,发送到 reduce 端做一个汇总,类似 MR 的提前 Combiner,所以执行计划中 HashAggregate 通常成对出现。
1、适用场景
聚合类的 shuffle 操作,部分 key 数据量较大,且大 key 的数据分布在很多不同的切片。
2、解决逻辑
两阶段聚合(加盐局部聚合+去盐全局聚合)
Join 数据倾斜优化
1 广播 Join
1、适用场景
适用于小表 join 大表。小表足够小,可被加载进 Driver 并通过 Broadcast 方法广播到各个 Executor 中。
2、解决逻辑
在小表 join 大表时如果产生数据倾斜,那么广播 join 可以直接规避掉此 shuffle 阶段。直接优化掉 stage。并且广播 join 也是 Spark Sql 中最常用的优化方案。
2 拆分大 key 打散大表 扩容小表
1、适用场景
适用于 join 时出现数据倾斜。
2、解决逻辑
1)将存在倾斜的表,根据抽样结果,拆分为倾斜 key(skew 表)和没有倾斜 key(common)的两个数据集。
2)将 skew 表的 key 全部加上随机前缀,然后对另外一个不存在严重数据倾斜的数据集(old 表)整体与随机前缀集作笛卡尔乘积(即将数据量扩大 N 倍,得到 new 表)。
3)打散的 skew 表 join 扩容的 new 表
union
Common 表 join old 表
以下为打散大 key 和扩容小表的实现思路
1)打散大表:实际就是数据一进一出进行处理,对大 key 前拼上随机前缀实现打散
2)扩容小表:实际就是将 DataFrame 中每一条数据,转成一个集合,并往这个集合里循环添加 10 条数据,最后使用 flatmap 压平此集合,达到扩容的效果.
3 参设开启 AQE
5. Job优化
6. 故障排除
故障排除一:控制 reduce 端缓冲大小以避免 OOM
在 Shuffle 过程,reduce 端 task 并不是等到 map 端 task 将其数据全部写入磁盘后再去拉取,而是 map 端写一点数据,reduce 端 task 就会拉取一小部分数据,然后立即进行后面的聚合、算子函数的使用等操作。
reduce 端 task 能够拉取多少数据,由 reduce 拉取数据的缓冲区 buffer 来决定,因为拉取过来的数据都是先放在 buffer 中,然后再进行后续的处理,buffer 的默认大小为 48MB。
reduce 端 task 会一边拉取一边计算,不一定每次都会拉满 48MB 的数据,可能大多数时候拉取一部分数据就处理掉了。
虽然说增大 reduce 端缓冲区大小可以减少拉取次数,提升 Shuffle 性能,但是有时map 端的数据量非常大,写出的速度非常快,此时 reduce 端的所有 task 在拉取的时候,有可能全部达到自己缓冲的最大极限值,即 48MB,此时,再加上 reduce 端执行的聚合函数的代码,可能会创建大量的对象,这可难会导致内存溢出,即 OOM。
如果一旦出现 reduce 端内存溢出的问题,我们可以考虑减小 reduce 端拉取数据缓冲区的大小,例如减少为 12MB。
在实际生产环境中是出现过这种问题的,这是典型的以性能换执行的原理。reduce 端拉取数据的缓冲区减小,不容易导致 OOM,但是相应的,reudce 端的拉取次数增加,造成更多的网络传输开销,造成性能的下降。 注意,要保证任务能够运行,再考虑性能的优化。
故障排除二:JVM GC 导致的 shuffle 文件拉取失败
在 Spark 作业中,有时会出现 shuffle file not found 的错误,这是非常常见的一个报错, 有时出现这种错误以后,选择重新执行一遍,就不再报出这种错误。
出现上述问题可能的原因是 Shuffle 操作中,后面 stage 的 task 想要去上一个 stage 的task 所在的 Executor 拉取数据,结果对方正在执行 GC,执行 GC 会导致 Executor 内所有的工作现场全部停止,比如 BlockManager、基于 netty 的网络通信等,这就会导致后面的task 拉取数据拉取了半天都没有拉取到,就会报出 shuffle file not found 的错误,而第二次再次执行就不会再出现这种错误。
可以通过调整 reduce 端拉取数据重试次数和 reduce 端拉取数据时间间隔这两个参数来对 Shuffle 性能进行调整,增大参数值,使得 reduce 端拉取数据的重试次数增加,并且每次失败后等待的时间间隔加长。
故障排除三:解决各种序列化导致的报错
当 Spark 作业在运行过程中报错,而且报错信息中含有 Serializable 等类似词汇,那么可能是序列化问题导致的报错。
序列化问题要注意以下三点:
➢ 作为 RDD 的元素类型的自定义类,必须是可以序列化的;
➢ 算子函数里可以使用的外部的自定义变量,必须是可以序列化的;
➢ 不可以在 RDD 的元素类型、算子函数里使用第三方的不支持序列化的类型,例如 Connection。
故障排除四:解决算子函数返回 NULL 导致的问题
在一些算子函数里,需要我们有一个返回值,但是在一些情况下我们不希望有返回值,此时我们如果直接返回 NULL,会报错,例如 Scala.Math(NULL)异常。如果你遇到某些情况,不希望有返回值,那么可以通过下述方式解决:
➢ 返回特殊值,不返回 NULL,例如“-1”;
➢ 在通过算子获取到了一个 RDD 之后,可以对这个 RDD 执行 filter 操作,进行数据过滤,将数值为-1 的数据给过滤掉;
➢ 在使用完 filter 算子后,继续调用 coalesce 算子进行优化。
故障排除六:解决 YARN-CLUSTER 模式的 JVM 栈内存溢出无法执行问题
解决上述问题的方法时增加 PermGen 的容量,需要在 spark-submit 脚本中对相关参数进行设置,设置方法如代码清单所示。
—conf spark.driver.extraJavaOptions=”-XX:PermSize=128M -XX:MaxPermSize=256M”
通过上述方法就设置了 Driver 永久代的大小,默认为 128MB,最大 256MB,这样就可以避免上面所说的问题。
故障排除七:解决 SparkSQL 导致的 JVM 栈内存溢出
建议将一条 sql 语句拆分为多条 sql 语句来执行,每条 sql 语句尽量保证 100 个以内的子句。根据实际的生产环境试验,一条 sql 语句的 or 关键字控制在 100 个以内,通常不会导致 JVM 栈内存溢出。
故障排除八:持久化与 checkpoint 的使用
使用 checkpoint 的优点在于提高了 Spark 作业的可靠性,一旦缓存出现问题,不需要重新计算数据,缺点在于,checkpoint 时需要将数据写入 HDFS 等文件系统,对性能的消耗较大。
故障排除十:频繁 GC 问题
1、打印 GC 详情
统计一下 GC 启动的频率和 GC 使用的总时间,在 spark-submit 提交的时候设置参数 —conf “spark.executor.extraJavaOptions=-XX:+PrintGCDetails - XX:+PrintGCTimeStamps” 如果出现了多次 Full GC,首先考虑的是可能配置的 Executor 内存较低,这个时候需要增加 Executor Memory 来调节。
2、如果一个任务结束前,Full GC 执行多次,说明老年代空间被占满了,那么有可能是没有分配足够的内存。
- 调整 executor 的内存,配置参数 executor-memory
- 调整老年代所占比例:配置-XX:NewRatio 的比例值
- 降低 spark.memory.storageFraction 减少用于缓存的空间
3、如果有太多 Minor GC,但是 Full GC 不多,可以给 Eden 分配更多的内存。
- 比如 Eden 代的内存需求量为 E,可以设置 Young 代的内存为-Xmn=4/3*E,设置该值也会导致 Survivor 区域扩张
- 调整 Eden 在年轻代所占的比例,配置-XX:SurvivorRatio 的比例值
4、调整垃圾回收器,通常使用 G1GC,即配置-XX:+UseG1GC。当 Executor 的堆空间比 较大时,可以提升 G1 region size(-XX:G1HeapRegionSize),在提交参数指定: —conf “spark.executor.extraJavaOptions=-XX:+UseG1GC - XX:G1HeapRegionSize=16M -XX:+PrintGCDetails -XX:+PrintGCTimeStamps”

若有收获,就点个赞吧
0 人点赞
