数据清洗
由于我们拿到的数据通常不会是干干净净的,所谓不干净就是说:数据中存在缺失值、一些异常点,这样的数据通常需要经过一定的处理才能继续做后面的分析或建模,故,我们在拿到数据的第一步通常是进行数据清洗。
1. 缺失值
例如:本次课程中我们通过打印可以看到泰坦尼克数据中的Cabin列存在NaN
1)观察
(1) df.info()(2) df.isnull().sum()
2) 处理
通过查阅API文档,我们可以看到如下方法可以进行缺失值的处理,官方的API写的很清晰的,很宝藏的~~~
链接:https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.fillna.html#pandas.DataFrame.fillna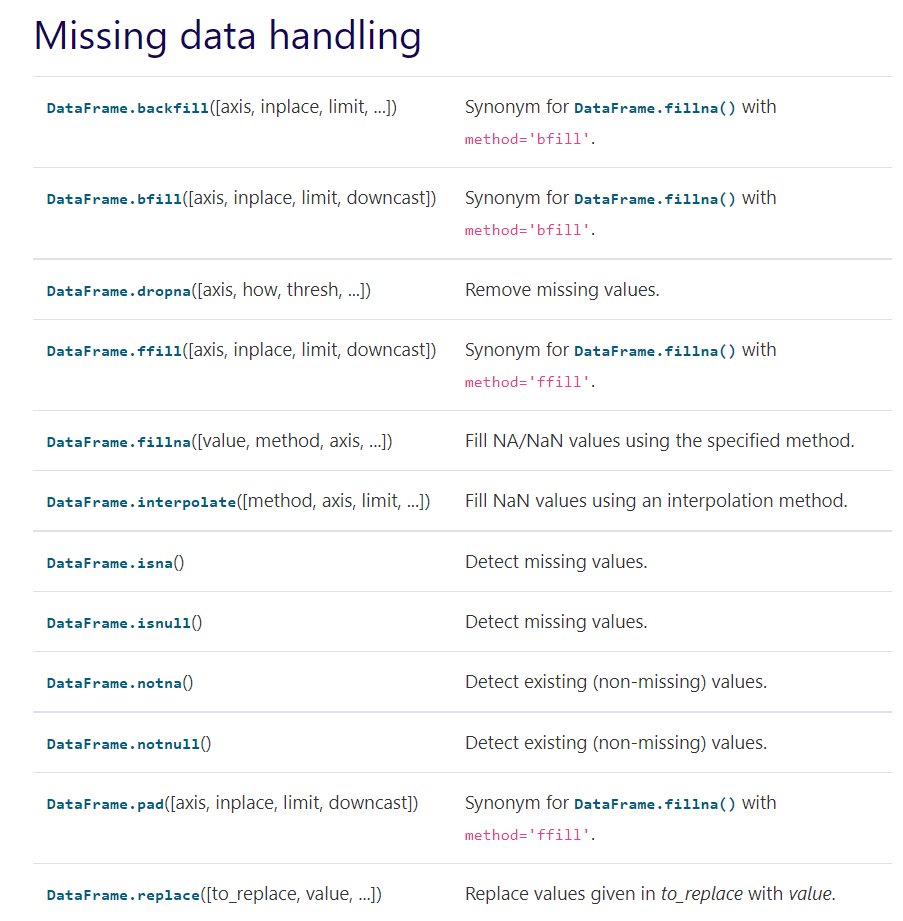
(1) df[df['Age']==None]=0 # 没有成功(2) df[df['Age'].isnull()] = 0 # 还好(3) df[df['Age'] == np.nan] = 0 # 没有成功# 对上面的内容还不太理解(4) df.fillna(0)
【思考】检索空缺值用np.nan,None以及.isnull()哪个更好,这是为什么?如果其中某个方式无法找到缺失值,原因又是为什么?
数值列读取数据后,空缺值的数据类型为float64所以用None一般索引不到,比较的时候最好用np.nan
2. 重复值
1)查看
df[df.duplicated()]
2)处理
df = df.drop_duplicates()
3. 特征观察与处理
这里可以把特征大概分为两大类:
数值型特征:Survived ,Pclass, Age ,SibSp, Parch, Fare,
其中: Survived, Pclass为离散型数值特征,Age,SibSp, Parch, Fare为连续型数值特征
文本型特征:Name, Sex, Cabin,Embarked, Ticket,
其中: Sex, Cabin, Embarked, Ticket为类别型文本特征。
数值型特征一般可以直接用于模型的训练,但有时候为了模型的稳定性及鲁棒性会对连续变量进行离散化。文本型特征往往需要转换成数值型特征才能用于建模分析。
1) 对年龄进行分箱(离散化)处理
分箱操作是什么?
分箱操作就是将连续数据转换为分类对应物的过程。
将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
df['AvgBand'] = pd.cut(df['Age'], 5, labels = [1, 2, 3, 4, 5])
将连续变量Age划分为(0,5] (5,15] (15,30] (30,50] (50,80]五个年龄段,并分别用类别变量12345表示
df['AgeBand'] = pd.cut(df['Age'], [0, 5, 15, 30, 50, 80], labels = [1, 2, 3, 4, 5])
将连续变量Age按10% 30% 50 70% 90%五个年龄段,并用分类变量12345表示
df['AgeBand'] = pd.qcut(df['Age'].rank(method='first'),[0, 0.1,0.3,0.5,0.7,0.9],labels = [1,2,3,4,5],)
2) 对文本变量进行转换
- 查看(以Sex变量为例)
value_counts
df['Sex'].value_counts()
unique
df['Sex'].unique()
- 文本转换
replace
df['Sex_num'] = df['Sex'].replace(['male', 'female'], [1, 2])
map
df['Sex_num'] = df['Sex'].map({'male': 1, 'female': 2})
使用sklearn.preprocessing的LabelEncoder
from sklearn.preprocessing import LabelEncoderfor feat in ['Cabin', 'Ticket']:lbl = LabelEncoder()label_dict = dict(zip(df[feat].unique(), range(df[feat].nunique())))df[feat + "_labelEncode"] = df[feat].map(label_dict)df[feat + "_labelEncode"]= lbl.fit_transform(df[feat].astype(str))
将类别文本转换为one-hot编码
#方法OneHotEncoderfor feat in ['Age', 'Embarked']:x = pd.get_dummies(df[feat], prefix=feat)df = pd.concat([df, x], axis=1)
从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
df['Title'] = df.Name.str.extract('([A-Za-z]+)\.', expand=False)

若有收获,就点个赞吧
0 人点赞
