1.数据载入
相关包:numpy&&pandas
import numpy as npimport pandas as pd
载入数据
df = pd.read_csv("train.csv")df.head(3)
思考:pd.read_csv()和pd.read_table()的区别?
‘’’
1、pd.read_csv()和pd.read_table()的区别:
read_csv()从文件、url、文件型对象中加载带分隔符的数据,默认分隔符为逗号;read_table()从文件、url、文件型对象中加载带分隔符的数据,默认分隔符为制表符;
2、’.tsv’和’.csv’的不同:T
TSV 是Tab-separated values的缩写,即制表符分隔值;CSV是Comma-separated values,即逗号分隔值。
TSV与CSV的区别: 1)从名称上即可知道,TSV是用制表符(Tab,’\t’)作为字段值的分隔符;CSV是用半角逗号(’,’)作为字段值的分隔符; 2)IANA规定的标准TSV格式,字段值之中是不允许出现制表符的。
思考: 什么是逐块读取?为什么要逐块读取呢?
‘’’
逐块读取就是将文本分成若干块;
对于几百MB的CSV文件,可以直接使用pd.read_csv()进行读取。然而如果csv文件太大,达到几个Gb,这种方法就不可取。这时应使用chunk,进行分块读取;
通过设置chunksize的参数,控制每次迭代的大小;如上面的数据只有891行,参数设置1000后只迭代了一次;改成500试一下,循环打印了两次;
chunker = pd.read_csv("train.csv", chunksize=500)for cuk in chunker:print(cuk)
保存数据
# df.to_csv('train_chinese.csv', encoding='utf-8') #中文存在乱码df.to_csv('train_chinese.csv', encoding='GBK')
注意:不同的操作系统保存下来可能会有乱码。大家可以加入encoding='GBK' 或者 ’encoding = ’utf-8‘
2. Pandas基础
查看数据的基础信息
df.info(): # 打印摘要df.describe(): # 描述性统计信息df.values: # 数据df.to_numpy() # 数据 (推荐)df.shape: # 形状 (行数, 列数)df.columns: # 列标签df.columns.values: # 列标签df.index: # 行标签df.index.values: # 行标签df.head(n): # 前n行df.tail(n): # 尾n行pd.options.display.max_columns=n: # 最多显示n列pd.options.display.max_rows=n: # 最多显示n行df.memory_usage(): # 占用内存(字节B)
判断数据是否为空,为空的地方返回True,其余地方返回False
df.isnull()
查看”Cabin”这列的所有值
(1) df["Cabin"](2) df.Cabin
删除多余的列的方式
(1) del df["a"](2) df.drop(['Unnamed: 0','PassengerId','Name','Age','Ticket'], axis=1)(3) df.drop(['Unnamed: 0','PassengerId','Name','Age','Ticket', 'a'], axis=1, inplace=True)
删除列的方式有两种:del(删除单列) 和 drop(可以选择删除多列), 其中2,3之间的区别在于:使用inplace=True,会将原数据覆盖了,如果想要完全的删除你的数据结构,可以选择设置一下
筛选
df[df['Age']<10].head(4) #显示年龄在10岁以下的乘客信息midage = df[(df['Age']>10)&(df['Age']<50)] #将年龄在10岁以上和50岁以下的乘客信息显示出来,并将这个数据命名为midage
【思考】对比iloc和loc的异同
1.loc: 通过列标签索引列数据
2.iloc: 通过列索引获取行数据,不能是字符
# 使用loc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来midage.loc[[100, 105, 108], ["Pclass", "Name", "Sex"]]# 使用iloc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来midage.iloc[[100, 105, 108], [2, 3, 4]]
探索性数据分析
#自己构建一个都为数字的DataFrame数据frame = pd.DataFrame(np.arange(8).reshape((2, 4)),index=['2', '1'],columns=['d', 'a', 'b', 'c'])
pd.DataFrame() :创建一个DataFrame对象
np.arange(8).reshape((2, 4)) : 生成一个二维数组(24),第一列:0,1,2,3 第二列:4,5,6,7
index=[‘2, 1] :DataFrame 对象的索引列
*columns=[‘d’, ‘a’, ‘b’, ‘c’] :DataFrame 对象的索引行
排序方式
索引排序
frame.sort_index() # 让行索引升序排序frame.sort_index(ascending=False) # 让行索引降序排序frame.sort_index(axis=1) # 让列索引升序排序frame.sort_index(axis=1, ascending=False) # 让列索引降序排序
列值排序
frame.sort_values(by='c', ascending=True) # 单列, 升序frame.sort_values(by=['a', 'c'], ascending=False) # 两列, 降序
DataFrame数据相加
frame1_a = pd.DataFrame(np.arange(9.).reshape(3, 3),columns=['a', 'b', 'c'],index=['one', 'two', 'three'])frame1_b = pd.DataFrame(np.arange(12.).reshape(4, 3),columns=['a', 'e', 'c'],index=['first', 'one', 'two', 'second'])frame1_a + frame1_b

提示: 两个DataFrame相加后,会返回一个新的DataFrame,对应的行和列的值会相加,没有对应的会变成空值NaN。DataFrame还有很多算术运算,如减法,除法等
Pandas describe()函数查看数据基本统计信息
df.describe()#count : 样本数据大小#mean : 样本数据的平均值#std : 样本数据的标准差#min : 样本数据的最小值#25% : 样本数据25%的时候的值#50% : 样本数据50%的时候的值#75% : 样本数据75%的时候的值#max : 样本数据的最大值
例子:
'''看看泰坦尼克号数据集中 票价 这列数据的基本统计数据'''text['票价'].describe()
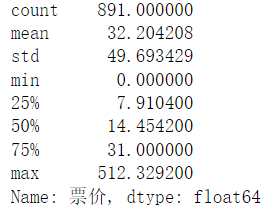
其中:一共有891个票价数据,
平均值约为:32.20,
标准差约为49.69,说明票价波动特别大,
25%的人的票价是低于7.91的,
50%的人的票价低于14.45,
75%的人的票价低于31.00,
票价最大值约为512.33,
票价最小值为0。

若有收获,就点个赞吧
0 人点赞
