- 前言
- 正文
- 前置知识
- Blob、File、URL.createObjectURL
- Base64、atob、btoa
- ArrayBuffer、Uint8Array
- Blob、File、Base64、ArrayBuffer相互转换
- 同源(域)和跨域
- 前端下载(同源)
- A标签
- window.open
- Ajax下载
- 前端下载(跨域)
- iframe下载
- Form表单下载
- NPM库推荐
- 前置知识
- 结束语
-
前言
在中后台项目中,前端难免需要处理下载的逻辑,需要下载的内容包括但不限于图片、Excel表格、CSV文件、MP4文件、PDF文件、TXT文件、JSON文件、HTML文件等等。虽然下载的内容各式各样,但是下载的原理大同小异。下面来一起学习一下前端是如何处理下载的。
正文
在讲下载之前,需要了解几个JS的对象,因为这些对象都跟下载息息相关。
前置知识
Blob、File、URL.createObjectURL、URL.revokeObjectURLURL
Blob 对象表示一个不可变、原始数据的类文件对象。它的数据可以按文本或二进制的格式进行读取,也可以转换成 ReadableSteam来用于数据操作。
Blob 表示的不一定是JavaScript原生格式的数据。File接口基于Blob,继承了 blob 的功能并将其扩展使其支持用户系统上的文件。
Blob 构造函数用法举例:

File对象接口提供有关文件的信息,并允许网页中的 JavaScript 访问其内容。
通常情况下, File 对象是来自用户在一个 input元素上选择文件后返回的FileList对象,也可以是来自由拖放操作生成的DataTransfer 对象,或者来自HTMLCanvasElement上的 mozGetAsFile() API。
File 对象是特殊类型的Blob,且可以用在任意的 Blob 类型的 context 中。比如说,FileReader, URL.createObjectURL(), createImageBitmap() (en-US), 及 XMLHttpRequest.send() 都能处理 Blob 和 File。
监听Input的change事件可以在FileList数组上获取File对象。
URL.createObjectURL(object) 静态方法会创建一个 DOMString,返回格式类似’blob:http://localhost:4200/0e40281d-92e9-40cf-af54-6193fb3a3f8c'。
它接受一个object参数,用于创建 URL 的 File 对象、Blob 对象或者 MediaSource 对象。返回一个DOMString包含了一个对象URL,该URL可用于指定源 object的内容。
在每次调用 createObjectURL() 方法时,都会创建一个新的 URL 对象,即使你已经用相同的对象作为参数创建过。当不再需要这些 URL 对象时,每个对象必须通过调用 URL.revokeObjectURL() 方法来释放。
浏览器在 document 卸载的时候,会自动释放它们,但是为了获得最佳性能和内存使用状况,你应该在安全的时机主动释放掉它们。
在前端处理下载流程中,首选使用URL.createObjectURL处理。
Base64、atob、btoa
Base64是一种用64个字符来表示任意二进制数据的方法。在前端中应用于如使用Base64来展示小图片,减少HTTP请求;某些文件可以避免跨域的问题;还有我们常见的一些二进制文件,如.xlsx、.pdf等。
在 JavaScript 中,很多人不知道的是,其实有两个函数被分别用来处理解码和编码 base64 字符串,atob和btoa方法。
btoa方法用于编码,而atob方法用于解码。但是在某种情况下调用window.btoa会造成Character Out Of Range 的异常。具体可以参考一下MDN(链接在底部给出)。
ArrayBuffer、Unit8Array
ArrayBuffer、Unit8Array(无符号8位整数)是JavaScript用来操作二进制数据的。具体的概念可以参考MDN上的问题,这里就不具体阐述了。之所以在这篇文章中提出来,是因为在downloadjs中需要用到这个对象,大家可以去了解了解。
Blob、File、Base64、ArrayBuffer相互转换
为什么要先前置让大家先了解一下这几个对象呢?因为在前端下载流程中,就是用Blob、相对路径或者Base64来实现下载的。
往往我们获取图片或者其他文件时,却并非是我们想要的格式,那么可以通过以下一些方法来实现相互转换。
File转成ArrayBuffer、Base64:export function handleFiles(files) {for (var i = 0; i < files.length; i++) {var file = files[i];var reader = new FileReader();reader.onload = function (e) {console.log(e.target.result);};// 转arrayBufferreader.readAsArrayBuffer(file);// or 转 base64reader.readAsDataURL(file);}}
Base64转成Blob:
export function dataUrlToBlob(strUrl) {const parts = strUrl.split(/[:;,]/);const type = parts[1];const indexDecoder = strUrl.indexOf('charset') > 0 ? 3 : 2;const decoder = parts[indexDecoder] == 'base64' ? atob : decodeURIComponent;const binData = decoder(parts.pop());const mx = binData.length;const i = 0;const uiArr = new Uint8Array(mx);for (i; i < mx; ++i) uiArr[i] = binData.charCodeAt(i);return new myBlob([uiArr], { type: type });}
Blob转成Base64
export function blobToBase64(blob) {return new Promise((resolve, reject) => {const reader = new FileReader();reader.onabort = (e) => reject(e.message);reader.onerror = (e) => reject(e.message);reader.onload = (e) => resolve(e.target.result);reader.readAsDataURL(blob);});}
同源(域)和跨域
需要明确的是,单单从前端去处理跨域下载,是不可能的。原因是浏览器同源策略的限制。目前网络上提供的一些方法,如动态创建iframe或者form表单手动触发submit方法去跨域下载,只是允许你在前端发起一个跨域请求,而是否能够下载需要配合后台(CORS和Content-Type、Content-Disposition)来完成。
终于要进入正题了!普天同庆前端下载(同源)
A标签
处理前端下载,首选的方式就是使用A标签。HTML5针对A标签,有一个download属性。这个属性指示浏览器下载href而不是导航它。这个属性仅支持同源URL。
搭配download属性,href可以设置以下值: 同域URL
- blob:
- data:URL
如以下代码: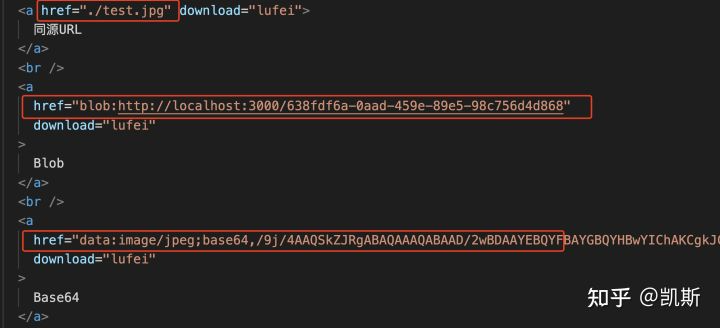
如果当前的url是跨域的URL,会走下载流程吗?答案是不会,点击之后会直接跳转到该图片上。
使用a标签的download属性来下载时,推荐以下方式
- 优先使用blob + URL方式。
- 其次是Base64方式。在不支持URL的情况下,可以采用这种方式,小文件可以采用这种,大文件不推荐。
- 最后是本地文件方式。不推荐使用这种方式,因为会增加JS打包体积。可以将图片上传到cdn。
那我们要怎么下载一个第三方图片呢,可以看下参考一下前端跨域下载的内容。
优点:
- 可以下载txt、png、pdf等类型文件
- download的属性是HTML5新增的属性 href属性的地址必须是非跨域的地址,如果引用的是第三方的网站或者说是前后端分离的项目(调用后台的接口),这时download就会不起作用。 此时,如果是下载浏览器无法解析的文件,例如.exe,.xlsx..那么浏览器会自动下载,但是如果使用浏览器可以解析的文件,比如.txt,.png,.pdf….浏览器就会采取预览模式;所以,对于.txt,.png,.pdf等的预览功能我们就可以直接不设置download属性(前提是后端响应头的Content-Type: application/octet-stream,如果为application/pdf浏览器则会判断文件为 pdf ,自动执行预览的策略)
缺点:
- a标签只能做get请求,所有url有长度限制
- 无法获取下载进度
- 无法在header中携带token做鉴权操作
- 跨域限制
- 无法判断接口是否返回成功
-
window.open
window.open方法主要是在浏览器不支持a标签的download属性中使用,使用方式跟a标签相同。
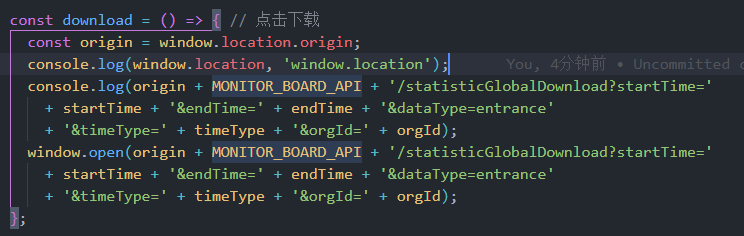
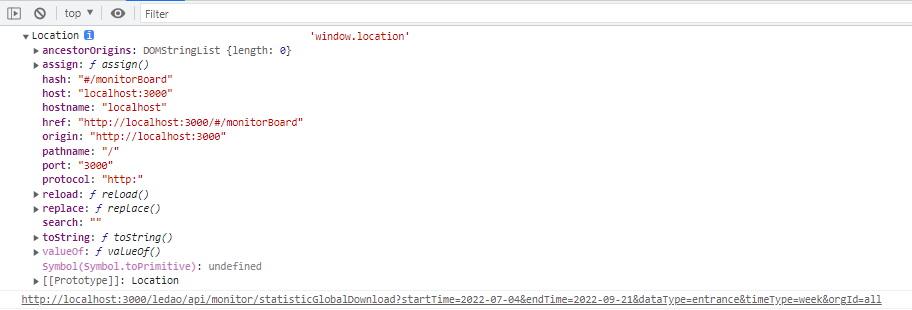
但是这里需要注意的是,当页面是https,open的url是http的情况下,会导致Chrome浏览器出现Mixed Content的错误。错误大致如下:
如果出现这种情况,可以尝试以下方法来解决: 如果请求资源支持https,可以在请求头加上,这样浏览器会将http请求转成https请求,就不会再出现Mixed Content错误了。
- 通过后台方式处理。
Ajax下载
可能有人会想,a标签和window.open,都是向浏览器发起了HTTP(S)请求,那我们是不是也可以通过ajax或者fetch来实现下载呢?
答案是不行。可以先来看看结果。当我们通过Ajax向后台发起一个download请求时,请求结果如下: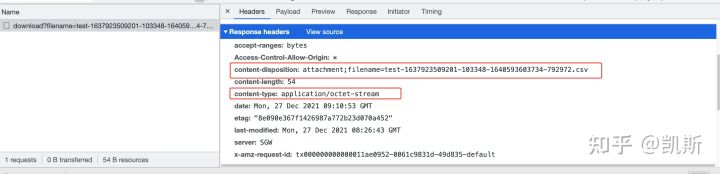

可以看到,正常情况下,当Response Header存在content-type为application/octet-stream的时候,浏览器会唤起下载框。而通过Ajax发起的请求,浏览器没有唤起下载框,反而是直接将我们需要下载的内容通过Response返回来了。
如果大家有遇到过这个问题,不知道是不是会觉得奇怪呢? 明明都是GET请求,a标签的download可以,Ajax发起GET请求却不行?
Chrome浏览器的多进程架构中,存在一个渲染进程。核心任务是将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页。出于安全考虑,渲染进程都是运行在沙箱模式下。你可以把沙箱看成是操作系统给进程上了一把锁,沙箱里面的程序可以运行,但是不能在你的硬盘上写入任何数据,也不能在敏感位置读取任何数据。
这也就是为什么Ajax无法唤起下载框的原因了。
前端下载(跨域)
由于浏览器同源限制,当你想要实现跨域下载资源时,往往都需要后台的配合。但是实现起来,也相对简单。
在Response中,需要后台设置CORS和两个header
res.header(‘Content-Type’, ‘application/octet-stream’) res.header(‘Content-Disposition’, attachment;filename=${filename})
浏览器在识别到其 Content-Type 的值是 application/octet-stream,显示数据是字节流类型的,通常情况下,浏览器会按照下载类型来处理该请求。
如果 Content-Type 字段的值被浏览器判断为下载类型,那么该请求会被提交给浏览器的下载管理器,即呼起下载框。
前端实现跨域下载的方式有两种,使用iframe或者form表单。这两种方式,实际上都是让前端可以发起一个跨域请求,而能否下载需要后台设置以上的response header。
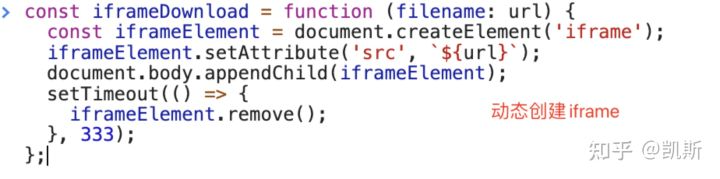
iframe下载
Iframe只支持GET请求,可以跨域是因为支持请求第三方资源。
export function iframeDownload(url, defaultMime = 'application/octet-stream') {//do iframe dataURL download (old ch+FF):const f = document.createElement('iframe');document.body.appendChild(f);if (/^data:/.test(url)) {// force a mime that will download:url = 'data:' + url.replace(/^data:([\w\/\-\+]+)/, defaultMime);}f.src = url;setTimeout(function () {document.body.removeChild(f);}, 333);}
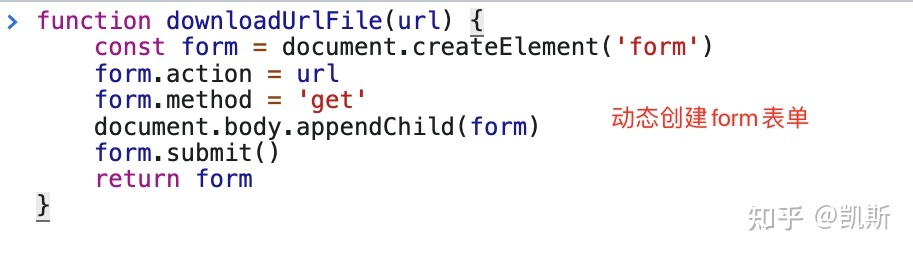
Form表单下载
Form表单之所以可以跨域,是因为JS无法获取到action后的内容,提交的form表单数据不需要返回,浏览器认为是安全的行为,所以浏览器不会阻止Form表单跨域。
Form表单可以支持GET请求和POST请求。
export function downloadFileByForm(url: string,filename: string,method = 'get') {const form = document.createElement('form');form.setAttribute('action', `${url}&bucketName=${config.bucketName}`);form.setAttribute('method', `${method}`);const input = document.createElement('input');input.setAttribute('type', 'hidden');input.setAttribute('name', 'filename');input.setAttribute('value', `${filename}`);form.appendChild(input);document.body.appendChild(form);form.submit();setTimeout(() => {document.body.removeChild(form);}, 100);}
NPM库推荐
墙裂推荐大家看看这几个仓库的源码实现,代码都非常精简,而且实现也相对简单,但是我们却可以从中学习到不少知识。
| Npm package | Address | MINIFIED + GZIPPED | Advantage |
|---|---|---|---|
| downloadjs | https://github.com/rndme/download | 1.3kB | 支持URL、File、Blob、DataUrl、ArrayBuffer |
| file-saver | https://github.com/eligrey/FileSaver.js | 1.3kB | 支持URL、File、Blob、DataUrl、ArrayBuffer |
| streamsaver | https://github.com/jimmywarting/StreamSaver.js | 1.7kB | 通过流的方式支持大文件下载 |
前端实现文件下载的方法
前端下载一般分为两种情况,一种是后端直接给一个文件地址,通过浏览器打开就可以下载,另外一种则需要发送请求,后端返回二进制流数据,前端解析流数据,生成URL,实现下载。
一、location.href
对于一些浏览器无法识别的文件格式,可以直接再浏览器地址栏输入url即可触发浏览器的下载功能。对于单文件下载没有什么问题,但是如果下载多文件,点击过快就会重置掉前面的请求
适用场景:
get请求
单文件下载
window.location.href = url;
1
二、window.open
和location.href类似
window.open(url);
三、a标签
直接下载仅适用于浏览器无法识别的文件。如果是浏览器支持的文件格式,如html、jpg、png、pdf等,则不会触发文件下载,而是直接被浏览器解析并展示,这种情况下,可以使用a标签下载文件,download属性可以设置文件名。适用于单文件下载,如果下载多文件,点击过快就会重置掉前面的请求。
适用场景:
get请求
单文件下载
需要自定义文件名
//写法1const download = (filename, url) => {let a = document.createElement('a');a.style = 'display: none'; // 创建一个隐藏的a标签a.download = filename;a.href = url;document.body.appendChild(a);a.click(); // 触发a标签的click事件document.body.removeChild(a);}// 写法2<a href="/images/download.jpg" download="myFileName">
注意:有时候对于浏览器可识别的文件格式,我们还是需要直接下载的情况,可以声明一下文件的header的 Content-Disposition信息,告诉浏览器,该链接为下载附件链接,并且可以声明文件名
Content-Disposition: attachment; filename="filename.xls"
四、文件流
如果需要使用post请求,且后端返回是一个文件流形式,那么前端需要自己将文件流转成链接,然后下载。 二进制流大概长这样: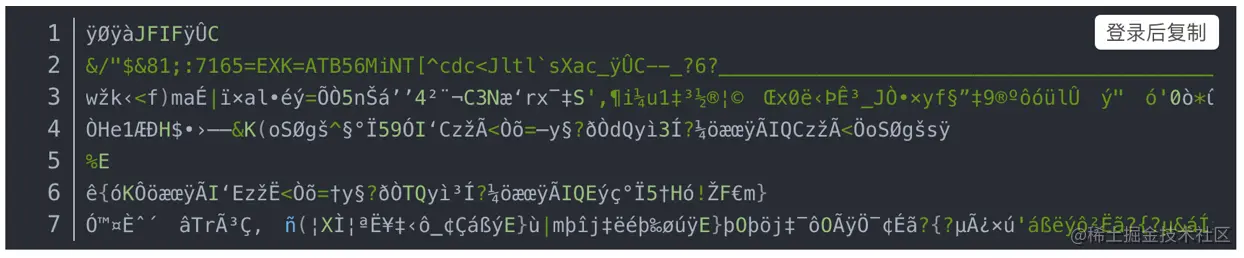
适用场景:
- post请求
- get请求
- 多文件
1.请求的方式
注意:不可以使用JQuery,因为JQuery不支持blob类型。
原生js写法 ``` const req = new XMLHttpRequest(); req.open(‘POST’, ‘/download/excel’, true); req.responseType = ‘blob’; //如果不指定,下载后文件会打不开 req.setRequestHeader(‘Content-Type’, ‘application/json’); req.onload = function() { var content = req.getResponseHeader(“Content-Disposition”) ; // 文件名最好用后端返的Content-disposition // 需要后端设置 Access-Control-Expose-Headers: Content-disposition 使得浏览器将该字段暴露给前端 var name = content && content.split(‘;’)[1].split(‘filename=’)[1]; var fileName = decodeURIComponent(name) downloadFile(req.response,fileName) }; req.send( JSON.stringify(params));
**axios写法**
axios({ method: ‘post’, headers: { ‘Content-Type’: ‘application/json; charset=utf-8’ }, url: ‘/robot/strategyManagement/analysisExcel’, responseType: ‘blob’, headers: { //如果需要权限下载的话,加在这里 Authorization: ‘123456’ } data: JSON.stringify(params), }).then(function(res){ var content = res.headers[‘content-disposition’]; var name = content && content.split(‘;’)[1].split(‘filename=’)[1]; var fileName = decodeURIComponent(name) downloadFile(res.data,fileName) })
<a name="YbHPJ"></a>#### 2.文件下载的方式**通过URL.createObjectURL()下载**<br />**URL.createObjectURL()** 静态方法会创建一个DOMString,其中包含一个表示参数中给出的对象的URL。这个 URL 的生命周期和创建它的窗口中的document绑定。
downloadFile:function(data,fileName){ // data为blob格式 var blob = new Blob([data]); var downloadElement = document.createElement(‘a’); var href = window.URL.createObjectURL(blob); downloadElement.href = href; downloadElement.download = fileName; document.body.appendChild(downloadElement); downloadElement.click(); document.body.removeChild(downloadElement); window.URL.revokeObjectURL(href); }
**通过# FileReader.readAsDataURL()下载**<br />**readAsDataURL()** 方法会读取指定的 Blob 或 File 对象。读取操作为异步操作,当读取完成时,可以从onload回调函数中通过实例对象的result属性获取data:URL格式的字符串(base64编码),此字符串即为读取文件的内容,可以放入a标签的href属性中。
downloadFile:function(data,fileName){ const reader = new FileReader() // 传入被读取的blob对象 reader.readAsDataURL(data) // 读取完成的回调事件 reader.onload = (e) => { let a = document.createElement(‘a’) a.download = fileName a.style.display = ‘none’ // 生成的base64编码 let url = reader.result a.href = url document.body.appendChild(a) a.click() document.body.removeChild(a) } }
<a name="c46Ry"></a>#### 两者的区别**返回值**<br />FileReader.readAsDataURL(blob)可以得到一段base64的字符串<br />URL.createObjectURL(blob)得到的是当前文件的一个内存url<br />**内存**<br />FileReader.readAsDataURL(blob)依照js垃圾回收机制自动从内存中清理 URL.createObjectURL(blob)存在于当前document内,清除方式通过revokeObjectURL()手动清除<br />**执行方式**<br />FileReader.readAsDataURL(blob)通过回调的方式f返回,异步执行<br />URL.createObjectURL(blob) 直接返回,同步执行<br />**多个文件**<br />FileReader.readAsDataURL(blob)同时处理多个文件时,需要一个文件对应一个FileReader对象<br />URL.createObjectURL(blob) 依次返回,没有影响<br />**优势对比**<br />URL.createObjectURL(blob)得到本地内存容器的URL地址,方便预览,需要注意手动释放内存的问题,性能优秀。<br />FileReader.readAsDataURL(blob)可直接转为base64格式,直接用于业务<a name="ztXk7"></a>### 五、插件downloadjs下载
npm install —save downloadjs
引入插件
import download from “downloadjs” // or const download = require(‘downloadjs’)
使用
export const downloadFile = (res, type, filename) => { // 将二进制流转成blob对象 const blob = new Blob([res], { type: type }) // 调用插件方法 download(blob, filename, type); }
结束语
以上,便是前端下载的全部内容了。内容不多,内容简单,希望可以帮助到大家。
另外,如果需要在生产环境下实现完成的前端下载,个人认为,单单使用上面的某个库是不够的。完成的下载流程应该包括但不限于
- 支持同源下载。如上面的downloadjs和file-saver
- 支持跨域下载。通过Node中间件转发或者后台实现。
- 支持大文件下载。如上面的streamsaver。
如果实现以上流程,便是一个较为完备的下载流程了。
才疏学浅,有什么不正确的地方,欢迎指出,共同学习。

若有收获,就点个赞吧
0 人点赞
