MySql Hash索引特性
- 基于hash结构 K(键) & V(值) 查找某一条记录的时候,速度非常快。
- Hash 索引是散列式分布。
- 不支持范围查找和排序等功能
- Memory表只存在内存中,断电会消失,适用于临时表
Hash索引结构
【Hash】索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可,是无序的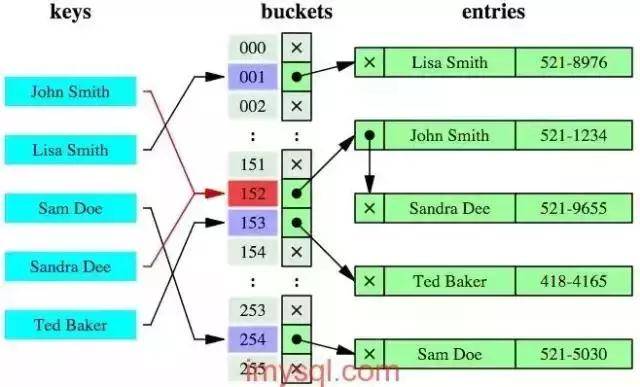
Hash索引的优势
等值查询。哈希索引具有绝对优势(前提是:没有大量重复键值,如果大量重复键值时,哈希索引的效率很低,因为存在所谓的哈希碰撞问题。)
Hash索引的劣势
1、不支持范围查询
2、不支持索引完成排序
3、不支持联合索引的最左前缀匹配规则
通常,B+树索引结构适用于绝大多数场景,像下面这种场景用哈希索引才更有优势:
在HEAP表中,如果存储的数据重复度很低(也就是说基数很大),对该列数据以等值查询为主,没有范围查询、没有排序的时候,特别适合采用哈希索引,例如这种SQL:
select id,name from table where name='李明'; — 仅等值查询
而常用的InnoDB引擎中默认使用的是B+树索引,它会实时监控表上索引的使用情况,如果认为建立哈希索引可以提高查询效率,则自动在内存中的“自适应哈希索引缓冲区”建立哈希索引(在InnoDB中默认开启自适应哈希索引),通过观察搜索模式,MySQL会利用index key的前缀建立哈希索引,如果一个表几乎大部分都在缓冲池中,那么建立一个哈希索引能够加快等值查询。
注意:在某些工作负载下,通过哈希索引查找带来的性能提升远大于额外的监控索引搜索情况和保持这个哈希表结构所带来的开销。但某些时候,在负载高的情况下,自适应哈希索引中添加的read/write锁也会带来竞争,比如高并发的join操作。like操作和%的通配符操作也不适用于自适应哈希索引,可能要关闭自适应哈希索引。

若有收获,就点个赞吧
0 人点赞
